【一】、搭建Hadoop环境----本地、伪分布式
## 前期准备
1.搭建Hadoop环境需要Java的开发环境,所以需要先在LInux上安装java
2.将 jdk1.7.tar.gz 和hadoop 通过工具上传到Linux服务器上
3.解压jdk 命令:tar -zxvf jdk-xxxx-xxx.tar.gz -C 目标文件目录中
4.使用root 用户 或者使用 sudo 编辑修改 vi /etc/profile
5.在文件的最后面添加上
export JAVA_HOME=xxxxxx[解压的目录]
export PATH=$PATH:$JAVA_HOME/bin
6.使用命令 : source /etc/profile 生效 ,检验是否安装成功命令 : java -version
## 开始搭建
1.首先解压Hadoop 2.5 到指定目录下,修改 /hadoop-2.5.0/etc/hadoop中的hadoop-env.sh中的JAVA_HOME
将export JAVA_HOME=${JAVA_HOME}
修改成 export JAVA_HOME=/xxxx/yyy/jdk1.7.0 (后面这个文件目录,可以使用 echo $JAVA_HOME来查看出 )
2.Hadoop 的测试开发环境有3种
1.Standalone Operation (标准版,单机启动)
2.Psedo-Distributed Operation (伪分布式启动)
3.Fully-Distributed Opeartion (完全分布式启动)
1).首先是Standalone Operation 测试
此时目录在hadoop2.5的解压目录中
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
2)Pseudo-Distributed Opeartion (需要进行配置文件)
2.1)首先配置 :(hadoop解压目录下的)/etc/hadoop/core-site.xml中的配置文件
这个是配置NameNode所在的机器,在value中,以前通常是9000,但是在Hadoop 2.0以后通常配置的 端口是 8020 而localhost也被换成主机名(查看主机名命令:hostname)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-senior.zuoyan.com:8020</value>
</property>
</configuration>
在这个文件中还需要覆盖一下默认的配置,然临时文件存放到我么指定的目录
在hadoop的解压目录下,创建mkdir data ===>cd data ===>mkdir tmp
<!--configurate Temporary date storage location-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
这个文件配置完毕,下面配置 hdfs-site.xml
这是配置文件的备份数量,因为是伪分布式,所以备份数量为1就可以
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
注:NameNode 存放的是元数据
第一次 对HDFS进行格式化 在hadoop的主目录中
bin/hdfs namenode -format
然后启动namenode :sbin/hadoop-daemon.sh start namenode
接着启动datanode :sbin/hadoop-daemon.sh start datanode
查看一下进程 : jps

*(有的人可能启动失败,可以去安装的主目录看一下日志:log)
http://hadoop-senior.zuoyan.com:50070 (hdfs 的web界面---Ip+50070(默认端口))
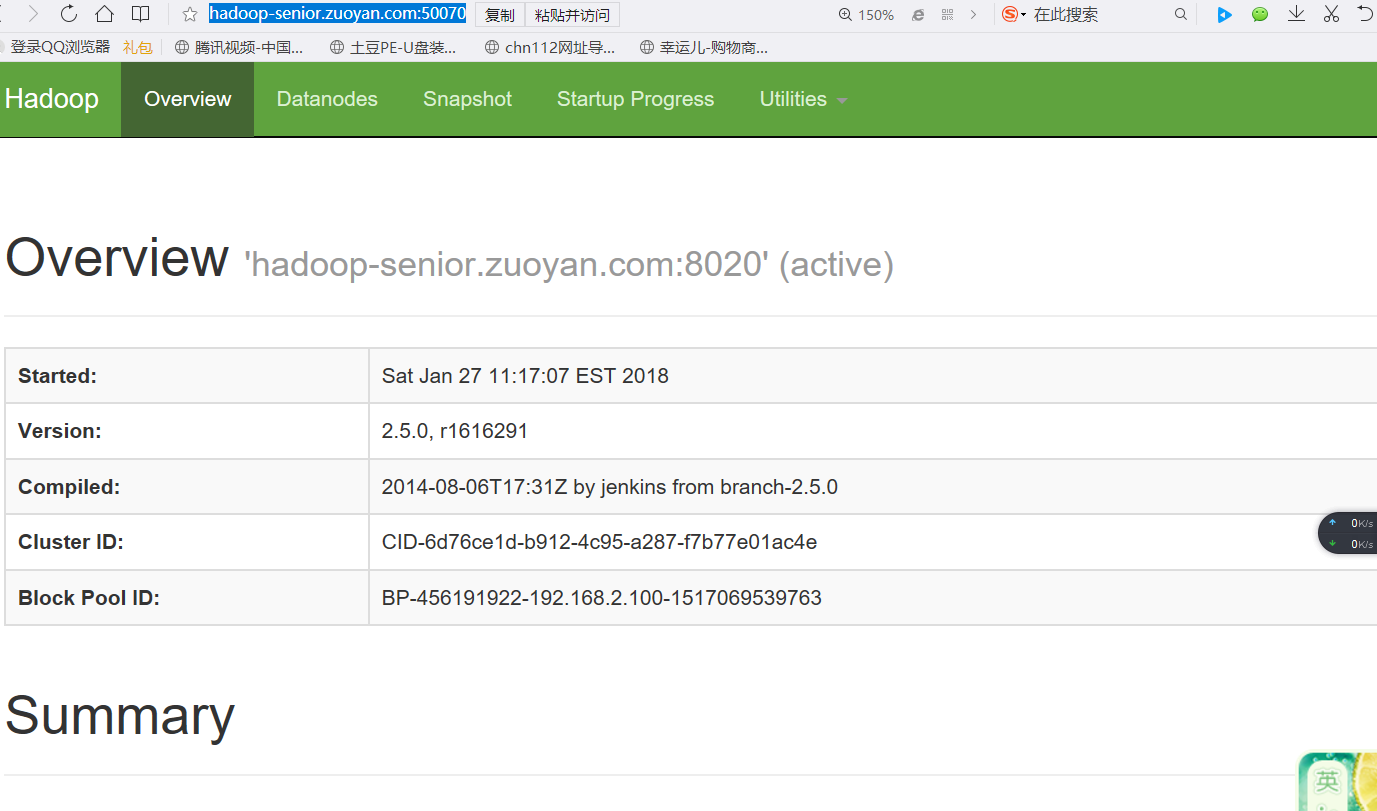
创建文件目录: bin/hdfs dfs -mkdir -p /usr/zuoyan
查看文件目录列表 : bin/hdfs dfs -ls / 或者循环查看问价目录列表 bin/hdfs dfs -ls -R /
删除文件目录 : bin/hdfs dfs -rm -r -f /xxx
上传文件: bin/hdfs dfs -put [本地文件目录] [HDFS上的文件目录]
例如:bin/hdfs dfs -put wcinput/wc.input /user/zuoyan/mapreduce/wordcount/input
效果:

使用命令查看文件列表效果:

使用命令查看文件内容 : bin/hdfs dfs -cat /XXXX/XXX
例:bin/hdfs dfs -cat /user/zuoyan/mapreduce/wordcount/input/wc.input
使用 mapreduce 统计单词出现的次数
命令: bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zuoyan/mapreduce/wordcount/input/ /user/zuoyan/mapreduce/wordcount/output
使用后的效果:

上图就是输出的效果!

两种执行效果是一样的,不同的是一个是在本地上运行的,一个是在HDFS文件系统上运行的!
下面配置yarn-env.sh(所在的目录为:hadoop安装路径 /etc/hadoop)
配置JAVA_HOME (可以不进行配置,为了保险起见,可以配置上)
# some Java parameters
export JAVA_HOME=/home/zuoyan/Softwares/jdk1.7.0_79
然后配置 yarn-site.xml (所在文件目录为:hadoop安装路径 /etc/hadoop)
<configuration>
<!--config the resourcemanager locatin computer ip-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior.zuoyan.com</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
讲一个英语单词:slaves(奴隶,或者是从节点的意思)
在slaves 中配置一下IP地址 :hadoop-senior.zuoyan.com
下面就是yarn 初始化
1.启动resourcemanager sbin/yarn-daemon.sh start resourcemanager
2.启动 nodemanager sbin/yarn-daemon.sh start nodemanager
使用jps看一下系统进程
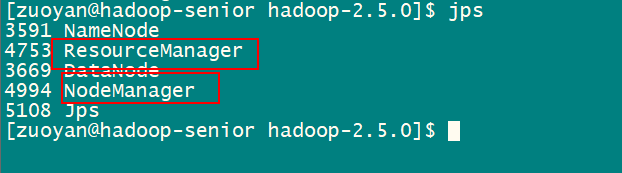
可以看到 resourceManger 和 NodeManager已经成功的启动起来了!
3.yarn也有一个自己默认的WEB页面 默认的端口号是8088
例如:http://hadoop-senior.zuoyan.com:8088 访问效果如下图

下面配置 mapreduce-site.xml 和mapreduce-env.sh
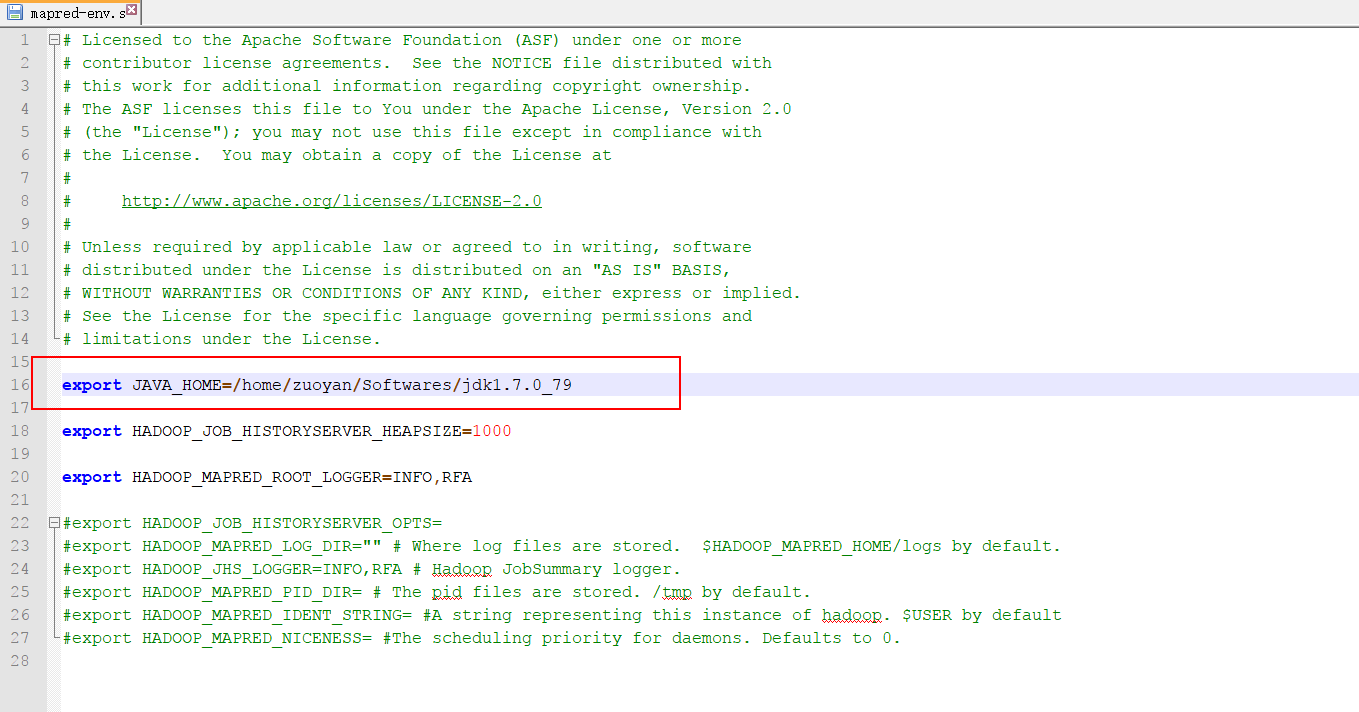
就是更改一下JAVA_HOME 的文件地址
首先找到 mapred-site.xml.template 更改文件名称 去掉后面的.template
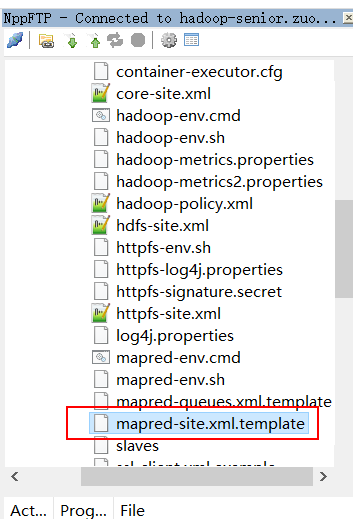
mapred-site.xml 然后配置这个里面的文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 这次执行 使用yarn 不在使用本地 所以速度会慢一点
使用的命令 (使用之前要记得删除output 目录,不然会报错 )
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zuoyan/mapreduce/wordcount/input/ /user/zuoyan/mapreduce/wordcount/output yarn执行时候的效果

上面统计单词出现个数的是
第一次演示的是 mapreduce 程序 运行在本机 (本地效果)
第二次演示的是mapreduce 程序 运行在yarn上的效果 (伪分布式效果)
【一】、搭建Hadoop环境----本地、伪分布式的更多相关文章
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- Hadoop学习2—伪分布式环境搭建
一.准备虚拟环境 1. 虚拟环境网络设置 A.安装VMware软件并安装linux环境,本人安装的是CentOS B.安装好虚拟机后,打开网络和共享中心 -> 更改适配器设置 -> 右键V ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用. 环境 操作系统 Centos 6.5_64bit 本机名称 hadoop001 本机IP ...
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- Ubuntu下用hadoop2.4搭建集群(伪分布式)
要真正的学习hadoop,就必需要使用集群,可是对于普通开发人员来说,没有大规模的集群用来測试,所以仅仅能使用伪分布式了.以下介绍怎样搭建一个伪分布式集群. 为了节省时间和篇幅,前面一些步骤不再叙述. ...
- Docker搭建Hadoop环境
文章目录 Docker搭建Hadoop环境 Docker的安装与使用 拉取镜像 克隆配置脚本 创建网桥 执行脚本 Docker命令补充 更换镜像源 安装vim 启动Hadoop 测试Word Coun ...
随机推荐
- jsp登陆界面代码
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncod ...
- 1 virtual
1 differents: 'virtual' just in C# In Java It does't have the keyword 2 Usages in C# used in base cl ...
- 使用QFileDiaglog实战designer快速开发
今天遇到一个大坑很久才解决 使用designer开发出图形界面转换为py文件后,使用QFileDialog对话框第一个参数一定要是当前窗口组件,否则程序直接奔溃(坑:能运行不报错但奔溃) def ge ...
- bzoj4443 小凸玩矩阵
题目链接 二分+最大check #include<algorithm> #include<iostream> #include<cstdlib> #include& ...
- input file accept类型
Valid Accept Types: For CSV files (.csv), use: <input type="file" accept=".csv&quo ...
- git getting started
2019/4/25-- after committing to blessed. modify dependency file to download file so as to get latest ...
- 算法笔记 #007# Backtracking
留着备用. 题目描述和代码参考:https://www.geeksforgeeks.org/8-queen-problem/ NQueenProblem(js代码): class NQueenProb ...
- 在使用springMVC时,页面报的404异常
HTTP Status – Not Found Type Status Report Message /WEB-INF/test/hello.jsp Description The origin se ...
- fjwc2019
机房搬迁.......再加上文化课.......咕了十几天才有空补上....... day0听一个教授讲理论......在学长的带领下咕掉了..... D1 T1:#178. 「2019冬令营提高组」 ...
- spring是如何控制事务
1.spring的核心是ioc和aop,其中ioc是将控制权交由spring容器进行管理,aop是面向切面编程,内部实现使用的是动态代理,二动态代理内部实现用的是反射.spring的事务是通过aop来 ...