深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
2018-07-17 16:54:51
Reference: https://blog.openai.com/openai-baselines-ppo/
Code: https://github.com/openai/baselines
Paper: https://arxiv.org/pdf/1707.06347.pdf
Video Tutorials: https://www.youtube.com/watch?v=OAKAZ hFmYoI&t=1s
Proximal Policy Optimization Algorithms (原文解析) :
Abstract:
首先要说的是本文提出一种新的 Policy Gradient 的方法,可以在如下两个步骤之间来回迭代进行学习:
1. sampling data through interaction with the environment ; 通过与环境进行交互,进行采样;
2. optimizing a "surrogate" objective function using stochastic gradient ascent. 利用梯度上升的方法进行代替的目标函数(surrgogate objective function)的优化。
传统的 Policy Gradient Method 仅仅能够利用采样得到的 samples 进行一次更新,就要将这些samples扔掉,重新采样,再实现更新。而本文所提出的方法可以进行 multiple epochs of minibatch updates.
Introduction :
最近深度学习的方法和强化学习的组合,得到了很多新的成果,如:Deep Q-leanring, "Vanilla" policy gradient method, trust region/natural poliicy gradient methods. 但是这些方法其实都是有其各自不足的地方,如:
Deep Q-learning 在很多简单的任务上却失败了,并且 poorly understood,
vanilla policy gradient methods 数据的效率和鲁棒性很差;
TRPO(trust region policy optimization)是一个相对较为复杂,并且不能与其他框架兼容的(not compatiable with architecture that including noise (such as dropout) or parameter sharing (between the policy and value function, or with auxiliary tasks)).
这篇文章旨在通过引入算法获得 data efficiency,and reliable performance of TRPO,来改善当前算法的情况,与此同时,仅仅采用 first-order optimization. 我们提出 a novel objective with clipped probability ratios,为了优化策略,我们用该 policy 进行采样,然后在采样的数据上进行几个 epoch 的更新。作者的实验证明,本文的方法在几个数据集上都取得了不错的效果。
2. Background:Policy Optimization
2.1 Policy Gradient Methods

2.2 TRPO





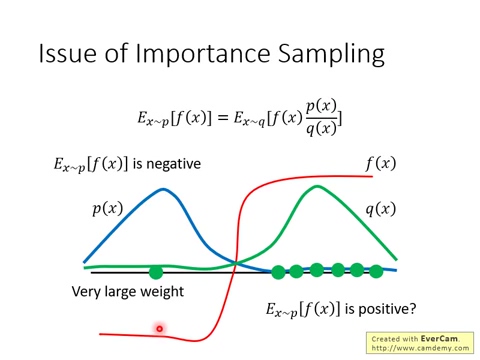








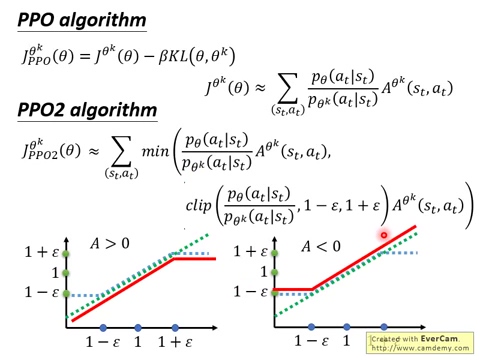
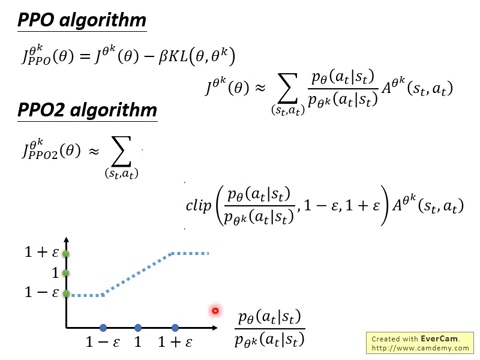
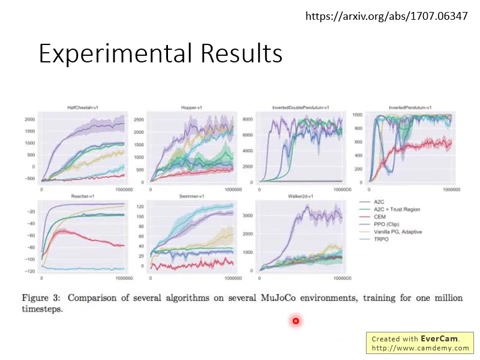
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)的更多相关文章
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- ng-深度学习-课程笔记-1: 介绍深度学习(Week1)
1 什么是神经网络( What is a neural network ) 深度学习一般是指非常非常大的神经网络,那什么是神经网络呢? 以房子价格预测为例,现在你有6个房子(样本数量),你知道房子的大 ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- 深度学习课程笔记(十)Q-learning (Continuous Action)
深度学习课程笔记(十)Q-learning (Continuous Action) 2018-07-10 22:40:28 reference:https://www.youtube.com/watc ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(七):模仿学习(imitation learning)
深度学习课程笔记(七):模仿学习(imitation learning) 2017.12.10 本文所涉及到的 模仿学习,则是从给定的展示中进行学习.机器在这个过程中,也和环境进行交互,但是,并没有显 ...
随机推荐
- asp.net web form 的缺点
与mvc相比,web form 的缺点: 代码架构麻烦. 以页面或控件为单位,把逻辑放在了一起,代码架构简单.平铺直叙,修改.维护比较麻烦. 不方便单元测试. 功能堆加在了一起,不方便对单个的功能进 ...
- Python OS模块常用功能 中文图文详解
一.Python OS模块介绍 OS模块简单的来说它是一个Python的系统编程的操作模块,可以处理文件和目录这些我们日常手动需要做的操作. 可以查看OS模块的帮助文档: >>> i ...
- 苹果手机显示分享链接的方法html页面
function onBridgeReady(){ WeixinJSBridge.call('showOptionMenu'); } if (typeof WeixinJSBridge == &quo ...
- hiho一下 第148周
题目1 : Font Size 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 Steven loves reading book on his phone. The b ...
- react复习总结(1)--react组件开发基础
这次是年后第一次发文章,也有很长一段时间没有写文章了.准备继续写.总结是必须的. 最近一直在业余时间学习和复习前端相关知识点,在一个公司呆久了,使用的技术不更新,未来真的没有什么前景,特别是我们这种以 ...
- Linux下EC20实现ppp拨号(转)
源: Linux下EC20实现ppp拨号 参考: 4g模块EC20+android6.0系统移植 OK6410开发板调试EC20通信模块 海思3531添加移远EC20 4g模块 将移远通信的EC20驱 ...
- Docker学习笔记之常见 Dockerfile 使用技巧
0x00 概述 在掌握 Dockerfile 的基本使用方法后,我们再来了解一些在开发中使用 Dockerfile 的技巧.这一小节的展现方式与之前的略有不同,其主要来自阅读收集和我自身在使用中的最佳 ...
- Python3 Pandas的DataFrame格式数据写入excle文件、json、html、剪贴板、数据库
Python3 Pandas的DataFrame格式数据写入excle文件.json.html.剪贴板.数据库 一.DataFrame格式数据 Pandas是Python下一个开源数据分析的库,它提供 ...
- Python 自学基础(一)——元组 字典 文件操作
格式化输出 name = input("请输入你的名字:") age = input("请输入你的年龄:") msg = ''' -------------in ...
- 纯手写SpringMVC到SpringBoot框架项目实战
引言 Spring Boot其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. 通过这种方式,springboot ...