022 Spark shuffle过程
1.官网
http://spark.apache.org/docs/1.6.1/configuration.html#shuffle-behavior
Spark数据进行重新分区的操作就叫做shuffle过程

2.介绍
SparkStage划分的时候,将最后一个Stage称为ResultStage(ResultTask),其它Stage叫做ShuffleMapStage(ShuffleMapTask)

3.SparkShuffle实现
基于ShuffleManager来实现,1.6.1版本中存在两种实现:HashShuffleManager和SortShuffleManager(默认);
由参数spark.shuffle.manager决定(sort or hash)
其中,sort:类似MR的shuffle,如下:
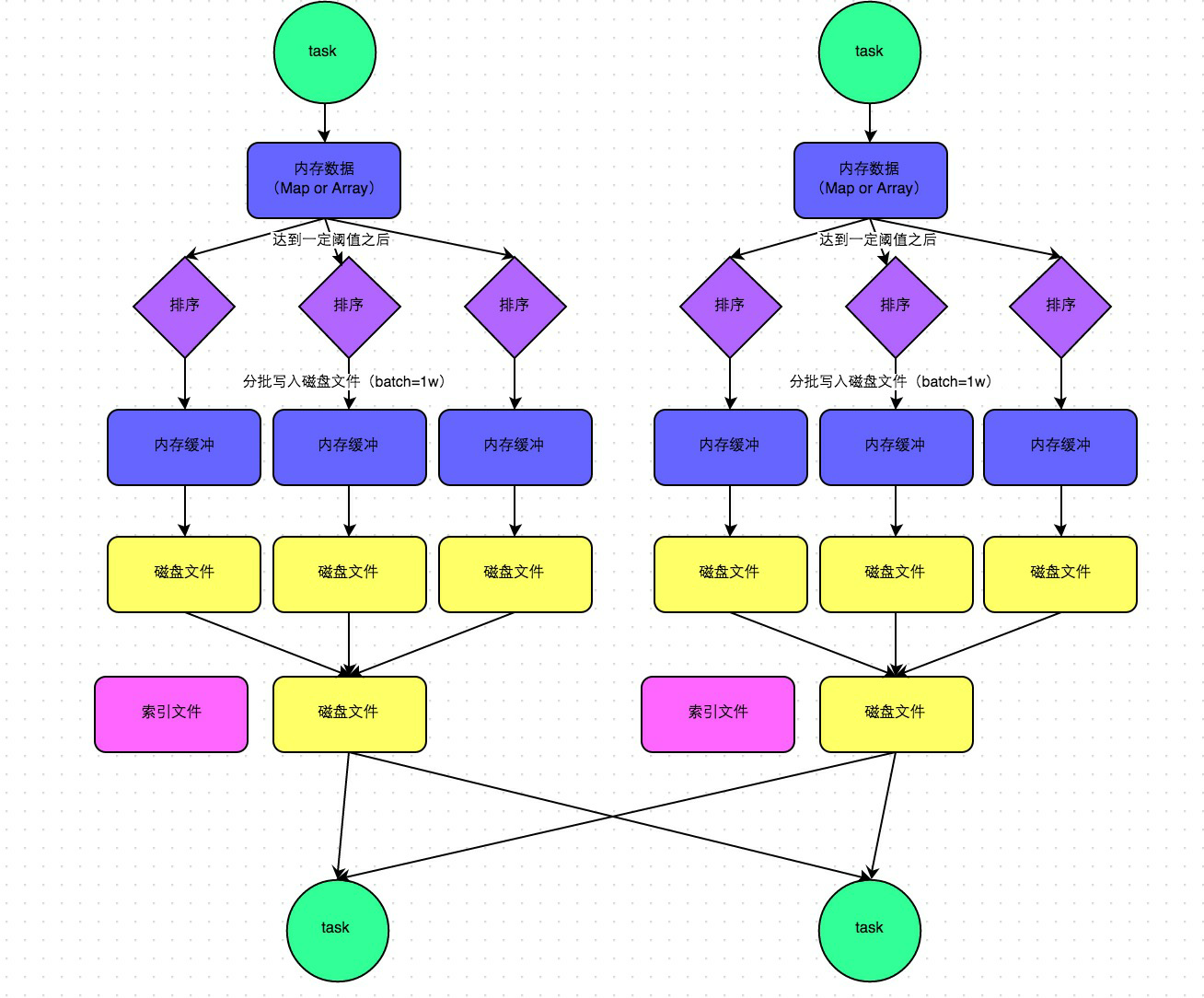
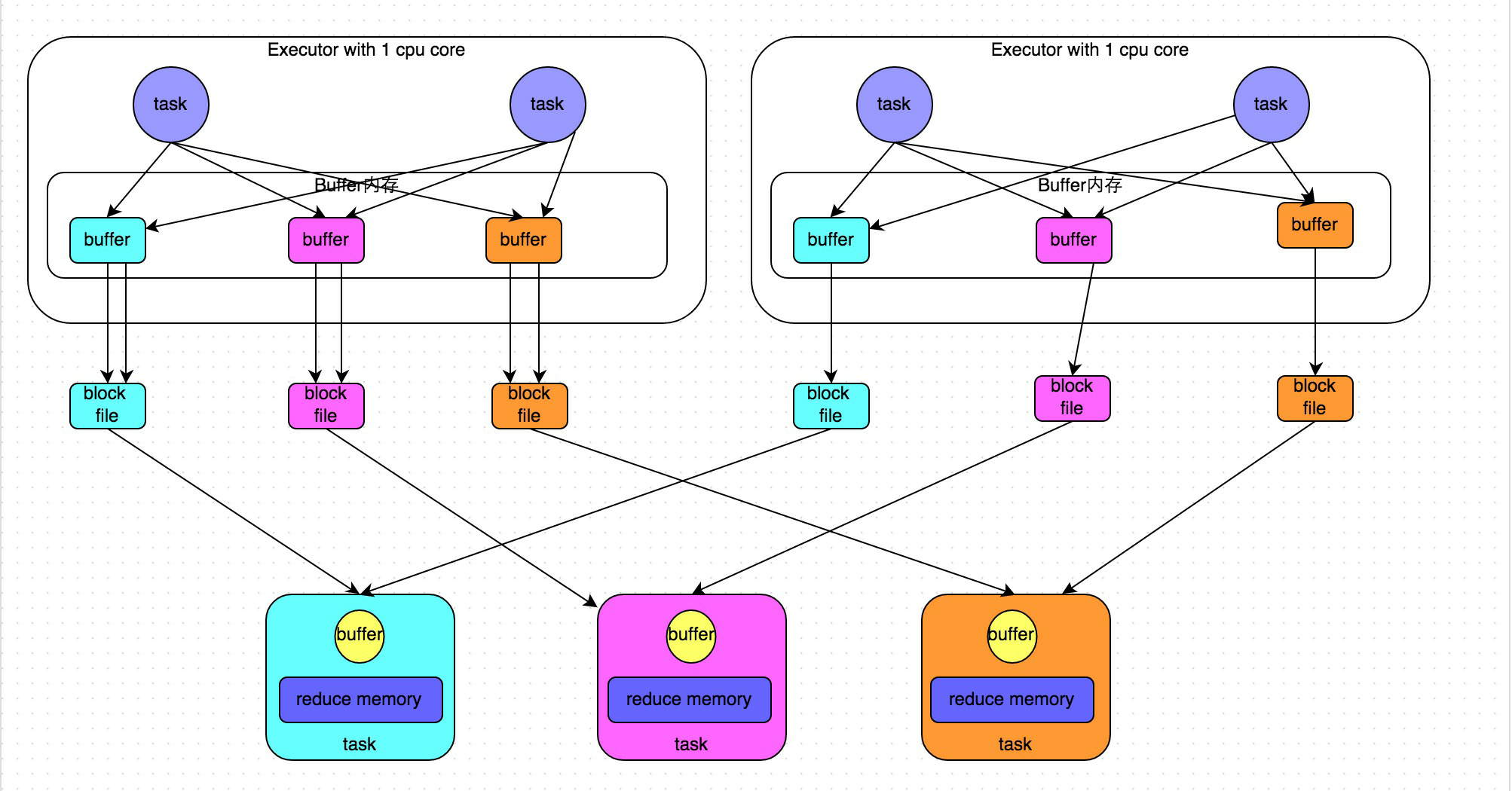
4.hash shuffle
在Spark1.2.x版本之前,只有一个ShuffleManager,就是hash
hash shuffle在以前的版本中存在一个问题:
会产生大量的磁盘问题
优化:
将一个Executor上的所有Task的执行结果合并到一起,减少文件的数量
spark.shuffle.consoldateFiles=true
原hash下的原理:

优化原理:
5.sort shuffle
在1.2版本之后,默认是SortManager,就是sort
小问题:所有的情况都进行排序(不管数据量的大小)<通过bypass运行模式可以解决>
两种运行:
普通运行模式:
中间会涉及到sort操作
bypass运行模式:
针对小数据量的情况下,不进行排序,类似于优化后的HashManager(性能没有HashManager<优化后>高)
下面是两个条件,就会走bypass模式,小数据量不排序:
-1. 当RDD的task数量小于spark.shuffle.sort.bypassMergeThreshold(默认200)的时候启用
-2. 不是聚合类shuffle算子(比如:不能是reduceByKey,可以是join)
二:shuffle与依赖的关系
1.说明
在后面补充一下知识点
2.关系

022 Spark shuffle过程的更多相关文章
- Spark Shuffle 过程
本文参考:http://www.cnblogs.com/cenyuhai/p/3826227.html 在数据流动的整个过程中,最复杂最影响性能的环节,就是 Shuffle 过程,本文将参考大神的博客 ...
- 浅析 Spark Shuffle 内存使用
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段.那么在 Spark Shuffle 中具 ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中.那么我们先说一下mapreduce的shuffle过程. ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- 剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
随机推荐
- vue2.0环境安装
参考网站http://www.open-open.com/lib/view/open1476240930270.html (以上博客vue init webpack-simple 工程名字<工程 ...
- AutoML技术现状与未来展望
以下内容是对AutoML技术现状与未来展望讲座的总结. 1.机器学习定义 <西瓜书>中的直观定义是:利用经验来改善系统的性能.(这里的经验一般是指数据) Mitchell在<Mach ...
- Sql Server 2008 数据库18456错误怎么解决?
可以windows连接,以前都可以,昨天突然就不可以用SQL连接,报18456错误. 1.以windows验证模式进入数据库管理器. 2.右击sa,选择属性: 在常规选项卡中,重新填写密码和确认密码( ...
- JavaScript中Function的拓展
Function 是什么东西,就是JavaScript中的顶级类,系统级别的类.我们平时写的函数方法例如下. function Animal() { } Animal就是Function的实例,但是在 ...
- malloc 函数详解【转】
转自:https://www.cnblogs.com/Commence/p/5785912.html 很多学过C的人对malloc都不是很了解,知道使用malloc要加头文件,知道malloc是分配一 ...
- ERROR 1067 (42000): Invalid default value for 'created_time'【转】
执行表增加字段语句报错 mysql> ALTER TABLE ha_question ADD COLUMN question_number INT; ERROR (): Invalid defa ...
- [Android四大组件之二]——Service
Service是Android中四大组件之一,在Android开发中起到非常重要的作用,它运行在后台,不与用户进行交互. 1.Service的继承关系: java.lang.Object → andr ...
- mysql多线程插入速度与不同数据库之间的比较
package ThreadInsetMysql;import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQ ...
- 前端开发必须知道的JS之闭包及应用
本文讲的是函数闭包,不涉及对象闭包(如用with实现).如果你觉得我说的有偏差,欢迎拍砖,欢迎指教. 在前端开发必须知道的JS之原型和继承一文中说过下面写篇闭包,加之最近越来越发现需要加强我的闭包应用 ...
- Linux C 结构体初始化三种形式
最近看linux代码时发现了结构体 struct 一种新的初始化方式,各方查找对比后总结如下: 1. 顺序初始化教科书上讲C语言结构体初始化是按照顺序方式来讲的,没有涉及到乱序的方式.顺序初始化str ...