java中三种for循环之间的对比
普通for循环语法:
for (int i = 0; i < integers.length; i++) {
System.out.println(intergers[i]);
}
foreach 循环语法:
for(Integer in : integers){
System.out.println(in);
}
今天我们来比较一下两种for循环对ArrayList和LinkList集合的循环性能比较。首先简单的了解一下ArrayList和LinkList的区别:
ArrayList:ArrayList是采用数组的形式保存对象的,这种方式将对象放在连续的内存块中,所以插入和删除时比较麻烦,查询比较方便。
LinkList:LinkList是将对象放在独立的空间中,而且每个空间中还保存下一个空间的索引,也就是数据结构中的链表结构,插入和删除比较方便,但是查找很麻烦,要从第一个开始遍历。
下面是我测试的代码:
package cn.migu.newportal.activity.service.activity; import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List; /**
*
* @author
* @version C10 2017年11月30日
* @since SDP V300R003C10
*/
public class Test
{
public static void main(String[] args)
{ // 实例化arrayList
List<Integer> arrayList = new ArrayList<Integer>();
// 实例化linkList
List<Integer> linkList = new LinkedList<Integer>(); // 插入10万条数据
for (int i = 0; i < 100000; i++)
{
arrayList.add(i);
linkList.add(i);
} int array = 0;
// 用for循环arrayList
long arrayForStartTime = System.currentTimeMillis();
for (int i = 0; i < arrayList.size(); i++)
{
array = arrayList.get(i);
}
long arrayForEndTime = System.currentTimeMillis();
System.out.println("用for循环arrayList 10万次花费时间:" + (arrayForEndTime - arrayForStartTime) + "毫秒"); // 用foreach循环arrayList
long arrayForeachStartTime = System.currentTimeMillis();
for (Integer in : arrayList)
{
array = in;
}
long arrayForeachEndTime = System.currentTimeMillis();
System.out.println("用foreach循环arrayList 10万次花费时间:" + (arrayForeachEndTime - arrayForeachStartTime) + "毫秒"); // 用for循环linkList
long linkForStartTime = System.currentTimeMillis();
int link = 0;
for (int i = 0; i < linkList.size(); i++)
{
link = linkList.get(i);
}
long linkForEndTime = System.currentTimeMillis();
System.out.println("用for循环linkList 10万次花费时间:" + (linkForEndTime - linkForStartTime) + "毫秒"); // 用froeach循环linkList
long linkForeachStartTime = System.currentTimeMillis();
for (Integer in : linkList)
{
link = in;
}
long linkForeachEndTime = System.currentTimeMillis();
System.out.println("用foreach循环linkList 10万次花费时间:" + (linkForeachEndTime - linkForeachStartTime) + "毫秒");
}
}
循环10万次的时候,控制台打印结果: (结果每次都会变,但求个平均值还是可以分析出结果的)
用for循环arrayList 10万次花费时间:6毫秒
用foreach循环arrayList 10万次花费时间:7毫秒
用for循环linkList 10万次花费时间:20489毫秒
用foreach循环linkList 10万次花费时间:8毫秒
可以看出,循环ArrayList时,普通for循环比foreach循环花费的时间要少一点;循环LinkList时,普通for循环比foreach循环花费的时间要多很多。
当我将循环次数提升到一百万次的时候,循环ArrayList,普通for循环还是比foreach要快一点;但是普通for循环在循环LinkList时,程序直接卡死。
结论:需要循环数组结构的数据时,建议使用普通for循环,因为for循环采用下标访问,对于数组结构的数据来说,采用下标访问比较好。
需要循环链表结构的数据时,一定不要使用普通for循环,这种做法很糟糕,数据量大的时候有可能会导致系统崩溃。
网上参考一种代码更紧凑的写法:
实体Person类
package cn.migu.newportal.activity.service.activity; /**
*
* @author
* @version C10 2017年11月30日
* @since SDP V300R003C10
*/
public class Person
{
private String a; private int b; public Person(String a, int b)
{
super();
this.a = a;
this.b = b;
} public String getA()
{
return a;
} public void setA(String a)
{
this.a = a;
} public int getB()
{
return b;
} public void setB(int b)
{
this.b = b;
} }
测试ArrayList的主程序:
package com.zhang.loop; import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List; public class TestArrayList {
private static final int COUNT = 800000;
private static List<Person> persons = new ArrayList<Person>(); public static void main(String[] args) {
init();
System.out.println("for循环测试结果:"+testFor());
System.out.println("foreach循环测试结果:"+testForeach());
System.out.println("iterator循环测试结果:"+testIterator());
} //初始化集合
public static void init(){
for (int i = 0; i <COUNT; i++) {
persons.add(new Person("第"+i+"个元素",i));
}
}
//for循环便利集合
public static long testFor(){
long start = System.nanoTime();
Person p = null;
for (int i = 0; i < persons.size(); i++) {
p = persons.get(i);
}
return (System.nanoTime()-start)/1000;
}
//foreach循环便利集合
public static long testForeach(){
long start = System.nanoTime();
Person p = null;
for (Person person : persons) {
p = person;
}
return (System.nanoTime()-start)/1000;
}
//iterator循环便利集合
public static long testIterator(){
long start = System.nanoTime();
Person p = null;
Iterator<Person> itreator = persons.iterator();
while(itreator.hasNext()){
p = itreator.next();
}
return (System.nanoTime()-start)/1000;
} }
ArrayList测试结果:
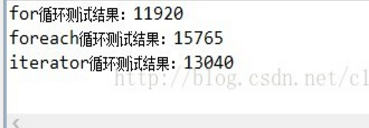
测试LinkedList的主程序:
package com.zhang.loop; import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List; public class TestArrayList {
private static final int COUNT = 8000;
private static List<Person> persons = new LinkedList<Person>(); public static void main(String[] args) {
init();
System.out.println("for循环测试结果:"+testFor());
System.out.println("foreach循环测试结果:"+testForeach());
System.out.println("iterator循环测试结果:"+testIterator());
} //初始化集合
public static void init(){
for (int i = 0; i <COUNT; i++) {
persons.add(new Person("第"+i+"个元素",i));
}
}
//for循环便利集合
public static long testFor(){
long start = System.nanoTime();
Person p = null;
for (int i = 0; i < persons.size(); i++) {
p = persons.get(i);
}
return (System.nanoTime()-start)/1000;
}
//foreach循环便利集合
public static long testForeach(){
long start = System.nanoTime();
Person p = null;
for (Person person : persons) {
p = person;
}
return (System.nanoTime()-start)/1000;
}
//iterator循环便利集合
public static long testIterator(){
long start = System.nanoTime();
Person p = null;
Iterator<Person> itreator = persons.iterator();
while(itreator.hasNext()){
p = itreator.next();
}
return (System.nanoTime()-start)/1000;
} }
LinkedList测试结果:
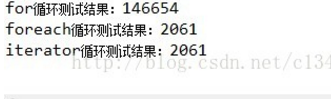
记录的存取方式有两种:
一种是顺序存储(数组,ArrayList..)可以根据其下标找到对应的记录
另一种是链接存储(LinkedList..)链接存储(拿单链表为例)则必须找到其前一个记录的位置才能够找到本记录。
根据以上可以得到的结果是:for循环便于访问顺序存储的记录,而foreach和迭代器便于访问链接存储。
java中三种for循环之间的对比的更多相关文章
- Java中几种常用数据类型之间转换的方法
Java中几种常用的数据类型之间转换方法: 1. short-->int 转换 exp: short shortvar=0; int intvar=0; shortvar= (short) in ...
- java设计模式---三种工厂模式之间的区别
简单工厂,工厂方法,抽象工厂都属于设计模式中的创建型模式.其主要功能都是帮助我们把对象的实例化部分抽取了出来,优化了系统的架构,并且增强了系统的扩展性. 本文是本人对这三种模式学习后的一个小结以及对他 ...
- 关于java中三种初始化块的执行顺序
许多小伙伴对于java中的三种初始化块的执行顺序一直感到头疼,接下来我们就来分析一下这三种初始化块到底是怎么运行的.有些公司也会将这个问题作为笔试题目. 下面通过一段代码来看看创建对象时这么初始化块是 ...
- java中三种方式获得类的字节码文件对象
package get_class_method; public class ReflectDemo { /** * @param args */ public static void main(St ...
- Java使用三种不同循环结构对1+2+3+...+100 求和
▷//第一种求法,使用while结构 /** * @author 9527 * @since 19/6/20 */ public class Gaosi { public static void ma ...
- Java中两种实现多线程方式的对比分析
本文转载自:http://www.linuxidc.com/Linux/2013-12/93690.htm#0-tsina-1-14812-397232819ff9a47a7b7e80a40613cf ...
- Go_18: Golang 中三种读取文件发放性能对比
Golang 中读取文件大概有三种方法,分别为: 1. 通过原生态 io 包中的 read 方法进行读取 2. 通过 io/ioutil 包提供的 read 方法进行读取 3. 通过 bufio 包提 ...
- Golang 中三种读取文件发放性能对比
Golang 中读取文件大概有三种方法,分别为: 1. 通过原生态 io 包中的 read 方法进行读取 2. 通过 io/ioutil 包提供的 read 方法进行读取 3. 通过 bufio 包提 ...
- Java中三种比较常见的数组排序
我们学习数组比较常用的数组排序算法不是为了在工作中使用(这三个算法性能不高),而是为了练习for循环和数组.因为在工作中Java API提供了现成的优化的排序方法,效率很高,以后工作中直接使用即可 . ...
随机推荐
- PhoneGap Vs AppCan
首先在写这篇文章前,必须先申明一下,本人是技术出身,对HTML技术及手机客户端都有过编程经验,只是出于工作岗位的变动,便没有再具体代码工作,以下文章涉及的中间件的基本代码实现及前期的API使用,都是自 ...
- 交换机的默认网关(跨网段telnet)
实验要求:配置一台交换机,并配置默认网关,使不同网段的主机能够远程telnet连接到交换机 拓扑图如下: 交换机配置: enable 进入特权模式 configure terminal 进入全局模式 ...
- 【转载】 强化学习(二)马尔科夫决策过程(MDP)
原文地址: https://www.cnblogs.com/pinard/p/9426283.html ------------------------------------------------ ...
- 2017-2018-2 20165228 实验三《敏捷开发与XP实践》实验报告
2017-2018-2 20165228 实验三<敏捷开发与XP实践>实验报告 相关知识点 (一)敏捷开发与XP 通过 XP准则来表达: 沟通 :XP认为项目成员之间的沟通是项目成功的关键 ...
- 【leetcode】7-ReverseInteger
problem: Reverse Integer 注意考虑是否越界: INT_MAX INT_MIN 32bits or 64bits 调整策略,先从简单的问题开始:
- Micro- and macro-averages
https://datascience.stackexchange.com/questions/15989/micro-average-vs-macro-average-performance-in- ...
- [LeetCode&Python] Problem 217. Contains Duplicate
Given an array of integers, find if the array contains any duplicates. Your function should return t ...
- Gym - 101002D:Programming Team (01分数规划+树上依赖背包)
题意:给定一棵大小为N的点权树(si,pi),现在让你选敲好K个点,需要满足如果如果u被选了,那么fa[u]一定被选,现在要求他们的平均值(pi之和/si之和)最大. 思路:均值最大,显然需要01分数 ...
- 改变radio单选按钮的样式
<div class="choose_btn"> <input type="radio" name="choose_raido&qu ...
- 静态布局、自适应布局、流式布局、响应式布局、弹性布局简析、BFC
静态布局:给页面元素设置固定的宽度和高度,单位用px,当窗口缩小,会出现滚动条,拉动滚动条显示被遮挡内容.针对不同分辨率的手机端,分别写不同的样式文件.例如:浏览器窗口是1000px,那么最小的宽度是 ...