ML: 聚类算法R包 - 模型聚类
模型聚类
- mclust::Mclust
- RWeka::Cobweb
mclust::Mclust
EM算法也称为期望最大化算法,在是使用该算法聚类时,将数据集看作一个有隐形变量的概率模型,并实现模型最优化,即获取与数据本身性质最契合的聚类方式为目的,通过‘反复估计’模型参数找出最优解,同时给出相应的最有类别级数k
所需程序安装包
install.packages("mclust")
函数示例代码
> library(mclust)
> EM<-Mclust(iris[,-5])
> summary(EM,parameters=T)
----------------------------------------------------
Gaussian finite mixture model fitted by EM algorithm
---------------------------------------------------- Mclust VEV (ellipsoidal, equal shape) model with 2 components: log.likelihood n df BIC ICL
-215.726 150 26 -561.7285 -561.7289 Clustering table:
1 2
50 100 Mixing probabilities:
1 2
0.333332 0.666668 Means:
[,1] [,2]
Sepal.Length 5.0060021 6.261996
Sepal.Width 3.4280046 2.871999
Petal.Length 1.4620006 4.905993
Petal.Width 0.2459998 1.675997
可以看到最优类别级数为2,各类分别含有50,100,
mclust::plot.Mclust(EM,what = "classification")
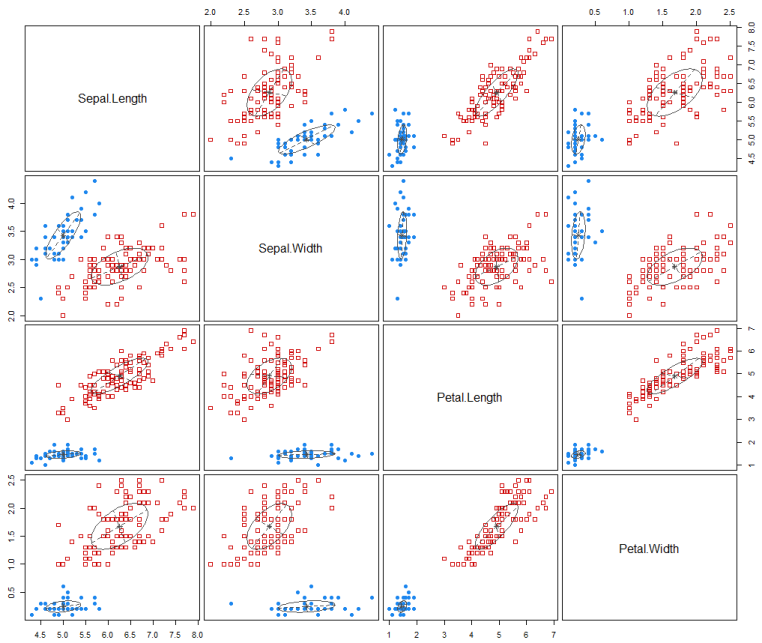
mclust::plot.Mclust(EM,what = "density")

RWeka::Cobweb
COBWEB是一种流行的简增量概念聚类算法。它以一个分类树的形式创建层次聚类,每个节点对应一个概念,包含该概念的一个概率描述,概述被分在该节点下的对象。使得该函数,需要安装RWeka包,在安装的过程中,可能出现如下的异常
** R
** inst
** preparing package for lazy loading
Error : .onLoad failed in loadNamespace() for 'rJava', details:
call: fun(libname, pkgname)
error: JAVA_HOME cannot be determined from the Registry
ERROR: lazy loading failed for package 'RWeka'
* removing 'C:/Users/zhushy/Documents/R/win-library/3.2/RWeka'
安装jre, 参考资料: http://blog.csdn.net/afei__/article/details/51464783
RWeka包未安装成功,示例代码未验证,待确认
library(RWeka) dcom=iris[,-5]
c1<-Cobweb(dcom)
c1
c1$class_ids
table(predict(c1),dcom$clas)
参考资料:
ML: 聚类算法R包 - 模型聚类的更多相关文章
- ML: 聚类算法R包-模糊聚类
1965年美国加州大学柏克莱分校的扎德教授第一次提出了'集合'的概念.经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面.为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析.用模 ...
- ML: 聚类算法R包-层次聚类
层次聚类 stats::hclust stats::dist R使用dist()函数来计算距离,Usage: dist(x, method = "euclidean", di ...
- ML: 聚类算法R包-网格聚类
网格聚类算法 optpart::clique optpart::clique CLIQUE(Clustering In QUEst)是一种简单的基于网格的聚类方法,用于发现子空间中基于密度的簇.CLI ...
- ML: 聚类算法R包 - 密度聚类
密度聚类 fpc::dbscan fpc::dbscan DBSCAN核心思想:如果一个点,在距它Eps的范围内有不少于MinPts个点,则该点就是核心点.核心和它Eps范围内的邻居形成一个簇.在一个 ...
- ML: 聚类算法R包-对比
测试验证环境 数据: 7w+ 条,数据结构如下图: > head(car.train) DV DC RV RC SOC HV LV HT LT Type TypeName 1 379 85.09 ...
- ML: 聚类算法R包-K中心点聚类
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值, ...
- 聚类算法之k-均值聚类
k-均值聚类算法 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 适用数据类型:数值型数据 其工作流程:首先,随机确定k个初始点作为质心,然后将数据集中的每个点分配到一个簇中,具 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- Kmeans文档聚类算法实现之python
实现文档聚类的总体思想: 将每个文档的关键词提取,形成一个关键词集合N: 将每个文档向量化,可以参看计算余弦相似度那一章: 给定K个聚类中心,使用Kmeans算法处理向量: 分析每个聚类中心的相关文档 ...
随机推荐
- Spring MVC之ResposeEntity下载文件
Spring Mvc中用ResponseEntity方式下载文件如下: @RequestMapping("/download") public ResponseEntity< ...
- ORACLE外连接实例
--查询各个部门工资范围,按照1000~2000,2000~3000....这样的格式显示人数 -------------------方法一 select dept.dname ,nvl(ano,) ...
- advanced ip scanner —— 局域网下 ip 及设备的扫描
advanced ip scanner 下载地址:Advanced IP Scanner - Download Free Network Scanner. 用于扫描当前局域网下全部设备及其 ip,构建 ...
- HihoCoder - 1801 :剪切字符串 (置换与逆序对)
Sample Input 6 5 11 Sample Output 6 小Hi有一个长度为N的字符串,这个字符串每个位置上的字符两两不同.现在小Hi可以进行一种剪切操作: 选择任意一段连续的K个字符, ...
- centos安装jdk1.8
一.安装Java环境 1. 删除系统预装的opensdk或其他sdk 用命令 java -version 验证是否存在sdk 2. 下载Java JDK约定的版本 版本:Java SE Develop ...
- acm 2072
////////////////////////////////////////////////////////////////////////////////#include<iostream ...
- 走进 AQS 瞧一瞧看一看
并发中有一块很重要的东西就是AQS.接下来一周的目标就是它. 看复杂源码时,一眼望过去,这是什么?不要慌,像剥洋葱一样,一层层剥开(哥,喜欢"扒开"这个词). 参考资源: http ...
- Nginx学习安装配置和Ftp配置安装
什么是代理? 什么是正向代理? 什么是反向代理? Nginx与负载均衡有什么联系? 如何在centos7 中安装Nginx-------------安装配置---------------------- ...
- 使用C语言简单模拟Linux的cat程序
先给出源码 //fileio.c #include<stdio.h> #include<stdlib.h> #include<fcntl.h> void print ...
- PostgreSQL Q&A: Building an Enterprise-Grade PostgreSQL Setup Using Open Source Tools
转自:https://www.percona.com/blog/2018/10/19/postgresql-building-enterprise-grade-setup-with-open-sour ...