Python之路PythonThread,第四篇,进程4
python3 进程/线程4
进程间同步互斥方法:
from multiprocessing import Lock
创建 进程锁对象
lock = Lock()
lock.acquire() 给临界区上锁
lock.release() 给临界区解锁
说明:1,具体实现上 acquire() 为一个条件阻塞函数;
2,当有任意一个进程先进行了acquire操作后,其他进程再企图进行acquire操作时就会阻塞,直到lock对象被release后其他进程CIA可以进行下次
acquire操作;
with lock: 也可以实现加锁,解锁
线程:
1,线程也可以使用计算机的多核资源,也是多任务编程方式之一;
2, 线程又称为轻量级的进程,在并发上和进程相同,但是在创建时销毁资源少;
说明:1,一个进程中可以包含多个线程,这个多个线程共享进程的资源;
2, 多个线程因为共享进程的资源,所以在通信上往往采用全局变量的方式;
3,线程也有自己特有的资源,比如TTD指令集等;
多进程和多线程的区别和联系:
1,多进程和多线程都是多任务编程方式,都可以使用计算机多核;
2,进程的创建要比线程消耗更多的资源;
3,进程的空间独立数据更安全,有专门的进程间通信方式进行交互;
4,一个进程包含多个线程,所以线程共享进程资源,没有专门的通信方式,依赖全局变量进行通信。 往往需要使用同步互斥机制,逻辑需要考虑更多;
5,进程线程都有自己特有的资源,多个关联任务的时候使用多线程资源消耗更少; 如果是多个无关联任务也不适用全部都使用线程;
- from multiprocessing import Process,Lock
- import time,sys
- def worker1(stream):
- lock.acquire() # 加锁
- for i in range(5):
- time.sleep(1)
- stream.write("Lock acquired via\n")
- lock.release()#解锁
- def worker2(stream):
- # lock.acquire()
- with lock: #加锁 语句块结束即解锁
- for i in range(5):
- time.sleep(1)
- stream.write("Lock acquired directly\n")
- # lock.release()
- lock = Lock()
- #sys.stdout为所有进程都拥有的资源
- w1 = Process(target=worker1,args=(sys.stdout,))
- w2 = Process(target=worker2,args=(sys.stdout,))
- w1.start()
- w2.start()
- w1.join()
- w2.join()
创建线程:
import threading
创建线程函数
threading.Tread()
功能:创建线程
参数:target 线程函数
args 以元组方式给线程函数传参
kwargs 以字典方式给线程函数传参
name 线程名称(默认Thread-1)
返回值:返回线程对象
线程属性和方法:
t.start() 启动一个线程
t.is_alive() 查看一个线程的状态
t.name 查看线程的名称
t.join([esc]) 阻塞等待回收线程
- import threading
- from time import ctime,sleep
- a = 10
- def music(sec):
- print("Listening music")
- global a
- a = 1000
- sleep(sec)
- t = threading.Thread(name = "my thread",\
- target = music,args = (2,))
- t.start()
- print("创建线程")
- sleep(3)
- print(a)
deamon属性:
1,设置该属性默认为False, 主线程执行完毕后不会影响其他线程的执行;
2, 如果设置为True, 则主线程执行完毕其他线程也终止执行;
代码:
设置daemon: t.setDaemon(True) 或 t.daemon = True
获取daemon属性值: t.isDaemon()
- import threading
- from time import sleep,ctime
- def fun():
- print("This is a thread test")
- sleep(5)
- print("thread over")
- t = threading.Thread(name = 'levi',\
- target = fun)
- # t.setDaemon(True)
- t.daemon = True
- print(t.isDaemon())
- t.start()
- print(t.is_alive()) #线程状态
- print(t.name) #线程名称
- t.join(2)
- print("all over",ctime())
线程间的通信:
全局变量进行通信;
线程间的同步和互斥;
- import threading
- from time import sleep
- s = None
- e = threading.Event()
- def bar():
- print("呼叫foo")
- global s
- s = "天王盖地虎"
- def foo():
- print('foo等口令')
- sleep(2)
- print('foo收到 %s'%s)
- e.set()
- def fun():
- sleep(1)
- e.wait()
- print("内奸出现")
- global s
- s = "小鸡炖蘑菇"
- t1 = threading.Thread\
- (name = 'bar',target = bar)
- t2 = threading.Thread\
- (name = 'foo',target = foo)
- t3 = threading.Thread\
- (name = 'fun',target = fun)
- t1.start()
- t2.start()
- t3.start()
- t1.join()
- t2.join()
- t3.join()
线程 event:
创建事件对象: e = threading.Event()
e.wait([timeout]) 如果e被设置则不会阻塞,未被设置则阻塞 ;timeout为阻塞的超时时间;
e.set() 将e变为设置是状态
e.clear() 将e变为未设置状态;
- from threading import *
- import random
- from time import sleep
- a = 500
- #创建事件对象
- e = Event()
- #子线程不断减少a 但是希望a的值不会少于100
- def fun():
- global a
- while True:
- sleep(2)
- print('a = ',a)
- e.wait()
- a -= random.randint(0,100)
- t = Thread(target = fun)
- t.start()
- #主线程不断的让a增加以确保a不会小于100
- while True:
- sleep(1)
- a += random.randint(1,10)
- if a > 100:
- e.set()
- else:
- e.clear()
- t.join()
线程锁:
lock = threading.Lock() 创建线程锁;
lock.acquire() 上锁
lock.release() 解锁
- import threading
- a = b = 0
- lock = threading.Lock()
- def value():
- while True:
- lock.acquire()
- if a != b:
- print("a = %d,b = %d"%(a,b))
- lock.release()
- t = threading.Thread(target = value)
- t.start()
- while True:
- lock.acquire()
- a += 1
- b += 1
- lock.release()
- t.join()
创建自己的线程类:
1,自定义类 继承于 原有线程类Thread
2, 复写原有的run方法;
3,创建线程对象调用start的时候会自动执行run
- from time import ctime,sleep
- import threading
- #编写自己的线程类
- class MyThread(threading.Thread):
- def __init__(self,func,args,name = 'Levi'):
- threading.Thread.__init__(self)
- self.func = func
- self.name = name
- self.args = args
- #自定义 线程启动函数
- def run(self):
- self.func(*self.args)
- #待启动的线程函数
- def player(file,time):
- for i in range(2):
- print('start playing %s:%s'\
- %(file,ctime()))
- sleep(time)
- t = MyThread(player,('baby.mp3',3))
- t.start()
- t.join()
线程池第三方模块 :threadpool
sudo pip3 install threadpool
GIL (全局解释器锁)
python ---> 支持多线程 ----> 同步和互斥 ---> 加锁 --->超级锁 ---> 解释器在同一时刻只能解释一个线程;
大量python库为了省事依赖于这种机制----> python多线程效率低;
GIL 即为从python解释器由于 上锁带了的同一时刻只能解释一个线程的问题;
解决方案:
1, 不使用线程,转而使用进程;
2, 不使用c 作为解释器 java c# 都可以做python解释器;
(1)IO密集型: 程序中进行了大量的IO操作,只有少量的CPU操作;
在内存中进行了数据的交换的操作都可以认为是IO操作;
特点: 速度较慢,使用cpu不高;
(2)cpu密集型(计算密集型):大量的程序都在进行运算操作;
特点:cpu占有率高
效率测试:
Line cpu 1.224205732345581
Line IO 4.142379522323608
Thread cpu 0.7009162902832031
Thread IO 3.458016872406006
Process cpu 0.6419346332550049
Process IO 1.8482108116149902
总结:多线程的工作效率和单线程几乎相近,而多进程要比前两者有明显的效率提升
设计模式:
设计模式代表了一种最佳实践,是被开发人员长期开发总结,用来解决某一类问题的思路方法。这种方法保证了代码的效率,也易于理解;
单例模式,工厂模式,生产者模式。。。
生产者消费者模式:
高内聚: 在同一模块内,实现单一功能,尽量不使功能混杂;
低耦合: 不同的模块之间尽量相互独立,减少模块间的影响;
代码实现
- from threading import Thread
- #python标准库中的队列模块
- import queue
- import time
- #创建一个队列模型作为商品的仓库
- q = queue.Queue()
- class Producer(Thread):
- def run(self):
- count = 0
- while True:
- if q.qsize() < 50:
- for i in range(3):
- count += 1
- msg = "产品 %d"%count
- q.put(msg) #将产品放入队列
- time.sleep(1)
- class Customer(Thread):
- def run(self):
- while True:
- if q.qsize() > 20:
- for i in range(2):
- msg = q.get() #从仓库拿到商品
- print("消费了一个 %s"%msg)
- time.sleep(1)
- #创建三个生产者
- for i in range(3):
- p = Producer()
- p.start()
- #创建5个消费者
- for i in range(5):
- p = Customer()
- p.start()
总结:
1,进程和线程的区别
2.会创建使用线程 threading
3.掌握基本的线程间同步互斥编程方法
4.知道什么是GIL
5.了解设计模式的概念
*************************************************************
面试问题:
1. 进程和线程的区别
2. 什么是同步和互斥
3. 给一个具体的情况,问采用进程还是线程为什么
4. 你是怎么处理僵尸进程的
5. 怎么测试一个硬盘的读写速度
6. xxx框架 是用的多进程还是多线程并发
7. 进程间通信方式知道哪些,都有什么特点
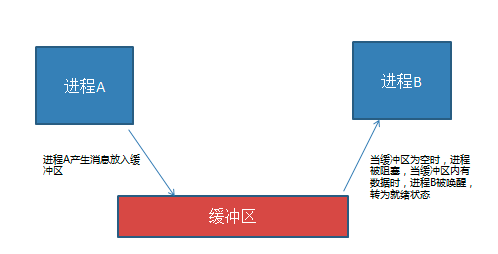 同步
同步
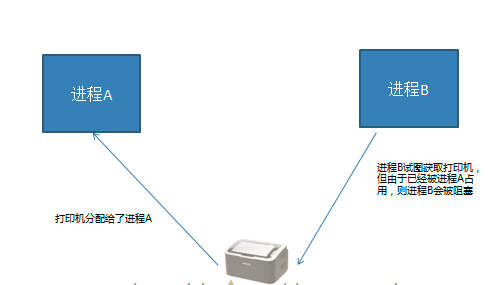 互斥
互斥
Python之路PythonThread,第四篇,进程4的更多相关文章
- Python之路【第四篇】:模块
什么是模块: 模块就是一个功能的集合. 模块就和乐高积木差不多,你用这些模块组合出一个模型,然后也可以用这个模块加上其他的模块组合成一个新的模型 模块的种类: 1.内置模块(python自带的比如os ...
- Python之路PythonThread,第二篇,进程2
python3 进程2 僵尸进程处理方法: 3,创建二级子进程处理 4,在父进程中使用信号处理的方法忽略子进程发来的信号: signal(SIGCHLD,DIG,IGN) # 创建二级子进场解决僵 ...
- Python之路PythonThread,第一篇,进程1
python3 进程1 多任务编程: 可以有效的利用计算机资源,同时执行多个任务, 进程:进程就是程序在计算机中一次执行的结果: 进程和程序的区别: 程序是一个静态文件的描述,不占用计算机的系统资源: ...
- Python之路【第四篇】:Python基础之函数
函数的理解 面向过程:根据业务逻辑从上到下垒代码 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可 函数作用是你的程序有良好的扩展性.复用性. 同样的功能要是用3次以上的话就建议使 ...
- Python之路【第四篇】: 函数、递归、内置函数
一. 背景提要 现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码 while True: i ...
- 【Python之路】第四篇--Python基础之函数
三元运算 三元运算(三目运算),是对简单的条件语句的缩写 # 书写格式 result = 值1 if 条件 else 值2 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2” ...
- Python之路【第四篇补充】:面向对象初识和总结回顾
面向过程的编程 面向过程:根据业务逻辑从上到下写垒代码! 例子: 需求一.有一个程序需要做身份认证: 用户名有个字典: #定义一个用户名信息字典 user_info = { "zhangsa ...
- Python之路【第四篇】Python基础2
一.格式化输出 按要求输出信息 name=input("name:") age=int(input("age:")) job=input("job:& ...
- Python之路,第四篇:Python入门与基础4
Python3 字符串 字符串是一个有序的字符序列 如何表示一个字符串: 在非注释中凡是用引号括起来的部分都是字符串: ‘ 单引号 ” 双引号 ‘’‘ 三单引号 “”“ ...
- Python之路(第二十四篇) 面向对象初级:多态、封装
一.多态 多态 多态:一类事物有多种形态,同一种事物的多种形态,动物分为鸡类,猪类.狗类 例子 import abc class H2o(metaclass=abc.ABCMeta): def _ ...
随机推荐
- 牛客第二场A-run
链接:https://www.nowcoder.com/acm/contest/140/A 来源:牛客网 White Cloud is exercising in the playground. Wh ...
- Farm Irrigation(非常有意思的并查集)
Farm Irrigation Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Tot ...
- vsftpd更新和修改版本号教程
1.rpm包更新 类似以下更新即可 rpm -Uvh vsftpd--.el6.x86_64.rpm 2.源码更新 不懂为什么对于新版本可能只有源码包而没有rpm等包,如此只能以源码更新了. .tar ...
- learning ddr mode register MR0
- 关于scratch导出的flash画质很差的问题解决方案
Scratch的分辨率是480*360,因此把scratch文件转变为flash时,因影像和画质很差,把flash插入到ppt幻灯片后,影像和画质仍然得不到保证.经过不断摸索,这个问题终于得到解决,关 ...
- java⑧
1.switch的表达式取值: byte short int char Enum(枚举) jdk1.7版本以上支持 String类型 2. break: 01.代表跳出当前方法体!跳出 ...
- awk计算最大值,最小值,平均值的脚本
传入至少三个数字参数到脚本awk_file,并计算出最大,最小,平均值.需要判断传入的数字是否足够,否则输出警告信息.平均值保留两位小数. 如执行bash awk_file 3 4 6 5,脚本输出结 ...
- 稀疏 部分 Checkout
To easily select only the items you want for the checkout and force the resulting working copy to ke ...
- VSTO:使用C#开发Excel、Word【10】
第二部分:.NET中的Office编程本书前两章介绍了Office对象模型和Office PIA. 您还看到如何使用Visual Studio使用VSTO的功能构建文档中的控制台应用程序,加载项和代码 ...
- 深入理解java虚拟机---java虚拟机的发展史(四)
1.java虚拟机 A:java虚拟机有很多个版本,但是我们经常使用的是sun公司的HotSpot,可以通过以下命令获取java虚拟机版本 B:JAVA虚拟机分类: 1.Sun Class VM 2. ...