Python中结巴分词使用手记
手记实用系列文章:
3 自然语言处理手记
结巴分词方法封装类
from __future__ import unicode_literals
import sys
sys.path.append("../") import jieba
import jieba.posseg
import jieba.analyse print('='*40)
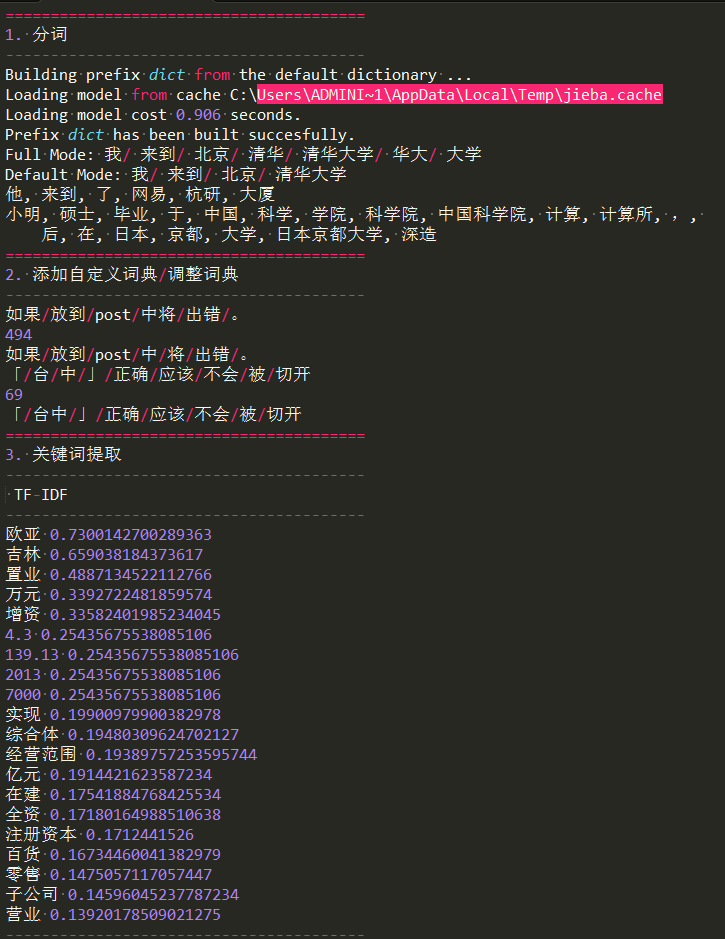
print('1. 分词')
print('-'*40) seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默认模式 seg_list = jieba.cut("他来到了网易杭研大厦")
print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list)) print('='*40)
print('2. 添加自定义词典/调整词典')
print('-'*40) print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中将/出错/。
print(jieba.suggest_freq(('中', '将'), True))
#494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台/中/」/正确/应该/不会/被/切开
print(jieba.suggest_freq('台中', True))
#69
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台中/」/正确/应该/不会/被/切开 print('='*40)
print('3. 关键词提取')
print('-'*40)
print(' TF-IDF')
print('-'*40) s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w)) print('-'*40)
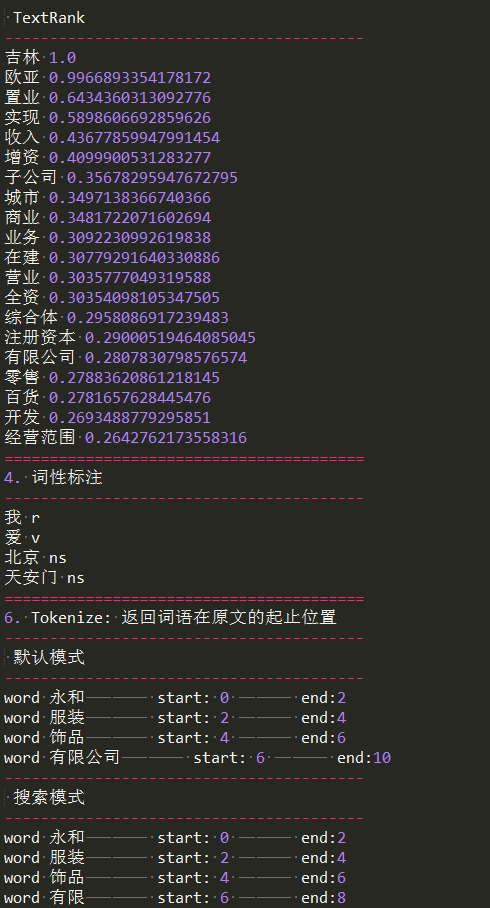
print(' TextRank')
print('-'*40) for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w)) print('='*40)
print('4. 词性标注')
print('-'*40) words = jieba.posseg.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag)) print('='*40)
print('6. Tokenize: 返回词语在原文的起止位置')
print('-'*40)
print(' 默认模式')
print('-'*40) result = jieba.tokenize('永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2])) print('-'*40)
print(' 搜索模式')
print('-'*40) result = jieba.tokenize('永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
结巴分词的运行结果
Python中结巴分词使用手记的更多相关文章
- python调用hanlp分词包手记
python调用hanlp分词包手记 Hanlp作为一款重要的分词工具,本月初的时候看到大快搜索发布了hanlp的1.7版本,新增了文本聚类.流水线分词等功能.关于hanlp1.7版本的新功能,后 ...
- 结巴分词和自然语言处理HanLP处理手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- Python中调用自然语言处理工具HanLP手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- Python中文语料批量预处理手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- Python 结巴分词(1)分词
利用结巴分词来进行词频的统计,并输出到文件中. 结巴分词github地址:结巴分词 结巴分词的特点: 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成 ...
- Python 结巴分词模块
原文链接:http://www.gowhich.com/blog/147?utm_source=tuicool&utm_medium=referral PS:结巴分词支持Python3 源码下 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
随机推荐
- Linux学习笔记:scp远程拷贝文件
scp是secure copy的简写,用于Linux下进行远程拷贝文件的命令,类似的有cp,不过cp仅在本机上进行拷贝不能跨服务器. 命令格式: scp [参数] [原路径] [目标路径] -q 不显 ...
- windows下安装GIT,使用GIT GUI 上传文件到github
安装 1.从官网 https://git-scm.com/download/win下载安装包 2.打开安装包安装,点击next,接着再点击三次next 3.在下拉菜单中选择已安装的文本编辑器,点击ne ...
- 《剑指offer》-前n项和不准用通解和各种判断
题目描述 求1+2+3+...+n,要求不能使用乘除法.for.while.if.else.switch.case等关键字及条件判断语句(A?B:C). 这题目简直没事找事...为啥这么说,因为没有限 ...
- usaco 校园网
题解: 显然当一个图上的点是一个环时能满足题目要求 那么我们来考虑怎么形成一个环 很显然的是要先缩点 缩完点就成为了森林,如何让森林成环呢? 考虑一下环上的点的入度出度一定都大于1 而连一条边可以增加 ...
- Codeforces Round #469 (Div. 2)
Codeforces Round #469 (Div. 2) 难得的下午场,又掉分了.... Problem A: 怎么暴力怎么写. #include<bits/stdc++.h> #de ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用
最近按公司要求,爬取相关网站时,发现没有找到js包的地址,我就采用selenium来爬取信息,相关实战链接:python爬虫实战(一)--------中国作物种质信息网 一.Selenium介绍 Se ...
- Python - 经典程序示例
列表排序 def que6(): # 6.输入三个整数x, y, z,形成一个列表,请把这n个数由小到大输出. # 程序分析:列表有sort方法,所以把他们组成列表即可. li = np.random ...
- Redis实现的分布式锁和分布式限流
随着现在分布式越来越普遍,分布式锁也十分常用,我的上一篇文章解释了使用zookeeper实现分布式锁(传送门),本次咱们说一下如何用Redis实现分布式锁和分布限流. Redis有个事务锁,就是如下的 ...
- LoRaWAN 1.1 网络协议规范 - 3 物理层帧格式
LoRaWAN 1.1 网络协议规范 LoRaWAN 1.1 版本封稿很久了也没有完整啃过一遍,最近边啃边翻译,趁着这个机会把它码下来. 如果觉得哪里有问题,欢迎留言斧正. 翻译不易,转载请申明出处和 ...
- Vue的移动端多图上传插件vue-easy-uploader
原文地址 前言 这段时间赶项目,需要用到多文件上传,用Vue进行前端项目开发.在网上找了不少插件,都不是十分满意,有的使用起来繁琐,有的不能适应本项目.就打算自己折腾一下,写一个Vue的上传插件,一劳 ...