Hadoop---Java-API对HDFS的操作
Java-API对HDFS的操作
哈哈哈哈,深夜来一波干货哦!!!
Java-PAI对hdfs的操作,首先我们建一个maven项目,我主要说,我们可以通过Java代码来对HDFS的具体信息的打印,然后用java代码实现上传文件和下载文件,以及对文件的增删。
首先来介绍下如何将java代码和HDFS联系起来,HDFS是分布式文件系统,说通俗点就是用的存储的数据库,是hadoop的核心组件之一,其他还有mapreduce,yarn.其实也就是我们通过java代码来访问这个这个系统。然后进行操作等等。。java中导入jar包来进行编码操作。
我们这里使用pom.xml导入依赖的方式,还有种1中方式就是lib(通俗易懂就是导入jar包)。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>hu-hadoop1</groupId>
<artifactId>k</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>k</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-app</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
然后我们就可以开始进入编码阶段了。
首先建一个类HDFSDemo1
谈谈如何访问HDFS的方法:在下提出3种方法.分别一下列出。清晰可见在下的真心实意。
方式一:使用 使用hfds api 操作hadoop
package com.bw.day01; import java.io.InputStream;
import java.net.URL; import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils; /**
* 相对较老的hdfs api 使用java api也是可以访问hdfs的
* @author huhu_k
*
*/
public class HDFSDemo1 { static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
} public static void main(String[] args) throws Exception {
URL url = new URL("hdfs://hu-hadoop1:8020/1708as1/f1.txt");
InputStream openStream = url.openStream();
IOUtils.copyBytes(openStream, System.out, );
}
}
方式二:相对较老的hdfs api 进行访问
package com.bw.day01; import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo; /**
* 使用hfds api 操作hadoop
*
* @author huhu_k
*
*/
public class HDFSDemo2 { public static void main(String[] args) throws Exception { // 1.step 配置容器 可以配置
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://hu-hadoop1:8020");
// 2.step
FileSystem fs = FileSystem.get(conf);
DistributedFileSystem dfs = (DistributedFileSystem) fs;
DatanodeInfo[] di = dfs.getDataNodeStats();
for (DatanodeInfo d : di) {
//datanode的一些信息
System.out.println(d.getBlockPoolUsed());
System.out.println(d.getCacheCapacity());
System.out.println(d.getCapacity());
System.out.println(d.getDfsUsed()); // 地址
System.out.println(d.getInfoAddr()); // 状态
System.out.println(d.getAdminState()); System.out.println("----------------------------");
// System.out.println(d.getDatanodeReport());
SimpleDateFormat sdf = new SimpleDateFormat("EEE MMM dd HH:mm:ss z yyyy", java.util.Locale.US);
String value = d.getDatanodeReport(); Map<String, String> map1 = new HashMap<>();
Map<String, String> map2 = new HashMap<>();
Map<String, String> map3 = new HashMap<>();
int flag = 0;
String[] str1 = value.split("\\n");
for (String s : str1) {
String[] str2 = s.split(": ");
if (0 == flag) {
if ("Last contact".equals(str2[0])) {
String format = sdf.format(new Date(str2[1]));
Date date = sdf.parse(format.toString());
//最后一次访问hdfs 和现实的时间戳==心跳
System.out.println(System.currentTimeMillis() - date.getTime());
System.out.println(System.currentTimeMillis());
System.out.println(date.getTime());
}
map1.put(str2[0], str2[1]);
} else if (1 == flag) {
map2.put(str2[0], str2[1]);
} else {
map3.put(str2[0], str2[1]);
}
}
System.out.println("----------------------------"); for (Entry<String, String> m1 : map1.entrySet()) {
System.out.println(m1.getKey() + "---" + m1.getValue());
}
for (Entry<String, String> m2 : map1.entrySet()) {
System.out.println(m2.getKey() + "---" + m2.getValue());
}
for (Entry<String, String> m3 : map1.entrySet()) {
System.out.println(m3.getKey() + "---" + m3.getValue());
}
}
}
}
注意: 以上代码好多没用的,我觉得最有用得就是 getDatanodeReport(); 所以我只说只一个,结果如下:
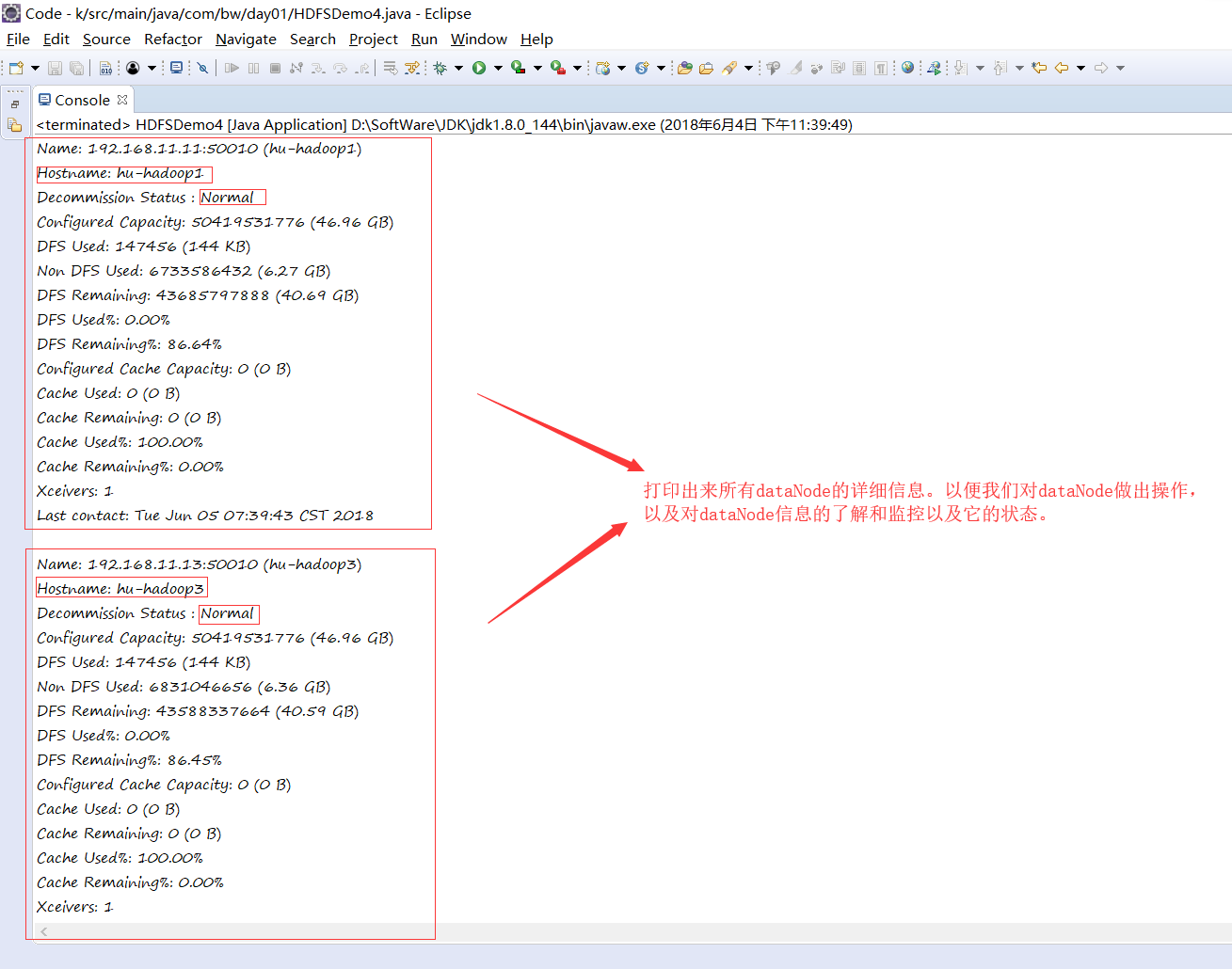
可以一眼就看出来它的用处了吧。
方式三:使用配置文件的方法+fs.newInstance(Conf):
这里的配置文件是从虚拟机上的hadoop/etc里面。分别为core.site.xml和hdfs-site.xml
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hu-hadoop1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/tmp</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.block.size</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoopdata/dfs/data</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///home/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///home/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hu-hadoop1:</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hu-hadoop2:</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
将这两个文件写入到src下:建一个HDFSDemo3 然后开始编码:
文件的删除1:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// hadoop路径
FileSystem fs = FileSystem.newInstance(conf);
// 本地得路径
LocalFileSystem localFileSystem = FileSystem.getLocal(conf);
// mkdir创建文件夹
Path path = new Path("/1708as1/hehe.txt");
if (fs.exists(path)) {
// fs.delete(path);默认递归删除
fs.delete(path, true);// false:不是递归 true:递归
System.out.println("------------------");
fs.mkdirs(new Path("/1708a1/f1.txt"));
} else {
fs.mkdirs(path);
System.out.println("------------------****");
}
}
创建一个文件并写入内容:

下载文件:
方法一:

方法二:

上传文件:
方式一:
方式二:
下载文件:
合并下载:
方法一:
package com.bw.day01; import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.io.IOUtils; import com.bw.day01.util.FSUtils; /**
* 合并下载
*
* @author huhu_k
*
*/
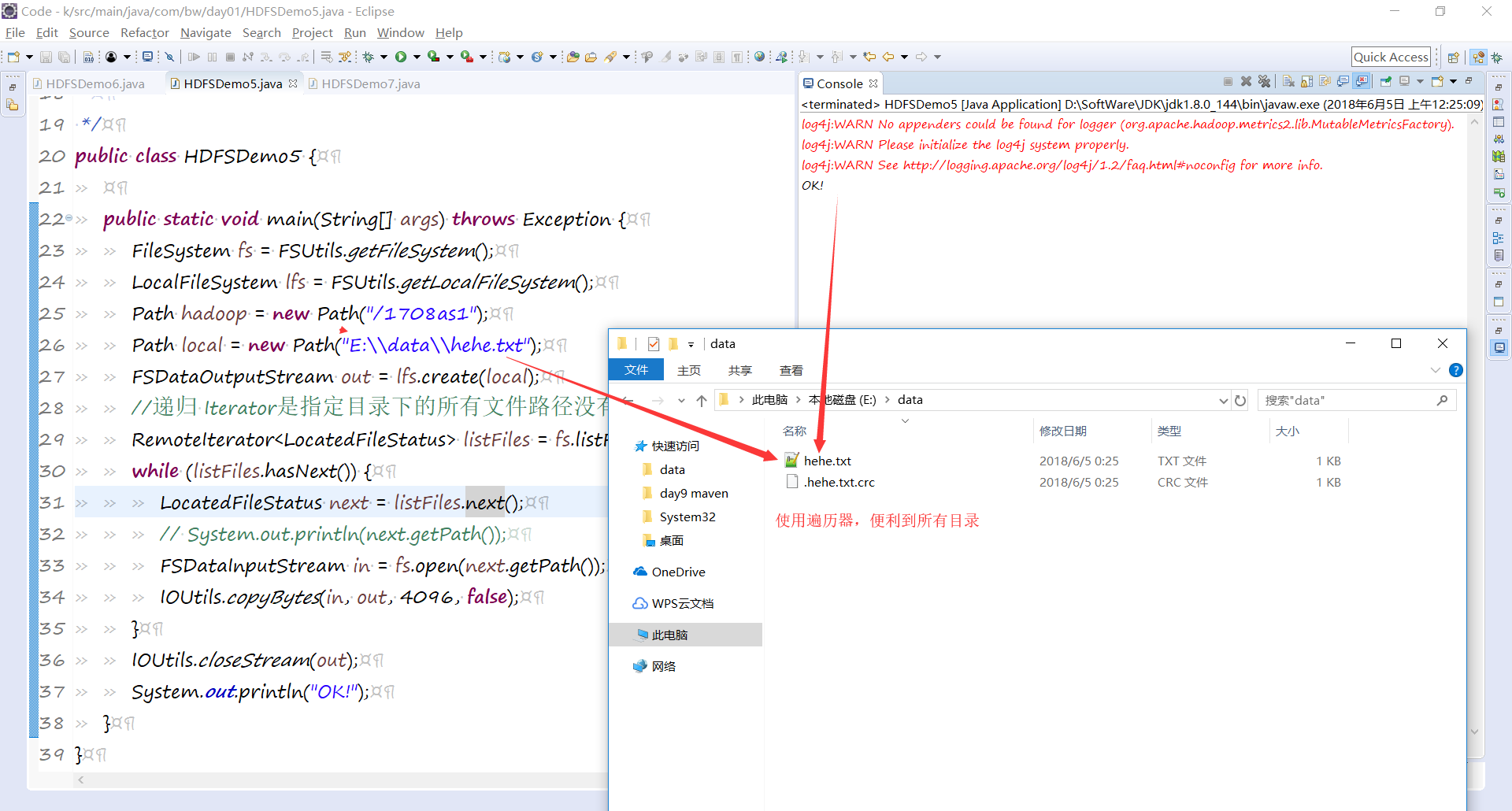
public class HDFSDemo5 { public static void main(String[] args) throws Exception {
FileSystem fs = FSUtils.getFileSystem();
LocalFileSystem lfs = FSUtils.getLocalFileSystem();
Path hadoop = new Path("/1708as1");
Path local = new Path("E:\\data\\hehe.txt");
FSDataOutputStream out = lfs.create(local);
//递归 Iterator是指定目录下的所有文件路径没有文件夹的
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(hadoop, true);
while (listFiles.hasNext()) {
LocatedFileStatus next = listFiles.next();
// System.out.println(next.getPath());
FSDataInputStream in = fs.open(next.getPath());
IOUtils.copyBytes(in, out, 4096, false);
}
IOUtils.closeStream(out);
System.out.println("OK!");
}
}
方法二:
package com.bw.day01; import java.util.ArrayList;
import java.util.List; import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; import com.bw.day01.util.FSUtils; /**
* 合并下载
*
* @author huhu_k
*
*/
public class HDFSDemo6 { static List<Path> list = new ArrayList<>(); public static void main(String[] args) throws Exception {
FileSystem fs = FSUtils.getFileSystem();
LocalFileSystem lfs = FSUtils.getLocalFileSystem();
Path hadoop = new Path("/1708as1");
Path local = new Path("E:\\data\\haha.txt");
copy(hadoop, fs);
FSDataInputStream in = null;
FSDataOutputStream out = lfs.create(local);
for (Path p : list) {
System.out.println(p.toString());
in = fs.open(p);
out.writeUTF("\n");
out.writeUTF("file:" + p.toString());
out.writeUTF("\n");
IOUtils.copyBytes(in, out, 4096, false);
}
IOUtils.closeStream(out);
} /**
* 使用递归得到文件所有目录
* @param hadoop
* @param fs
* @throws Exception
*/
public static void copy(Path hadoop, FileSystem fs) throws Exception {
FileStatus[] lFileStatus = fs.listStatus(hadoop);
for (FileStatus f : lFileStatus) {
if (fs.isDirectory(f.getPath())) {
// System.out.println("目录:" + f.getPath());
copy(f.getPath(), fs);
} else if (fs.isFile(f.getPath())) {
// System.out.println("wenjian:" + f.getPath());
list.add(f.getPath());
}
}
}
}
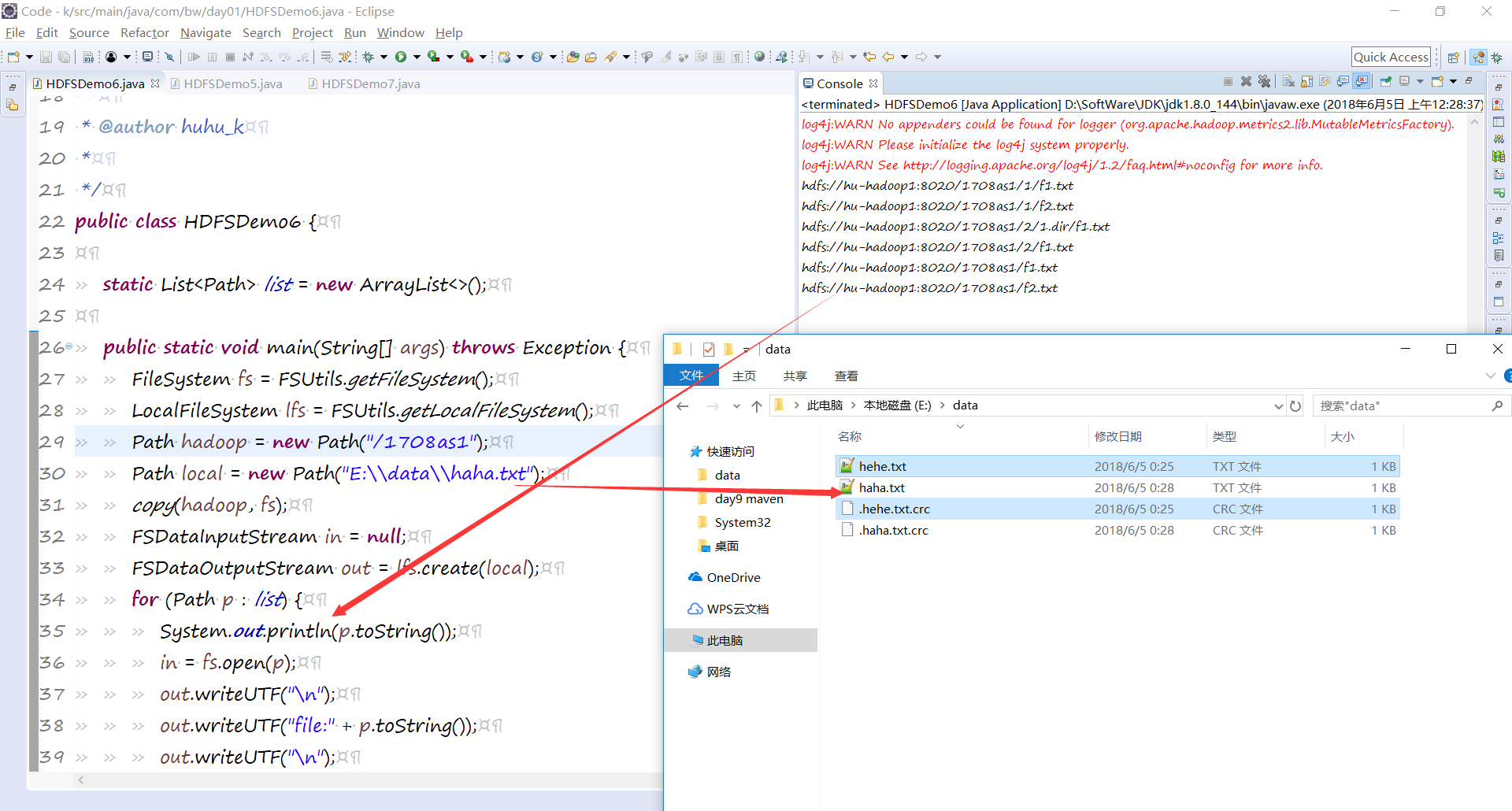
原样下载:
package com.bw.day01; import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path; import com.bw.day01.util.FSUtils; /**
* 原样下载
*
* @author huhu_k
*
*/
public class HDFSDemo7 { public static void main(String[] args) throws Exception {
FileSystem fs = FSUtils.getFileSystem();
LocalFileSystem lfs = FSUtils.getLocalFileSystem();
System.out.println("++++++++");
copey(new Path("/1708as1"), fs, lfs);
} public static void copey(Path path, FileSystem fs, LocalFileSystem lfs) throws Exception {
Path p = new Path("/");
FileStatus[] listStatus = fs.listStatus(path);
for (FileStatus l : listStatus) {
String[] str = l.getPath().toString().split("8020/1708as1");
if (fs.isDirectory(l.getPath())) {
if (str.length > 1) {
p = new Path(str[1]);
System.out.println(p + "---------------");
}
lfs.mkdirs(new Path("E:/data" + l.toString()));
copey(l.getPath(), fs, lfs);
} else if (fs.isFile(l.getPath())) {
if (str.length > 1) {
p = new Path("E:/data" + str[1]);
System.out.println(p.toString() + "---");
}
fs.copyToLocalFile(l.getPath(), p);
}
}
}
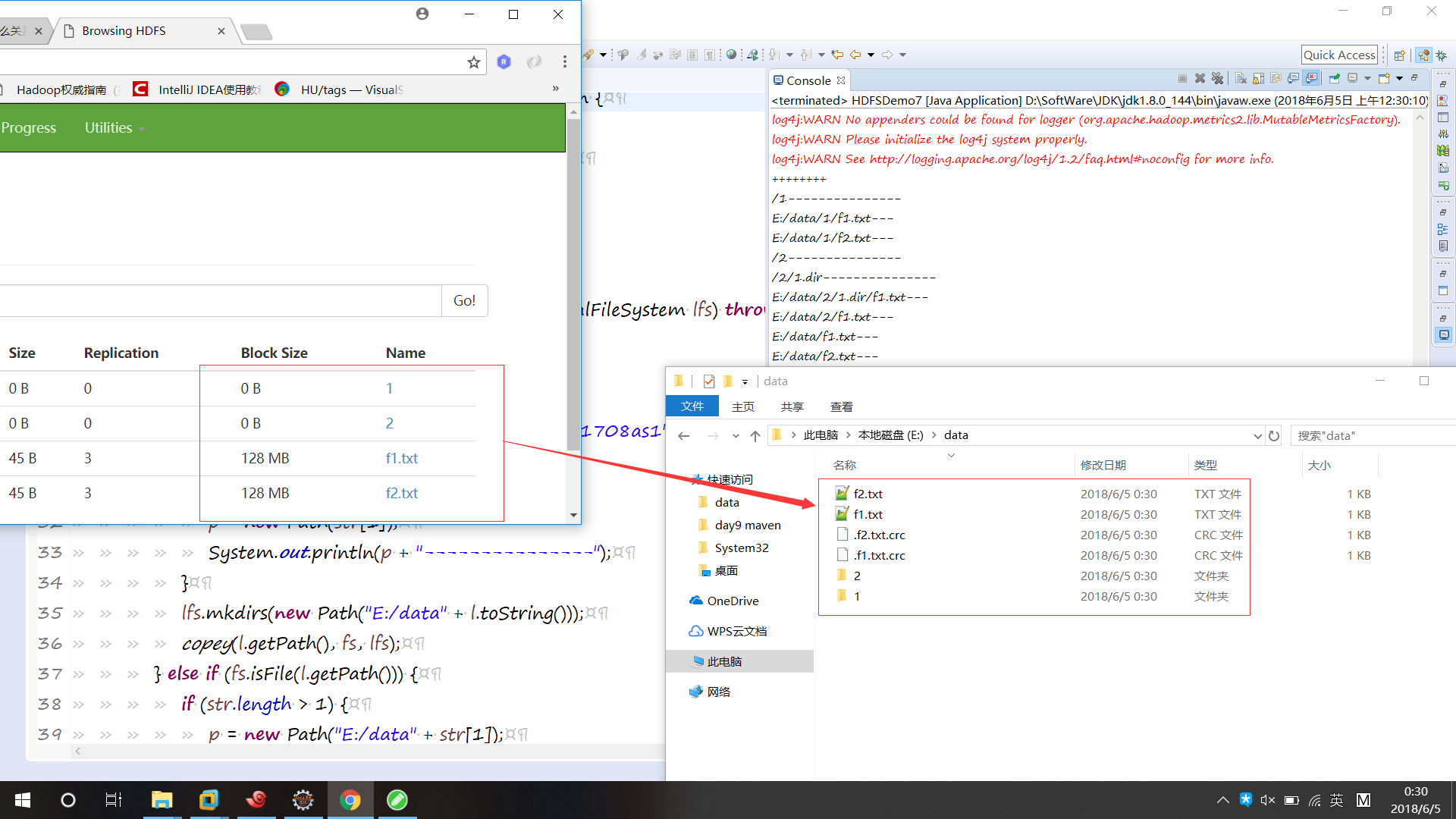
再加一個吧。
原文件上传:
package com.bw.day01; import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path; import com.bw.day01.util.FSUtils; /**
* 文件原样上传
*
* @author huhu_k
*
*/
public class HDFSDemo8 { public static void main(String[] args) throws Exception {
FileSystem fs = FSUtils.getFileSystem();
LocalFileSystem lfs = FSUtils.getLocalFileSystem();
System.out.println();
upLoadFile(new Path("E:\\data"), fs, lfs);
System.out.println("OK!!");
} public static void upLoadFile(Path path, FileSystem fs, LocalFileSystem fls) throws Exception {
Path p = new Path("/");
FileStatus[] listStatus = fls.listStatus(path);
for (FileStatus l : listStatus) {
String str1[] = l.getPath().toString().split("data");
String[] str2 = l.getPath().toString().split(":/");
String truePath = str2[1] +":/"+ str2[2];
if (fls.isDirectory(new Path(truePath))) {
if (str1.length > 1) {
p = new Path("/1708a1" + str1[1]);
}
fs.mkdirs(p);
System.out.println(p.toString() + "目录*****");
upLoadFile(l.getPath(), fs, fls);
} else if (fls.isFile(new Path(truePath))) {
if (str1.length > 1) {
p = new Path("/1708a1" + str1[1]);
}
fs.copyFromLocalFile(l.getPath(), p);
System.out.println(p.toString() + "文件*****");
}
}
}
}
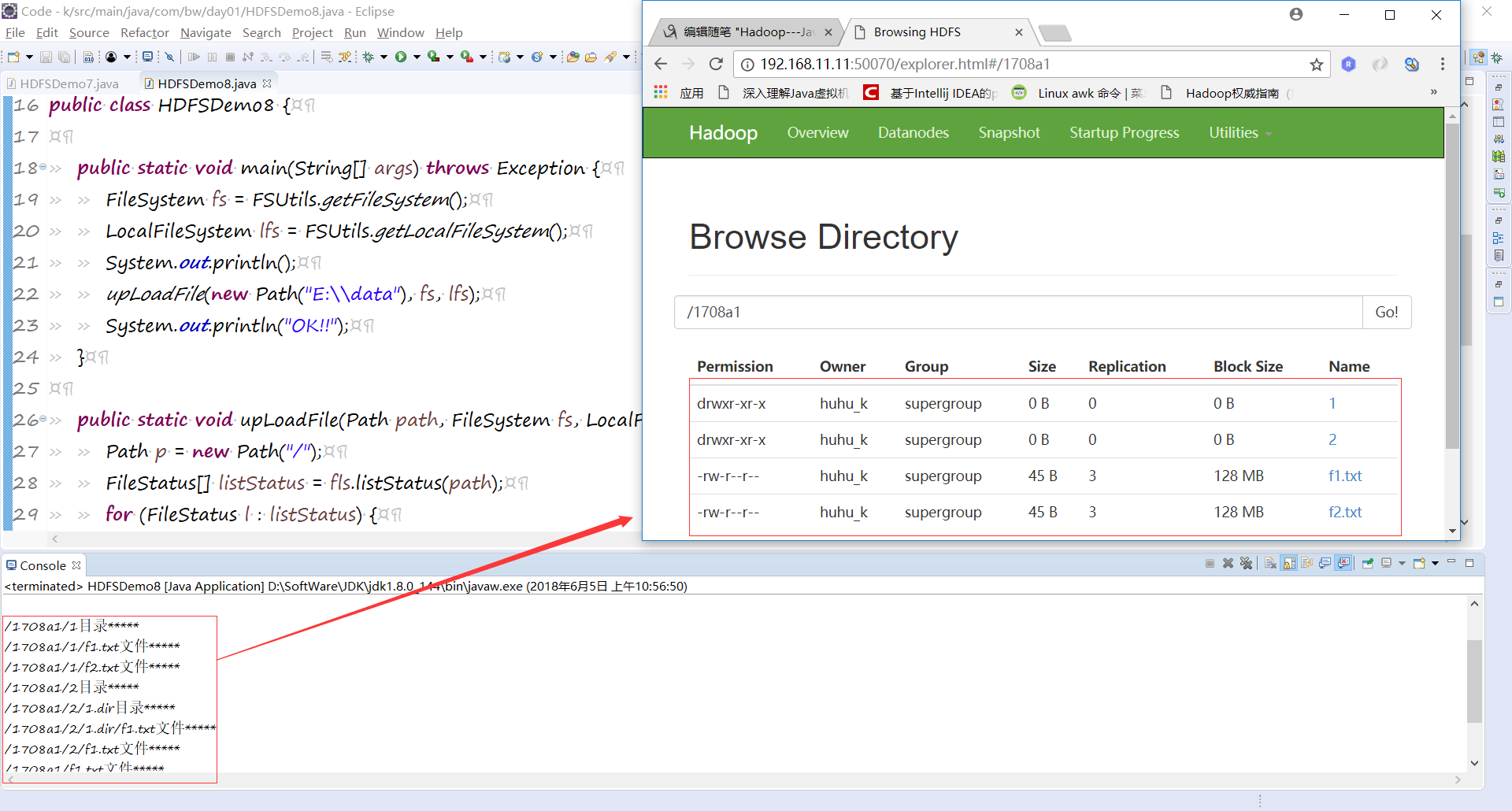
注意:
可能在运行时报指针异常!!!
可以参考以下链接解决:https://www.cnblogs.com/meiLinYa/p/9136771.html
还有在Java-API对hdfs操作时要开启服务 start-all-sh.
然后主要的都讲完了!!怎么样是波狗粮吧。。。。
huhu_L:深夜的狗粮吃的最撑哦!!!
Hadoop---Java-API对HDFS的操作的更多相关文章
- JAVA API 实现hdfs文件操作
java api 实现hdfs 文件操作会出现错误提示: Permission denied: user=hp, access=WRITE, inode="/":hdfs:supe ...
- hadoop的API对HDFS上的文件访问
这篇文章主要介绍了使用hadoop的API对HDFS上的文件访问,其中包括上传文件到HDFS上.从HDFS上下载文件和删除HDFS上的文件,需要的朋友可以参考下hdfs文件操作操作示例,包括上传文件到 ...
- JAVA API连接HDFS HA集群
使用JAVA API连接HDFS时我们需要使用NameNode的地址,开启HA后,两个NameNode可能会主备切换,如果连接的那台主机NameNode挂掉了,连接就会失败. HDFS提供了names ...
- 使用JAVA API读取HDFS的文件数据出现乱码的解决方案
使用JAVA api读取HDFS文件乱码踩坑 想写一个读取HFDS上的部分文件数据做预览的接口,根据网上的博客实现后,发现有时读取信息会出现乱码,例如读取一个csv时,字符串之间被逗号分割 英文字符串 ...
- Hadoop Java API 操作 hdfs--1
Hadoop文件系统是一个抽象的概念,hdfs仅仅是Hadoop文件系统的其中之一. 就hdfs而言,访问该文件系统有两种方式:(1)利用hdfs自带的命令行方式,此方法类似linux下面的shell ...
- HDFS的Java API 对文件的操作
在本次操作中所用到的命令 1.首先启动HDFS $HADOOP_HOME/sbin/start-dfs.sh 2.关防火墙 切换到root用户,执行service iptables stop 3.拷贝 ...
- Java API 读取HDFS的单文件
HDFS上的单文件: -bash-3.2$ hadoop fs -ls /user/pms/ouyangyewei/data/input/combineorder/repeat_rec_categor ...
- Java API —— IO流(数据操作流 & 内存操作流 & 打印流 & 标准输入输出流 & 随机访问流 & 合并流 & 序列化流 & Properties & NIO)
1.操作基本数据类型的流 1) 操作基本数据类型 · DataInputStream:数据输入流允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型.应用程序可以使用数据输出 ...
- HDFS的java接口——简化HDFS文件系统操作
今天闲来无事,于是把HDFS的基本操作用java写出简化程序出来给大家一些小小帮助! package com.quanttech; import org.apache.hadoop.conf.Conf ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
随机推荐
- Terminal run py文件
cd Documents cd PythonCode python3 hello.py Text Editor: Atom Atom 可以用来写 python 脚本 (文件后缀名 .py). 但是不用 ...
- python学习打卡 day07 set集合,深浅拷贝以及部分知识点补充
本节的主要内容: 基础数据类型补充 set集合 深浅拷贝 主要内容: 一.基础数据类型补充 字符串: li = ["李嘉诚", "麻花藤", "⻩海峰 ...
- ECharts配置项之title(标题)
1.标题居中 //left的值为'left', 'center', 'right' title:{ left:'center' } 2.主副标题之间的间距 title:{ //默认为10 itemGa ...
- 力扣(LeetCode)1.两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个数组中同样的元 ...
- es6 export 和export default的区别
区别 export 每个文件中可使用多次export命令 import时需要知道所加载的变量名或函数名 import时需要使用{},或者整体加载方法 export export default 每个文 ...
- MySQL学习(八)
连接查询 1 集合的特点:无序性,唯一性 集合的运算:求并集,求交集,求笛卡尔积 表和集合的关系 一张表就是一个集合,每一行就是一个元素 疑问:集合不能重复,但我有可能两行数据完全一样 答:mysql ...
- Qt中的角度转弧度
在Qt中,qAsin(),qAtan2()等三角函数的返回值是弧度而不是角度,因此要将弧度转化为角度. 弧度=角度*Pi/180 以qAtan()函数为例 qreal qAtan(qreal v) R ...
- 使用git命令行解决冲突
文章转载自:https://blog.csdn.net/sureSand/article/details/78765727 使用git和提交的代码有所冲突,用IDE自带的git工具功能多了反而不知道怎 ...
- Codeforces 958C3 - Encryption (hard)
C3 - Encryption (hard) 思路: 记sum[i]表示0 - i 的和对 p 取模的值. 1.如果k * p > n,那么与C2的做法一致,O(k*p*n)复杂度低于1e8. ...
- 最大频率栈 Maximum Frequency Stack
2018-10-06 22:01:11 问题描述: 问题求解: 为每个频率创建一个栈即可. class FreqStack { Map<Integer, Integer> map; Lis ...