Scrapy学习篇(一)之框架
概览
在具体的学习scrapy之前,我们先对scrapy的架构做一个简单的了解,之后所有的内容都是基于此架构实现的,在初学阶段只需要简单的了解即可,之后的学习中,你会对此架构有更深的理解。
下面是scrapy官网给出的最新的架构图示。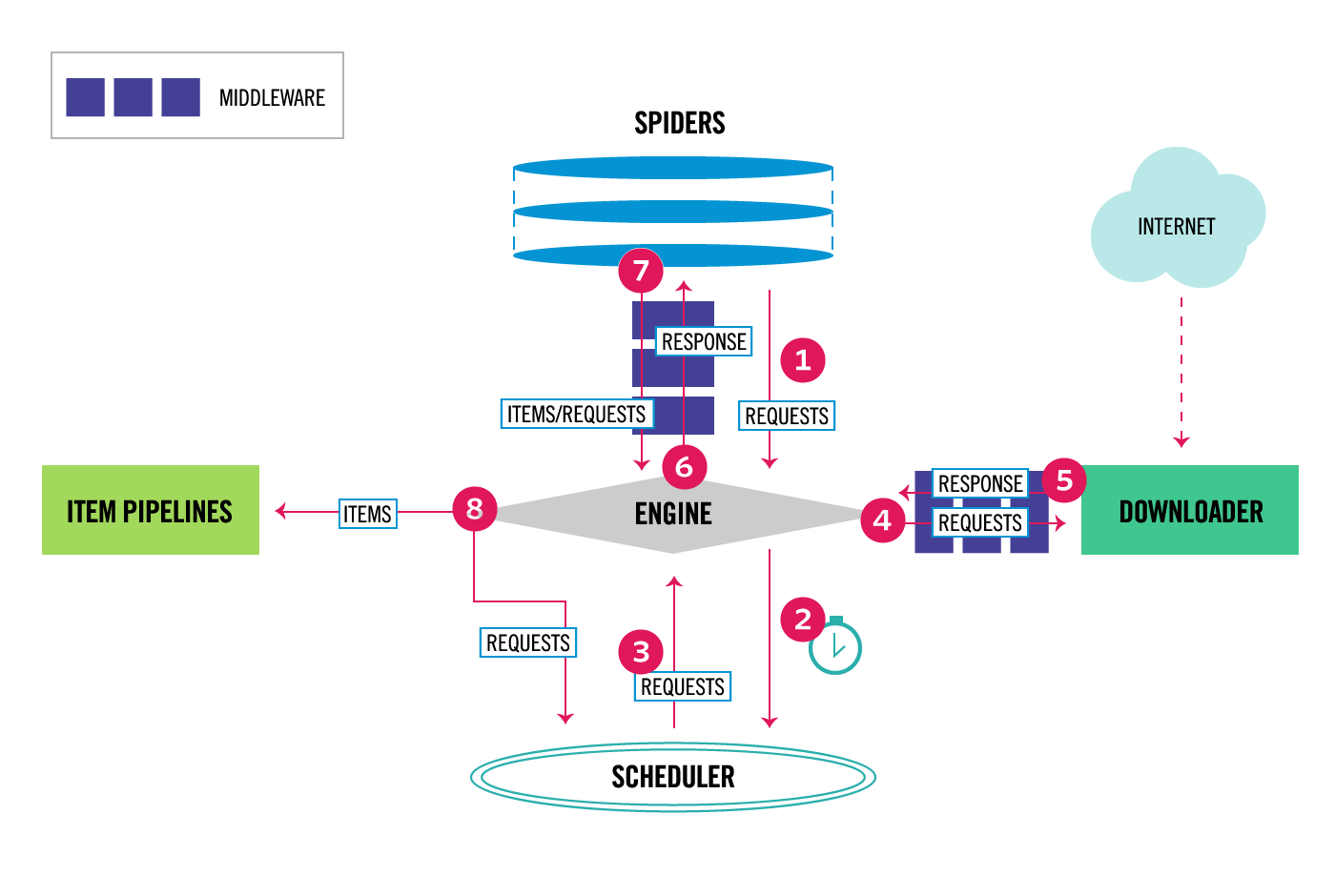
基本组件
引擎(Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
爬虫(Spiders)
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流向
Scrapy的数据流由执行引擎(Engine)控制,其基本过程如下:
- 引擎从Spider中获取到初始Requests。
- 引擎将该Requests放入调度器,并请求下一个要爬取的Requests。
- 调度器返回下一个要爬取的Requests给引擎
- 引擎将Requests通过下载器中间件转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item交给ItemPipeline处理,将(Spider返回的)Request交给调度器,并请求下一个Requests(如果存在的话)。
- (从第一步)重复直到调度器中没有更多地Request。
总结
Scrapy的各个组件相互配合执行,有的组件负责任务的调度,有的组件负责任务的下载,有的组件负责数据的清洗保存,各组件分工明确。在组件之间存在middleware的中间件,其作用就是功能的拓展,当然还可以根据自身的需求自定义这些拓展功能,比如我们可以在Downloader middlewares里面实现User-Agent的切换,Proxy的切换等等。这些功能我们会在后续的学习中逐渐拓展。这里只需要大致的了解即可。
Scrapy学习篇(一)之框架的更多相关文章
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy学习篇(四)之数据存储
上一篇中,我们简单的实现了toscrapy网页信息的爬取,并存储到mongo,本篇文章信息看看数据的存储.这一篇主要是实现信息的存储,我们以将信息保存到文件和mongo数据库为例,学习数据的存储,依然 ...
- (转载)OC学习篇之---Foundation框架中的其他类(NSNumber,NSDate,NSExcetion)
前一篇说到了Foundation框架中的NSDirctionary类,这一一篇来看一下Foundation的其他常用的类:NSNumber,NSDate,NSException. 注:其实按照Java ...
- (转载)OC学习篇之---Foundation框架中的NSDirctionary类以及NSMutableDirctionary类
昨天学习了Foundation框架中NSArray类和NSMutableArray类,今天来看一下Foundation框架中的NSDirctionary类,NSMutableDirctionary类, ...
- (转载)OC学习篇之---Foundation框架中的NSArray类和NSMutableArray类
在之前的一篇文章中介绍了Foundation框架中的NSString类和NSMutableString类,今天我们继续来看一下Foundation框架中的NSArray类和NSMutableArray ...
- (转载)OC学习篇之---Foundation框架中的NSString对象和NSMutableString对象
在之前的一篇文章中我们说到了Foundation框架中的NSObject对象,那么今天在在来继续看一下Foundation框架中的常用对象:NSString和NSMutableString. 在OC中 ...
- (转载)OC学习篇之---Foundation框架中的NSObject对象
前一篇文章讲到了OC中的代理模式,而且前几篇文章就介绍了OC中的类相关知识,从这篇文章开始我们开始介绍Foundation框架. OC中的Foundation框架是系统提供了,他就相当于是系统的一套a ...
- Scrapy学习篇(十二)之设置随机IP代理(IPProxy)
当我们需要大量的爬取网站信息时,除了切换User-Agent之外,另外一个重要的方式就是设置IP代理,以防止我们的爬虫被拒绝,下面我们就来演示scrapy如何设置随机IPProxy. 设置随机IPPr ...
随机推荐
- Python基础练习及答案
1.请用代码实现:利用下划线将列表的每一个元素拼接成字符串,li=['alex', 'eric', 'rain'] 该题目主要是考的字符串的拼接,join方法, s = "" li ...
- java 自带的工具
前辈说,java的基本功的好坏,一个方面要看是否能熟练使用jdk bin下的工具使用情况. 自己整理一下使用的工具. ■ javac 一个编译java的工具,进入java所在文件的路径后,javac ...
- 堆栈详解 + 彻底理解Java的值传递和引用传递
本文旨在用最通俗的语言讲述最枯燥的基本知识 学过Java基础的人都知道:值传递和引用传递是初次接触Java时的一个难点,有时候记得了语法却记不得怎么实际运用,有时候会的了运用却解释不出原理,而且坊间讨 ...
- LeetCode - Reorganize String
Given a string S, check if the letters can be rearranged so that two characters that are adjacent to ...
- apache kafka系列之在zookeeper中存储结构
1.topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 Schema: { "version": ...
- skipper http router 简单试用
说明: 使用源码编译,注意需要FQ,以及golang版本的问题,新版使用的是go mod 进行依赖管理 环境准备 clone 代码 git clone https://github.com/zalan ...
- 主机-配件-接口-整机-3c-2
pc机,服务器,智能手机与各种嵌入式乃至物联网 http://www.mifalife.net/hk/mall.html MIFA F5 户外无线蓝牙音箱2.0声道高保真可通话插卡便携低音炮迷你iph ...
- [转]linux中vim命令
在vi中按u可以撤销一次操作 u 撤销上一步的操作 ctrl+r 恢复上一步被撤销的操作 在vi中移动光标至: 行首:^或0 行尾:$ 页首:1G(或gg) 页尾:G(即shift+g) 显 ...
- 3个问题:MySQL 中 character set 与 collation 的理解;utf8_general_ci 与 utf8_unicode_ci 区别;uft8mb4 默认collation:utf8mb4_0900_ai_ci 的含义
MySQL 中 character set 与 collation 的理解 出处:https://www.cnblogs.com/EasonJim/p/8128196.html 推荐: 编码使用 uf ...
- TweenMax 动画库,知识点
官方地址:https://greensock.com/tweenmax github 地址:https://github.com/greensock/GreenSock-JS 比较好的介绍文章: ht ...