Scala集合(二)
将函数映射到集合
map方法
val names = List("Peter" , "Paul", "Mary")
names.map(_.toUpperCase) // 等同于 for(n <- names) yield n.toUpperCase
flatMap方法,如果函数产出一个集合,又想将所有值串联在一起
def ulcase(s:String) = Vector(s.toUpperCase(), s.toLowerCase())
names.map(ulcase)得到
List(Vector("PETER","peter"), Vector("PAUL","paul"), Vector("MARY","mary"))
names.flatMap(ulcase)得到
List("PETER","peter","PAUL","paul","MARY","mary")
collect 方法用于 partial function,那些并没有对所有可能的输入值进行定义的函数, 产出被定义的所有参数的函数值得集合
"-3+4".collect(case '+' -> ; case '-' -> -) // vector(-1,1)
foreach方法
names.foreach(println)
化简、折叠和扫描
List(,,,).reduceLeft(_ - _)
( ( - ) - ) - = - - - = -
List(,,,).reduceRight(_ - _)
- ( - ( - ) ) = - + - = -
以不同首元素开始计算
List(,,,).foldLeft()(_ - _)
---- = -
List(,,,).foldLeft(" ")(_ + _) // 由柯里化判断第二个参数类型定义(String, Int) => String
" " + + ++ = ""
( /: List(,,,))(_ - _) // /: 操作符代替了foldLeft操作
Scala 也提供了foldRight 和 :\的变体
折叠有时可以代替循环,比如计算字母出现频率
val freq = scala.collection.mutable.Map[Char, Int]() // 可变映射
for( c <- "Mississippi")
freq(c) =freq.getOrElse(c,)+ // Map('i' ->4, 'M' -> 1, 's' -> 4, 'p' ->2)
折叠实现
(Map[Char, Int]() /:"Mississippi"){
(m,c) => m + (c -> (m.getOrElse(c,) +)
}// 这里的 Map是不可变,每次计算出一个新的Map
scanLeft,scanRight, 得到包含所有中间结果的集合
( to ).scanLeft()(_ + _)
Vector(,,,,,,,,,,)
拉链操作
zip
val prices = List(5.0,20.0,9.95) // 价格
val quantities = List(,,) //数量
prices zip quantities 得到一个List[(Double, Int)] , 一个个对偶的列表
List[(Double, Int)] = List( (5.0, ), (20.0, ), (9.95, ))
计算总价
((prices zip quantities) map {p => p._1 * p._2}) sum
如果两个集合数量不一致
List( 5.0, 20.0, 9.95 ) zip List(, ) // List((5.0, 10), (20.0, 2))
zipAll 指定短列表的缺省值:第二个参数补充左边,第三个参数补充右边
List(,).zipAll(List(),,) // List((1,2),(1,7))
List().zipAll(List(,),,)// List((1,2), (3,6))
zipWithIndex, 返回对偶列表,第二个组成部分是元素下标
"Scala".zipWithIndex // Vector(('S',0),('c',1),('a',2),('l',3),('a',4))
求最大编码的值得下标为
"Scala".zipWithIndex.max._2
迭代器 (相对于集合而言是一个“懒”的替代品,只有在需要时才去取元素,如果不需要更多元素,不会付出计算剩余元素的代价)
对于那些完整构造需要很大开销的集合,适合用迭代器 如Source.fromFile产出一个迭代器,因为整个文件加载进内存不高效。 迭代器的两种用法 while(iter.hasNext) iter.next() for(elem <- iter) 对elem操作 上述两种循环都会讲迭代器移动到集合末端,不能再被使用, 调用 map filter count sum length方法后, 迭代器也会位于集合的末端,不能使用 find 或 take ,迭代器位于找到的元素之后
流(stream)
迭代器每次调用next都会改变指向,
如果要缓存之前的值,可以使用流
流是一个尾部被懒计算的不可变列表,也就是说只有需要时才计算
def numsForm(n:BigInt) : Stream[BigInt] = n #:: numsForm(n+) // #:: 操作符 构建出来的是一个流
var tenOrMore = numsForm() // Stream(10,?), 其尾部是未被求值得
tenOrMore.tail.tail.tail // Stream(13,?)
val squares = numsForm().map{ x=> x*x) // Stream(1,?)
take 可以一次获得多个值, force强制求值
squares.take().force // Stream(1,4,9,16,25)
squares.force // 会尝试对一个无穷流的所有成员求值,最后OutOfMemoryError
迭代器可以用来构造一个流
Source.getLines返回一个Iterator[String],用这个迭代器,对于每一行只能访问一次,而流将缓存访问过的行,允许重新访问
val words = Sourcce.fromFile("/usr/share/dict/words").getLines.toStream
words // Stream(A, ?)
words() // Aachen
words // Stream(A, A'o, AOL, AOL's, Aachen, ?)
懒视图(应用于集合)
类似流的懒理念 与流的不同 、连第一个元素都不会求值 、不会缓存求过的值 val powers = ( unti ).view.map(pow(,_)) powers() // pow(10,100)被计算,其他值未计算,同时也不缓存,下次pow(10,100)将重新计算 force方法可以对懒视图强制求值,得到与原集合相同类型的新集合, 懒视图的好处:可以避免在多种变换下产生的中间集合 ( to ).map(pow(,_)).map(/_) //先第一个map,再第二个map, 构建了一个中间集合 ( to ).view.map(pow(,_)).map(/_).force // 记住两个map操作,每个元素被两个操作同时执行,不需要额外构中间集合
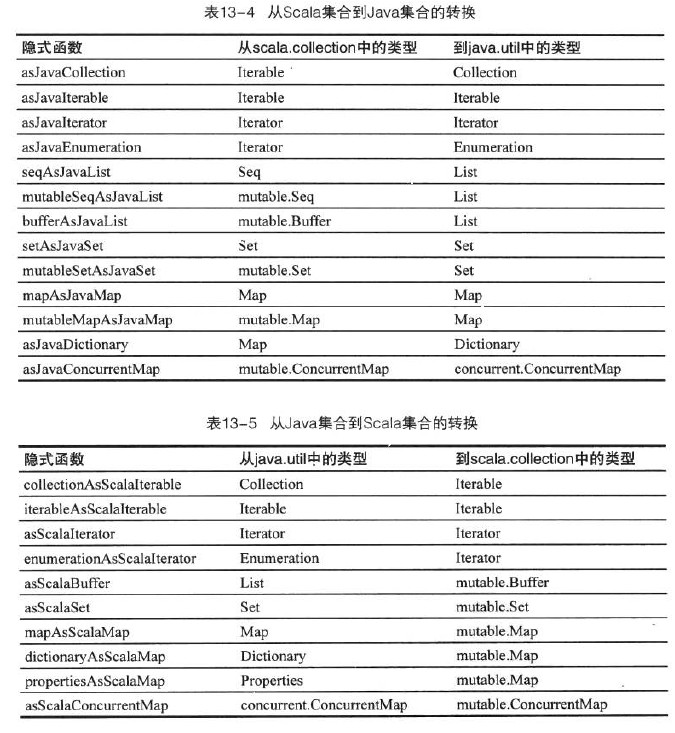
与Java集合的互操作
import scala.collection.JavaConversions._
val props:scala.collection.mutable.Map[String,String] = System.getProperties()
如果担心那些不需要的隐式转换也被引入的话,只引入需要的即可
import scala.collection.JavaConversions.propertiesAsScalaMap
这些转换产出的是包装器,让你可以使用目标接口来访问原本的值
props("name") = "clat" //props既是包装器
包装器将调用底层Properties对象的put("name","clat")
线程安全的集合
Scala类库提供了六个特质,将他们混入集合,让集合的操作变成同步 SynchromizedBuffer SynchromizedMap SynchromizedPriorityQueue SynchromizedQueue SynchromizedSet SynchromizedStack val scores =new scala.collection.collection.mutable.HashMap[String, Int] with scala.collection.mutalbe.SynchronizzedMap[String,Int] 注:这里可以确保scores不会被破坏,任何操作都必须先完成,其他线程才可执行另一个操作。但并发修改和遍历集合并不安全。 通常来说,最好使用java.util.concurrent包中的类.
并行集合
为了更好利用计算机的多个处理器,支持并发通常是必需的 如果coll是个大型集合,那么 coll.par.sum //并发求和,par方法产出当前集合的一个并行实现,该实现会尽可能地并行执行集合方法 coll.par.count(_ % ==) //计算偶数的数量 对数组、缓冲、哈希表、平衡树而言,并行实现会直接重用底层实际集合的实现,所以很高效。 可以通过对要遍历的集合应用.par并行化for循环 for( i <- ( until ).par) print( i + " " ) //数字是按照作用于该任务的线程产出的顺序输出 在for/yield循环中,结果是依次组装的 for( i <- ( until ).par) yield i +" " par返回的并行集合扩展自ParSeq ParSet Parmap,都是ParIterable的子类型,不是Iterable的子类型,所以不能将并行集合传递给预期Iterable Seq Set Map的方法。 可以用ser方法将并行集合转换回串行的版本。
只有可以自由结合的操作 可以用平行集合 (a op b) op c = a op( b op c), 加是可自由结合的 (a -b ) -c != a - (b -c) 减法不是自由结合 有一个fold方法对集合的不同部分进行操作,但是不像foldLeft和foldRight那样灵活, 该操作符的两个操作元都必须是集合的元素类型,要求fold的参数类型与集合元素一样,不像上面foldLeft,参数是String, 集合是Int 那样 coll.par.fold()(_ + _) aggregate方法,可以解决上面的问题,该操作符应用于集合的不同部分,然后再用你另一个操作符组合结果 str.par.aggregate(Set[Char]())(_ + _, _ ++ _) //等同于 str.foldLeft(Set[Char]())(_ + _) 产出一个str中所有不同字符的集
Scala集合(二)的更多相关文章
- Scala集合类型详解
Scala集合 Scala提供了一套很好的集合实现,提供了一些集合类型的抽象. Scala 集合分为可变的和不可变的集合. 可变集合可以在适当的地方被更新或扩展.这意味着你可以修改,添加,移除一个集合 ...
- Scala学习(二)--- 控制结构和函数
控制结构和函数 摘要: 本篇主要学习在Scala中使用条件表达式.循环和函数,你会看到Scala和其他编程语言之间一个根本性的差异.在Java或C++中,我们把表达式(比如3+4)和语句(比如if语句 ...
- Scala函数式编程(三) scala集合和函数
前情提要: scala函数式编程(二) scala基础语法介绍 scala函数式编程(二) scala基础语法介绍 前面已经稍微介绍了scala的常用语法以及面向对象的一些简要知识,这次是补充上一章的 ...
- Scala集合操作
大数据技术是数据的集合以及对数据集合的操作技术的统称,具体来说: 1.数据集合:会涉及数据的搜集.存储等,搜集会有很多技术,存储技术现在比较经典方案是使用Hadoop,不过也很多方案采用Kafka. ...
- Spark:scala集合转化为DS/DF
scala集合转化为DS/DF case class TestPerson(name: String, age: Long, salary: Double) val tom = TestPerson( ...
- Scala集合常用方法解析
Java 集合 : 数据的容器,可以在内部容纳数据 List : 有序,可重复的 Set : 无序,不可重复 Map : 无序,存储K-V键值对,key不可重复 scala 集合 : 可变集合( ...
- Scala集合笔记
Scala的集合框架类比Java提供了更多的一些方便的api,使得使用scala编程时代码变得非常精简,尤其是在Spark中,很多功能都是由scala的这些api构成的,所以,了解这些方法的使用,将更 ...
- Scala集合(一)
Scala集合的主要特质 Iterator,用来访问集合中所有元素 val coll = ... // 某种Iterable val iter = col.iterator while(iter.ha ...
- 再谈Scala集合
集合!集合!一个现代语言平台上的程序员每天代码里用的最多的大概就是该语言上的集合类了,Scala的集合丰富而强大,至今无出其右者,所以这次再回过头再梳理一下. 本文原文出处: 还是先上张图吧,这是我 ...
随机推荐
- VIM 的帮助文档在哪里?看这里。
我一直奇怪,像VIM这么优秀的软件怎么就没有个详细的文档. 再优秀,新手不会用也是白搭啊.再说,谁生下来就是老手么? 只有那个简单的tutor么? 虽说看了这个tutor也能用了,但作为“编辑器之神” ...
- vue 本地开发时使用localhost与ip访问
修改config文件夹下面的index.js配置,将localhost改为0.0.0.0就可以了.用ip,127.0.0.1,localhost均行 host: '0.0.0.0', // can b ...
- mui---自定义页面打开的方向
在使用MUI做APP的时候,会考虑对页面的打开方向做规定,MUI也给我们提供了很多种页面的打开方式. 具体参考: http://ask.dcloud.net.cn/question/174 MUI做A ...
- Codeforces 670E - Correct Bracket Sequence Editor - [对顶栈]
题目链接:https://codeforces.com/contest/670/problem/E 题意: 给出一个已经匹配的括号串,给出起始的光标位置(光标总是指向某个括号). 有如下操作: 1.往 ...
- HDU 5954 - Do not pour out - [积分+二分][2016ACM/ICPC亚洲区沈阳站 Problem G]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5954 Problem DescriptionYou have got a cylindrical cu ...
- git commit -m 与 git commit -am的区别
字面解释的话,git commit -m用于提交暂存区的文件:git commit -am用于提交跟踪过的文件 要理解它们的区别,首先要明白git的文件状态变化周期,如下图所示 工作目录下面的所有文件 ...
- Sharding与数据库分区(Partition) 分表、分库、分片和分区
Sharding与数据库分区(Partition) http://blog.sina.com.cn/s/blog_72ef7bea0101cjtb.html https://www.2cto.com/ ...
- 业界微服务楷模Netflix是这样构建微服务技术架构的
1. 如不考虑组织架构,直接切入技术架构(很多架构师的通病),则失败风险巨大. https://mp.weixin.qq.com/s/C8Rdz9wFtrBKfxPRzf0OBQ
- xcode工程编译错误:error: Couldn’t materialize
错误信息: error: Couldn't materialize: couldn't get the value of variable amount: variable not available ...
- Window ferformance toolkit 学习
1.环境配置 2.内存泄露 a. 编写自己的wprp文件: http://msdn.microsoft.com/en-us/library/hh448223.aspx b.启动 @echo off s ...