python urllib2 支持 自定义cookie
首先需要2个软件来抓包。
fiddler : http 代理软件可以分析,抓包,重放。
wireshark : 全能抓包分析软件。
RFC 提供了非常好的设计描述。
https://tools.ietf.org/html/rfc7230
https://tools.ietf.org/html/rfc7231
安装好
Fiddler2
Tools ->Fiddler Options…-> Connections
Allow remotecomputers toconnect
需要重启 Fiddler2 后生效
Wireshark
设置好抓包规则
tcp.port == 8888
全部设置好后,使用另外一台电脑,配置好浏览器,打开下面的测试地址:
https://www.baidu.com/img/bd_logo1.png
最好是,在2台电脑上进行,有IP 地址比较好分辩(没有2台电脑的用VM 也行)。
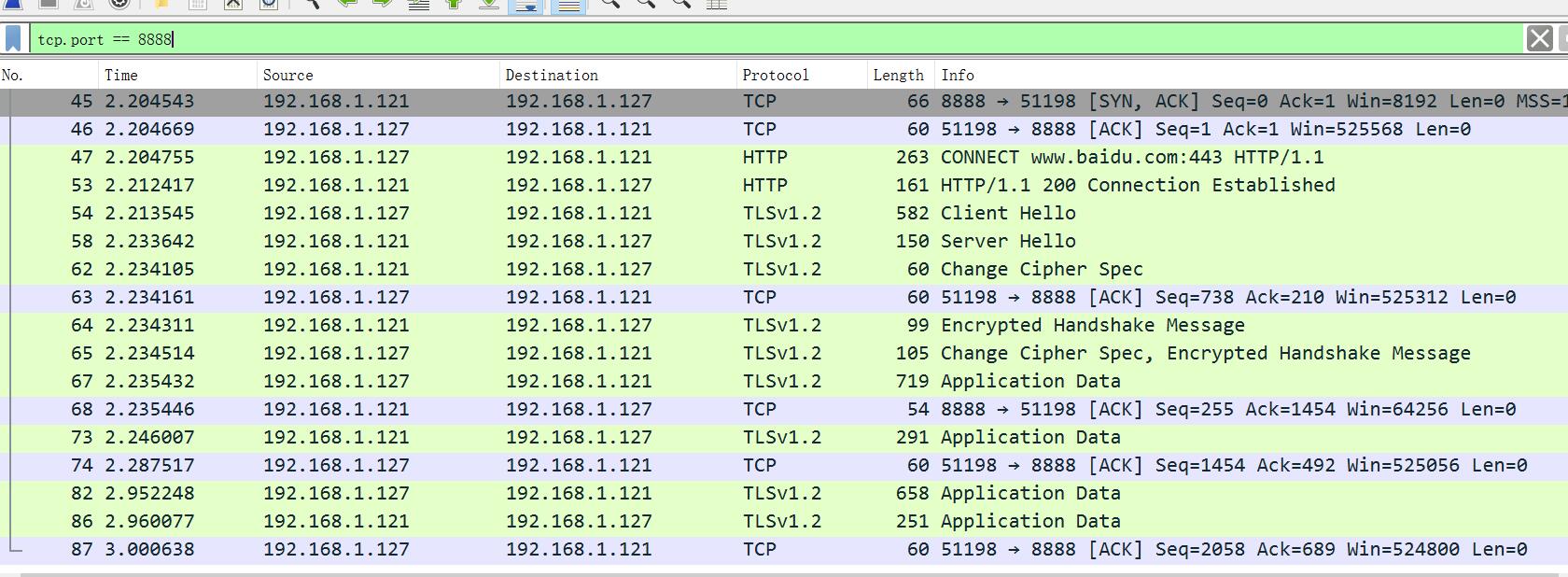
本机为 192.168.1.127 , Fiddler 为 192.168.1.121。
可以看到,本地在发送了一个 请求头后,直接和 192.168.1.121 进行了 TLS 协商。
可见 HTTPS 代理也是非常容易实现。
TCP 流:

或者使用 curl 进行测试,firefox 自带了很多垃圾请求,不太好分辨包。
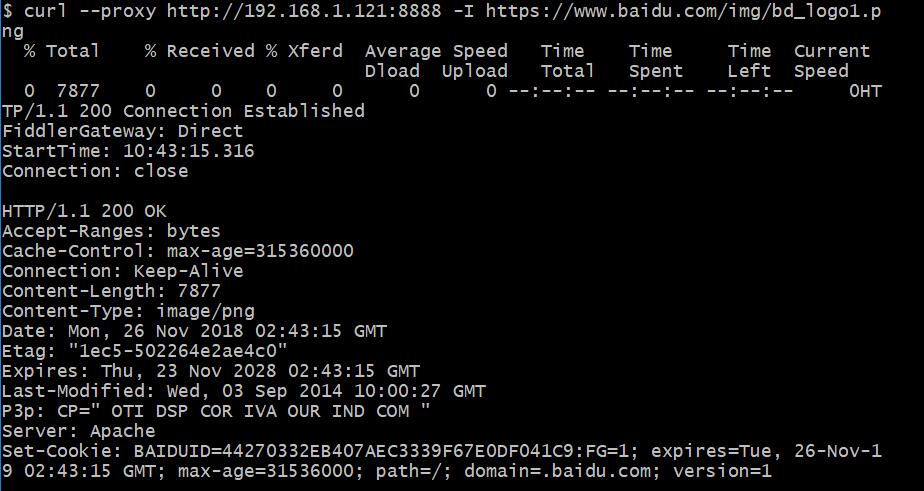
可见 百度用的是 apache 的服务器。
建立一个 连接到目标站点的 https socket。
回复 HTTP/1.1 200 Connection Established
浏览器发过来 client hello ,转发给 https socket
普通的 HTTP 是 请求 响应模式。
而 HTTPS 是有可能 HTTPS 也会主动发送 tcp 数据包过来,如 server hello 。
所以实现上,还需要用到 select 来实现 fd 的检查工作。
#!/usr/bin/env python
#coding:utf-8
import socket
import sys
import re
import os
import time
import select
import threading HEADER_SIZE = 4096 host = '0.0.0.0'
port = 8000 #子进程进行socket 网络请求
def http_socket(client, addr):
#创建 select 检测 fd 列表
inputs = [client]
outputs = []
remote_socket = 0
print("client connent:{0}:{1}".format(addr[0], addr[1]))
while True:
readable, writable, exceptional = select.select(inputs, outputs, inputs)
try:
for s in readable:
if s is client:
#读取 http 请求头信息
data = s.recv(HEADER_SIZE)
if remote_socket is 0:
#拆分头信息
host_url = data.split("\r\n")[0].split(" ")
method, host_addr, protocol = map(lambda x: x.strip(), host_url)
#如果 CONNECT 代理方式
if method == "CONNECT":
host, port = host_addr.split(":")
else:
host_addr = data.split("\r\n")[1].split(":")
#如果未指定端口则为默认 80
if 2 == len(host_addr):
host_addr.append("")
name, host, port = map(lambda x: x.strip(), host_addr)
#建立 socket tcp 连接
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, int(port)))
remote_socket = sock
inputs.append(sock)
if method == "CONNECT":
start_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
s.sendall("HTTP/1.1 200 Connection Established\r\nFiddlerGateway: Direct\r\nStartTime: {0}\r\nConnection: close\r\n\r\n".format(start_time))
continue
#发送原始请求头
remote_socket.sendall(data)
else:
#接收数据并发送给浏览器
resp = s.recv(HEADER_SIZE)
if resp:
client.sendall(resp)
except Exception as e:
print("http socket error {0}".format(e)) #创建socket对象
http_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
http_server.bind((host, port))
except Exception as e:
sys.exit("python proxy bind error {0}".format(e)) print("python proxy start") http_server.listen(1024) while True:
client, addr = http_server.accept()
http_thread = threading.Thread(target=http_socket, args=(client, addr))
http_thread.start()
time.sleep(1) #关闭所有连接
http_server.close()
print("python proxy close")
python urllib2 支持 自定义cookie的更多相关文章
- python urllib2模块携带cookie
今天干活遇到一个事.有一些网站的一些操作非得要求你登陆才能做,比如新浪微博,你要随便看看吧,不行,非得让你登陆了才能看,再比如一些用户操作,像更改自己的资料啦,个人的隐私啦巴拉巴拉的.想抓取这样的ur ...
- python之路-----django 自定义cookie签名
1.默认自定义cookie 在使用扩展签名时,会根据settings 配置中的 SIGNING_BACKEND 来运行加密方法,默认使用 django.core.signing.TimestampS ...
- python urllib2使用细节
刚好用到,这篇文章写得不错,转过来收藏. 转载自 道可道 | Python 标准库 urllib2 的使用细节 Python 标准库中有很多实用的工具类,但是在具体使用时,标准库文档上对使用细节 ...
- python urllib2 模拟网站登陆
python urllib2 模拟网站登陆 1. 可用浏览器先登陆,然后查看网页源码,分析登录表单 2. 使用python urllib2,cookielib 模拟网页登录 import urllib ...
- python urllib2详解及实例
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件.他以urlopen函数的形式提供了一个非常简单的接口, 这是具有利用不同协议获取URLs的能 ...
- python urllib2介绍
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件.他以urlopen函数的形式提供了一个非常简单的接口, 这是具有利用不同协议获取URLs的能 ...
- python urllib2使用心得
python urllib2使用心得 1.http GET请求 过程:获取返回结果,关闭连接,打印结果 f = urllib2.urlopen(req, timeout=10) the_page = ...
- Python urllib2写爬虫时候每次request open以后一定要关闭
最近用python urllib2写一个爬虫工具,碰到运行一会程序后就会出现scoket connection peer reset错误.经过多次试验发现原来是在每次request open以后没有及 ...
- Python爬虫入门:Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
随机推荐
- 1019 JDBC链接数据库进行修删改查
package com.liu.test01; import java.sql.Statement; import java.sql.Connection; import java.sql.Drive ...
- GitLab安装手记
阿里云1G内存20G硬盘 1.首先下载GitLab Deb包(官网附有apt-get安装方式,但国内环境貌似不成功): https://about.gitlab.com/downloads/ 2. d ...
- html5的本地存储
转载1:http://www.cnblogs.com/fly_dragon/p/3946012.html 转载2:http://www.cnblogs.com/xiaowei0705/archive/ ...
- web实验指导书和课后习题参考答案
实验指导书 :http://course.baidu.com/view/daf55bd026fff705cc170add.html 课后习题参考答案:http://wenku.baidu.com/li ...
- 常见26个jquery使用技巧详解(比如禁止右键点击、隐藏文本框文字等)
来自:http://www.xueit.com/js/show-6015-1.aspx 本文列出jquery一些应用小技巧,比如有禁止右键点击.隐藏搜索文本框文字.在新窗口中打开链接.检测浏览器. ...
- oracle函数,查询,事务
函数包括:单行函数,多行函数(分组函数) 数值函数: --绝对值 select abs(-12.3) from dual; --向上取值 select ceil(5.3) from dual; --向 ...
- C# - 时间格式
如果是字符串,需要先转化为DateTime格式 DateTime ExDate = DateTime.Parse(dt.Rows[]["HKMonth"].ToNotNullStr ...
- 管闲事的小明-nyoj51
描述某校大门外长度为L的马路上有一排树,每两棵相邻的树之间的间隔都是1米.我们可以把马路看成一个数轴,马路的一端在数轴0的位置,另一端在L的位置:数轴上的每个整数点,即0,1,2,……,L,都种有一棵 ...
- Java代理模式
java代理模式及动态代理类 1. 代理模式 代理模式的作用是:为其他对象提供一种代理以控制对这个对象的访问.在某些情况下,一个客户不想或者不能直接引用另一个对象,而代理对象可以在客户端和目 ...
- Android课程---Activity中保存和恢复用户状态
onSaveInstanceState 保存 在暂停之后和保存之前调用 onRestoreInstanceState 恢复 再启动之后和显示之前调用 package com.example.chens ...