MapReduce中的分区方法Partitioner
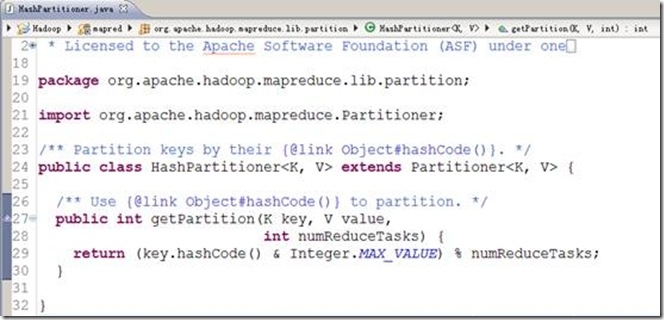
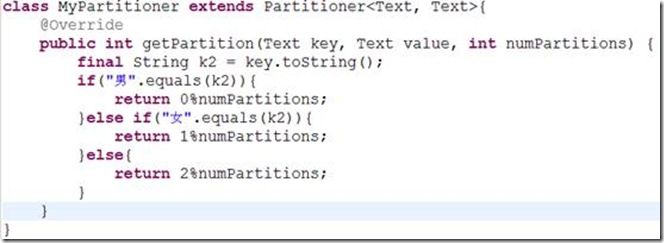
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。

MapReduce中的分区方法Partitioner的更多相关文章
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- MapReduce中combine、partition、shuffle的作用是什么
http://www.aboutyun.com/thread-8927-1-1.html Mapreduce在hadoop中是一个比較难以的概念.以下须要用心看,然后自己就能总结出来了. 概括: co ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- Mapreduce中的字符串编码
Mapreduce中的字符串编码 $$$ Shuffle的执行过程,需要经过多次比较排序.如果对每一个数据的比较都需要先反序列化,对性能影响极大. RawComparator的作用就不言而喻,能够直接 ...
- MapReduce中一次reduce方法的调用中key的值不断变化分析及源码解析
摘要:mapreduce中执行reduce(KEYIN key, Iterable<VALUEIN> values, Context context),调用一次reduce方法,迭代val ...
- [MapReduce_5] MapReduce 中的 Combiner 组件应用
0. 说明 Combiner 介绍 && 在 MapReduce 中的应用 1. 介绍 Combiner: Map 端的 Reduce,有自己的使用场景 在相同 Key 过多的情况下 ...
- Hadoop案例(七)MapReduce中多表合并
MapReduce中多表合并案例 一.案例需求 订单数据表t_order: id pid amount 1001 01 1 1002 02 2 1003 03 3 订单数据order.txt 商品信息 ...
随机推荐
- [Linux]安装phpredis扩展
1.下载phpredis,解压并进入目录,在目录下运行phpize /usr/local/php/bin/phpize ./configure --enable-redis-igbinary --wi ...
- 欧洲杯 2016 高清直播 - 观看工具 UEFA-EURO-2016-Play.7z
OnlineTV-MPlayer-nocache.exe 占 CPU 内存 较少 OnlineTV-FFPlay.exe 可截取图像 UEFA-EURO-2016-Play-v5.7z UEFA-EU ...
- Java for LeetCode 231 Power of Two
public boolean isPowerOfTwo(int n) { if(n<1) return false; while(n!=1){ if(n%2!=0) return false; ...
- Class和ClassLoader的getResourceAsStream区别
这两个方法还是略有区别的, 以前一直不加以区分,直到今天发现要写这样的代码的时候运行 错误, 才把这个问题澄清了一下. 基本上,两个都可以用于从 classpath 里面进行资源读取, classp ...
- tomcat浏览器地址支持中文方法
- 将file转变成contenthash
一.将MultipartFile转file CommonsMultipartFile cf= (CommonsMultipartFile)file; DiskFileItem fi = (DiskFi ...
- Myeclipse常用快捷键
转自:http://zjxbw.blog.51cto.com/2808787/543792 Ctrl+Shift+L 显示所有快捷键 Ctrl+K 参照选中的词(Word)快速定位到下 ...
- Spring Data JPA初使用(转载)
我们都知道Spring是一个非常优秀的JavaEE整合框架,它尽可能的减少我们开发的工作量和难度. 在持久层的业务逻辑方面,Spring开源组织又给我们带来了同样优秀的Spring Data JPA. ...
- vs c# int & int32
在vs c#中,int就等价于int32, 所以通常也是使用int32 当在统计总数时,最好使用int32,int16数值范围太小,如果超出,就会变成随机数.
- in addition to 和 except for
except for 除了...以外(与 except for 连用的整体词与 except for 所跟的词往往不是同类的,是指整体中除去 一个细节.) eg:Your composition is ...