Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系。他只是一个运算框架,和storm一样只做运算,不做存储。
Spark程序可以运行在Yarn、standalone、mesos等平台上,standalone是Spark提供的一个分布式运行平台,分为master和worker两个角色。
Standalone模式安装:只要修改一个文件即可
Spark-env.sh为: (master没有做HA)
#指定JAVA_HOME位置
export JAVA_HOME=/usr/jdk
#不做HA,需要指定spark老大Master的IP
export SPARK_MASTER_IP=master1
#指定spark的Master的端口
export SPARK_MASTER_PORT=7077
#指定可用的CPU内核数量(默认:所有可用)
#export SPARK_WORKER_CORES=1
#作业可使用的内存容量,默认格式为1000m或者2g(默认:所有RAM去掉给操作系统用的1GB)
#export SPARK_WORKER_MEMORY=500m
#机器上运行worker数量 (默认:1)。当你有一个非常强大的计算机的时可启动多个worker进程。
#export SPARK_WORKER_INSTANCES=1
#设置hadoop集群的配置文件所在目录
#export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
#(可选)配置两个Spark Master实现高可靠(首先要配置zookeeper集群,在spark-env.sh添加SPARK_DAEMON_JAVA_OPTS)
#export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1ha:2181,master2:2181,master2ha:2181 -Dspark.deploy.zookeeper.dir=/spark"Spark-env.sh为: (master做HA)
#指定JAVA_HOME位置
export JAVA_HOME=/usr/jdk
#做HA,不能指定spark老大Master的IP,让zookeeper来选择
#export SPARK_MASTER_IP=master1
#指定spark的Master的端口
export SPARK_MASTER_PORT=7077
#指定可用的CPU内核数量(默认:所有可用)
#export SPARK_WORKER_CORES=1
#作业可使用的内存容量,默认格式为1000m或者2g(默认:所有RAM去掉给操作系统用的1GB)
#export SPARK_WORKER_MEMORY=500m
#机器上运行worker数量 (默认:1)。当你有一个非常强大的计算机的时可启动多个worker进程。
#export SPARK_WORKER_INSTANCES=1
#设置hadoop集群的配置文件所在目录
#export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
#(可选)配置两个Spark Master实现高可靠(首先要配置zookeeper集群,在spark-env.sh添加SPARK_DAEMON_JAVA_OPTS)
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1ha:2181,master2:2181,master2ha:2181 -Dspark.deploy.zookeeper.dir=/spark"
其实很简单,配置文件只需要配置
export JAVA_HOME=/usr/jdk
export SPARK_MASTER_IP=master1
export SPARK_MASTER_PORT=7077
或者
export JAVA_HOME=/usr/jdk
export SPARK_MASTER_PORT=7077
//指定zookeeper的路径,让他们去选择主master
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1ha:2181,master2:2181,master2ha:2181 -Dspark.deploy.zookeeper.dir=/spark"
思考:Spark需要从HDFS上读取数据,又不在这里配置hadoop的安装目录,它是怎么知道HDFS的NameNode在哪里?
答案:
1、如果在这里配置hadoop的安装路径,意味着每一台Spark机器都要安装hadoop软件。这样对软件的依赖太强,其实如果是指定hadoop的安装目录,莫非就是想读取他的配置文件,然后知道NameNode在哪里即可,因为它是通过HDFS的API来对HDFS进行操作的。
2、Spark的解决方案很简单也很直白
把你们的配置文件都扔到我的conf目录下我就知道怎么去和NameNode连接了,同样也知道如何去和yarn连接,而且还知道如何去使用hive的仓库元数据。
整合HDFS之后,默认路径就会是那个HDFS的NameNode路径了。如果要读取本地的数据,那么需要指定file:///root/words.txt
只要你们把配置文件给我,我什么都知道。哈哈哈哈哈哈哈哈哈哈哈哈!!!!
问题:上述的standalone模式是Spark提供的一种方式,但是很多公司做大数据原本就有了Yarn集群了,如何把Spark也运行在Yarn上,从而省去Spark集群?
1、Spark-On-Yarn的介绍:
Spark-ON-Yarn之后,不在需要Spark集群了,也就是其他机器上不需要安装Spark框架程序,只需要有一台机器安装Spark+hadoop作为客户端即可,有了hadoop的安装目录,就知道resourceManager在哪里。
还有就是Yarn集群。
Spark-On-Yarn配置
Spark-env.sh为:
#指定JAVA_HOME位置
export JAVA_HOME=/usr/jdk
#指定hadoop的安装目录在哪里,因为他要读取hadoop的配置文件,从而知道resourceManager在哪里
export HADOOP_CONF_DIR=/usr/mysoft/hadoop/etc/
Spark-On-Yarn运行方式有两种==>cluster 、 client
1、cluster模式(在yarn上启动一个appmaster作为Driver,完成DAGscheduler和TaskScheduler,也就是安装Spark的机器就是一个“仅仅上传jar包到HDFS的角色”)
cluster模式:Driver程序在YARN中运行,应用的运行结果不能在客户端显示,所以最好运行那些将结果最终保存在外部存储介质(如HDFS、Redis、Mysql)而非stdout输出的应用程序,客户端的终端显示的仅是作为YARN的job的简单运行状况。
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
lib/spark-examples*.jar \
10
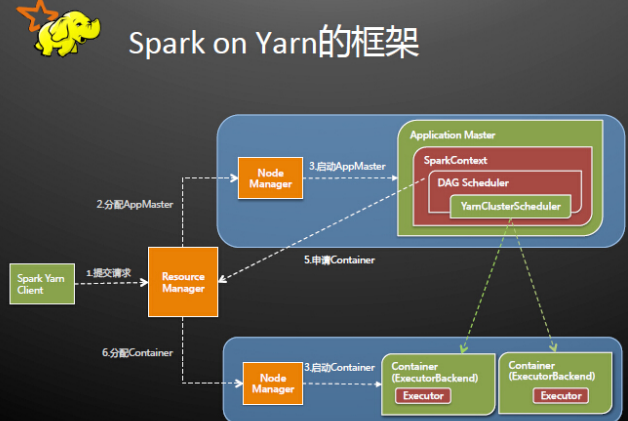
1.1运行原理图如下:
1.2具体步骤
Spark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的NodeManager节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。具体过程:
由client向ResourceManager提交请求,并上传jar到HDFS上 这期间包括四个步骤: a).连接到RM b).从RM的ASM(ApplicationsManager )中获得metric、queue和resource等信息。 c). upload app jar and spark-assembly jar d).设置运行环境和container上下文(launch-container.sh等脚本)
ResouceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationMaster)
- NodeManager启动ApplicationMaster,并向ResourceManager AsM注册
- ApplicationMaster从HDFS中找到jar文件,启动SparkContext、DAGscheduler和YARN Cluster Scheduler
- ResourceManager向ResourceManager AsM注册申请container资源
- ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container对应一个executor)
- Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。
2、client模式(这个是后Spark提交任务程序才是整整的客户端,它充当Driver,负责DAGScheduler和Taskscheduler等)
client模式:Driver运行在Client上,应用程序运行结果会在客户端显示,所有适合运行结果有输出的应用程序(如spark-shell)
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
lib/spark-examples*.jar \
10
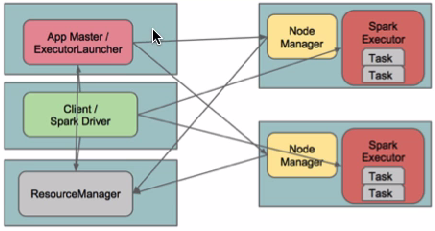
2.1运行原理图如下:
2.2具体步骤
在client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都 是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver- memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。
总结:
1、Spark可以运行在standalone、yarn、mesos等资源调度平台上。
2、当运行在yarn上时,有两种方式,cluster模式和client模式,不同的场景用不同的模式,比如spark-shell必须使用client模式,因为要进行交互式处理。
Spark的StandAlone模式原理和安装、Spark-on-YARN的理解的更多相关文章
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- Spark之standalone模式
standalone hdfs:namenode是主节点进程,datanode是从节点进程 yarn:resourcemanager是主节点进程,nodemanager是从节点进程 hdfs和yarn ...
- 008 Spark中standalone模式的HA(了解,知道怎么配置即可)
standalone也存在单节点问题,这里主要是配置两个master. 1.官网 2.具体的配置 3.配置方式一(不是太理想) 这种知识基于未来可以重启,但是不能在宕机的时候提供服务. 方式一:Sin ...
- 一步一步搭建:spark之Standalone模式+zookeeper之HA机制
理论参考:http://www.cnblogs.com/hseagle/p/3673147.html 基于3台主机搭建:以下仅是操作步骤,原理网上自查 :1. 增加ip和hostname的对应关系,跨 ...
- Spark在StandAlone模式下提交任务,spark.rpc.message.maxSize太小而出错
1.错误信息org.apache.spark.SparkException: Job aborted due to stage failure:Serialized task 32:5 was 172 ...
- Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark的集群的准备环境 1>.master节点信息(s101) 2&g ...
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
随机推荐
- 2015 西雅图微软总部MVP峰会记录
2015 西雅图微软总部MVP峰会记录 今年决定参加微软MVP全球峰会,在出发之前本人就已经写这篇博客,希望将本次会议原汁原味奉献给大家 因为这次是本人第一次写会议记录,写得不好的地方希望各位园友见谅 ...
- 最新 去掉 Chrome 新标签页的8个缩略图
chrome的新标签页的8个缩略图实在让人不爽,网上找了一些去掉这个略缩图的方法,其中很多已经失效.不过其中一个插件虽然按照原来的方法已经不能用了,但是稍微变通一下仍然是可以用的(本方法于2017.1 ...
- 运行执行sql文件脚本的例子
sqlcmd -s -d db_test -r -i G:\test.sql 黑色字体为关键命令,其他颜色(从左至右):服务器名称,用户名,密码,数据库,文件路径 通过select @@servern ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- spring的BeanFactory加载过程
ApplicationContext spring = new ClassPathXmlApplicationContext("classpath*:spring/applicationCo ...
- 一个软件开发者的BPM之路
我是小林,一名普通的软件工程师,从事BPM(业务流程管理)软件开发工作.我没有几十年的技术底蕴,无法像大牛们一样高谈阔论,品评BPM开发之道:也不是资深的流程管理专家,能与大家分析流程管理的时弊.我只 ...
- Android之SQLite数据存储
一.SQLite保存数据介绍 将数据库保存在数据库对于重复或者结构化数据(比如契约信息)而言是理想之选.SQL数据库的主要原则之一是架构:数据库如何组织正式声明.架构体现于用于创建数据库的SQL语句. ...
- LINQ to SQL语句(7)之Exists/In/Any/All/Contains
适用场景:用于判断集合中元素,进一步缩小范围. Any 说明:用于判断集合中是否有元素满足某一条件:不延迟.(若条件为空,则集合只要不为空就返回True,否则为False).有2种形式,分别为简单形式 ...
- x01.os.23: 制作 linux LiveCD
1.首先运行如下命令 sudo apt-get install wget bc build-essential gawk genisoimage 2.下载如下资源,make all 即可 http: ...
- TFS 生成发布代理
下载Agent 后,执行配置命令 参考 安装TFS(2015)工作组模式代理服务器(Agent)