mpi4python
转载:https://zhuanlan.zhihu.com/p/25332041
前言
在高性能计算的项目中我们通常都会使用效率更高的编译型的语言例如C、C++、Fortran等,但是由于Python的灵活性和易用性使得它在发展和验证算法方面备受人们的青睐于是在高性能计算领域也经常能看到Python的身影了。本文简单介绍在Python环境下使用MPI接口在集群上进行多进程并行计算的方法。
MPI(Message Passing Interface)
这里我先对MPI进行一下简单的介绍,MPI的全称是Message Passing Interface,即消息传递接口。
它并不是一门语言,而是一个库,我们可以用Fortran、C、C++结合MPI提供的接口来将串行的程序进行并行化处理,也可以认为Fortran+MPI或者C+MPI是一种再原来串行语言的基础上扩展出来的并行语言。
它是一种标准而不是特定的实现,具体的可以有很多不同的实现,例如MPICH、OpenMPI等。
它是一种消息传递编程模型,顾名思义,它就是专门服务于进程间通信的。
MPI的工作方式很好理解,我们可以同时启动一组进程,在同一个通信域中不同的进程都有不同的编号,程序员可以利用MPI提供的接口来给不同编号的进程分配不同的任务和帮助进程相互交流最终完成同一个任务。就好比包工头给工人们编上了工号然后指定一个方案来给不同编号的工人分配任务并让工人相互沟通完成任务。
Python中的并行
由于CPython中的GIL的存在我们可以暂时不奢望能在CPython中使用多线程利用多核资源进行并行计算了,因此我们在Python中可以利用多进程的方式充分利用多核资源。
Python中我们可以使用很多方式进行多进程编程,例如os.fork()来创建进程或者通过multiprocessing模块来更方便的创建进程和进程池等。在上一篇《Python多进程并行编程实践-multiprocessing模块》中我们使用进程池来方便的管理Python进程并且通过multiprocessing模块中的Manager管理分布式进程实现了计算的多机分布式计算。
与多线程的共享式内存不同,由于各个进程都是相互独立的,因此进程间通信再多进程中扮演这非常重要的角色,Python中我们可以使用multiprocessing模块中的pipe、queue、Array、Value等等工具来实现进程间通讯和数据共享,但是在编写起来仍然具有很大的不灵活性。而这一方面正是MPI所擅长的领域,因此如果能够在Python中调用MPI的接口那真是太完美了不是么。
MPI与mpi4py
mpi4py是一个构建在MPI之上的Python库,主要使用Cython编写。mpi4py使得Python的数据结构可以方便的在多进程中传递。
mpi4py是一个很强大的库,它实现了很多MPI标准中的接口,包括点对点通信,组内集合通信、非阻塞通信、重复非阻塞通信、组间通信等,基本上我能想到用到的MPI接口mpi4py中都有相应的实现。不仅是Python对象,mpi4py对numpy也有很好的支持并且传递效率很高。同时它还提供了SWIG和F2PY的接口能够让我们将自己的Fortran或者C/C++程序在封装成Python后仍然能够使用mpi4py的对象和接口来进行并行处理。可见mpi4py的作者的功力的确是非常了得。
mpi4py
这里我开始对在Python环境中使用mpi4py的接口进行并行编程进行介绍。
MPI环境管理
mpi4py提供了相应的接口Init()和Finalize()来初始化和结束mpi环境。但是mpi4py通过在__init__.py中写入了初始化的操作,因此在我们from mpi4py import MPI的时候就已经自动初始化mpi环境。
MPI_Finalize()被注册到了Python的C接口Py_AtExit(),这样在Python进程结束时候就会自动调用MPI_Finalize(), 因此不再需要我们显式的去掉用Finalize()。
通信域(Communicator)
mpi4py直接提供了相应的通信域的Python类,其中Comm是通信域的基类,Intracomm和Intercomm是其派生类,这根MPI的C++实现中是相同的。
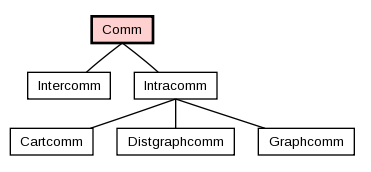
同时它也提供了两个预定义的通信域对象:
- 包含所有进程的COMM_WORLD
- 只包含调用进程本身的COMM_SELF
In [1]: from mpi4py import MPI
In [2]: MPI.COMM_SELF
Out[2]: <mpi4py.MPI.Intracomm at 0x7f2fa2fd59d0>
In [3]: MPI.COMM_WORLD
Out[3]: <mpi4py.MPI.Intracomm at 0x7f2fa2fd59f0>
通信域对象则提供了与通信域相关的接口,例如获取当前进程号、获取通信域内的进程数、获取进程组、对进程组进行集合运算、分割合并等等。
In [4]: comm = MPI.COMM_WORLD
In [5]: comm.Get_rank()
Out[5]: 0
In [6]: comm.Get_size()
Out[6]: 1
In [7]: comm.Get_group()
Out[7]: <mpi4py.MPI.Group at 0x7f2fa40fec30>
In [9]: comm.Split(0, 0)
Out[9]: <mpi4py.MPI.Intracomm at 0x7f2fa2fd5bd0>
关于通信域与进程组的操作这里就不细讲了,可以参考Introduction to Groups and Communicators
点对点通信
mpi4py提供了点对点通信的接口使得多个进程间能够互相传递Python的内置对象(基于pickle序列化),同时也提供了直接的数组传递(numpy数组,接近C语言的效率)。
如果我们需要传递通用的Python对象,则需要使用通信域对象的方法中小写的接口,例如send(),recv(),isend()等。
如果需要直接传递数据对象,则需要调用大写的接口,例如Send(),Recv(),Isend()等,这与C++接口中的拼写是一样的。
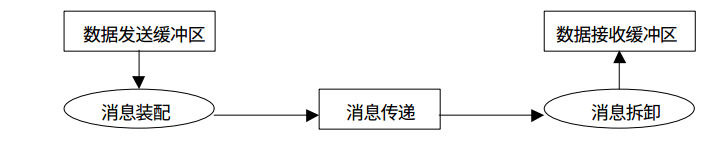
MPI中的点到点通信有很多中,其中包括标准通信,缓存通信,同步通信和就绪通信,同时上面这些通信又有非阻塞的异步版本等等。这些在mpi4py中都有相应的Python版本的接口来让我们更灵活的处理进程间通信。这里我只用标准通信的阻塞和非阻塞版本来做个举例:
阻塞标准通信
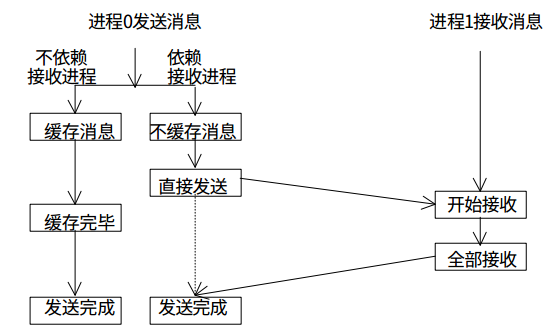
这里我尝试使用mpi4py的接口在两个进程中传递Python list对象。
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
data = range(10)
comm.send(data, dest=1, tag=11)
print("process {} send {}...".format(rank, data))
else:
data = comm.recv(source=0, tag=11)
print("process {} recv {}...".format(rank, data))
执行效果:
zjshao@vaio:~/temp_codes/mpipy$ mpiexec -np 2 python temp.py
process 0 send [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
process 1 recv [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
非阻塞标准通信
所有的阻塞通信mpi都提供了一个非阻塞的版本,类似与我们编写异步程序不阻塞在耗时的IO上是一样的,MPI的非阻塞通信也不会阻塞消息的传递过程中,这样能够充分利用处理器资源提升整个程序的效率。
来张图看看阻塞通信与非阻塞通信的对比:
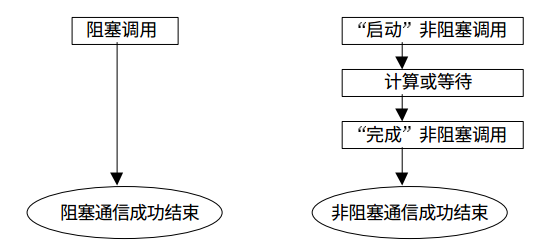 非阻塞通信的消息发送和接受:
非阻塞通信的消息发送和接受:
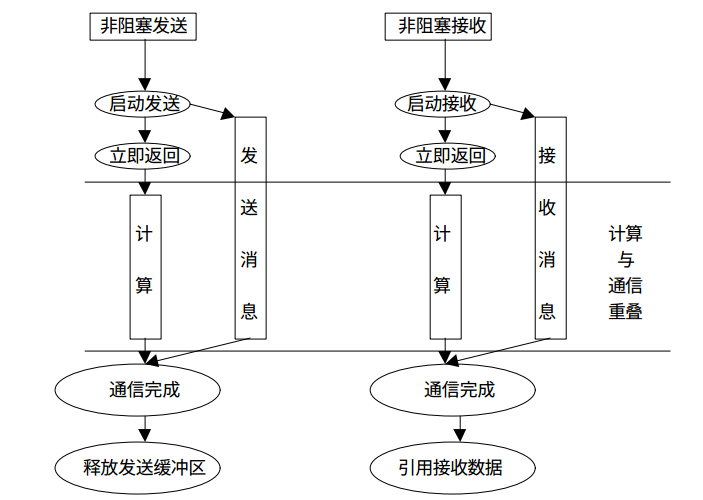
同样的,我们也可以写一个上面例子的非阻塞版本。
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
data = range(10)
comm.isend(data, dest=1, tag=11)
print("process {} immediate send {}...".format(rank, data))
else:
data = comm.recv(source=0, tag=11)
print("process {} recv {}...".format(rank, data))
执行结果,注意非阻塞发送也可以用阻塞接收来接收消息:
zjshao@vaio:~/temp_codes/mpipy$ mpiexec -np 2 python temp.py
process 0 immediate send [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
process 1 recv [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
支持Numpy数组
mpi4py的一个很好的特点就是他对Numpy数组有很好的支持,我们可以通过其提供的接口来直接传递数据对象,这种方式具有很高的效率,基本上和C/Fortran直接调用MPI接口差不多(方式和效果)
例如我想传递长度为10的int数组,MPI的C++接口是:
void Comm::Send(const void * buf, int count, const Datatype & datatype, int dest, int tag) const
在mpi4py的接口中也及其类似, Comm.Send()中需要接收一个Python list作为参数,其中包含所传数据的地址,长度和类型。
来个阻塞标准通信的例子:
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
data = np.arange(10, dtype='i')
comm.Send([data, MPI.INT], dest=1, tag=11)
print("process {} Send buffer-like array {}...".format(rank, data))
else:
data = np.empty(10, dtype='i')
comm.Recv([data, MPI.INT], source=0, tag=11)
print("process {} recv buffer-like array {}...".format(rank, data))
执行效果:
zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 2 python temp.py
process 0 Send buffer-like array [0 1 2 3 4 5 6 7 8 9]...
process 1 recv buffer-like array [0 1 2 3 4 5 6 7 8 9]...
组通信
MPI组通信和点到点通信的一个重要区别就是,在某个进程组内所有的进程同时参加通信,mpi4py提供了方便的接口让我们完成Python中的组内集合通信,方便编程同时提高程序的可读性和可移植性。
下面就几个常用的集合通信来小试牛刀吧。
广播
广播操作是典型的一对多通信,将跟进程的数据复制到同组内其他所有进程中。
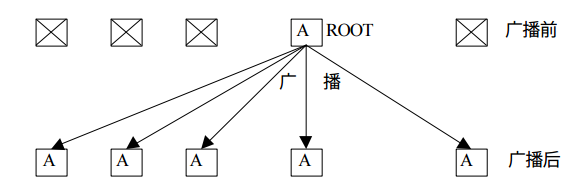 在Python中我想将一个列表广播到其他进程中:
在Python中我想将一个列表广播到其他进程中:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
data = range(10)
print("process {} bcast data {} to other processes".format(rank, data))
else:
data = None
data = comm.bcast(data, root=0)
print("process {} recv data {}...".format(rank, data))
执行结果:
zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 5 python temp.py
process 0 bcast data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] to other processes
process 0 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
process 1 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
process 3 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
process 2 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
process 4 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
发散
与广播不同,发散可以向不同的进程发送不同的数据,而不是完全复制。
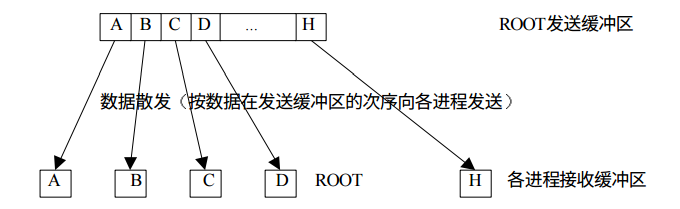 例如我想将0-9发送到不同的进程中:
例如我想将0-9发送到不同的进程中:
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
recv_data = None
if rank == 0:
send_data = range(10)
print("process {} scatter data {} to other processes".format(rank, send_data))
else:
send_data = None
recv_data = comm.scatter(send_data, root=0)
print("process {} recv data {}...".format(rank, recv_data))
发散结果:
zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 10 python temp.py
process 0 scatter data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] to other processes
process 0 recv data 0...
process 3 recv data 3...
process 5 recv data 5...
process 8 recv data 8...
process 2 recv data 2...
process 7 recv data 7...
process 4 recv data 4...
process 1 recv data 1...
process 9 recv data 9...
process 6 recv data 6...
收集
收集过程是发散过程的逆过程,每个进程将发送缓冲区的消息发送给根进程,根进程根据发送进程的进程号将各自的消息存放到自己的消息缓冲区中。
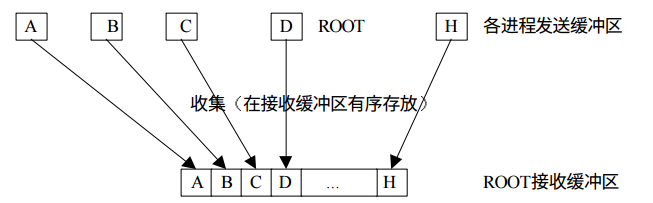
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
send_data = rank
print "process {} send data {} to root...".format(rank, send_data)
recv_data = comm.gather(send_data, root=0)
if rank == 0:
print "process {} gather all data {}...".format(rank, recv_data)
收集结果:
zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 5 python temp.py
process 2 send data 2 to root...
process 3 send data 3 to root...
process 0 send data 0 to root...
process 4 send data 4 to root...
process 1 send data 1 to root...
process 0 gather all data [0, 1, 2, 3, 4]...
其他的组内通信还有归约操作等等由于篇幅限制就不多讲了,有兴趣的可以去看看MPI的官方文档和相应的教材。
mpi4py并行编程实践
这里我就上篇中的二重循环绘制map的例子来使用mpi4py进行并行加速处理。
我打算同时启动10个进程来将每个0轴需要计算和绘制的数据发送到不同的进程进行并行计算。
因此我需要将pO2s数组发散到10个进程中:
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
pO2 = np.linspace(1e-5, 0.5, 10)
else:
pO2 = None
pO2 = comm.scatter(pO2, root=0)
pCOs = np.linspace(1e-5, 0.5, 10)
之后我需要在每个进程中根据接受到的pO2s的数据再进行一次pCOs循环来进行计算。
最终将每个进程计算的结果(TOF)进行收集操作:
comm.gather(tofs_1d, root=0)
由于代码都是涉及的专业相关的东西我就不全列出来了,将mpi4py改过的并行版本放到10个进程中执行可见:


效率提升了10倍左右。
总结
本文简单介绍了mpi4py的接口在python中进行多进程编程的方法,MPI的接口非常庞大,相应的mpi4py也非常庞大,mpi4py还有实现了相应的SWIG和F2PY的封装文件和类型映射,能够帮助我们将Python同真正的C/C++以及Fortran程序在消息传递上实现统一。有兴趣的同学可以进一步研究一下,欢迎交流。
参考
- MPI for Python 2.0.0 documentation
- MPI Tutorial
- A Python Introduction to Parallel Programming with MPI
- 《高性能计算并行编程技术-MPI并行程序设计》
- 《MPI并行程序设计实例教程》
mpi4python的更多相关文章
随机推荐
- day92之支付宝支付
Python之支付宝支付 正式环境:用营业执照,申请商户号,appid 基于支付宝的测试环境:https://openhome.alipay.com/platform/appDaily.htm?tab ...
- 【转】DataTable与实体类互相转换
原文地址:https://www.cnblogs.com/marblemm/p/7084797.html /// <summary> /// DataTable与实体类互相转换 /// & ...
- 基于Vue.js 2.0 + Vuex打造微信项目
一.项目简介 基于Vue + Vuex + Vue-router + Webpack 2.0打造微信界面,实现了微信聊天.搜索.点赞.通讯录(快速导航).个人中心.模拟对话.朋友圈.设置等功能. 二. ...
- Windows Community Toolkit 4.0 - DataGrid - Part01
概述 在上面一篇 Windows Community Toolkit 4.0 - DataGrid - Overview 中,我们对 DataGrid 控件做了一个概览的介绍,今天开始我们会做进一步的 ...
- 埋锅。。。BZOJ1004-置换群+burnside定理+
看这道题时当时觉得懵逼...这玩意完全看不懂啊...什么burnside...难受... 于是去看了点视频和资料,大概懂了置换群和burnside定理,亦步亦趋的懂了别人的代码,然后慢慢的打了出来.. ...
- Latex(表格|图片(一丢丢))
目录 普通的例子 Notation 例子 p{width} 列分割符 @{} \multicolumn supertabular | longtabular 浮动体 table 浮动体 图片 \use ...
- Joyride (spaf)
题目链接:https://codeforces.com/gym/101873/problem/C spaf的复杂度有点迷,按道理来说,一个简单的spaf在这题的复杂度是1e9,所以不敢写,然后用优先队 ...
- Jenkins部署net core小记
作为一个不熟悉linux命令的neter,在centos下玩Jenkins真的是一种折磨啊,但是痛并快乐着,最后还是把demo部署成功!写这篇文章是为了记录一下这次部署的流程,和心得体会. 网上很多资 ...
- ElasticSearch Nosql
把 ElasticSearch 当成是 NoSQL 数据库 Elasticsearch 可以被当成一个 "NoSQL"-数据库来使用么? NoSQL 意味着在不同的环境下存在不同的 ...
- 在IDEA中配置Spring的XML装配
不考虑混合模式的话,Spring有三类装配Bean的方法,自动装配和Java代码装配都会很容易上手,但在弄XML装配时遇到了问题,这与IDEA环境有关. 装配时需要在源码中配置XML文件的位置,我看别 ...