Scrapy项目创建以及目录详情
Scrapy项目创建已经目录详情
一、新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
PS C:\scrapy> scrapy startproject sp1
You can start your first spider with:
cd sp1
scrapy genspider example example.com
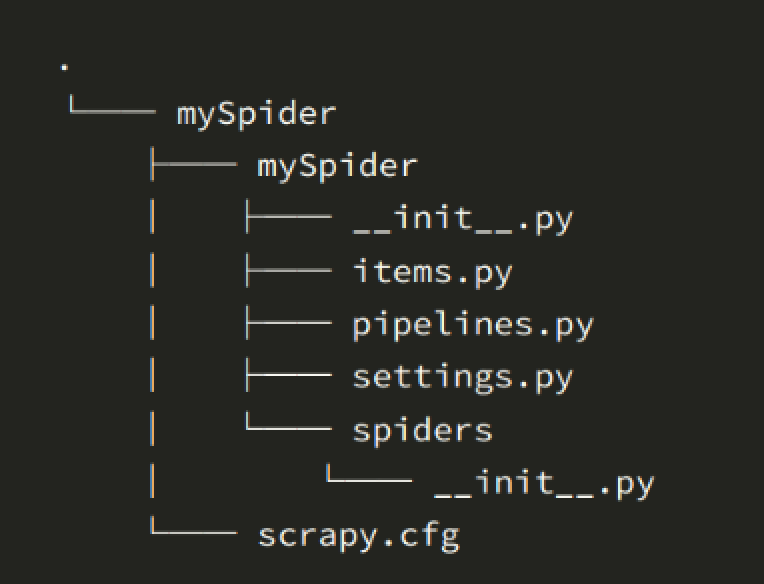
- scrapy.cfg # 项目的配置文件
- sp1/ # 项目的Python模块,将会从这里引用代码
- sp1/items.py # 项目的目标文件
- sp1/pipelines.py # 项目的管道文件用于文件持久化
- sp1/settings.py # 项目的设置文件
- sp1/middlewares.py # 中间件
- sp1/spiders/ # 存储爬虫代码目录
settings.py内容详情
settings.py
# 项目名
BOT_NAME = 'sp1'
# 爬虫所在的位置
SPIDER_MODULES = ['sp1.spiders']
NEWSPIDER_MODULE = 'sp1.spiders'
# 爬虫是否遵循 robots 协议
ROBOTSTXT_OBEY = False
# 爬虫的并发量 默认 16 个
# CONCURRENT_REQUESTS = 32
# 下载延时 3 s
#DOWNLOAD_DELAY = 3
# 是否禁用cookies 默认不禁用
#COOKIES_ENABLED = False # 表示为禁用
# 请求包头
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 语言可以关闭,按照服务器返回值为准
# 'Accept-Language': 'en',
}
# 下载中间件,值越小优先级越高
DOWNLOADER_MIDDLEWARES = {
'sp1.middlewares.Sp1DownloaderMiddleware': 543,
}
# 下载后的数据如何处理,存储过程
ITEM_PIPELINES = {
'sp1.pipelines.FilePipeline': 300,
}
创建一个爬虫文件
在当前目录下输入命令,将在sp1/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
PS C:\scrapy> cd sp1
# scrapy genspider关键字 chouti 爬虫名 chouti.com 一般指定站点域名
PS C:\scrapy\sp1> scrapy genspider chouti chouti.com
Created spider 'chouti' using template 'basic' in module:
sp1.spiders.chouti
通过pycharm调试scrapy项目
1.使用pycharm打开项目
2.在项目等级目录创建main.py
from scrapy.cmdline import execute
import sys
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
print(BASE_DIR)
execute(["scrapy","crawl","chouti"])
Scrapy项目创建以及目录详情的更多相关文章
- Python Scrapy项目创建(基础普及篇)
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目.通过如下命令即可创建 Scrapy 项目: scrapy startproject ZhipinSpider 在上面命令中,scrapy ...
- IDEA中Java项目创建lib目录并生成依赖
首先介绍说明一下idea在创建普通的Java项目,是没有lib文件夹的,下面我来带大家来创建一下1.右键点击项目,创建一个普通的文件夹 2.取名为lib 3.把项目所需的jar包复制到lib文件夹下 ...
- 创建第一个Scrapy项目
d:进入D盘 scrapy startproject tutorial建立一个新的Scrapy项目 工程的目录结构: tutorial/ scrapy.cfg # 部署配置文件 tutorial/ # ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- 【pycharm基本操作】项目创建、切换、运行、字体颜色设置,常见包的安装步骤
创建新项目 退出项目 怎样区别虚拟环境和系统环境? 虚拟环境和系统环境切换:进入项目切换解释器 切换项目 创建python目录和文件 代码运行方式一: 还可以这样执行代码方式二: 文件的剪切.复制.删 ...
- pycharm创建scrapy项目教程及遇到的坑
最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理 ...
- eclipse创建scrapy项目
1. 您必须创建一个新的Scrapy项目. 进入您打算存储代码的目录中(比如否F:/demo),运行下列命令: scrapy startproject tutorial 2.在eclipse中创建一个 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Scrapy库安装和项目创建
Scrapy是一个流行的网络爬虫框架,从现在起将陆续记录Python3.6下Scrapy整个学习过程,方便后续补充和学习.本文主要介绍scrapy安装.项目创建和测试基本命令操作 scrapy库安装 ...
随机推荐
- EditText设置可以点击,但是不可以编辑
EditText设置 editText.setEnabled(false);后不可编辑也不可点击 设置 setFocusable(false)后不可编辑,但是再设置 setFocusable(tr ...
- LeetCode Two Add Two Numbers (JAVA)
问题简介:输入两个数字链表,输出求和后的链表(链表由数字位数倒序组成) 问题详解: 给定两个非空链表,表示两个非负整数. 数字以相反的顺序存储,每个节点包含一位数字.对两个整数作求和运算,将结果倒序作 ...
- activemq学习笔记2
基本步骤: ConnectionFactory factory = new ActiveMQConnectionFactory("tcp://127.0.0.1:61616"); ...
- Java类锁和对象锁
一.类锁和对象锁 二.使用注意 三.参考资料 一.类锁和对象锁 类锁:在代码中的方法上加了static和synchronized的锁,或者synchronized(xxx.class) 对象锁:在代码 ...
- Python代码打印出9*9 九九乘法表
九九乘法表 一一 小问题展现技术 1.示例一 for i in range(10): s='' for j in range(1,i+1): s+=str(j)+'*'+str(i)+'='+str( ...
- JavaScript-简介、ECMAScript5.0
Javascript简介 web前端有三层: HTML:从语义的角度,描述页面的结构 CSS:从审美的角度,描述样式(美化页面) Javascript:从交互的角度,描述行为(提升用户体验) Java ...
- AD7729_双通道Sigma-Delta ADC
sigma-delta adc的原理,就是通过一种结构把量化噪声调制到频谱的高端,也即对量化噪声而言,sdm是一个高通滤波器,而对基带信号则等价为一个全通滤波器,这样等价的基带信号的量化噪声就很小了, ...
- 国产 WEB UI 框架 (收费)-- Quick UI,Mini UI
国产 WEB UI 框架 (收费)-- Quick UI,Mini UI : http://www.uileader.com/ http://www.miniui.com/
- 题解-APIO2010 特别行动队
题目 洛谷 & bzoj 简要题意:给定一个长为\(n\)的序列\(\{s_i\}\)与常数\(a,b,c\),序列的一个连续子段\(s_i\)到\(s_j\)的贡献为\(at^2+bt+c\ ...
- OpenStack实践系列⑥构建虚拟机实例
OpenStack实践系列⑥构建虚拟机实例 四.创建一台虚拟机图解网络,并创建一个真实的桥接网络 创建一个单一扁平网络(名字:flat),网络类型为flat,网络适共享的(share),网络提供者:p ...