SQL Server控制执行计划
为了提高性能,可以使用提示(hints)特性,包含以下三类:
查询提示:(query hints)告知优化器在整个查询过程中都应用某个提示
关联提示:(join hints)告知优化器在查询的特定部分使用指定的关联算法
表提示:(table hints)告知优化器使用表扫描还是表上特定的索引
这是非常规操作,除非你无计可施,或者用于研究。
一:查询提示
查询提示的基本语法是加入OPTION子句,如下:
select * from TableName OPTION 参数
这种提示不能运用在单独的INSET语句中,除非里面包含了SELECT操作,也不能用在子查询中
1.HASH/ORDER GROUP
两类提示----HASH GROUP和ORDER GROUP,用于GROUP BY聚合操作(通常就是DISTINCT或者聚合操作)。他们能强制优化器使用hashing或者grouping操作来实现聚合。
select p.Suffix,COUNT(p.Suffix)as SuffixUsageCount from Person.Person as p group by p.Suffix

优化器选择了Hash Match来实现聚合,这个操作在TempDB中创建了一个哈希表,然后从聚集索引扫描得到的结果里选出了不重复的数据插进这个表,接着返回结果集。
由于Hash Match操作是非排序的,因此这个开销大。如果把数据预先排序,就可避免在TempDB中额外排序。
select p.Suffix,COUNT(p.Suffix)as SuffixUsageCount from Person.Person as p
group by p.Suffix
option (order group)

强制优化器使用Sort操作符来替换Hash Match。开销反而增加,只是演示。
2.MERGE/HASH/CONCATE UNION
当代吗中出现UNION操作符,就可能出现这些操作符。可以使用提示来引导优化器
select pm1.Name,pm1.ModifiedDate from Production.ProductModel pm1
union
select pm2.Name,pm2.ModifiedDate from Production.ProductModel pm2

Concatenation(串联)操作符这个操作符开销为0,但是Sort操作符就比较昂贵了。可以加上MERGE UNION提示
select pm1.Name,pm1.ModifiedDate from Production.ProductModel pm1
union
select pm2.Name,pm2.ModifiedDate from Production.ProductModel pm2
option (merge UNION);
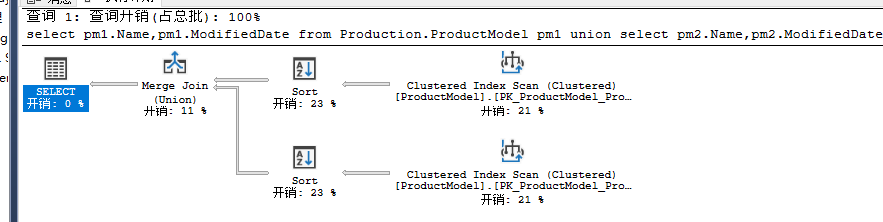
这里通过使用Merge Join来替代Concatenation操作从而实现UNION操作。由于合并连接要求数据是有序的,所以又引入了两个额外的Sort操作,反而增加了开销。
换成hash UNION。
select pm1.Name,pm1.ModifiedDate from Production.ProductModel pm1
union
select pm2.Name,pm2.ModifiedDate from Production.ProductModel pm2
option (hash UNION);

3.LOOP/MERGE/HASH JOIN
如果使用了某种JOIN提示,那么整个查询的所有表都会使用这种关联算法,所以这个查询提示比较危险。
select pm.Name,pm.CatalogDescription,p.Name as productName,i.Diagram
from Production.ProductModel as pm
left join Production.Product as p
on pm.ProductModelID=p.ProductModelID
left join Production.ProductModelIllustration as pmi
on p.ProductModelID=pmi.ProductModelID
left join Production.Illustration as i
on pmi.IllustrationID=i.IllustrationID
where pm.Name like '%Mountain%'
order by pm.Name

使用Hash Join提示:
select pm.Name,pm.CatalogDescription,p.Name as productName,i.Diagram
from Production.ProductModel as pm
left join Production.Product as p
on pm.ProductModelID=p.ProductModelID
left join Production.ProductModelIllustration as pmi
on p.ProductModelID=pmi.ProductModelID
left join Production.Illustration as i
on pmi.IllustrationID=i.IllustrationID
where pm.Name like '%Mountain%'
order by pm.Name
option (hash join)
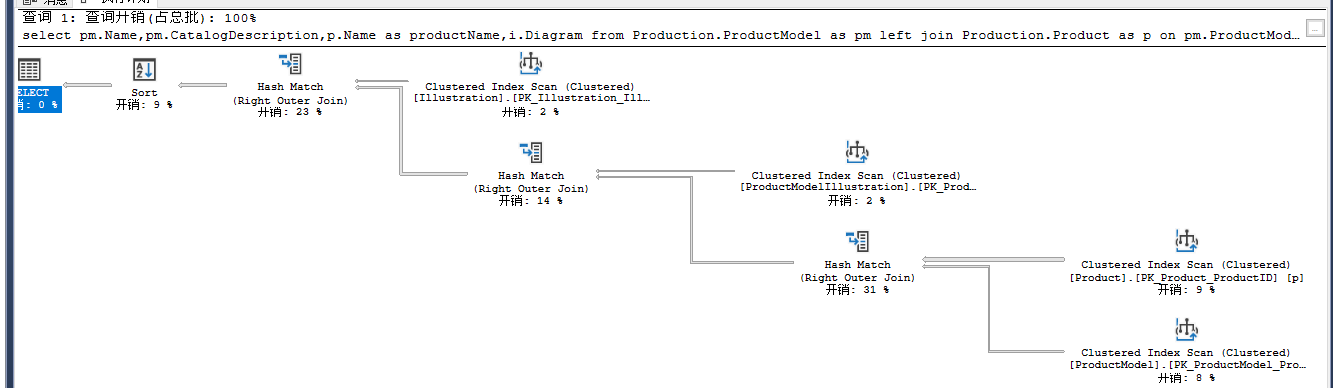
全部关联使用了Hash Join
使用MERGE JOIN的执行计划
select pm.Name,pm.CatalogDescription,p.Name as productName,i.Diagram
from Production.ProductModel as pm
left join Production.Product as p
on pm.ProductModelID=p.ProductModelID
left join Production.ProductModelIllustration as pmi
on p.ProductModelID=pmi.ProductModelID
left join Production.Illustration as i
on pmi.IllustrationID=i.IllustrationID
where pm.Name like '%Mountain%'
order by pm.Name
option (merge join)
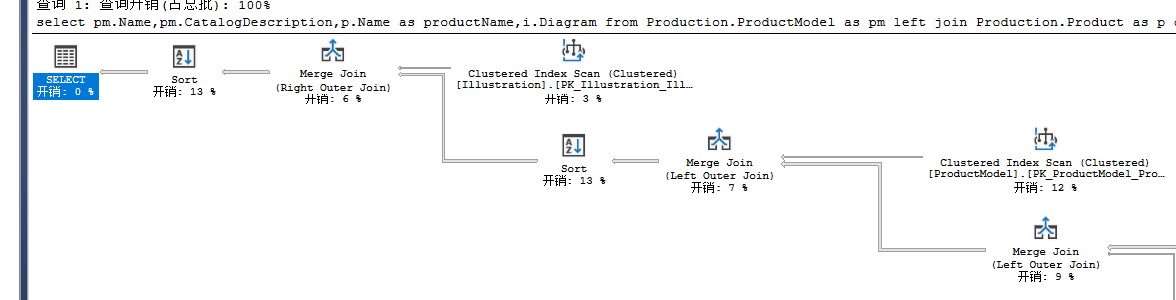
4.FORCE ORDER
如果想强制优化器使用自己的逻辑表关联顺序而不让优化器进行不穷尽的分析
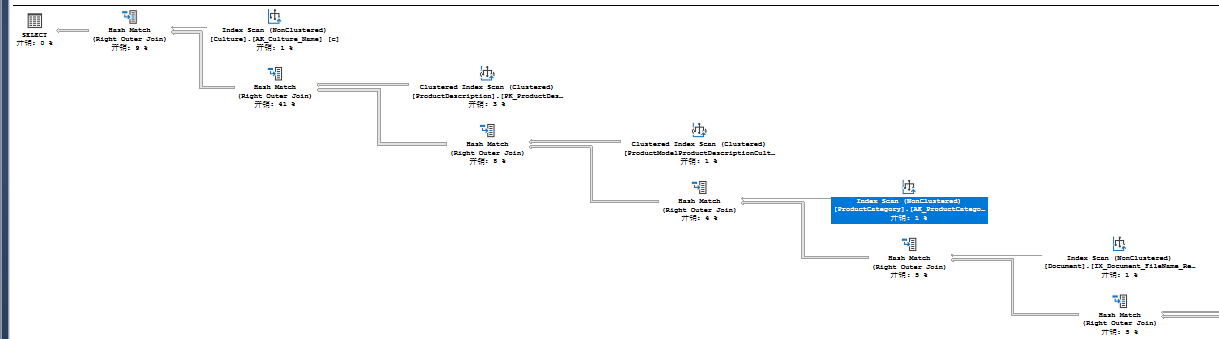
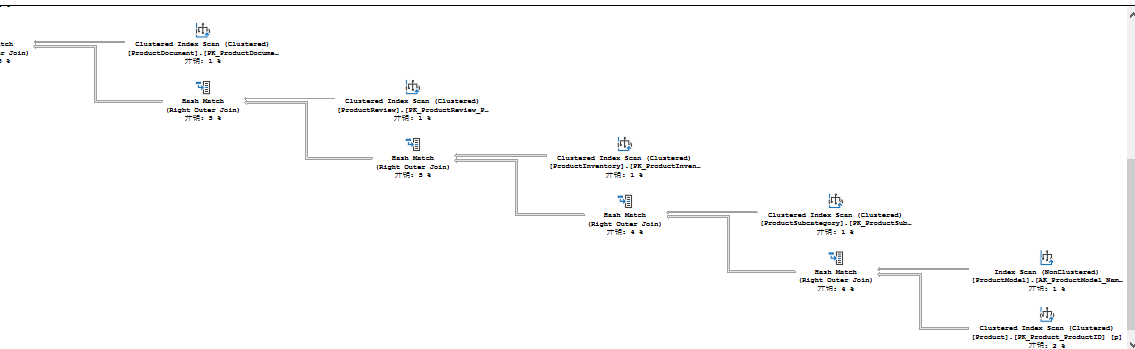
SELECT pc.Name AS ProductCategoryName ,
ps.Name AS ProductSubCategoryName ,
p.Name AS ProductName ,
pdr.Description ,
pm.Name AS ProductModelName ,
c.Name AS CultureName ,
d.FileName ,
pri.Quantity ,
pr.Rating ,
pr.Comments
FROM Production.Product AS p
LEFT JOIN Production.ProductModel AS pm ON p.ProductModelID = pm.ProductModelID
LEFT JOIN Production.ProductSubcategory AS ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
LEFT JOIN Production.ProductInventory AS pri ON p.ProductID = pri.ProductID
LEFT JOIN Production.ProductReview AS pr ON p.ProductID = pr.ProductID
LEFT JOIN Production.ProductDocument AS pd ON p.ProductID = pd.ProductID
LEFT JOIN Production.Document AS d ON pd.DocumentNode = d.DocumentNode
LEFT JOIN Production.ProductCategory AS pc ON ps.ProductCategoryID = pc.ProductCategoryID
LEFT JOIN Production.ProductModelProductDescriptionCulture AS pmpdc ON pm.ProductModelID = pmpdc.ProductModelID
LEFT JOIN Production.ProductDescription AS pdr ON pmpdc.ProductDescriptionID = pdr.ProductDescriptionID
LEFT JOIN Production.Culture AS c ON c.CultureID = pmpdc.CultureID;
加上option(force order);
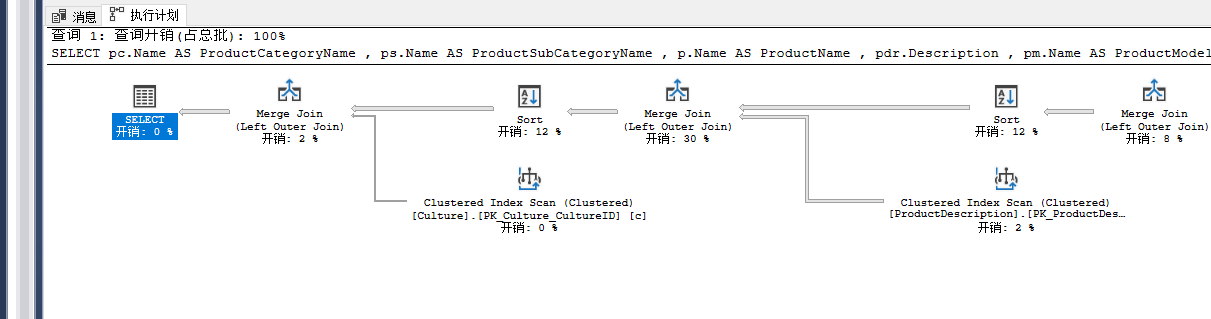
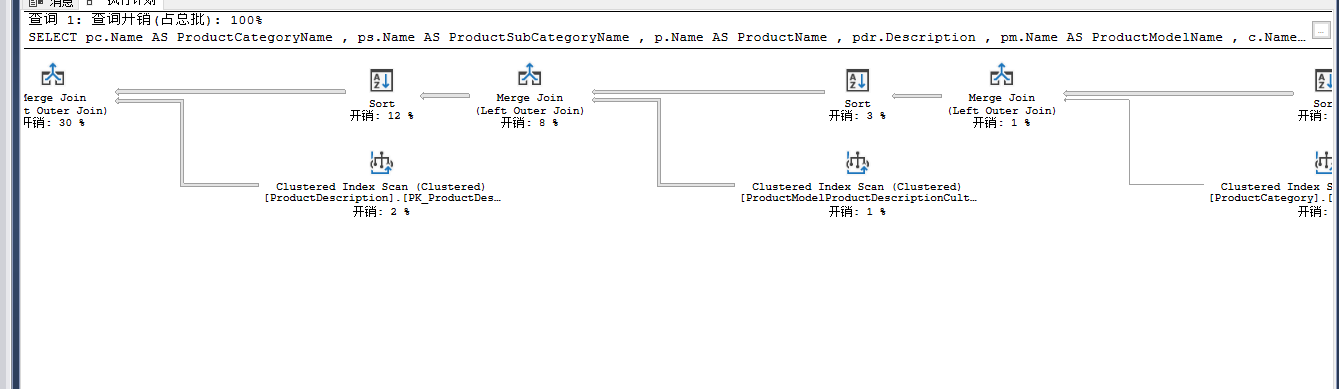
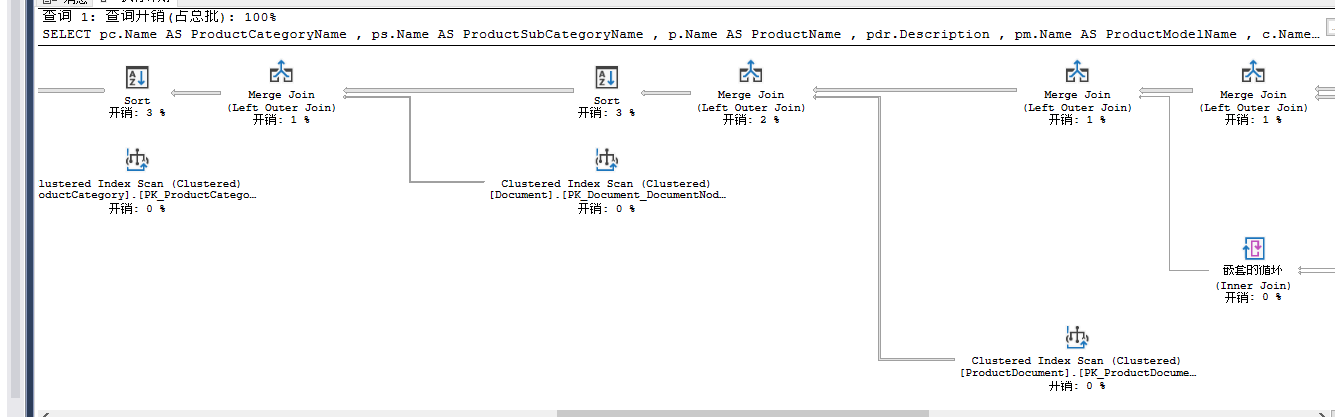
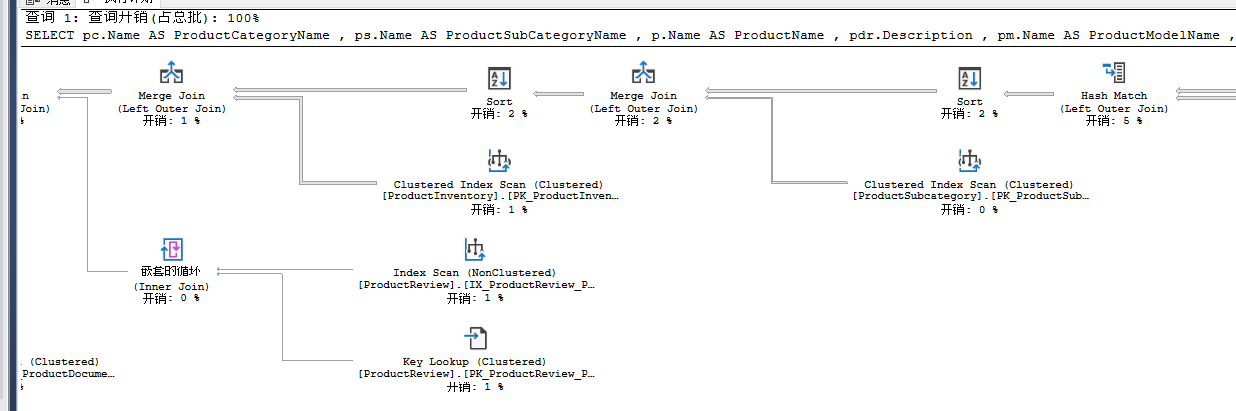
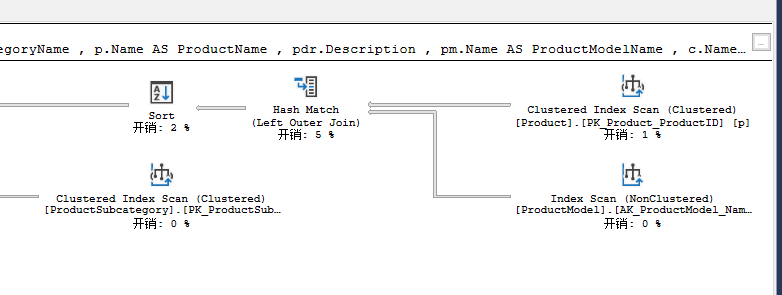
5.MAXDOP
有时候会出现两个执行计划:一个是实际的执行计划,一个是具有并行操作的执行计划,并行执行计划更慢,运行的开销已经超过了一个叫cost threshold for parallelism的值,优化器决定引入并行操作。
可以再语句级别就行控制
GO
sp_configure 'show advanced options',1
go
RECONFIGURE WITH OVERRIDE;
GO sp_configure 'cost threshold for parallelism', 1;
GO RECONFIGURE WITH OVERRIDE;
GO SELECT wo.DueDate ,
MIN(wo.OrderQty) MinOrderQty ,
MIN(wo.StockedQty) MinStockedQty ,
MIN(wo.ScrappedQty) MinScrappedQty ,
MAX(wo.OrderQty) MaxOrderQty ,
MAX(wo.StockedQty) MaxStockedQty ,
MAX(wo.ScrappedQty) MaxScrappedQty
FROM Production.WorkOrder wo
GROUP BY wo.DueDate
ORDER BY wo.DueDate;
GO
sp_configure 'cost threshold for parallelism', 50;
GO
RECONFIGURE WITH OVERRIDE;
GO
option(maxdop 1)
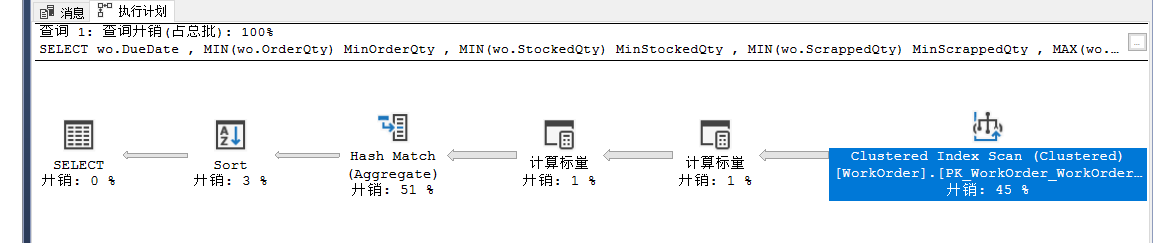
6.OPTIMIZE FOR
参数嗅探发生在存储过程中,参数化查询能够最大化地重用执行计划,优化器通过这些参数来评估索引等的情况。
select * from Person.Address where City='Mentor'
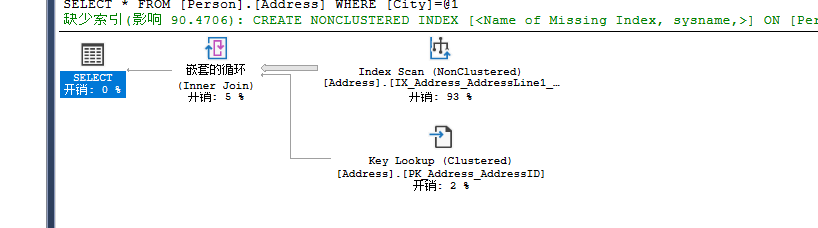
select * from Person.Address where City='London'
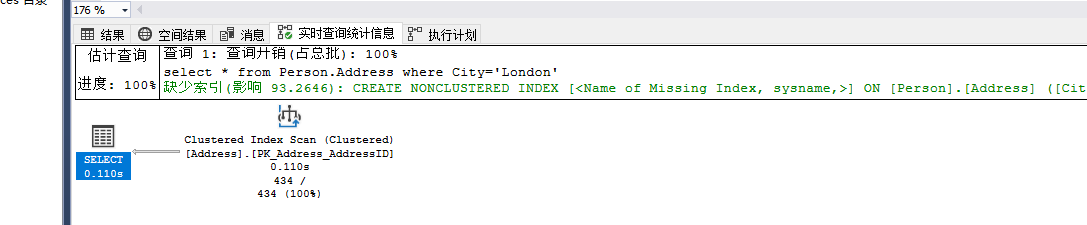
在同样的语句下,参数不同,会导致执行计划的不同,执行计划的不同主要是因为City=‘Mentor’具有较高的选择度,优化器可以使用查找操作,London这个参数导致选择度降低,这也致使优化器使用了扫描操作,而弃用了原有的非聚集索引
改写为参数化:
declare @city nvarchar(30)
set @city='Mentor'
select * from Person.Address where City=@city
set @city='London'
select * from Person.Address where city=@city
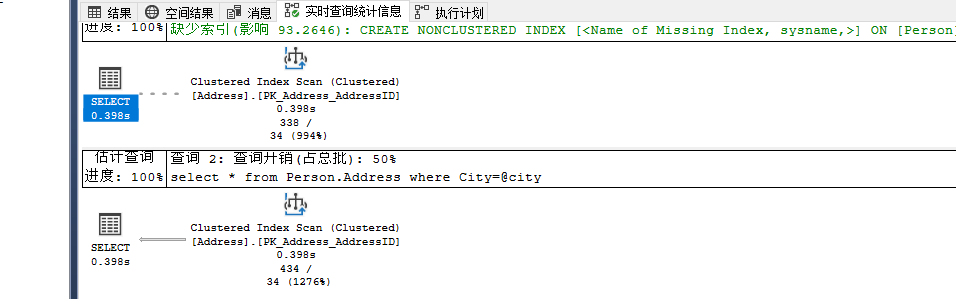
为什么使用聚集索引,因为优化器不知道你将要传入什么值,所以只能取统计信息中的平均值,平均值也较大,所以选择了扫描操作。
让优化器在第二个查询中使用Mentor值产生的执行计划作为该查询的执行计划。
declare @city nvarchar(30)
set @city='Mentor'
select * from Person.Address where City=@city
set @city='London'
select * from Person.Address where city=@city
option(optimize for(@city='Mentor'))
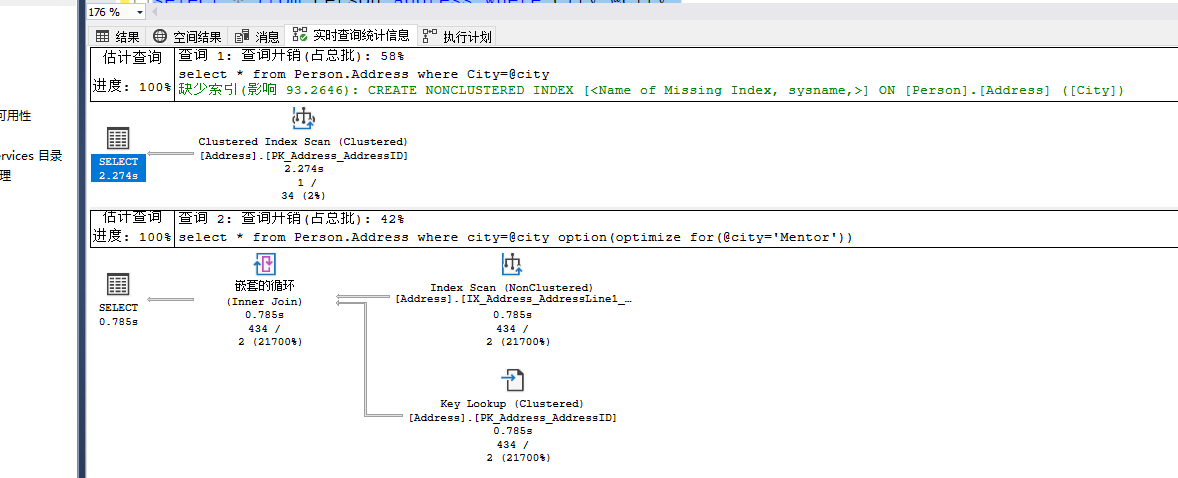
在无法预知参数时,这个提示是一个避免参数嗅探的较好的方法。
三:连接提示
物理关联算法只有Nested Loops、Merge Join、Hash Match Join3种
1.Nested Loops联接,从outer table(执行计划中位于上方的表)中读取一行,然后与inner table(执行计划中位于下方的表)中的每一行对比,并返回满足JOIN条件的行其算法的复杂度和两表的行数相乘之积成正比。对于小表来说非常高效
2.Merge联接:两个已经排序好的表(或者结构集),其算法复杂度与所有数据的总行数成正比。当所进行的连接是等于连接(关联中的等于操作)时,对于大数据集非常高效。
3.Hash Match联接,从一个输入表中读取所有的行,然后通过散列法,存入内存中的哈希表,并与另外一个表关联,如果满足JOIN条件,就返回。对于巨大的数据量,特别是数据仓库系统,是最有效的算法。
由于某些原因,改写关联算法可以从中获益。
(1)Nested Loops
SELECT pm.Name ,
pm.CatalogDescription ,
p.Name AS ProductName ,
i.Diagram
FROM Production.ProductModel pm
LEFT JOIN Production.Product p ON pm.ProductModelID = p.ProductModelID
LEFT JOIN Production.ProductModelIllustration pmi ON pm.ProductModelID = pmi.ProductModelID
LEFT JOIN Production.Illustration i ON pmi.IllustrationID = i.IllustrationID
WHERE pm.Name LIKE '%Mountain%'
ORDER BY pm.Name;
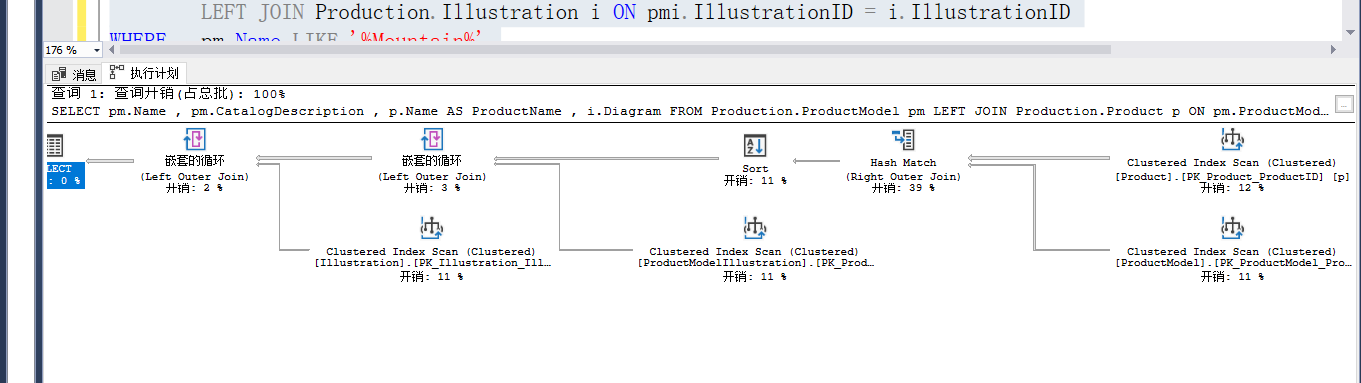
Hash Match占据了最大的开销、由于Where pm.name like '%mountain%'的存在,优化器使用不了列上的索引,所以选择聚集索引扫描,Order By 会导致Sort操作的发生。如果尝试把Hash Match换成Nested Loops,用于检查执行计划是否有性能问题。
select pm.Name,pm.CatalogDescription,i.Diagram from Production.ProductModel pm
left loop join Production.Product p on pm.ProductModelID =p.ProductModelID
left join Production.ProductModelIllustration pmi on pm.ProductModelID=pmi.ProductModelID
left join Production.Illustration i on pmi.IllustrationID=i.IllustrationID
where pm.Name like '%Mountain%'
order by pm.Name

改写后的查询效率更低。
Merger
把Loop提示改成Merger

三:表提示
表提示在很多地方都会用到,比如控制锁的行为。在生成执行计划的过程中,这种提示会控制优化器按照你指定的方式来使用特定的表。
对于表提示,建议用于测试和问题侦测,不建议常规化使用。
INDEX()
这个提示用于指定优化器使用特定索引来访问表,可以使用索引编号和索引名称,建议使用所以你名称
select de.Name,e.JobTitle,p.LastName+', '+p.FirstName from HumanResources.Department de
join HumanResources.EmployeeDepartmentHistory edh on de.DepartmentID=edh.DepartmentID
join HumanResources.Employee e on edh.BusinessEntityID=e.BusinessEntityID
join Person.Person p on e.BusinessEntityID=p.BusinessEntityID
where de.Name like 'P%'

来指定HumanResources.Department表上的pk_Department_DepartmentID索引
select de.Name,e.JobTitle,p.LastName+', '+p.FirstName
from HumanResources.Department de with(index(pk_Department_DepartmentID))
join HumanResources.EmployeeDepartmentHistory edh on de.DepartmentID=edh.DepartmentID
join HumanResources.Employee e on edh.BusinessEntityID=e.BusinessEntityID
join Person.Person p on e.BusinessEntityID=p.BusinessEntityID
where de.Name like 'P%'

扩展信息:
1.阅读庞大的执行计划
IF OBJECT_ID('Sales.uspGetDiscountRates', 'P') IS NOT NULL
DROP PROCEDURE Sales.uspGetDiscountRates;
go
CREATE PROCEDURE Sales.uspGetDiscountRates
(
@BusinessEntityId INT ,
@SpecialOfferId INT
)
as
begin TRY
IF EXISTS ( SELECT *
FROM Person.Person AS p
INNER JOIN Sales.Customer AS c ON p.BusinessEntityID = c.PersonID
INNER JOIN Sales.SalesOrderHeader AS soh ON soh.CustomerID = c.CustomerID
INNER JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Sales.SpecialOffer AS spo ON sod.SpecialOfferID = spo.SpecialOfferID
WHERE p.BusinessEntityID = @BusinessEntityId
AND spo.[SpecialOfferID] = @SpecialOfferId )
BEGIN
SELECT p.LastName + ', ' + p.FirstName ,
ea.EmailAddress ,
p.Demographics ,
spo.Description ,
spo.DiscountPct ,
sod.LineTotal ,
pr.Name ,
pr.ListPrice ,
sod.UnitPriceDiscount
FROM Person.Person AS p
INNER JOIN Person.EmailAddress AS ea ON p.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Sales.Customer AS c ON p.BusinessEntityID = c.PersonID
INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID
INNER JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Sales.SpecialOffer AS spo ON sod.SpecialOfferID = spo.SpecialOfferID
INNER JOIN Production.Product pr ON sod.ProductID = pr.ProductID
WHERE p.BusinessEntityID = @BusinessEntityId
AND sod.[SpecialOfferID] = @SpecialOfferId;
END
ELSE
BEGIN
SELECT p.LastName + ', ' + p.FirstName ,
ea.EmailAddress ,
p.Demographics ,
soh.SalesOrderNumber ,
sod.LineTotal ,
pr.Name ,
pr.ListPrice ,
sod.UnitPrice ,
st.Name AS StoreName ,
ec.LastName + ', ' + ec.FirstName AS SalesPersonName
FROM Person.Person AS p
INNER JOIN Person.EmailAddress AS ea ON p.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Sales.Customer AS c ON p.BusinessEntityID = c.PersonID
INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID
INNER JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product AS pr ON sod.ProductID = pr.ProductID
LEFT JOIN Sales.SalesPerson AS sp ON soh.SalesPersonID = sp.BusinessEntityID
LEFT JOIN Sales.Store AS st ON sp.BusinessEntityID = st.SalesPersonID
LEFT JOIN HumanResources.Employee AS e ON st.BusinessEntityID = e.BusinessEntityID
LEFT JOIN Person.Person AS ec ON e.BusinessEntityID = ec.BusinessEntityID
WHERE p.BusinessEntityID = @BusinessEntityId;
END
IF @SpecialOfferId = 16
BEGIN
SELECT p.Name ,
p.ProductLine
FROM Sales.SpecialOfferProduct sop
INNER JOIN Production.Product p ON sop.ProductID = p.ProductID
WHERE sop.SpecialOfferID = 16;
END
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ErrorNumber ,
ERROR_MESSAGE() AS ErrorMessage;
RETURN ERROR_NUMBER();
END CATCH
RETURN 0;
调用
EXEC Sales.uspGetDiscountRates
@BusinessEntityId=1423,
@SpecialOfferId=16
SQL Server控制执行计划的更多相关文章
- SQL Server 优化-执行计划
对于SQL Server的优化来说,优化查询可能是很常见的事情.由于数据库的优化,本身也是一个涉及面比较的广的话题, 因此本文只谈优化查询时如何看懂SQL Server查询计划.毕竟我对SQL Ser ...
- 了解Sql Server的执行计划
前一篇总结了Sql Server Profiler,它主要用来监控数据库,并跟踪生成的sql语句.但是只拿到生成的sql语句没有什么用,我们可以利用这些sql语句,然后结合执行计划来分析sql语句的性 ...
- SQL Server实际执行计划COST"欺骗"案例
有个系统,昨天Support人员发布了相关升级脚本后,今天发现系统中有个功能不能正常使用了,直接报超时了(Timeout expired)的错误.定位到相关相关存储过程后,然后在优化分析的过程中,又遇 ...
- 程序员眼中的 SQL Server-执行计划教会我如何创建索引?
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- SQL SERVER 2012 执行计划走嵌套循环导致性能问题的案例
开发人员遇到一个及其诡异的的SQL性能问题,这段完整SQL语句如下所示: declare @UserId INT declare @PSANo VAR ...
- SQL Server-执行计划教会我如何创建索引
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- Sql Server中执行计划的缓存机制
Sql查询过程 当执行一个Sql语句或者存储过程时, Sql Server的大致过程是 1. 对查询语句进行分析,将其生成逻辑单元,并进行基本的语法检查 2. 生成查询树(会将查询语句中所有操作转换为 ...
- sql server 根据执行计划查询耗时操作
with QS as( select cp.objtype as object_type, /*类型*/ db_name(st.dbid) as [database], /*数据库*/ object_ ...
- sql server 2008 执行计划
SSMS允许我们查看一个图形化的执行计划(快捷键Ctrl+L)
随机推荐
- 手写代码注意点--java.util.Stack相关
1-Stack的基本函数为: 注意: 取栈顶的函数为peek(),不是top()... 测试stack是否为空的函数为empty(),不是isEmpty()...
- Go语言中的结构体 (struct)
Golang官方称Go语言的语法相对Java语言而言要简洁很多,但是简洁背后也灵活了很多,所以很多看似很简单的代码上的细节稍不注意就会产生坑.本文主要对struct结构体的相关的语法进行总结和说明. ...
- git-bisect last updated in 2.19.1【转】
转自:https://git-scm.com/docs/git-bisect NAME git-bisect - Use binary search to find the commit that i ...
- canner CMS 系统 (公司在台湾) https://www.canner.io/
canner CMS 系统 (公司在台湾) https://www.canner.io/ https://github.com/Canner/canner 一种创新的CMS构建方式,采用 Nodej ...
- 关于CactiEZ自定义气象图的配置
作者:邓聪聪 主要目录: Weathermap主目录:/var/www/html/plugins/weathermap 图片目录(包含背景图标文件):/var/www/html/plugins/wea ...
- Ajax使用formdata异步上传文件,报错the request was rejected because no multipart boundary was found
基于jQuery的Ajaxs使用FormData上传文件要注意两个参数的设定 processData设为false 把processData设为false,让jquery不要对formData做处理, ...
- TCP与UDP区别小结
TCP(Transmission Control Protocol):传输控制协议 UDP(User Datagram Protocol):用户数据报协议 主要从连接性(Connectiv ...
- ssdb主从及双主模型配置和简单管理
ssdb主从及双主模型配置和简单管理 levelDB是一个key->value 的数据存储库,其只能在本地保存数据,支持持久化,并且支持保存非常大的数据,单机redis在保存较大数据的时候数十G ...
- python 基础 Two day
1.格式化输出 %s 字符串 %d 数字 %% 转义 % %f 小数 现在有以下需求,让用户输入name, age, job,hobby 然后输出如下所示: ------------ i ...
- 【原创】Linux基础之测试域名IP端口连通性
一 测试域名是否可达 1 ping # ping www.baidu.comPING www.a.shifen.com (220.181.112.244) 56(84) bytes of data.6 ...