决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

决策树优点和缺点
决策树优点
1.简单易懂,很好解读,可视化
2.可以变量筛选

缺点
1.决策树不稳定,容易过渡拟合
2.决策树用的贪婪算法,返回局部最优,而非全局最优,最后得到有偏见的树
(用随机森林改善)

分类树VS回归树
回归树应用场景:变量是连续性的,使用平均数参数
分类树应用场景:变量是分类型的,使用众数参数
树的延伸太多,会造成过渡拟合,返回局部最优,即对测试数据表现良好,但对未知数据表现很差,可以限制树深度和叶子节点来改善准确性

pruning是可以限制树深度和叶子节点来改善准确性

决策树应用
1.信用评分
2.泰坦尼克号生存分析
3.根据身高和体重判断人的性别
................

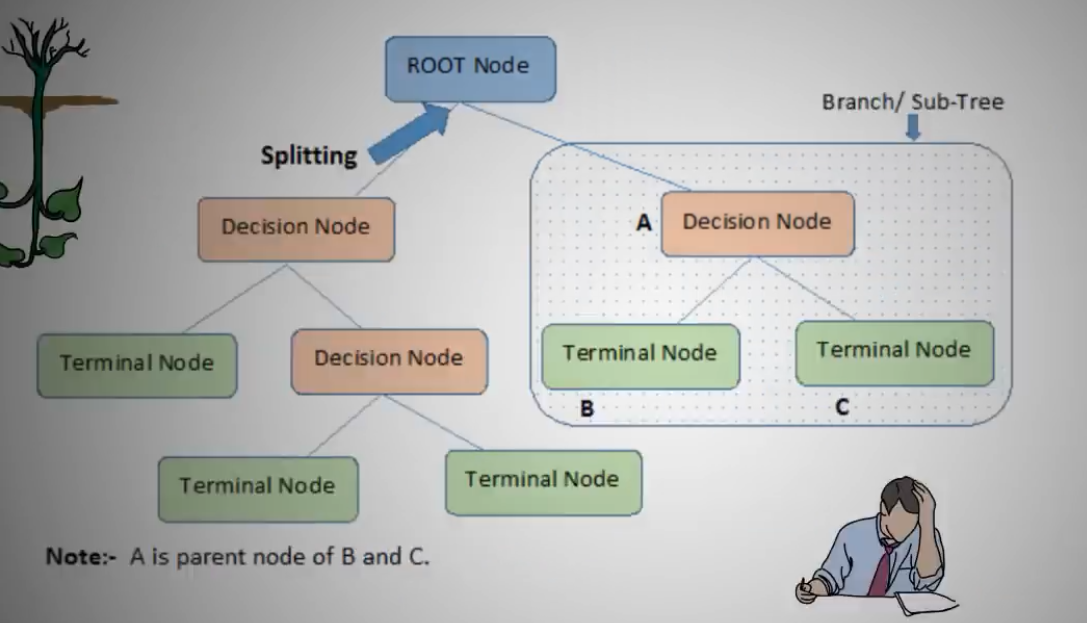
决策树组成
决策树由root node根节点,decision node决策点,terminall node终端点组成


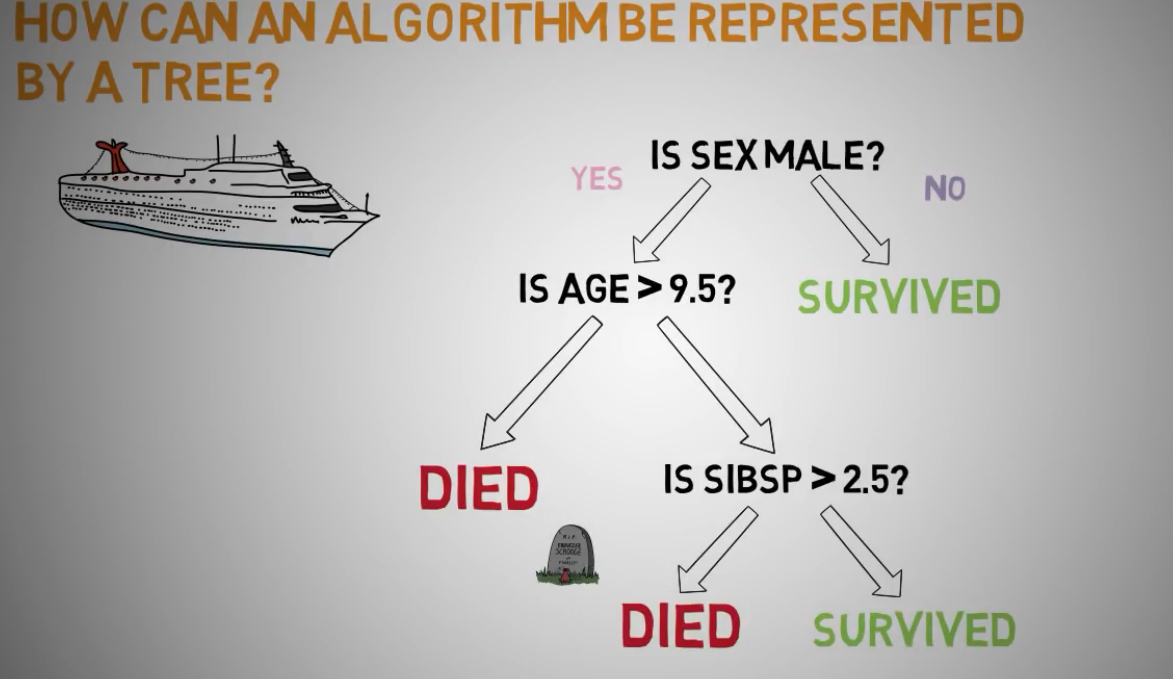
泰坦尼克号决策树的应用分析
第一个最显著因子是性别,如果是女性存活
如果是男性,有的死了,有的活了
如果是年龄大于9.5岁男性,死了
如果年龄小于9.5岁男性,且有兄弟姐妹年龄大于2.5岁的,死了
如果年龄小于9.5岁男性,且有兄弟姐妹年龄小于2.5岁的,存活
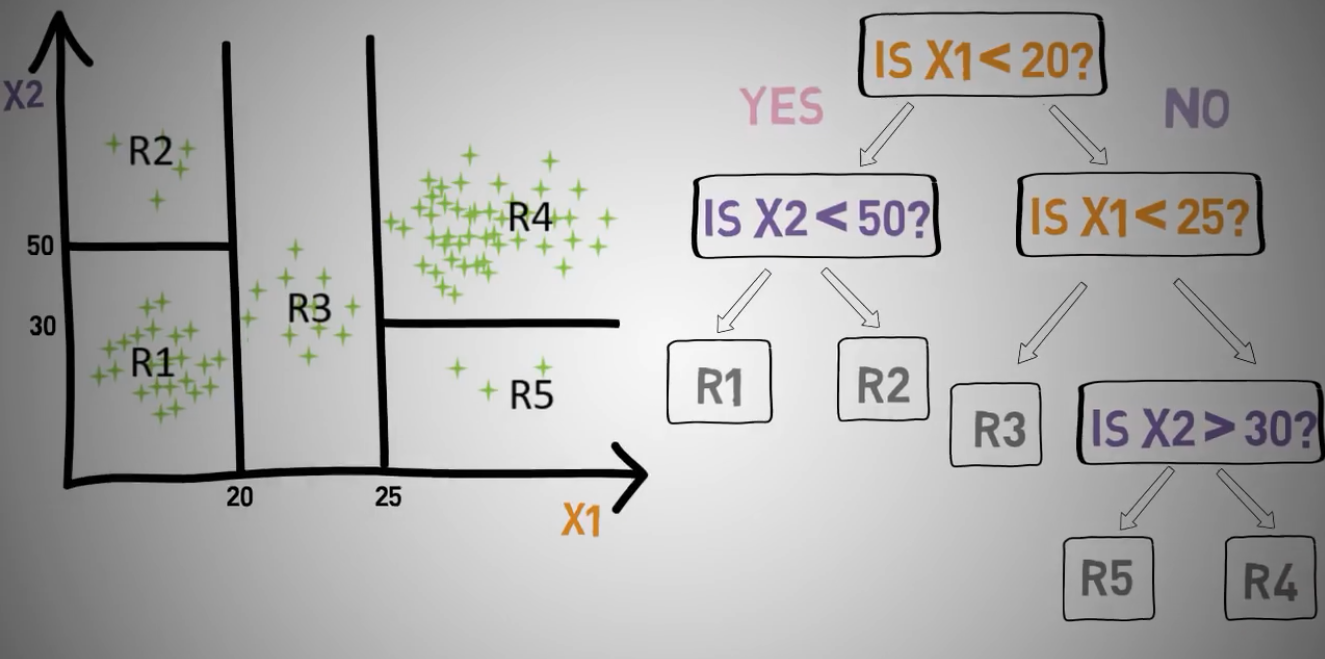
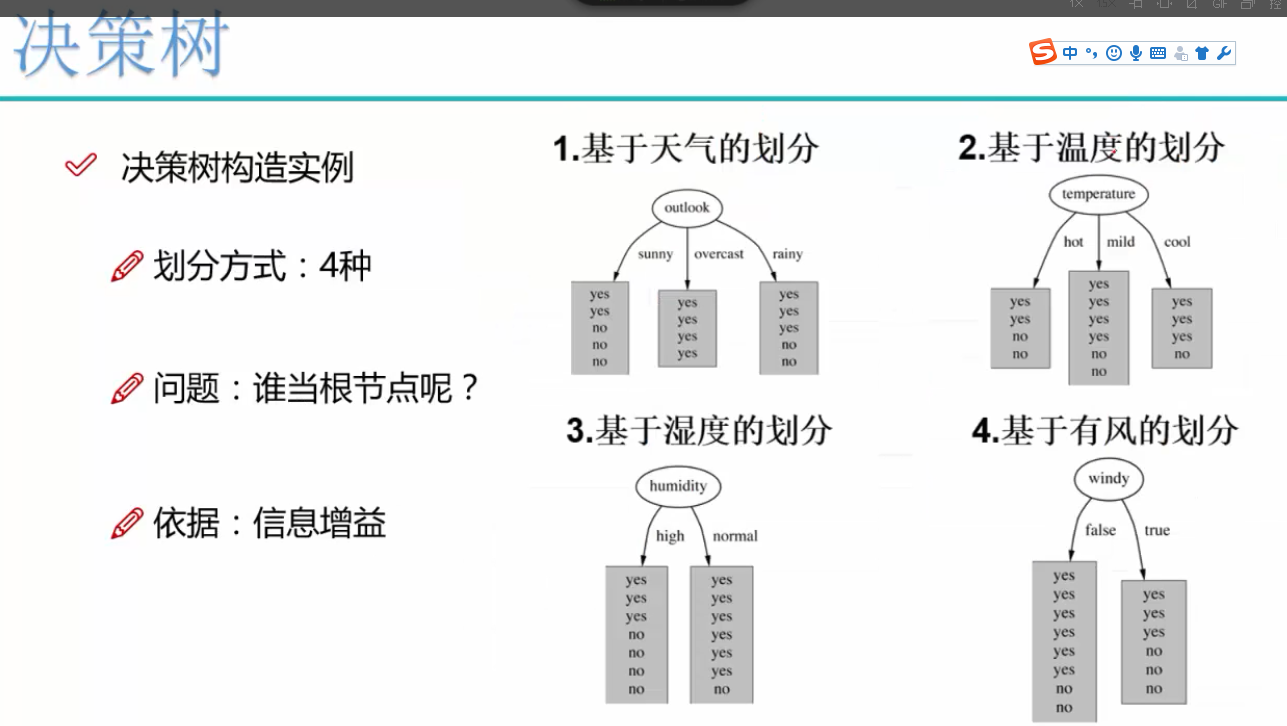
决策树举例
把一组数据划分为五个对象,通过x1的两个节点20和25
x2的两个节点30和50,来划分这五个对象
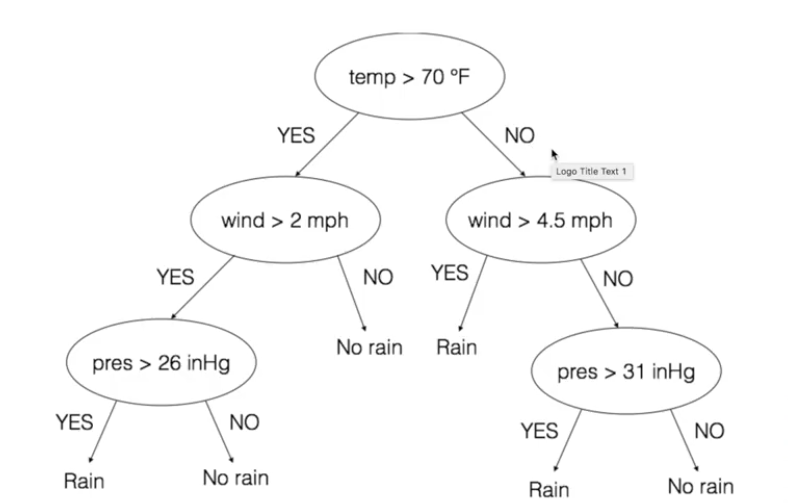
决策树举例:降雨是由气温,风速,气压共同决定
决策树对水果分类应用



先选大当家,再选二当家,根据熵值

熵值越大,混乱程度和不确定性越大

x概率越大,熵值y越小
x概率越小,熵值y越大
因为x取值范围是从0-1,得到log值是负数,所以公式前面有个负号,让值最终为正数
求和符号是对一个数据集的每个数字求熵值,然后累加
log底数是2

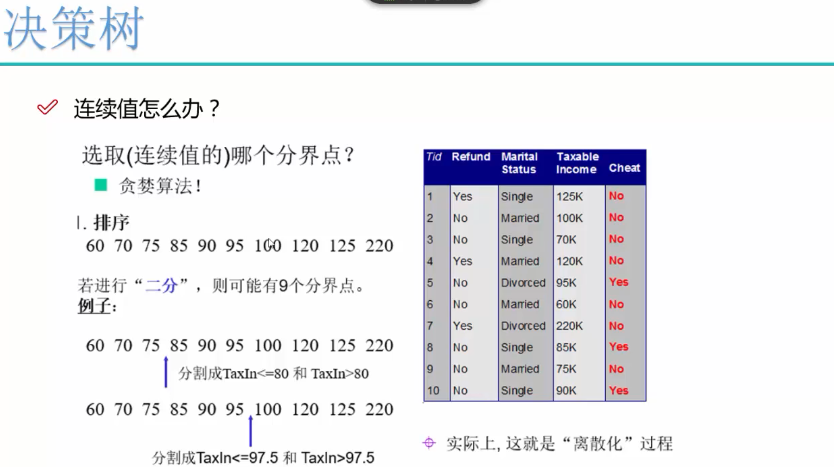
信息增益

举例



ID3算法对于小样本数据效果差,算出来信息增益很大
C4.5算法考虑自身熵,做了改进
cart和Gini系数算法现在用的多
另外还有卡方算法和减少方差算法


基尼系数GINI index
用于区分两个类别的分离程度如何,基尼系数=0.5,说明两个类别数量一致,无区分程度,如果基尼系数=0,说明两个类别区分度最明显



预剪枝用的比较多,避免过渡拟合

sklearn有很好可视化效果
信息增益小于某个值时,也可以限制

限制叶子节点个数
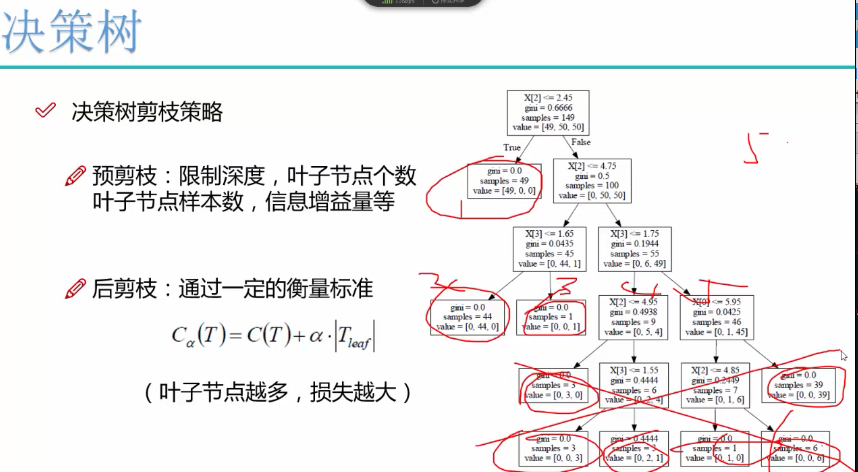
限制叶子节点深度

python代码构建乳腺癌细胞分类器
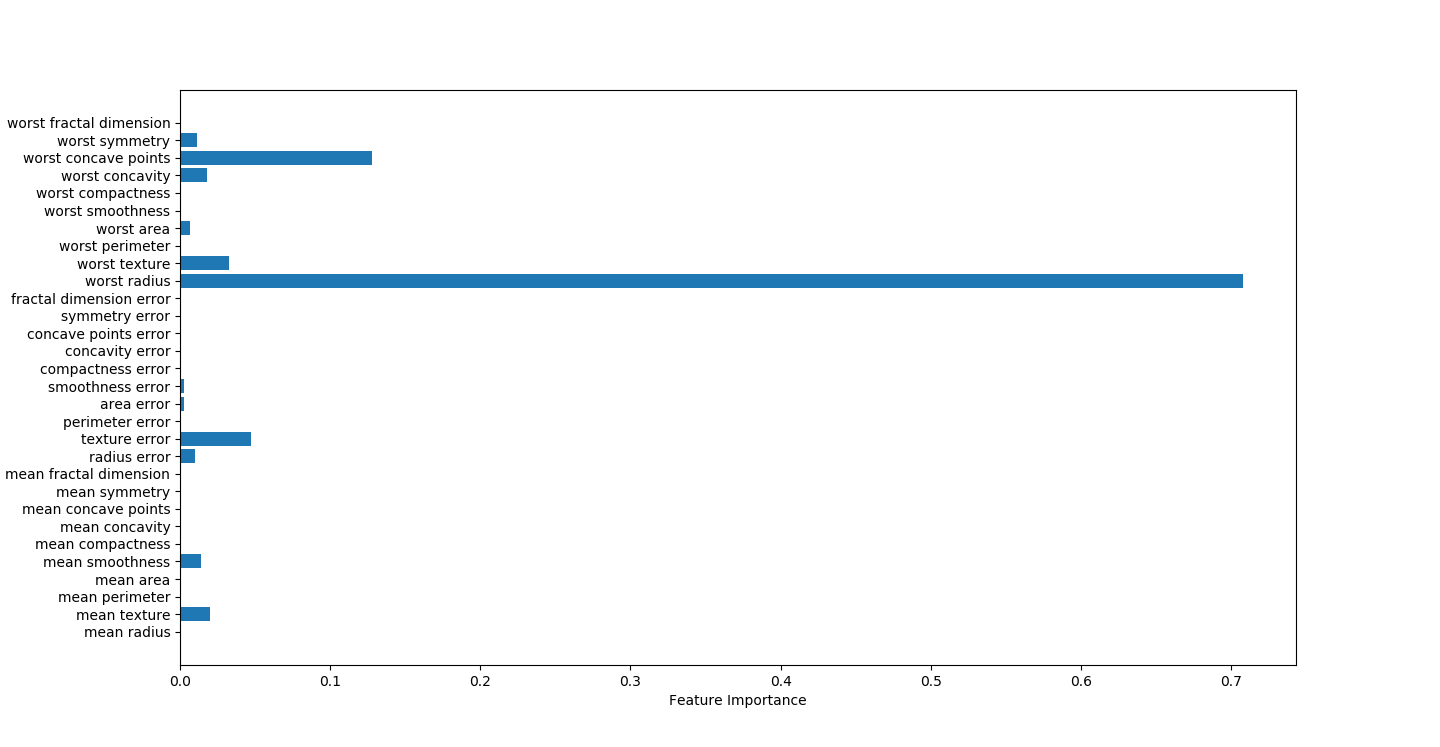
决策树可视化因子结果,worst radius影响因素最大
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 27 22:59:44 2018
@author: Toby,项目合作QQ:231469242
radius半径
texture结构,灰度值标准差
symmetry对称
决策树找出强因子
worst radius
worst symmetry
worst texture
texture error
"""
import csv,pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import pydotplus
from IPython.display import Image
import graphviz
from sklearn.tree import export_graphviz
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
cancer=load_breast_cancer()
featureNames=cancer.feature_names
#random_state 相当于随机数种子
X_train,x_test,y_train,y_test=train_test_split(cancer.data,cancer.target,stratify=cancer.target,random_state=42)
list_average_accuracy=[]
depth=range(1,30)
for i in depth:
#max_depth=4限制决策树深度可以降低算法复杂度,获取更精确值
tree= DecisionTreeClassifier(max_depth=i,random_state=0)
tree.fit(X_train,y_train)
accuracy_training=tree.score(X_train,y_train)
accuracy_test=tree.score(x_test,y_test)
average_accuracy=(accuracy_training+accuracy_test)/2.0
#print("average_accuracy:",average_accuracy)
list_average_accuracy.append(average_accuracy)
max_value=max(list_average_accuracy)
#索引是0开头,结果要加1
best_depth=list_average_accuracy.index(max_value)+1
print("best_depth:",best_depth)
best_tree= DecisionTreeClassifier(max_depth=best_depth,random_state=0)
best_tree.fit(X_train,y_train)
accuracy_training=best_tree.score(X_train,y_train)
accuracy_test=best_tree.score(x_test,y_test)
print("decision tree:")
print("accuracy on the training subset:{:.3f}".format(best_tree.score(X_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(best_tree.score(x_test,y_test)))
#print('Feature importances:{}'.format(best_tree.feature_importances_))
#绘图,显示因子重要性
n_features=cancer.data.shape[1]
plt.barh(range(n_features),best_tree.feature_importances_,align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.title("Decision Tree:")
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
#生成一个dot文件,以后用cmd形式生成图片
export_graphviz(tree,out_file="cancertree.dot",class_names=['malignant','benign'],feature_names=cancer.feature_names,impurity=False,filled=True)
决策树可视化
安装graphviz官网介绍
https://blog.csdn.net/lanchunhui/article/details/49472949
安装包graphviz
pip install graphviz
#生成一个dot文件,文件存放于脚本所在位置
以后用cmd形式生成图片,
export_graphviz(tree,out_file="cancertree.dot",class_names=['malignant','benign'],feature_names=cancer.feature_names,impurity=False,filled=True)
cmd切换路径到脚本所在位置,然后输入dot -Tpng cancertree.dot -o cancertree.png
生成一个决策树的图片
生成图片打开预览

决策树交叉验证代码
交叉验证结果0.92左右

import csv,pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import pydotplus
from IPython.display import Image
import graphviz
from sklearn.tree import export_graphviz
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
from sklearn.model_selection import train_test_split
#交叉验证样本平均测试,评分更加
from sklearn.cross_validation import cross_val_score #交叉验证得分,返回数组
#score_decisionTree=cross_val_score(decisionTree,x,y,cv=5,scoring='accuracy')
#print("cross value decisionTree= score:",score_decisionTree.mean()) cancer=load_breast_cancer()
#数据
data=cancer.data
#分类
target=cancer.target
x=data
y=target featureNames=cancer.feature_names
#5.决策树
#建立决策树分类器
decisionTree= tree.DecisionTreeClassifier(max_depth=5)
#交叉验证得分,返回数组
score_decisionTree=cross_val_score(decisionTree,x,y,cv=10,scoring='accuracy')
print("cross value decisionTree= score:",score_decisionTree.mean())

微信扫二维码,免费学习更多python资源

决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)的更多相关文章
- 机器学习方法(四):决策树Decision Tree原理与实现技巧
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 前面三篇写了线性回归,lass ...
- 神经网络1_neuron network原理_python sklearn建模乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- 数据挖掘 决策树 Decision tree
数据挖掘-决策树 Decision tree 目录 数据挖掘-决策树 Decision tree 1. 决策树概述 1.1 决策树介绍 1.1.1 决策树定义 1.1.2 本质 1.1.3 决策树的组 ...
- 机器学习算法实践:决策树 (Decision Tree)(转载)
前言 最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象.本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决 ...
- 机器学习-决策树 Decision Tree
咱们正式进入了机器学习的模型的部分,虽然现在最火的的机器学习方面的库是Tensorflow, 但是这里还是先简单介绍一下另一个数据处理方面很火的库叫做sklearn.其实咱们在前面已经介绍了一点点sk ...
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- 决策树 Decision Tree
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布.树的最顶层是根结点.  决策树的构建 想要构建一个决策树,那么咱们 ...
随机推荐
- 彻底弄懂 HTTP 缓存机制及原理 | 干货
来源:www.cnblogs.com/chenqf/p/6386163.html 前言 Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系库中的一个 ...
- puppet一些常用的参数
puppet一些常用的参数 通过@,realize来定义使用虚拟资源 虚拟资源主要来解决在安装包的时候,互相冲突的问题 具体参考这里 简单说下,在定义资源的时候加上@ 例如: @package { & ...
- js窗体间传值
A页面传值给 B页面 页面A <html xmlns="http://www.w3.org/1999/xhtml"> <HEAD> <TITLE> ...
- ALGO-19 审美课
算法训练 审美课 时间限制:1.0s 内存限制:256.0MB 问题描述 <审美的历程>课上有n位学生,帅老师展示了m幅画,其中有些是梵高的作品,另外的都出自五岁小朋 ...
- Chessboard POJ - 2446(最大流 || 匹配)
there is a pair of integers (x, y) in each line, which represents a hole in the y-th row, the x-th c ...
- 【BZOJ2655】calc DP 数学 拉格朗日插值
题目大意 一个序列\(a_1,\ldots,a_n\)是合法的,当且仅当: 长度为给定的\(n\). \(a_1,\ldots,a_n\)都是\([1,m]\)中的整数. \(a_1, ...
- 【Tsinsen A1339】JZPLCM (树状数组)
Description 原题链接 给定一长度为\(~n~\)的正整数序列\(~a~\),有\(~q~\)次询问,每次询问一段区间内所有数的\(~LCM~\)(即最小公倍数).由于答案可能很大,输出 ...
- nfs的配置文件/etc/exports
/etc/exports 文件格式 <输出目录> [客户端1 选项(访问权限,用户映射,其他)] [客户端2 选项(访问权限,用户映射,其他)] a. 输出目录:输出目录是指NFS系统中 ...
- [luogu3246][bzoj4540][HNOI2016]序列【莫队+单调栈】
题目描述 给定长度为n的序列:a1,a2,...,an,记为a[1:n].类似地,a[l:r](1<=l<=r<=N)是指序列:al,al+1,...,ar-1,ar.若1<= ...
- css基本语法及页面引用
css基本语法 css的定义方法是: 选择器 { 属性:值; 属性:值; 属性:值;} 选择器是将样式和页面元素关联起来的名称,属性是希望设置的样式属性每个属性有一个或多个值.代码示例: div{ w ...