innodb二阶段日志提交机制和组提交解析
前些天在查看关于innodb_flush_log_at_trx_commit的官网解释时产生了一些疑问,关于innodb_flush_log_at_trx_commit参数的详细解释参见官网:
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
InnoDB log buffer are written to the log file after each transaction commit and the log file is flushed to disk approximately once per second.
注意redo和undo是在事务执行过程中就即时生成的,且早于数据库真正被修改,这被称作write ahead logging(WAL),undo的disk文件位置默认在系统表空间中,5.6以后也可以指定独立的undo表空间。
- sync_binlog=0:表示fsync()的调用完全交给操作系统,即文件系统缓存中的binlog是否刷新到disk完全由操作系统控制。
- sync_binlog=1:表示在发出事务提交请求时,binlog一定会被固化到disk,write()跳过文件系统缓存直接写入disk。
- sync_binlog=N(N>1):数据库崩溃时,可能会丢失N-1个事务。
- 此值为0表示:redo log buffer的内容每秒会被写入文件系统缓存的redo log里,同时被flush(固化)到disk上的redo log file中。
- 此值为1表示:redo log buffer的内容会在事务commit时被写入文件系统缓存的redo log里,同时被flush(固化)到disk上的redo log file中。
- 此值为2表示:redo log buffer的内容会在事务commit时被写入文件系统缓存的redo log里,而文件系统缓存的redo log每秒一次被flush(固化)到disk上的redo log file中。
以上介绍的使用 prepare_commit_mutex 来保证事务提交的顺序,只有当上一个事务 commit 后释放锁,下个事务才可以进行 prepare 操作,这样并发事务之间的mutex争用可能比较高。
此外由于内存数据写入磁盘的开销很大,如果频繁 fsync() 把日志数据永久写入磁盘,数据库的性能将会急剧下降。高并发事务带来的频繁磁盘写会导致事务提交等待带来性能瓶颈,为此提供 sync_binlog 参数来设置多少个 binlog 日志产生的时候调用一次 fsync() 把二进制日志刷入磁盘来提高整体性能,但这可能导致主从不一致。
因此针对innodb事务出现了binlog的组提交方式,其大致原理就是将多个并发事务的binlog(3个以上)通过队列批次写入磁盘,从而减小磁盘写次数,也避免了prepare_commit_mutex 的争用。
改进方案:
Mysql5.6 引入了组提交,并将提交过程分成 Flush stage、Sync stage、Commit stage 三个阶段。其实简单的说就是加入队列机制使得binlog写入顺序与事务执行顺序一致,加入队列的最大好处就是可以不获取prepare_commit_mutex锁也能实现不降低性能的日志顺序写。
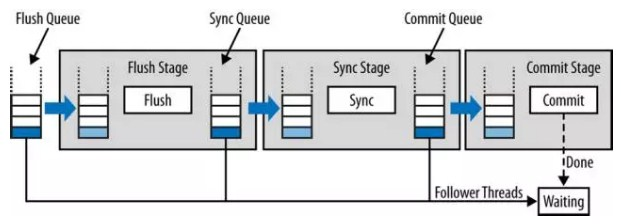
Binlog组提交的基本思想是,引入队列机制保证Innodb commit顺序与binlog落盘顺序一致,并将事务分组,组内的binlog刷盘动作交给一个事务进行,实现组提交目的。在MySQL数据库上层进行提交时首先按顺序将其放入一个队列中,队列中的第一个事务称为leader,其他事务称为follow,leader控制着follow的行为。
- Flush Stage
1) 持有Lock_log mutex [leader持有,follower等待]。
2) 获取队列中的一组binlog(队列中的所有事务)。
3) 将binlog buffer到I/O cache。
4) 通知dump线程dump binlog。
- Sync Stage
1) 释放Lock_log mutex,持有Lock_sync mutex[leader持有,follower等待]。
2) 将一组binlog 落盘(sync动作,最耗时,假设sync_binlog为1)。
- Commit Stage
1) 释放Lock_sync mutex,持有Lock_commit mutex[leader持有,follower等待]。
2) 遍历队列中的事务,逐一进行innodb commit。
3) 释放Lock_commit mutex。
4) 唤醒队列中等待的线程。
说明:由于有多个队列,每个队列各自有mutex保护,队列之间是顺序的,约定进入队列的一个线程为leader,因此FLUSH阶段的leader可能是SYNC阶段的follower,但是follower永远是follower。当有一组事务在进行commit阶段时,其他新事物可以进行Flush阶段,从而使group commit不断生效。当然group commit的效果由队列中事务的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多,甚至会更差。但当提交的事务越多时,group commit的效果越明显,数据库性能的提升也就越大。
与 binlog 组提交相关的参数主要包括了如下两个:
- binlog_max_flush_queue_time
单位为微秒,用于从 flush 队列中取事务的超时时间,这主要是防止并发事务过高,导致某些事务的 RT 上升,详细内容可以查看函数MYSQL_BIN_LOG::process_flush_stage_queue() 。
注意:该参数在 5.7 之后已经取消了。
- binlog_order_commits
当设置为 0 时,事务可能以和 binlog 不同的顺序提交,其性能会有稍微提升,但并不是特别明显.
innodb二阶段日志提交机制和组提交解析的更多相关文章
- MySQL组提交(group commit)
MySQL组提交(group commit) 前提: 以下讨论的前提 是设置MySQL的crash safe相关参数为双1: sync_binlog=1 innodb_flush_log_at_trx ...
- mysql 5.6 binlog组提交
mysql 5.6 binlog组提交实现原理 http://blog.itpub.net/15480802/viewspace-1411356 Redo组提交 Redo提交流程大致如下 lock l ...
- mysql 5.6 binlog组提交实现原理(转载)
http://blog.itpub.net/15480802/viewspace-1411356/ Redo组提交 Redo提交流程大致如下 lock log->mutex write redo ...
- mysql复制那点事(2)-binlog组提交源码分析和实现
mysql复制那点事(2)-binlog组提交源码分析和实现 [TOC] 0. 参考文献 序号 文献 1 MySQL 5.7 MTS源码分析 2 MySQL 组提交 3 MySQL Redo/Binl ...
- InnoDB事务的二阶段提交
问题: 什么是二阶段提交 为什么需要二阶段提交 二阶段提交流程 什么是二阶段提交? ### 假设原来id 为10 的记录age 为5 begin; update student set age = 1 ...
- (转)MySQL 日志组提交
原文:https://jin-yang.github.io/post/mysql-group-commit.html 组提交 (group commit) 是为了优化写日志时的刷磁盘问题,从最初只支持 ...
- MYSQL学习笔记3--mysql 2PC二阶段协义 与 日志闪回
mysql两份日志: binlog :server innodb redo log:engine 两份日志顺序一致性:否则主备不一致 两份日志:原子性,同时都有,同时都无 2PC二阶段协义: 第一阶段 ...
- MySQL binlog 组提交与 XA(两阶段提交)
1. XA-2PC (two phase commit, 两阶段提交 ) XA是由X/Open组织提出的分布式事务的规范(X代表transaction; A代表accordant?).XA规范主要定义 ...
- MySQL binlog 组提交与 XA(分布式事务、两阶段提交)【转】
概念: XA(分布式事务)规范主要定义了(全局)事务管理器(TM: Transaction Manager)和(局部)资源管理器(RM: Resource Manager)之间的接口.XA为了实现分布 ...
随机推荐
- MFC控件编程之鼠标跟键盘消息
MFC控件编程之鼠标跟键盘消息 在MFC中鼠标消息.键盘消息我们很常用.所以说一下. 鼠标消息分为客户区消息.跟非客户区消息. 一丶客户区消息 我们可以处理消息.来进行我们相应的函数即可. MFC添加 ...
- 简单了解static
初学java,面对着这个static修饰符,愣是琢磨了两天时间,还在今天琢磨透了,现在将悟到的东西记录下来: 1.static修饰符表示静态修饰符,其所修饰的内容(变量.方法.代码块暂时学到这三种)统 ...
- Jenkins持续集成介绍及插件安装版本更新演示(一)--技术流ken
Jenkins介绍 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能. Jenkins功能包括: ...
- linux四剑客-grep/find/sed/awk/详解-技术流ken
四剑客简介 相信接触过linux的大家应该都学过或者听过四剑客,即sed,grep,find,awk,有人对其望而生畏,有人对其爱不释手.参数太多,变化形式太多,使用超级灵活,让一部分人难以适从继而望 ...
- Spring Cloud Stream消费失败后的处理策略(一):自动重试
之前写了几篇关于Spring Cloud Stream使用中的常见问题,比如: 如何处理消息重复消费 如何消费自己生产的消息 下面几天就集中来详细聊聊,当消息消费失败之后该如何处理的几种方式.不过不论 ...
- 写一个ORM框架的第一步(Apache Commons DbUtils)
新一次的内部提升开始了,如果您想写一个框架从Apache Commons DbUtils开始学习是一种不错的选择,我们先学习应用这个小“框架”再把源代码理解,然后写一个属于自己的ORM框架不是梦. 一 ...
- Python正则进阶
目录 1.Python正则表达式模块 1.1 正则表达式处理字符串主要有四大功能 1.2 Python中re模块使用正则表达式的两种方法 1.3 正则表达式对象的常用方法 1.4 匹配对象的属性与方法 ...
- jqgrid中的column的日期格式
---恢复内容开始--- {name:'StartDate',index:'StartDate', formatter:"date", formatoptions: {newfor ...
- [Linux] Nginx响应压缩gzip
压缩和解压缩 .本节介绍如何配置响应的压缩或解压缩以及发送压缩文件. gzip on; .NGINX仅使用MIME类型text / html压缩响应 gzip_types text/plain app ...
- Netty实战九之单元测试
ChannelHandler是Netty应用程序的关键元素,所以彻底地测试他们应该是你的开发过程的一个标准部分.最佳实践要求你的测试不仅要能够证明你的实现是正确的,而且还要能够很容易地隔离那些因修改代 ...