爬虫_古诗文网(队列,多线程,锁,正则,xpath)
import requests
from queue import Queue
import threading
from lxml import etree
import re
import csv class Producer(threading.Thread):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'}
def __init__(self, page_queue, poem_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.poem_queue = poem_queue def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_html(url) def parse_html(self, url):
# poems = []
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'}
response = requests.get(url, headers=headers)
response.raise_for_status()
html = response.text
html_element = etree.HTML(html)
titles = html_element.xpath('//div[@class="cont"]//b/text()')
contents = html_element.xpath('//div[@class="contson"]')
hrefs = html_element.xpath('//div[@class="cont"]/p[1]/a/@href')
for index, content in enumerate(contents):
title = titles[index]
content = etree.tostring(content, encoding='utf-8').decode('utf-8')
content = re.sub(r'<.*?>|\n|', '', content)
content = re.sub(r'\u3000\u3000', '', content)
content = content.strip()
href = hrefs[index]
self.poem_queue.put((title, content, href)) class Consumer(threading.Thread): def __init__(self, poem_queue, writer, gLock, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.writer = writer
self.poem_queue = poem_queue
self.lock = gLock def run(self):
while True:
try:
title, content, href = self.poem_queue.get(timeout=20)
self.lock.acquire()
self.writer.writerow((title, content, href))
self.lock.release()
except:
break def main():
page_queue = Queue(100)
poem_queue = Queue(500)
gLock = threading.Lock()
fp = open('poem.csv', 'a',newline='', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('title', 'content', 'href')) for x in range(1, 100):
url = 'https://www.gushiwen.org/shiwen/default.aspx?page=%d&type=0&id=0' % x
page_queue.put(url) for x in range(5):
t = Producer(page_queue, poem_queue)
t.start() for x in range(5):
t = Consumer(poem_queue, writer, gLock)
t.start() if __name__ == '__main__':
main()
运行结果
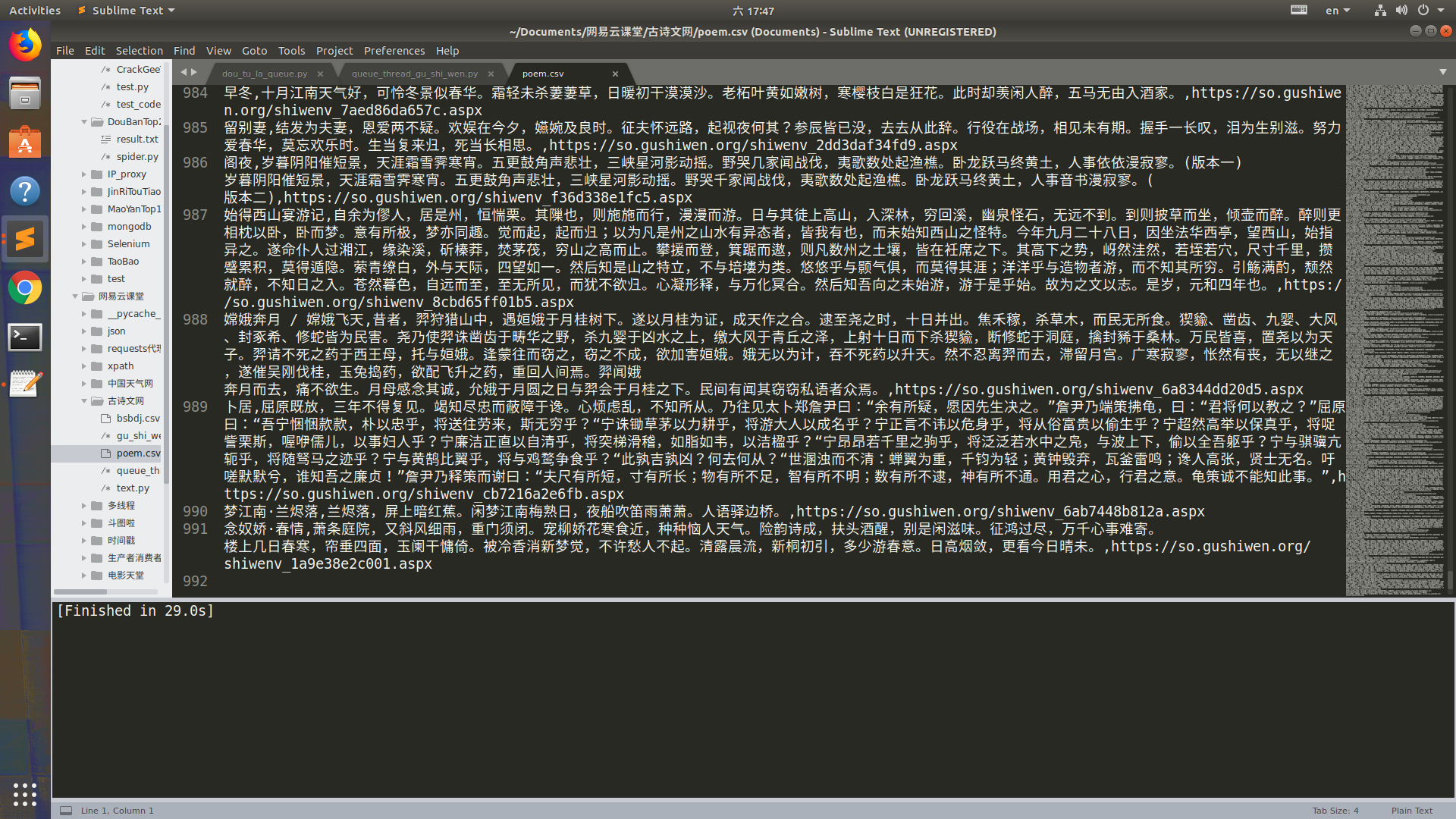
爬虫_古诗文网(队列,多线程,锁,正则,xpath)的更多相关文章
- 爬虫_中国天气网_文字天气预报(xpath)
import requests from lxml import etree headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/5 ...
- requests_cookie登陆古诗文网。session的使用
通过登录失败,快速找到登录接口 获取hidden隐藏域中的id的value值 # 通过登陆 然后进入到主页面 # 通过找登陆接口我们发现 登陆的时候需要的参数很多 # _VIEWSTATE: /m1O ...
- 爬虫_豆瓣全部正在热映电影 (xpath)
单纯地练习一下xpath import requests from lxml import etree def get_url(url): html = requests.get(url) retur ...
- Python爬虫入门教程 11-100 行行网电子书多线程爬取
行行网电子书多线程爬取-写在前面 最近想找几本电子书看看,就翻啊翻,然后呢,找到了一个 叫做 周读的网站 ,网站特别好,简单清爽,书籍很多,而且打开都是百度网盘可以直接下载,更新速度也还可以,于是乎, ...
- 初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据
通过requests.re(正则表达式) 爬取"古诗文"网页数据. 详细代码如下: #!/user/bin env python # author:Simple-Sir # tim ...
- Java多线程--锁的优化
Java多线程--锁的优化 提高锁的性能 减少锁的持有时间 一个线程如果持有锁太长时间,其他线程就必须等待相应的时间,如果有多个线程都在等待该资源,整体性能必然下降.所有有必要减少单个线程持有锁的时间 ...
- synchronized与static synchronized 的差别、synchronized在JVM底层的实现原理及Java多线程锁理解
本Blog分为例如以下部分: 第一部分:synchronized与static synchronized 的差别 第二部分:JVM底层又是怎样实现synchronized的 第三部分:Java多线程锁 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- SANSA 上上洛可可 贾伟作品 高山流水 香炉 香插香台香具 高端商务礼品 黑色【正品 价格 图片 折扣 评论】_尚品网ShangPin.com
SANSA 上上洛可可 贾伟作品 高山流水 香炉 香插香台香具 高端商务礼品 黑色[正品 价格 图片 折扣 评论]_尚品网ShangPin.com
随机推荐
- H5 20-属性选择器上
20-属性选择器上 --> 我是段落1 我是段落2 我是段落3 我是段落4 我是段落5 <!DOCTYPE html> <html lang="en"> ...
- PAT L3-010 是否完全二叉搜索树
https://pintia.cn/problem-sets/994805046380707840/problems/994805049870368768 将一系列给定数字顺序插入一个初始为空的二叉搜 ...
- composer 自动加载一 通过file加载
github地址 https://github.com/brady-wang/composer composer init 可以生成一个composer.json文件 { "name&quo ...
- 利用js给datalist或select动态添加option选项
<!DOCTYPE html> <html> <head> <title>鼠标点击时加载</title> <script type=& ...
- vue图表
https://www.cnblogs.com/powertoolsteam/p/top-9-javascript-charting-libraries.html
- javax.validation.ValidationException: Unable to create a Configuration, because no Bean Validation provider could be found. Add a provider like Hibernate Validator (RI) to your classpath.
项目依赖 <dependency> <groupId>javax</groupId> <artifactId>javaee-api</artifa ...
- Appscanner实验还原code2
import _pickle as pickle from sklearn import svm, ensemble import random from sklearn.metrics import ...
- java学习之—合并两个数组并排序
/** * 合并两个数组并排序 * Create by Administrator * 2018/6/26 0026 * 下午 4:29 **/ public class MergeApp { pub ...
- 不停机修改线上 MySQL 主键字段 以及其带来的问题和总结思考
起因: 线上 user 数据库没有自增字段,数据量已经达到百万级.无论是给离线仓库还是数据分析同步数据,没有主键自增 id 都是杀手级的困难.所以在使用 create_time 痛苦了几次之后准备彻底 ...
- 使用Guava cache构建本地缓存
前言 最近在一个项目中需要用到本地缓存,在网上调研后,发现谷歌的Guva提供的cache模块非常的不错.简单易上手的api:灵活强大的功能,再加上谷歌这块金字招牌,让我毫不犹豫的选择了它.仅以此博客记 ...