聚簇索引(Clustered Index)和非聚簇索引 (Non- Clustered Index)
本文转自https://my.oschina.net/u/1866821/blog/297673
索引的重要性
数据库性能优化中索引绝对是一个重量级的因素,可以说,索引使用不当,其它优化措施将毫无意义。
聚簇索引(Clustered Index)和非聚簇索引 (Non- Clustered Index)
最通俗的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关。举例来说,你翻到新华字典的汉字“爬”那一页就是P开头的部分,这就是物理存储顺序(聚簇索引);而不用你到目录,找到汉字“爬”所在的页码,然后根据页码找到这个字(非聚簇索引)。
下表给出了何时使用聚簇索引与非聚簇索引:
| 动作 | 使用聚簇索引 | 使用非聚簇索引 |
| 列经常被分组排序 | 应 | 应 |
| 返回某范围内的数据 | 应 | 不应 |
| 一个或极少不同值 | 不应 | 不应 |
| 小数目的不同值 | 应 | 不应 |
| 大数目的不同值 | 不应 | 应 |
| 频繁更新的列 | 不应 | 应 |
| 外键列 | 应 | 应 |
| 主键列 | 应 | 应 |
| 频繁修改索引列 | 不应 | 应 |
聚簇索引的唯一性
正式聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引,因为物理存储只能有一个顺序。正因为一个表最多只能有一个聚簇索引,所以它显得更为珍贵,一个表设置什么为聚簇索引对性能很关键。
初学者最大的误区:把主键自动设为聚簇索引
因为这是SQLServer的默认主键行为,你设置了主键,它就把主键设为聚簇索引,而一个表最多只能有一个聚簇索引,所以很多人就把其他索引设置为非聚簇索引。这个是最大的误区。甚至有的主键又是无意义的自动增量字段,那样的话Clustered index对效率的帮助,完全被浪费了。
刚才说到了,聚簇索引性能最好而且具有唯一性,所以非常珍贵,必须慎重设置。一般要根据这个表最常用的SQL查询方式来进行选择,某个字段作为聚簇索引,或组合聚簇索引,这个要看实际情况。
事实上,建表的时候,先需要设置主键,然后添加我们想要的聚簇索引,最后设置主键,SQLServer就会自动把主键设置为非聚簇索引(会自动根据情况选择)。如果你已经设置了主键为聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
记住我们的最终目的就是在相同结果集情况下,尽可能减少逻辑IO。
我们先从一个实际使用的简单例子开始。
一个简单的表:
CREATE TABLE [dbo].[Table1](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Da
ta1] [int] NOT NULL DEFAULT ((0)),
[Da
ta2] [int] NOT NULL DEFAULT ((0)),
[Da
ta3] [int] NOT NULL DEFAULT ((0)),
[Name1] [nvarchar](50) NOT NULL DEFAULT (''),
[Name2] [nvarchar](50) NOT NULL DEFAULT (''),
[Name3] [nvarchar](50) DEFAULT (''),
[DTAt] [datetime] NOT NULL DEFAULT (getdate())
复制代码

来点测试数据(10w条):
declare @i int
set @i = 1
while @i < 100000
begin
insert into Table1 ([Da
ta1] ,[Da
ta2] ,[Da
ta3] ,[Name1],[Name2] ,[Name3])
values(@i , 2* @i ,3*@i, CAST(@i AS NVARCHAR(50)), CAST(2*@i AS NVARCHAR(50)), CAST(3*@i AS NVARCHAR(50)))
set @i = @i + 1
end
update table1 set dtat= DateAdd (s, da
ta1, dtat)
复制代码
打开查询分析器的IO统计和时间统计:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
复制代码
显示实际的“执行计划”:
我们最常用的SQL查询是这样的:
SELECT * FROM Table1 WHERE Da
ta1 = 2 ORDER BY DTAt DESC;
复制代码
先在Table1设主键ID,系统自动为该主键建立了聚簇索引。
然后执行该语句,结果是:
Table 'Table1'. Scan count 1, logical reads 911, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 7 ms.
复制代码

然后我们在Data1和DTat字段分别建立非聚簇索引:
CREATE NONCLUSTERED INDEX [N_Da
ta1] ON [dbo].[Table1]
(
[Da
ta1] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ON
LINE = OFF) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [N_DTat] ON [dbo].[Table1]
(
[DTAt] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ON
LINE = OFF) ON [PRIMARY]
复制代码
再次执行该语句,结果是:
Table 'Table1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 39 ms.
复制代码

可以看到设立了索引反而没有任何性能的提升而且消耗的时间更多了,继续调整。
然后我们删除所有非聚簇索引,并删除主键,这样所有索引都删除了。建立组合索引Data1和DTAt,最后加上主键:
CREATE CLUSTERED INDEX [C_Da
ta1_DTat] ON [dbo].[Table1]
(
[Da
ta1] ASC,
[DTAt] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ON
LINE = OFF) ON [PRIMARY]
复制代码
再次执行语句:
Table 'Table1'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
复制代码

可以看到只有聚簇索引seek了,消除了index scan和nested loop,而且执行时间也只有1ms,达到了最初优化的目的。
组合索引小结
小结以上的调优实践,要注意聚簇索引的选择。首先我们要找到我们最多用到的SQL查询,像本例就是那句类似的组合条件查询的情况,这种情况最好使用组合聚簇索引,而且最多用到的字段要放在组合聚簇索引的前面,否则的话就索引就不会有好的效果,看下例:
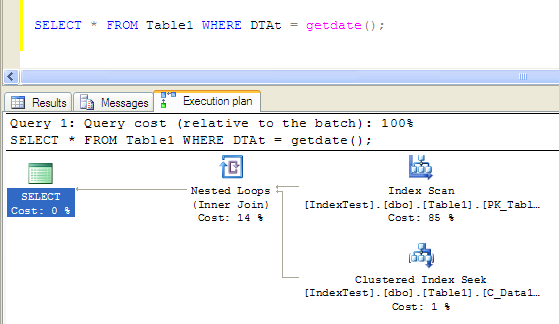
查询条件落在组合索引的第二个字段上,引起了index scan,效果很不好,执行时间是:
Table 'Table1'. Scan count 1, logical reads 238, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 22 ms.
复制代码
而如果仅查询条件是第一个字段也没有问题,因为组合索引最左前缀原则,实践如下:
Table 'Table1'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
复制代码
从中可以看出,最多用到的字段要放在组合聚簇索引的前面。
Index seek 为什么比 Index scan好?
索引扫描也就是遍历B树,而seek是B树查找直接定位。
Index scan多半是出现在索引列在表达式中。数据库引擎无法直接确定你要的列的值,所以只能扫描整个整个索引进行计算。index seek就要好很多.数据库引擎只需要扫描几个分支节点就可以定位到你要的记录。回过来,如果聚集索引的叶子节点就是记录,那么Clustered Index Scan就基本等同于full table scan。
一些优化原则
1、缺省情况下建立的索引是非聚簇索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说:
a.有大量重复值、且经常有范围查询( > ,< ,> =,< =)和order by、group by发生的列,可考
虑建立群集索引;
b.经常同时存取多列,且每列都含有重复值可考虑建立组合索引;
c.组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。索引虽有助于提高性能但不是索引越多越好,恰好相反过多的索引会导致系统低效。用户在表中每加进一个索引,维护索引集合就要做相应的更新工作。
2、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短语,任何一种索引都有助于SELECT的性能提高。
3、多表操作在被实际执行前,查询优化器会根据连接条件,列出几组可能的连接方案并从中找出系统开销最小的最佳方案。连接条件要充份考虑带有索引的表、行数多的表;内外表的选择可由公式:外层表中的匹配行数*内层表中每一次查找的次数确定,乘积最小为最佳方案。
4、任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
5、IN、OR子句常会使用工作表,使索引失效。如果不产生大量重复值,可以考虑把子句拆开。拆开的子句中应该包含索引。
Sql的优化原则2:
1、只要能满足你的需求,应尽可能使用更小的数据类型:例如使用MEDIUMINT代替INT
2、尽量把所有的列设置为NOT NULL,如果你要保存NULL,手动去设置它,而不是把它设为默认值。
3、尽量少用VARCHAR、TEXT、BLOB类型
4、如果你的数据只有你所知的少量的几个。最好使用ENUM类型
使用SQLServer Profiler找出数据库中性能最差的SQL
首先打开SQLServer Profiler:

然后点击工具栏“New Trace”,使用默认的模板,点击RUN。
也许会有报错:"only TrueType fonts are supported. There id not a TrueType font"。不用怕,点击Tools菜单->Options,重新选择一个字体例如Vendana 即可。(这个是微软的一个bug)
运行起来以后,SQLServer Profiler会监控数据库的活动,所以最好在你需要监控的数据库上多做些操作。等觉得差不多了,点击停止。然后保存trace结果到文件或者table。
这里保存到Table:在菜单“File”-“Save as ”-“Trace table”,例如输入一个master数据库的新的table名:profileTrace,保存即可。
找到最耗时的SQL:
use master
select * from profiletrace order by duration desc;
复制代码
找到了性能瓶颈,接下来就可以有针对性的一个个进行调优了。
对使用SQLServer Profiler的更多信息可以参考:
http://www.codeproject.com/KB/database/DiagnoseProblemsSQLServer.aspx
使用SQLServer Database Engine Tuning Advisor数据库引擎优化顾问
使用上述的SQLServer Profiler得到了trace还有一个好处就是可以用到这个优化顾问。用它可以偷点懒,得到SQLServer给您的优化顾问,例如这个表需要加个索引什么的…
首先打开数据库引擎优化顾问:
然后打开刚才profiler的结果(我们存到了master数据库的profileTrace表):

点击“start analysis”,运行完成后查看优化建议(图中最后是建议建立的索引,性能提升72%)

这个方法可以偷点懒,得到SQLServer给您的优化顾问。
聚簇索引(Clustered Index)和非聚簇索引 (Non- Clustered Index)的更多相关文章
- SQL Server中的聚集索引(clustered index) 和 非聚集索引 (non-clustered index)
本文转载自 http://blog.csdn.net/ak913/article/details/8026743 面试时经常问到的问题: 1. 什么是聚合索引(clustered index) / ...
- mysql聚簇索引和非聚簇索引
聚簇索引 InnoDB使用的是聚簇索引 将数据与主键索引放在了一起,索引的叶子节点保存了行数据,找到了主键索引,即找到了行数据. 辅助索引记录了主键的位置,所以查询where name= xxx 时, ...
- 聚簇索引(clustered index )和非聚簇索引(secondary index)的区别
这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式.对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树. ...
- Clustered Index & Non Clustered Index(聚簇索引和非聚簇索引)
每个表只能有一个聚簇索引,而能有200多个非聚簇索引. 在物理分配上, 每个表的数据都是分配在页上,一个页大概有8k左右,假设一条数据占1000字节的话,那么8000条数据占8000*1k/8k = ...
- 聚合索引(clustered index) / 非聚合索引(nonclustered index)
以下我面试经常问的2道题..尤其针对觉得自己SQL SERVER 还不错的同志.. 呵呵 很难有人答得好.. 各位在我收集每个人擅长的东西时,大部分都把SQL SERVER 标为Expert,看看是否 ...
- sqlserver聚合索引(clustered index) / 非聚合索引(nonclustered index)的理解
1. 什么是聚合索引(clustered index) / 什么是非聚合索引(nonclustered index)? 可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索 ...
- 一分钟明白MySQL聚簇索引和非聚簇索引
MySQL的InnoDB索引数据结构是B+树,主键索引叶子节点的值存储的就是MySQL的数据行,普通索引的叶子节点的值存储的是主键值,这是了解聚簇索引和非聚簇索引的前提 什么是聚簇索引? 很简单记住一 ...
- mysql索引之聚簇索引与非聚簇索引
1 数据结构及算法基础 1.1 索引的本质 官方定义:索引(Index)是帮助MySQL高效获取数据的数据结构 本质:索引是数据结构 查询是数据库的最主要功能之一.我们都希望查询速度能尽可能快,因此数 ...
- MYSQL性能调优: 对聚簇索引和非聚簇索引的认识
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法.特点是存储数据的顺序和索引顺序一致.一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引. 在<数据库原理&g ...
随机推荐
- Specify 的含义 ------ 转载
specify block用来描述从源点(source:input/inout port)到终点(destination:output/inout port)的路径延时(path delay),由sp ...
- Docker安装ElasticSearch及kibana
什么是Kibana? Kibana 是一个设计出来用于和 Elasticsearch 一起使用的开源的分析与可视化平台,可以用 kibana 搜索.查看.交互存放在Elasticsearch 索引里的 ...
- 如何快速扫描C段(网站快照、后台识别/登录、目录扫描)
1.C段扫描 C类地址范围从 192.0.0.1 到 223.255.255.254 ,192转换成二进制就是1100000:223转换成二进制就是1101111:所以说网络地址的最高位肯定是110开 ...
- ADB抓取内存命令
1. 在IDE中查看Log信息当程序运行垃圾回收的时候,会打印一条Log信息,其格式如下:D/dalvikvm: <GC_Reason> <Amount_freed>, < ...
- ubuntu 外接显示器
xrandr --help xrandr # 列出显示器 sudo xrandr --output eDP-1 --off # 关闭eDP-1显示器 sudo xrandr --output ...
- hadoop streaming 中跑python程序,自定义模块的导入
今天在做代码重构,以前将所有python文件放到一个文件夹下,上传到hadoop上跑,没有问题:不过随着任务的复杂性增加,感觉这样甚是不合理,于是做了个重构,建了好几个包存放不同功能的python文件 ...
- django-rest-framework配置json web token
安装jwt库,简单快速的生成我们所需要的token 1.安装djangorestframe pip install djangorestframe 2.在settings.py的INSTALLED_A ...
- vue--组件基础
组件是可复用的 vue 实例,它与new Vue 接收相同的参数,例如:data.methods.computed.watch 以及生命周期钩子.除了 el 等. 1.组件注册必须有一个组件名. 组件 ...
- python day07笔记总结
2019.4.4 S21 day07笔记总结 一.深浅拷贝 1.copy.copy() 浅拷贝 deep.copy() 深拷贝 2.一般情况 1.str/int/bool 是不可变类型 ...
- linux重装rabbitmq的问题
一.卸载 [root@zabbix_server lib]# rpm -qa|grep rabbitmq rabbitmq-server--.noarch [root@zabbix_server li ...