KMP算法的next[]数组通俗解释
原文:https://blog.csdn.net/yearn520/article/details/6729426
我们在一个母字符串中查找一个子字符串有很多方法。KMP是一种最常见的改进算法,它可以在匹配过程中失配的情况下,有效地多往后面跳几个字符,加快匹配速度。
当然我们可以看到这个算法针对的是子串有对称属性,如果有对称属性,那么就需要向前查找是否有可以再次匹配的内容。
在KMP算法中有个数组,叫做前缀数组,也有的叫next数组,每一个子串有一个固定的next数组,它记录着字符串匹配过程中失配情况下可以向前多跳几个字符,当然它描述的也是子串的对称程度,程度越高,值越大,当然之前可能出现再匹配的机会就更大。
这个next数组的求法是KMP算法的关键,但不是很好理解
1、用一个例子来解释,下面是一个子串的next数组的值,可以看到这个子串的对称程度很高,所以next值都比较大。
|
位置i |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
前缀next[i] |
0 |
0 |
0 |
0 |
1 |
2 |
3 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
4 |
0 |
|
子串 |
a |
g |
c |
t |
a |
g |
c |
a |
g |
c |
t |
a |
g |
c |
t |
g |
申明一下:下面说的对称不是中心对称,而是中心字符块对称,比如不是abccba,而是abcabc这种对称。
(1)逐个查找对称串。
这个很简单,我们只要循环遍历这个子串,分别看前1个字符,前2个字符,3个... i个 最后到15个。
第1个a无对称,所以对称程度0
前两个ag无对称,所以也是0
依次类推前面0-4都一样是0
前5个agcta,可以看到这个串有一个a相等,所以对称程度为1前6个agctag,看得到ag和ag对成,对称程度为2
这里要注意了,想是这样想,编程怎么实现呢?
只要按照下面的规则:
a、当前面字符的前一个字符的对称程度为0的时候,只要将当前字符与子串第一个字符进行比较。这个很好理解啊,前面都是0,说明都不对称了,如果多加了一个字符,要对称的话最多是当前的和第一个对称。比如agcta这个里面t的是0,那么后面的a的对称程度只需要看它是不是等于第一个字符a了。
b、按照这个推理,我们就可以总结一个规律,不仅前面是0呀,如果前面一个字符的next值是1,那么我们就把当前字符与子串第二个字符进行比较,因为前面的是1,说明前面的字符已经和第一个相等了,如果这个又与第二个相等了,说明对称程度就是2了。有两个字符对称了。比如上面agctag,倒数第二个a的next是1,说明它和第一个a对称了,接着我们就把最后一个g与第二个g比较,又相等,自然对称成都就累加了,就是2了。
c、按照上面的推理,如果一直相等,就一直累加,可以一直推啊,推到这里应该一点难度都没有吧,如果你觉得有难度说明我写的太失败了。
当然不可能会那么顺利让我们一直对称下去,如果遇到下一个不相等了,那么说明不能继承前面的对称性了,这种情况只能说明没有那么多对称了,但是不能说明一点对称性都没有,所以遇到这种情况就要重新来考虑,这个也是难点所在。
(2)回头来找对称性
这里已经不能继承前面了,但是还是找对称程度嘛,最愚蠢的做法大不了写一个子函数,查找这个字符串的最大对称程度,怎么写方法很多吧,比如查找出所有的当前字符串,然后向前走,看是否一直相等,最后走到子串开头,当然这个是最蠢的,我们一般看到的KMP都是优化过的,因为这个串是有规律的。
在这里依然用上面表中一段来举个例子:
位置i=0到14如下,我加的括号只是用来说明问题:
(a g c t a g c )( a g c t a g c) t
我们可以看到这段,最后这个t之前的对称程度分别是:1,2,3,4,5,6,7,倒数第二个c往前看有7个字符对称,所以对称为7。但是到最后这个t就没有继承前面的对称程度next值,所以这个t的对称性就要重新来求。
这里首要要申明几个事实
1、t 如果要存在对称性,那么对称程度肯定比前面这个c 的对称程度小,所以要找个更小的对称,这个不用解释了吧,如果大那么t就继承前面的对称性了。
2、要找更小的对称,必然在对称内部还存在子对称,而且这个t必须紧接着在子对称之后。
如下图说明。

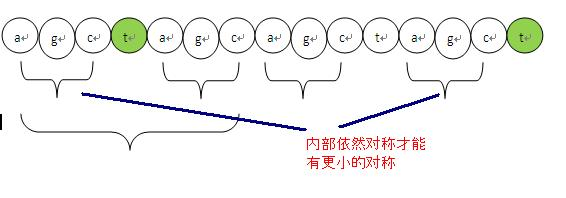
从上面的理论我们就能得到下面的前缀next数组的求解算法。
void SetPrefix(const char *Pattern, int prefix[])
{
int len=CharLen(Pattern);//模式字符串长度。
prefix[0]=0;
for(int i=1; i<len; i++)
{
int k=prefix[i-1];
//不断递归判断是否存在子对称,k=0说明不再有子对称,Pattern[i] != Pattern[k]说明虽然对称,但是对称后面的值和当前的字符值不相等,所以继续递推
while( Pattern[i] != Pattern[k] && k!=0 )
k=prefix[k-1]; //继续递归
if( Pattern[i] == Pattern[k])//找到了这个子对称,或者是直接继承了前面的对称性,这两种都在前面的基础上++
prefix[i]=k+1;
else
prefix[i]=0; //如果遍历了所有子对称都无效,说明这个新字符不具有对称性,清0
}
}
通过这个说明,估计能够理解KMP的next求法原理了,剩下的就很简单了。我自己也有点晕了,实在不喜欢那些数学公式,所以用形象逻辑思维方法总结了一下。
////////
KMP还有一种写法:这个写法是经过N个人优化的:
int j = -1, i = 0;
next[0] = -1;
while(i < len)
{
if(j == -1 || ss[i] == ss[j])
{
i++;
j++;
next[i] = j;
}
else
{
j = next[j];
}
}
KMP算法的next[]数组通俗解释的更多相关文章
- poj 2406:Power Strings(KMP算法,next[]数组的理解)
Power Strings Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 30069 Accepted: 12553 D ...
- hdu 1358:Period(KMP算法,next[]数组的使用)
Period Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- hdu3336解读KMP算法的next数组
查看原题 题意大致是:给你一个字符串算这里面全部前缀出现的次数和.比方字符串abab,a出现2次.ab出现2次,aba出现1次.abab出现1次.总计6次. 而且结果太大.要求对1007进行模运算. ...
- KMP算法的Next数组详解
转载请注明来源,并包含相关链接. 网上有很多讲解KMP算法的博客,我就不浪费时间再写一份了.直接推荐一个当初我入门时看的博客吧:http://www.cnblogs.com/yjiyjige/p/32 ...
- KMP算法的Next数组详解 转
这个写的很好,还有讲kmp,值得一看. http://www.cnblogs.com/tangzhengyue/p/4315393.html 转载请注明来源,并包含相关链接. 网上有很多讲解KMP算法 ...
- 浅谈KMP算法及其next[]数组
KMP算法是众多优秀的模式串匹配算法中较早诞生的一个,也是相对最为人所知的一个. 算法实现简单,运行效率高,时间复杂度为O(n+m)(n和m分别为目标串和模式串的长度) 当字符串长度和字符集大小的比值 ...
- KMP算法的Next数组详解(转)
转载请注明来源,并包含相关链接. 网上有很多讲解KMP算法的博客,我就不浪费时间再写一份了.直接推荐一个当初我入门时看的博客吧: http://www.cnblogs.com/yjiyjige/p/3 ...
- KMP算法(next数组方法)
KMP算法之前需要说一点串的问题: 串: 字符串:ASCII码为基本数据形成的一堆线性结构. 串是一个线性结构:它的存储形式: typedef struct STRING { CHARACTER *h ...
- KMP算法中next数组的理解与算法的实现(java语言)
KMP 算法我们有写好的函数帮我们计算 Next 数组的值和 Nextval 数组的值,但是如果是考试,那就只能自己来手算这两个数组了,这里分享一下我的计算方法吧. 计算前缀 Next[i] 的值: ...
随机推荐
- The Unique MST POJ - 1679 次小生成树prim
求次小生成树思路: 先把最小生成树求出来 用一个Max[i][j] 数组把 i点到j 点的道路中 权值最大的那个记录下来 used数组记录该条边有没有被最小生成树使用过 把没有使用过的一条边加 ...
- Iroha and a Grid AtCoder - 1974(思维水题)
就是一个组合数水题 偷个图 去掉阴影部分 把整个图看成上下两个矩形 对于上面的矩形求出起点到每个绿点的方案 对于下面的矩形 求出每个绿点到终点的方案 上下两个绿点的方案相乘后相加 就是了 想想为什么 ...
- 我的SSH框架实例(附源码)
整理一下从前写的SSH框架的例子,供新人学习,使用到了注解的方式. 源码和数据库文件在百度网盘:http://pan.baidu.com/s/1hsH3Hh6 提取码:br27 对新同学的建议:最好的 ...
- 用keras实现基本的文本分类任务
数据集介绍 包含来自互联网电影数据库的50000条影评文本,对半拆分为训练集和测试集.训练集和测试集之间达成了平衡,意味着它们包含相同数量的正面和负面影评,每个样本都是一个整数数组,表示影评中的字词. ...
- 15 Zabbix Item类型之Zabbix trapper类型
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 15 Zabbix Item类型之Zabbix trapper类型 zabbix获取数据时有时会出 ...
- 【BZOJ5294】[BJOI2018]二进制(线段树)
[BZOJ5294][BJOI2018]二进制(线段树) 题面 BZOJ 洛谷 题解 二进制串在模\(3\)意义下,每一位代表的余数显然是\(121212\)这样子交替出现的. 其实换种方法看,就是\ ...
- 【转】RO段、RW段和ZI段 --Image$$??$$Limit 含义(zz)
@2019-02-14 [小记] RO段.RW段和ZI段 --Image$$??$$Limit 含义(zz)
- [ZJOI2005]九数码游戏(BFS+hash)
Solution 这题的话直接上BFS就可以了,因为要输出方案,所以我们要开一个pre数组记录前驱,最后输出就可以了. 对于状态的记录,一般都用哈希来存,但因为这道题比较特殊,它是一个排列,所以我们可 ...
- Mybatis中org.apache.ibatis.binding.BindingException错误问题总结
1. Mybatis出现多个参数,但是多个参数中没有使用@Param注解进行修饰 2. Xml文件中字段名和PO绑定时候,字段写错了 3.XML中<foreach/>标签中的colleac ...
- Python中字符串、列表、元组、字典、集合常用方法总结