065 updateStateByKey的函数API
一:使用场景
1.应用场景
数据的累加
一段时间内的数据的累加
2.说明
每个批次都输出自己批次的数据,
这个时候,可以使用这个API,使得他们之间产生联系。
3.说明2
在累加器的时候,起到的效果和这里的说明想法有些相同,都可以输出上一个批次的信息
二:程序
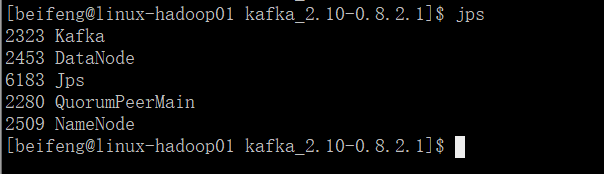
1.需要启动一些服务
需要使用hadoop
2.程序
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object UpdateStateByKeyKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"smallest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") /**
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)]
*/ val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
.updateStateByKey(
(values: Seq[Int], state: Option[Long]) => {
// 从value中获取累加值
val sum = values.sum // 获取以前的累加值
val oldStateSum = state.getOrElse(0L) // 更新状态值并返回
Some(oldStateSum + sum)
}
) resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
三:updateStateByKey的优化
1.说明
主要的情况是,程序停止,刚刚累加的数据不再存在。
重启后效果如下:
只剩下,已经被checkPoint的数据,后面的数据不再存在。
2.优化的程序
多加两个参数。
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object UpdateStateByKeyKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"largest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") // 初始化updateStateByKey用到的状态值
// 从保存状态值的地方(HBase)读取状态值, 这里采用模拟的方式
val initialRDD: RDD[(String, Long)] = sc.parallelize(
Array(
("hadoop", 100L),
("spark", 25L)
)
) /**
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)]
*/ val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
.updateStateByKey(
(values: Seq[Int], state: Option[Long]) => {
// 从value中获取累加值
val sum = values.sum // 获取以前的累加值
val oldStateSum = state.getOrElse(0L) // 更新状态值并返回
Some(oldStateSum + sum)
},
new HashPartitioner(ssc.sparkContext.defaultParallelism), // 分区器
initialRDD // 初始化状态值
) resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
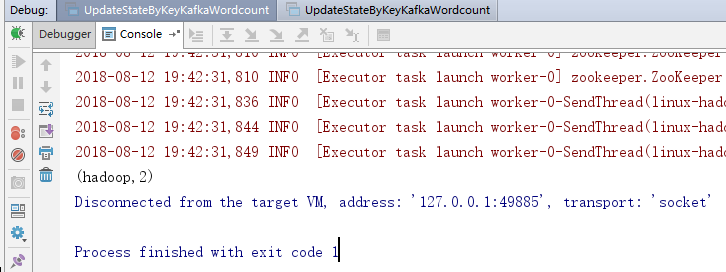
3.运行效果

4.注意点
需要有checkPoint的路径。
累加值存在硬盘中,长时间不访问会被删除。
065 updateStateByKey的函数API的更多相关文章
- HTML5 Audio标签方法和函数API介绍
问说网 > 文章教程 > 网页制作 > HTML5 Audio标签方法和函数API介绍 Audio APIHTML5HTML5 Audio预加载 HTML5 Audio标签方法和函数 ...
- MySQL Crash Course #05# Chapter 9. 10. 11. 12 正则.函数. API
索引 正则表达式:MySQL only supports a small subset of what is supported in most regular expression implemen ...
- Unix/Linux系统时间函数API
首先说明关于几个时间的概念: 世界时:起初,国际上的标准时间是格林尼治标准时间,以太阳横穿本初子午线的时刻为标准时间正午12点.它根据天文环境来定义,就像古代人们根据日晷来计时一样,如下图: 原子时: ...
- Atitit.跨平台预定义函数 魔术方法 魔术函数 钩子函数 api兼容性草案 v2 q216 java c# php js.docx
Atitit.跨平台预定义函数 魔术方法 魔术函数 钩子函数 api兼容性草案 v2 q216 java c# php js.docx 1.1. 预定义函数 魔术方法 魔术函数是什么1 1.2. & ...
- kotlin函数api
原 Kotlin学习(4)Lambda 2017年09月26日 21:00:03 gwt0425 阅读数:551 记住Lambda的本质,还是一个对象.和JS,Python等不同的是,Kotlin ...
- jQuery函数API,各版本新特性汇总
jQuery API 速查表 选择器 基本 #id element .class * selector1,selector2,selectorN 层级 ancestor descendant pare ...
- Azure 静态 web 应用集成 Azure 函数 API
前几次我们演示了如果通过Azure静态web应用功能发布vue跟blazor的项目.但是一个真正的web应用,总是免不了需要后台api服务为前端提供数据或者处理数据的能力.同样前面我们也介绍了Azur ...
- cocosCreator 新版本的动作函数API的应用
利用触摸位置判断,点击的是屏幕的左侧还是右侧,控制主角左右移动: 见代码: InputControl:function () { var self=this; //cc.systemEvent sel ...
- 【原创】自己动手写的一个查看函数API地址的小工具
C开源代码如下: #include <stdio.h> #include <windows.h> #include <winbase.h> typedef void ...
随机推荐
- ionic 打包 报错Execution failed for task ':processDebugResources'. > com.android.ide.common.process.ProcessException: Failed to execute aapt
在platform --> android目录下找到build.gradle文件,打开并在def promptForReleaseKeyPassword() {...}函数前加入以下内容: 完整 ...
- SpringBoot实现异步
1.创建AsyncTest类 package com.cppdy.service; import org.springframework.scheduling.annotation.Async; im ...
- LeetCode(106):从中序与后序遍历序列构造二叉树
Medium! 题目描述: 根据一棵树的中序遍历与后序遍历构造二叉树. 注意:你可以假设树中没有重复的元素. 例如,给出 中序遍历 inorder = [9,3,15,20,7] 后序遍历 posto ...
- 《剑指offer》用两个栈实现队列
本题来自<剑指offer> 用两个栈实现队列 题目: 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 思路: 队列定义:先进先出 栈定义:先进后出 要 ...
- Metasploit
1.启动Metasploit 声明:本次渗透测试的主机是我自己在自己的攻击主机上搭建的另一个操作系统,为了真实性设置了常见的IP地址,如有重合但绝对不是任何实体公司或者单位的IP地址. 所以不承担任何 ...
- 【Vue】组件watch props属性值
转载: https://www.cnblogs.com/mqxs/p/8972368.html #HTML <div id="example"> <p> & ...
- ajax之阴影效果实现(对象函数方法)
shadow.js文件内容jQuery.fn.shadow = function () { //获取到每个已封装的元素 //this表示jQuery对象 this.each(function () { ...
- appium获取APP控件信息
uiautomatorviewer.bat 该文件位于SDK安装目录tools下,如笔者在“C:\Program Files (x86)\Android\android-sdk\tools”下,双击u ...
- 如何用TortoiseSVN对文件进行操作
我们如何用TortoiseSVN修改文件,添加文件,删除文件,以及如何解决冲突等. 添加文件 在检出的工作副本中添加一个Readme.txt文本文件,这时候这个文本文件会显示为没有版本控制的状态,如图 ...
- Cannot uninstall 'html5lib'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
如标题,安装Tensorflow-gpu时遇到的完整问题 Cannot uninstall 'html5lib'. It is a distutils installed project and th ...