Hadoop| MapReduce01 概述
概述
分布式运算程序;
优点:易于编程;良好扩展性;高容错性;适合PB级以上海量数据的离线处理;
缺点:不擅长实时计算;不擅长流式计算;不擅长DAG有向图计算;
核心思想:
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
一个完整的MapReduce在分布式运行时有3类实例进程:
MrAppMaster:负责整个程序的过程调度及状态协调;
MapTask:负责Map阶段的整个数据处理流程;
ReduceTask:负责ReduceTask阶段的整个数据处理流程;
数据序列化类型
常用的数据类型对应的Hadoop数据序列化类型
Java类型 Hadoop Writable类型
Boolean BooleanWritable
Byte ByteWritable
Int IntWritable
Float FloatWritable
Long LongWritable
Double DoubleWritable
String Text
Map MapWritable
Array ArrayWritable
Null NullWritable
MapReduce编程规范:
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
Mapper阶段:
自定义的Mapper继承父类;输入数据以K,V对的形式;业务逻辑写在map( )方法;
输出数据以K,V形式;map()方法(MapTask进程)对每一个k,v调用一次
Reduce阶段:
自定义的Reducer继承父类;输入数据类型对应Mapper的输出类型以K,V对的形式;业务逻辑写在reduce( )方法;
输出数据以K,V形式;(ReduceTask进程)对每一组相同k的k,v调用一次reduce方法
Driver 阶段:
Driver 相当于yarn集群的客户端,提交(封装了MapReduce程序相关运行参数的job对象)整个程序到yarn集群
Word Count案例 -- 创建Maven工程
在pom.xml文件中添加如下依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
编写Mapper类
package com.xxx.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException; public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//定义泛型: 输入是以行号: 一行文本这种形式; 输出是以aaa: 1这种形式
private Text word = new Text(); //对象定义为类的私有,是为了防止垃圾,对象太多会占用很大的JVM堆空间;
private IntWritable one = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.切分行数据
String[] split = value.toString().split(" ");
for (String str : split) {
this.word.set(str);
//context贯彻整个页面的,
context.write(this.word, one);
} }
}
WcReduce类
package com.xxx.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator; public class WcReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
//泛型 输入aaa 1; 输出是对所有的进行统计汇总aaa 3;
private IntWritable sumAll = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
sum += iterator.next().get();
}
this.sumAll.set(sum);
context.write(key, this.sumAll);
}
}
WcDriver
package com.atguigu.mapreduce.wordcount; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WcDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取一个任务实例; 获取配置信息和封装任务
Job job = Job.getInstance(new Configuration());
//2.设置jar类加载路径
job.setJarByClass(WcDriver.class);
//3.设置Mapper和Reduce类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReduce.class);
//4.设置Mapper和Reduce最终输出的k v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //5.设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); //6.提交任务
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
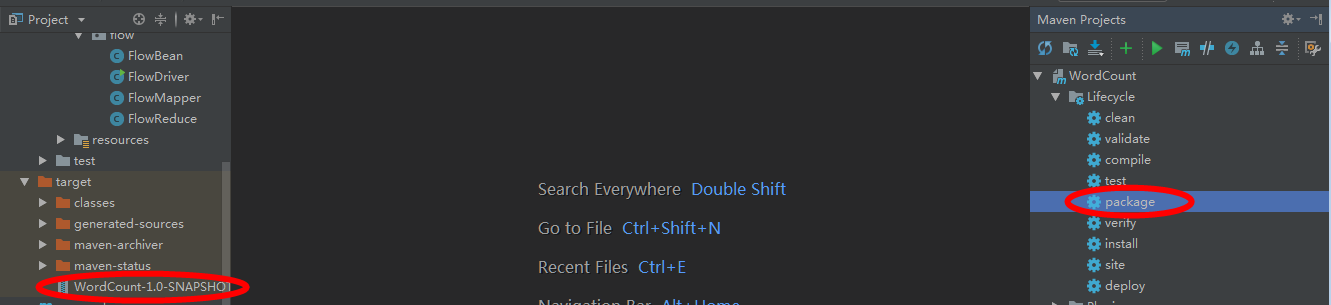
打包jar,copy到Hadoop集群上传,然后在集群中运行
[kris@hadoop101 hadoop-2.7.2]$ rz -E //上传jar包WordCount-1.0-SNAPSHOT.jar [kris@hadoop101 hadoop-2.7.2]$ hadoop jar WordCount-1.0-SNAPSHOT.jar com.atguigu.mapreduce.wordcount.WcDriver /2.txt /output //运行
Hadoop序列化

注意:
反序列化时,需要反射调用空参构造函数,所以必须有空参构造
注意反序列化的顺序和序列化的顺序完全一致
要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口(WritableComparable< >),因为MapReduce框中的Shuffle过程要求对key必须能排序。
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return xxx ;
}
自定义bean对象实现序列化接口(Writable)
package flow; import org.apache.hadoop.io.Writable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; //1.实现Writable接口
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow; public FlowBean() {
super();
} public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = this.upFlow + this.downFlow;
} public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
} public long getDownFlow() {
return downFlow;
} public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
} public long getSumFlow() {
return sumFlow;
} public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
} @Override
public String toString() {
return "上行流量=" + upFlow +
",下行流量=" + downFlow +
",总流量=" + sumFlow;
}
//写序列化方法;
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
//反序列化方法必须和序列化方法顺序一致;
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong(); }
}
//写序列化方法;
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
//反序列化方法必须和序列化方法顺序一致;
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
FlowMapper类
//1.泛型是输入:行号+一行的内容; 输出:key字符手机号+类对象
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
private Text phone = new Text();
FlowBean flowBean = new FlowBean(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
phone.set(split[1]); //获取手机号key
flowBean.set(Long.parseLong(split[split.length-3]), Long.parseLong(split[split.length-2]));//获取upFlow和downFlow作为v
context.write(phone, flowBean);
}
} FlowReducer类 public class FlowReduce extends Reducer<Text, FlowBean, Text, FlowBean> {
private FlowBean flowBean = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
super.reduce(key, values, context);
int sumUpFlow = 0;
int sumDownFlow = 0;
for (FlowBean value : values) {
sumUpFlow += value.getUpFlow();
sumDownFlow += value.getDownFlow();
}
flowBean.set(sumUpFlow, sumDownFlow);
context.write(key, flowBean);
}
} FlowDriver类 public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取job实例;获取配置信息
Job job = Job.getInstance(new Configuration());
//2.设置类路径;指定被程序的jar包所在的路径
job.setJarByClass(FlowDriver.class);
//3.设置Mapper和Reducer 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReduce.class);
//4.设置输出类型 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//5.设置输入输出路径
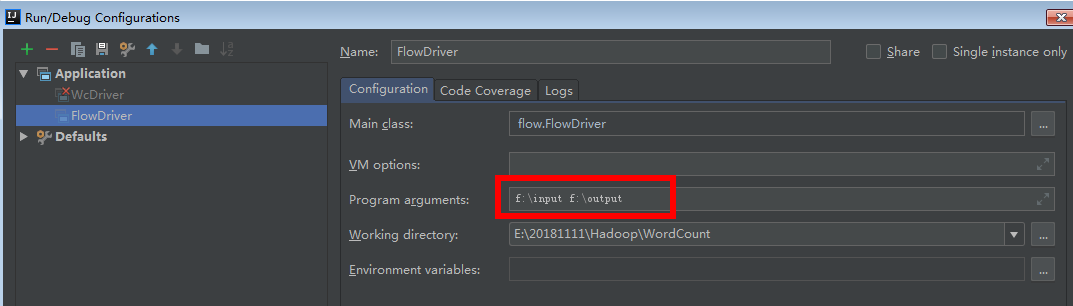
FileInputFormat.setInputPaths(job, new Path("F:\\input"));
FileOutputFormat.setOutputPath(job, new Path("F:\\output"));
//6.提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
Hadoop| MapReduce01 概述的更多相关文章
- 大数据及Hadoop的概述
一.大数据存储和计算的各种框架即工具 1.存储:HDFS:分布式文件系统 Hbase:分布式数据库系统 Kafka:分布式消息缓存系统 2.计算:Mapreduce:离线计算框架 stor ...
- Hadoop - YARN 概述
一 概述 Apache Hadoop YARN (Yet Another Resource Negotiator,还有一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源 ...
- 【大数据project师之路】Hadoop——MapReduce概述
一.概述. MapReduce是一种可用于数据处理的编程模型.Hadoop能够执行由各种语言编写的MapReuce程序.MapReduce分为Map部分和Reduce部分. 二.MapReduce的机 ...
- 一、Hadoop入门概述
一.Hadoop是什么 Hadoop是一个由Apche基金会所开发的分布式系统基础架构. 主要解决海量数据的存储和海量数据的分析计算问题. 广义上来说,Hadoop通常是指一个更广泛的概念—Hadoo ...
- MapReduce01 概述
MapReduce 概述 目录 MapReduce 概述 1.定义 2.优缺点 优点 缺点 3.MapReduce核心思想 4.MapReduce进程 5.官方 WordCount 源码 6.常用数据 ...
- hadoop核心组件概述及hadoop集群的搭建
什么是hadoop? Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台.允许使用简单的编程模型在大量计算机集群上对大型数据集进行分 ...
- Hadoop整体概述
目录 前言 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml 一.HDFS HDFS的设计理念 HDFS的缺点 1.NameNode ...
- Hadoop & Spark
Hadoop & Spark 概述 Apache Hadoop 是一种通过服务集群并使用MapReduce编程数据模型完成大数据的分布式处理框架,核心模块包括:MapReduce,Hadoop ...
- hadoop伪分布模式的配置和一些常用命令
大数据的发展历史 3V:volume.velocity.variety(结构化和非结构化数据).value(价值密度低) 大数据带来的技术挑战 存储容量不断增加 获取有价值的信息的难度:搜索.广告.推 ...
随机推荐
- 编译和运行dubbo-admin管理平台
下载 Github上下载最新的dubbo源码包并解压 修改ZooKeeper相关的配置 打开dubbo-admin/src/main/webapp/WEB-INF下的dubbo.p ...
- CSS 三角形与圆形
1. 概述 1.1 说明 通过边框(border)的宽度与边框圆角(border-radius)来设置所需的三角形与圆形. 1.2 边框 宽高都为0时,边框设置的不同结果也不同,如下: 1.四个边框都 ...
- Python-爬虫-猫眼T100
目标站点需求分析 涉及的库 from multiprocessing import Poolfrom requests.exceptions import RequestExceptionimport ...
- vue-fetch
1.安装命令“ cnpm install --save isomorphic-fetch es6-promise 2.由于ie不支持Promise,所以需要安装promise-polyfill; cn ...
- IPv4和IPv6简单对比介绍(转载)
原链接:https://baijiahao.baidu.com/s?id=1570208896149974&wfr=spider&for=pc 在配置计算机网络,特别是内网的时候,有时 ...
- day10 函数2
为什么需要函数? 先使用目前的知识点实现一个需求: """ 三个功能 1.登录 2.购物车 3.收藏夹 收藏夹和 购物车 需要先登录才能使用! ...
- 【深度学习】吴恩达网易公开课练习(class1 week3)
知识点梳理 python工具使用: sklearn: 数据挖掘,数据分析工具,内置logistic回归 matplotlib: 做图工具,可绘制等高线等 绘制散点图: plt.scatter(X[0, ...
- 部署描述符 web.xml
google的部署描述符详解: https://cloud.google.com/appengine/docs/flexible/java/configuring-the-web-xml-deploy ...
- PDF怎么去除页眉页脚,PDF页眉页脚编辑方法
我们在使用文件的时候需要编辑页眉页脚的时候,这个时候我们应该怎么做呢,相信别的文件大家都知道怎么编辑了,PDF文件大家都知道吗,最开始接触这个文件的时候小编觉得很难,之后找到技巧之后也并没有很难,今天 ...
- name
问题 A: name 时间限制: 1 Sec 内存限制: 256 MB 题目描述 lpq同学最近突然对外国人的名字产生了兴趣,特别是外国女生的名字,于是他开始试图去认识一些国外的女生. 随着认识的女 ...