大数据-kafka
1Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
作用:1发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2以容错的方式记录消息流,kafka以文件的方式来存储消息流
3可以再消息发布的时候进行处理
用于;在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
构建实时的流数据处理程序来变换或处理数据流,数据处理功能
1.3.1 消息传输流程
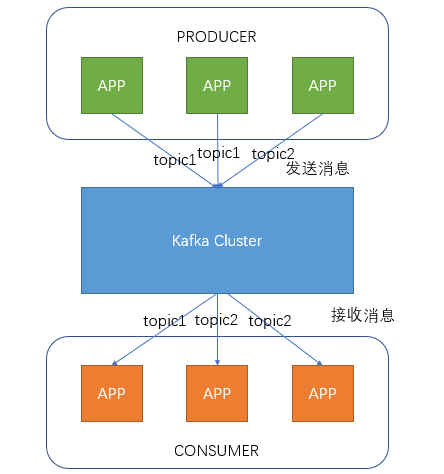
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
1.3.2 kafka服务器消息存储策略
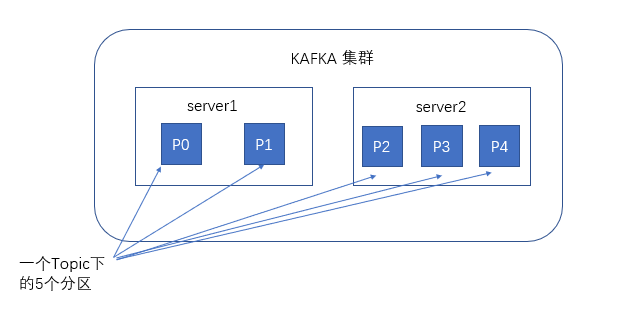
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。

在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
1.3.3 与生产者的交互

生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
1.3.4 与消费者的交互
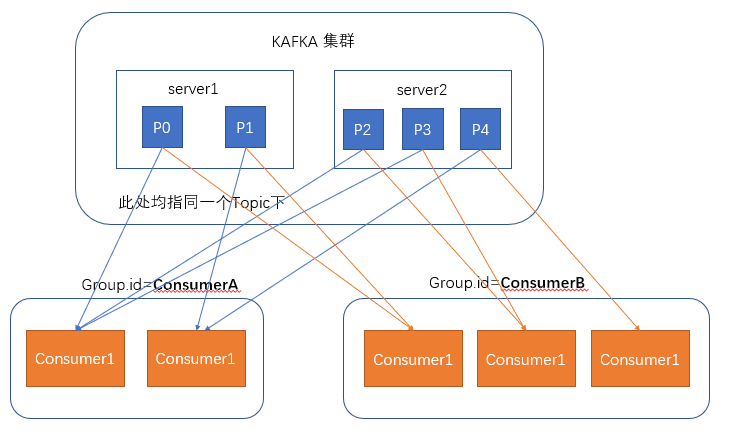
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
2. Kafka安装与使用
2.1. 下载
你可以在kafka官网 http://kafka.apache.org/downloads下载到最新的kafka安装包,选择下载二进制版本的tgz文件,根据网络状态可能需要fq,这里我们选择的版本是0.11.0.1,目前的最新版
2.2. 安装
Kafka是使用scala编写的运行与jvm虚拟机上的程序,虽然也可以在windows上使用,但是kafka基本上是运行在linux服务器上,因此我们这里也使用linux来开始今天的实战。
首先确保你的机器上安装了jdk,kafka需要java运行环境,以前的kafka还需要zookeeper,新版的kafka已经内置了一个zookeeper环境,所以我们可以直接使用
说是安装,如果只需要进行最简单的尝试的话我们只需要解压到任意目录即可,这里我们将kafka压缩包解压到/home目录
2.3. 配置
在kafka解压目录下下有一个config的文件夹,里面放置的是我们的配置文件
consumer.properites 消费者配置,这个配置文件用于配置于2.5节中开启的消费者,此处我们使用默认的即可
producer.properties 生产者配置,这个配置文件用于配置于2.5节中开启的生产者,此处我们使用默认的即可
server.properties kafka服务器的配置,此配置文件用来配置kafka服务器,目前仅介绍几个最基础的配置
- broker.id 申明当前kafka服务器在集群中的唯一ID,需配置为integer,并且集群中的每一个kafka服务器的id都应是唯一的,我们这里采用默认配置即可
- listeners 申明此kafka服务器需要监听的端口号,如果是在本机上跑虚拟机运行可以不用配置本项,默认会使用localhost的地址,如果是在远程服务器上运行则必须配置,例如:
listeners=PLAINTEXT:// 192.168.180.128:9092。并确保服务器的9092端口能够访问
3.zookeeper.connect 申明kafka所连接的zookeeper的地址 ,需配置为zookeeper的地址,由于本次使用的是kafka高版本中自带zookeeper,使用默认配置即可
zookeeper.connect=localhost:2181
2.4. 运行
- 启动zookeeper
cd进入kafka解压目录,输入
bin/zookeeper-server-start.sh config/zookeeper.properties
启动zookeeper成功后会看到如下的输出

2.启动kafka
cd进入kafka解压目录,输入
bin/kafka-server-start.sh config/server.properties
启动kafka成功后会看到如下的输出

2.5. 第一个消息
2.5.1 创建一个topic
Kafka通过topic对同一类的数据进行管理,同一类的数据使用同一个topic可以在处理数据时更加的便捷
在kafka解压目录打开终端,输入
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建一个名为test的topic

在创建topic后可以通过输入
bin/kafka-topics.sh --list --zookeeper localhost:2181
来查看已经创建的topic
2.4.2 创建一个消息消费者
在kafka解压目录打开终端,输入
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
可以创建一个用于消费topic为test的消费者

消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据
不过别着急,不要关闭这个终端,打开一个新的终端,接下来我们创建第一个消息生产者
2.4.3 创建一个消息生产者
在kafka解压目录打开一个新的终端,输入
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
在执行完毕后会进入的编辑器页面

在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息

3. 使用java程序
跟上节中一样,我们现在在java程序中尝试使用kafka
3.1 创建Topic
public static void main(String[] args) {
//创建topic
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.180.128:9092");
AdminClient adminClient = AdminClient.create(props);
ArrayList<NewTopic> topics = new ArrayList<NewTopic>();
NewTopic newTopic = new NewTopic("topic-test", 1, (short) 1);
topics.add(newTopic);
CreateTopicsResult result = adminClient.createTopics(topics);
try {
result.all().get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
使用AdminClient API可以来控制对kafka服务器进行配置,我们这里使用NewTopic(String name, int numPartitions, short replicationFactor)的构造方法来创建了一个名为“topic-test”,分区数为1,复制因子为1的Topic.
3.2 Producer生产者发送消息
public static void main(String[] args){
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.180.128:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("topic-test", Integer.toString(i), Integer.toString(i)));
producer.close();
}
使用producer发送完消息可以通过2.5中提到的服务器端消费者监听到消息。也可以使用接下来介绍的java消费者程序来消费消息
3.3 Consumer消费者消费消息
public static void main(String[] args){
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.12.65:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
final KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props);
consumer.subscribe(Arrays.asList("topic-test"),new ConsumerRebalanceListener() {
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
//将偏移设置到最开始
consumer.seekToBeginning(collection);
}
});
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
这里我们使用Consume API 来创建了一个普通的java消费者程序来监听名为“topic-test”的Topic,每当有生产者向kafka服务器发送消息,我们的消费者就能收到发送的消息。
4. 使用spring-kafka
Spring-kafka是正处于孵化阶段的一个spring子项目,能够使用spring的特性来让我们更方便的使用kafka
4.1 基本配置信息
与其他spring的项目一样,总是离不开配置,这里我们使用java配置来配置我们的kafka消费者和生产者。
- 引入pom文件
<!--kafka start-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.11.0.1</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>1.3.0.RELEASE</version>
</dependency>
- 创建配置类
我们在主目录下新建名为KafkaConfig的类
@Configuration
@EnableKafka
public class KafkaConfig {
}
- 配置Topic
在kafkaConfig类中添加配置
//topic config Topic的配置开始
@Bean
public KafkaAdmin admin() {
Map<String, Object> configs = new HashMap<String, Object>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.180.128:9092");
return new KafkaAdmin(configs);
}
@Bean
public NewTopic topic1() {
return new NewTopic("foo", 10, (short) 2);
}
//topic的配置结束
- 配置生产者Factort及Template
//producer config start
@Bean
public ProducerFactory<Integer, String> producerFactory() {
return new DefaultKafkaProducerFactory<Integer,String>(producerConfigs());
}
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<String,Object>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.180.128:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
@Bean
public KafkaTemplate<Integer, String> kafkaTemplate() {
return new KafkaTemplate<Integer, String>(producerFactory());
}
//producer config end
5.配置ConsumerFactory
//consumer config start
@Bean
public ConcurrentKafkaListenerContainerFactory<Integer,String> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<Integer, String>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Integer,String> consumerFactory(){
return new DefaultKafkaConsumerFactory<Integer, String>(consumerConfigs());
}
@Bean
public Map<String,Object> consumerConfigs(){
HashMap<String, Object> props = new HashMap<String, Object>();
props.put("bootstrap.servers", "192.168.180.128:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
//consumer config end
4.2 创建消息生产者
//使用spring-kafka的template发送一条消息 发送多条消息只需要循环多次即可
public static void main(String[] args) throws ExecutionException, InterruptedException {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(KafkaConfig.class);
KafkaTemplate<Integer, String> kafkaTemplate = (KafkaTemplate<Integer, String>) ctx.getBean("kafkaTemplate");
String data="this is a test message";
ListenableFuture<SendResult<Integer, String>> send = kafkaTemplate.send("topic-test", 1, data);
send.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() {
public void onFailure(Throwable throwable) {
}
public void onSuccess(SendResult<Integer, String> integerStringSendResult) {
}
});
}
4.3 创建消息消费者
我们首先创建一个一个用于消息监听的类,当名为”topic-test”的topic接收到消息之后,我们的这个listen方法就会调用。
public class SimpleConsumerListener {
private final static Logger logger = LoggerFactory.getLogger(SimpleConsumerListener.class);
private final CountDownLatch latch1 = new CountDownLatch(1);
@KafkaListener(id = "foo", topics = "topic-test")
public void listen(byte[] records) {
//do something here
this.latch1.countDown();
}
}
我们同时也需要将这个类作为一个Bean配置到KafkaConfig中
@Bean
public SimpleConsumerListener simpleConsumerListener(){
return new SimpleConsumerListener();
}
默认spring-kafka会为每一个监听方法创建一个线程来向kafka服务器拉取消息
安装
二、kafka 安装
2.1 jdk安装
#以oracle jdk为例,下载地址http://java.sun.com/javase/downloads/index.jsp
|
1
|
yum -y install jdk-8u141-linux-x64.rpm |
2.2 安装zookeeper
|
1
2
3
|
wget http://apache.forsale.plus/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gztar zxf zookeeper-3.4.9.tar.gzmv zookeeper-3.4.9 /data/zk |
修改配置文件内容如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@localhost ~]# cat /data/zk/conf/zoo.cfgtickTime=2000initLimit=10syncLimit=5dataDir=/data/zk/data/zookeeperdataLogDir=/data/zk/data/logsclientPort=2181maxClientCnxns=60autopurge.snapRetainCount=3autopurge.purgeInterval=1server.1=zk01:2888:3888server.2=zk02:2888:3888server.3=zk03:2888:3888 |
参数说明:
server.id=host:port:port:表示了不同的zookeeper服务器的自身标识,作为集群的一部分,每一台服务器应该知道其他服务器的信息。用户可以从“server.id=host:port:port” 中读取到相关信息。在服务器的data(dataDir参数所指定的目录)下创建一个文件名为myid的文件,这个
文件的内容只有一行,指定的是自身的id值。比如,服务器“1”应该在myid文件中写入“1”。这个id必须在集群环境中服务器标识中是唯一的,且大小在1~255之间。这一样配置中,zoo1代表第一台服务器的IP地址。第一个端口号(port)是从follower连接到leader机器的
端口,第二个端口是用来进行leader选举时所用的端口。所以,在集群配置过程中有三个非常重要的端口:clientPort:2181、port:2888、port:3888。
关于zoo.cfg配置文件说明,参考连接https://zookeeper.apache.org/doc/r3.4.10/zookeeperAdmin.html#sc_configuration;
如果想更换日志输出位置,除了在zoo.cfg加入"dataLogDir=/data/zk/data/logs"外,还需要修改zkServer.sh文件,大概修改方式地方在125行左右,内容如下:
|
1
2
3
4
|
125 ZOO_LOG_DIR="$($GREP "^[[:space:]]*dataLogDir" "$ZOOCFG" | sed -e 's/.*=//')"126 if [ ! -w "$ZOO_LOG_DIR" ] ; then127 mkdir -p "$ZOO_LOG_DIR"128 fi |
在启动服务之前,还需要分别在zookeeper创建myid,方式如下:
|
1
|
echo 1 > /data/zk/data/zookeeper/myid |
启动服务
|
1
|
/data/zk/bin/zkServer.sh start |
验证服务
|
1
2
3
4
|
### 查看相关端口号[root@localhost ~]# ss -lnpt|grep javaLISTEN 0 50 :::34442 :::* users:(("java",pid=2984,fd=18))LISTEN 0 50 ::ffff:192.168.15.133:3888 :::* users:(("java",pid=2984,fd=26))LISTEN 0 50 :::2181 :::* users:(("java",pid=2984,fd=25))###查看zookeeper服务状态 |
[root@localhost ~]# /data/zk/bin/zkServer.sh status
ZooKeeper JMX enabled by default
|
1
|
Using config: /data/zk/bin/../conf/zoo.cfgMode: follower |
zookeeper相关命令说明,参考https://zookeeper.apache.org/doc/r3.4.10/zookeeperStarted.html (文末有说明);
2.3 安装kafka
|
1
2
|
tar zxf kafka_2.11-0.11.0.0.tgzmv kafka_2.11-0.11.0.0 /data/kafka |
修改配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[root@localhost ~]# grep -Ev "^#|^$" /data/kafka/config/server.propertiesbroker.id=0delete.topic.enable=truelisteners=PLAINTEXT://192.168.15.131:9092num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600log.dirs=/data/kafka/datanum.partitions=1num.recovery.threads.per.data.dir=1offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1log.flush.interval.messages=10000log.flush.interval.ms=1000log.retention.hours=168log.retention.bytes=1073741824log.segment.bytes=1073741824log.retention.check.interval.ms=300000zookeeper.connect=192.168.15.131:2181,192.168.15.132:2181,192.168.15.133:2181zookeeper.connection.timeout.ms=6000group.initial.rebalance.delay.ms=0 |
提示:其他主机将该机器的kafka目录拷贝即可,然后需要修改broker.id、listeners地址。有关kafka配置文件参数,参考:http://orchome.com/12;
启动服务
|
1
|
/data/kafka/bin/kafka-server-start.sh /data/kafka/config/server.properties |
验证服务
|
1
2
3
4
5
|
### 随便在其中一台主机执行/data/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.15.131:2181,192.168.15.132:2181,192.168.15.133:2181 --replication-factor 1 --partitions 1 --topic test###在其他主机查看/data/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.15.131:2181,192.168.15.132:2181,192.168.15.133:2181 |
大数据-kafka的更多相关文章
- [Hadoop大数据]--kafka入门
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行“随机读写”的原因是什么? 3.kafka集群consumer和producer状态信息是如何保存的? ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- 入门大数据---Kafka生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- 入门大数据---Kafka消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- 入门大数据---Kafka深入理解分区副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- 入门大数据---Kafka的搭建与应用
前言 上一章介绍了Kafka是什么,这章就讲讲怎么搭建以及如何使用. 快速开始 Step 1:Download the code Download the 2.4.1 release and un-t ...
- 入门大数据---Kafka简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
- 大数据 --> Kafka集群搭建
Kafka集群搭建 下面是以三台机器搭建为例,(扩展到4台以上一样,修改下配置文件即可) 1.下载kafka http://apache.fayea.com/kafka/0.9.0.1/ ,拷贝到三台 ...
- 大数据kafka视频教程 学习记录【B站尚硅谷 】
视频地址: https://www.bilibili.com/video/av35354301/?p=1 2019/03/06 21:59 消息队列的内部实现: Kafka基础: ...
随机推荐
- 通过zabbix自带api进行主机的批量添加操作
通过zabbix自带api进行批量添加主机 我们需要监控一台服务器的时候,当客户端装好zabbix-agent端并正确配置以后,需要在zabbix-server的web gui界面进行添加zabbix ...
- PHP随机红包算法
2017年1月14日 14:19:14 星期六 一, 整体设计 算法有很多种, 可以自行选择, 主要的"架构" 是这样的, 用redis decr()命令去限流, 用mysql去记 ...
- 51nod--1459 迷宫游戏 (dijkstra)
1459 迷宫游戏 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 你来到一个迷宫前.该迷宫由若干个房间组成,每个房间都有一个得分,第一次进入这个房间,你就可 ...
- appium+java(四)微信公众号自动化测试实践
前言 随着手机阅读的普遍应用,微信公众号阅读,更为普遍,微信和qq一样,都是基于腾讯自研X5内核,不是google原生webview(其实就是进行了二次定制).实质上也是混合应用的一种,现在很多app ...
- bootstrap 3列表单布局
<form class="form-horizontal" role="form"> <fieldset> <legend> ...
- 8 张图帮你一步步看清 async/await 和 promise 的执行顺序(转)
https://mp.weixin.qq.com/s?__biz=MzAxODE2MjM1MA==&mid=2651555491&idx=1&sn=73779f84c289d9 ...
- table中border-collapse的问题
在table中,如果设置了border-collapse: collapse;,边框会合并,这时你修改top或bottom的颜色,会有问题 解决办法是:border-collapse: separat ...
- 来,了解一下Java内存模型(JMM)
网上有很多关于Java内存模型的文章,在<深入理解Java虚拟机>和<Java并发编程的艺术>等书中也都有关于这个知识点的介绍.但是,很多人读完之后还是搞不清楚,甚至有的人说自 ...
- Confluence 6 自定义默认空间内容
中文标题[自定义默认空间内容] Confluence 管理员 可以编辑用于创建主页和新站点的模板.默认的内容将会在新空间创建后的主页上显示出来.这个与站点空间,个人空间和空间蓝图的模板是不同的. 模板 ...
- jquery 获取和设置 select下拉框的值
获取Select : 获取select 选中的 text : $("#ddlRegType").find("option:selected").text(); ...