图解elasticsearch的_source、_all、store和index
Elasticsearch中有几个关键属性容易混淆,很多人搞不清楚_source字段里存储的是什么?store属性的true或false和_source字段有什么关系?store属性设置为true和_all有什么关系?index属性又起到什么作用?什么时候设置store属性为true?什么时候应该开启_all字段?本文通过图解的方式,深入理解Elasticsearch中的_source、_all、store和index属性。
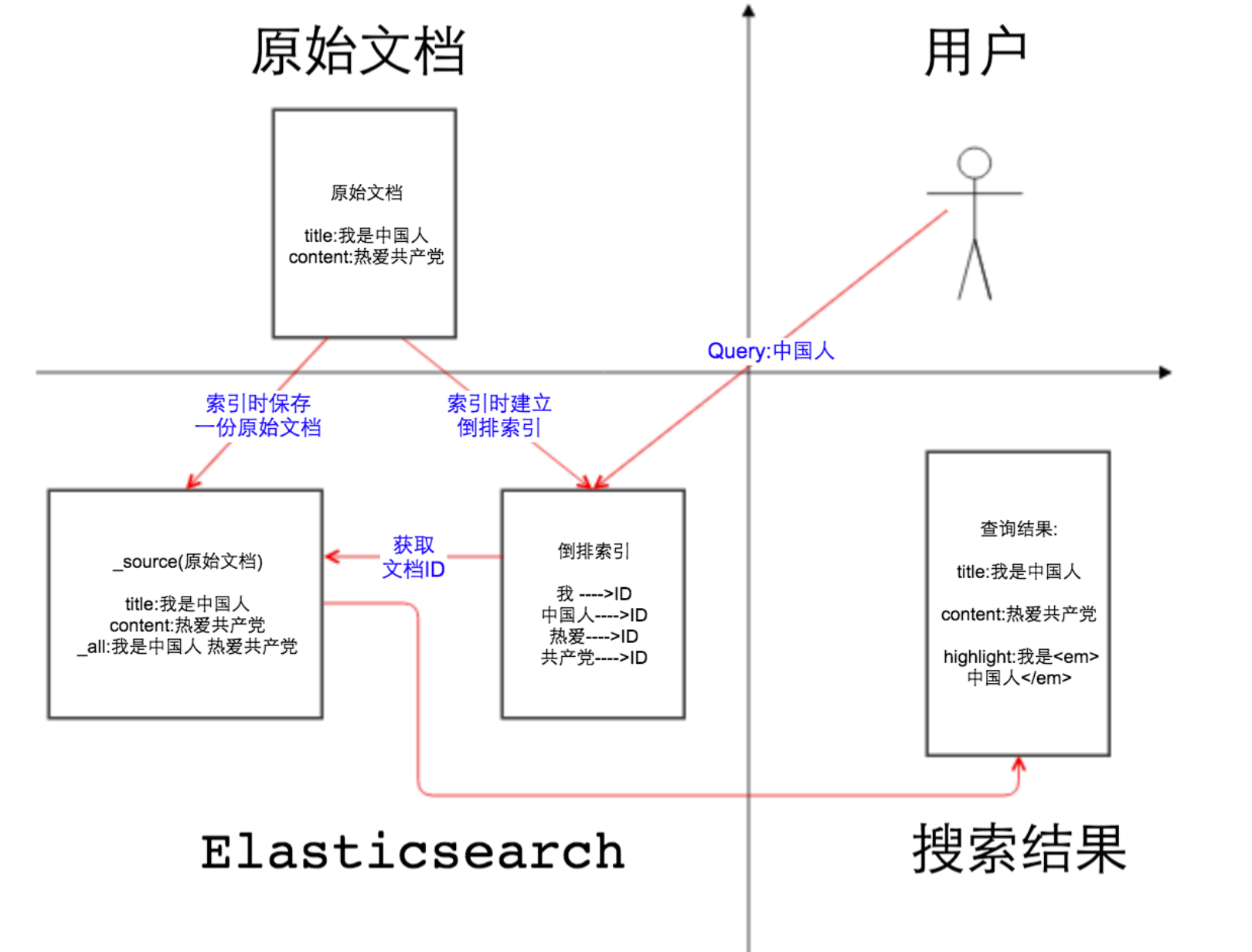
图1 Elasticsearch中的_source、_all、store和index属性解析
如图1所示, 第二象限是一份原始文档,有title和content2个字段,字段取值分别为”我是中国人”和” 热爱xx党”,这一点没什么可解释的。我们把原始文档写入Elasticsearch,默认情况下,Elasticsearch里面有2份内容,一份是原始文档,也就是_source字段里的内容,我们在Elasticsearch中搜索文档,查看的文档内容就是_source中的内容,如图2,相信大家一定非常熟悉这个界面。
图2 _source字段举例
另一份是倒排索引,倒排索引中的数据结构是倒排记录表,记录了词项和文档之间的对应关系,比如关键词”中国人”包含在文档ID为1的文档中,倒排记录表中存储的就是这种对应关系,当然也包括词频等更多信息。Elasticsearch底层用的是Lucene的API,Elasticsearch之所以能完成全文搜索的功能就是因为存储的有倒排索引。如果把倒排索引拿掉,Elasticsearch是不是和mongoDB很像?
那么文档索引到Elasticsearch的时候,默认情况下是对所有字段创建倒排索引的(动态mapping解析出来为数字类型、布尔类型的字段除外),某个字段是否生成倒排索引是由字段的index属性控制的,在Elasticsearch 5之前,index属性的取值有三个:
- analyzed:字段被索引,会做分词,可搜索。反过来,如果需要根据某个字段进搜索,index属性就应该设置为analyzed。
- not_analyzed:字段值不分词,会被原样写入索引。反过来,如果某些字段需要完全匹配,比如人名、地名,index属性设置为not_analyzed为佳。
- no:字段不写入索引,当然也就不能搜索。反过来,有些业务要求某些字段不能被搜索,那么index属性设置为no即可。
再说_all字段,顾名思义,_all字段里面包含了一个文档里面的所有信息,是一个超级字段。以图中的文档为例,如果开启_all字段,那么title+content会组成一个超级字段,这个字段包含了其他字段的所有内容,当然也可以设置只存储某几个字段到_all属性里面或者排除某些字段。
回到图一的第一象限,用户输入关键词" 中国人",分词以后,Elasticsearch从倒排记录表中查找哪些文档包含词项"中国人 ",注意变化,分词之前" 中国人"是用户查询(query),分词之后在倒排索引中" 中国人"是词项(term)。Elasticsearch根据文档ID(通常是文档ID的集合)返回文档内容给用户,如图一第四象限所示。
通常情况下,对于用户查询的关键字要做高亮处理,如图3所示: 
图3 搜索引擎中的关键字高亮
关键字高亮实质上是根据倒排记录中的词项偏移位置,找到关键词,加上前端的高亮代码。这里就要说到store属性,store属性用于指定是否将原始字段写入索引,默认取值为no。如果在Lucene中,高亮功能和store属性是否存储息息相关,因为需要根据偏移位置到原始文档中找到关键字才能加上高亮的片段。在Elasticsearch,因为_source中已经存储了一份原始文档,可以根据_source中的原始文档实现高亮,在索引中再存储原始文档就多余了,所以Elasticsearch默认是把store属性设置为no。
注意:如果想要对某个字段实现高亮功能,_source和store至少保留一个。下面会给出测试代码。
至此,文章开头提出的几个问题都给出了答案。下面给出这几个字段常用配置的代码。
一、_source配置
_source字段默认是存储的, 什么情况下不用保留_source字段?如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,最后返回文档id,查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。
如果想要关闭_source字段,在mapping中的设置如下:
{
"yourtype":{
"_source":{
"enabled":false
},
"properties": {
...
}
}
}如果只想存储某几个字段的原始值到Elasticsearch,可以通过incudes参数来设置,在mapping中的设置如下:
{
"yourtype":{
"_source":{
"includes":["field1","field2"]
},
"properties": {
...
}
}
}同样,可以通过excludes参数排除某些字段:
{
"yourtype":{
"_source":{
"excludes":["field1","field2"]
},
"properties": {
...
}
}
}测试,首先创建一个索引
PUT test设置mapping,禁用_source:
PUT test/test/_mapping
{
"test": {
"_source": {
"enabled": false
}
}
}写入一条文档:
POST test/test/1
{
"title":"我是中国人",
"content":"热爱xx党"
}搜索关键词”中国人”:
GET test/_search
{
"query": {
"match": {
"title": "中国人"
}
}
}
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.30685282,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "1",
"_score": 0.30685282
}
]
}
}从返回结果中可以看到,搜到了一条文档,但是禁用_source以后查询结果中不会再返回文档原始内容。(注,测试基于ELasticsearch 2.3.3,配置文件中已默认指定ik分词。)
二、_all配置
_all字段默认是关闭的,如果要开启_all字段,索引增大是不言而喻的。_all字段开启适用于不指定搜索某一个字段,根据关键词,搜索整个文档内容。
开启_all字段的方法和_source类似,mapping中的配置如下:
{
"yourtype": {
"_all": {
"enabled": true
},
"properties": {
...
}
}
}
也可以通过在字段中指定某个字段是否包含在_all中:
{
"yourtype": {
"properties": {
"field1": {
"type": "string",
"include_in_all": false
},
"field2": {
"type": "string",
"include_in_all": true
}
}
}
}如果要把字段原始值保存,要设置store属性为true,这样索引会更大,需要根据需求使用。下面给出测试代码。
创建test索引:
DELETE test
PUT test设置mapping,这里设置所有字段都保存在_all中并且存储原始值:
PUT test/test/_mapping
{
"test": {
"_all": {
"enabled": true,
"store": true
}
}
}插入文档:
POST test/test/1
{
"title":"我是中国人",
"content":"热爱xx党"
}对_all字段进行搜索并高亮:
POST test/_search
{
"fields": ["_all"],
"query": {
"match": {
"_all": "中国人"
}
},
"highlight": {
"fields": {
"_all": {}
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.15342641,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "1",
"_score": 0.15342641,
"_all": "我是中国人 热爱xx党 ",
"highlight": {
"_all": [
"我是<em>中国人</em> 热爱xx党 "
]
}
}
]
}
}Elasticsearch中的query_string和simple_query_string默认就是查询_all字段,示例如下:
GET test/_search
{
"query": {
"query_string": {
"query": "xx党"
}
}
}三、index和score配置
index和store属性实在字段内进行设置的,下面给出一个例子,设置test索引不保存_source,title字段索引但不分析,字段原始值写入索引,content字段为默认属性,代码如下:
DELETE test
PUT test
PUT test/test/_mapping
{
"test": {
"_source": {
"enabled": false
},
"properties": {
"title": {
"type": "string",
"index": "not_analyzed",
"store": "true"
},
"content": {
"type": "string"
}
}
}
}对title字段进行搜索并高亮,代码如下:
GET test/_search
{
"query": {
"match": {
"title": "我是中国人"
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.30685282,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "1",
"_score": 0.30685282,
"highlight": {
"title": [
"<em>我是中国人</em>"
]
}
}
]
}
}从返回结果中可以看到,虽然没有保存title字段到_source, 但是依然可以实现搜索高亮。
四、总结
通过图解和代码测试,对Elasticsearch中的_source、_all、store和index进行了详解,相信很容易明白。错误和疏漏之处,欢迎批评指正。
图解elasticsearch的_source、_all、store和index的更多相关文章
- Elasticsearch学习之图解Elasticsearch中的_source、_all、store和index属性
转自 : https://blog.csdn.net/napoay/article/details/62233031 1. 概述 Elasticsearch中有几个关键属性容易混淆,很多人搞不清楚_s ...
- 浅析ES的_source、_all、store、index
Elasticsearch中有大量关键概念容易混淆,对于初学者来说是噩梦: _source字段里存储了什么? index属性的作用是什么? 何时应该开启_all字段? store属性和_source字 ...
- ES索引瘦身 压缩——_source _all 均disable filed store为no,引入第三方DB存储原始数据,去掉pos倒排和doc_values,强制定期merge segments,将所有fileds合并为一个field big string
原始数据:835MB ES 设置了_source _all disabled 且设置了仅仅存docs倒排Wed Feb 22 11:58:27 CST 2017Before size:1 /home/ ...
- Elasticsearch 5.0 _all field的简单认识
前言:本文的目的是为后续磁盘空间利用优化做铺垫,主要知识点来源于官网 一._all 是什么 在Elasticsearch中,_all field维护这一个很大的字符串数组(text类型).这个字符串是 ...
- 解决:ElasticSearch ClusterBlockException[blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];
简记 使用SkyWalking用ES做存储,发现运行一段时间会提示ElasticSearch ClusterBlockException[blocked by: [FORBIDDEN/12/index ...
- 图解Elasticsearch中的_source、_all、store和index属性
https://blog.csdn.net/napoay/article/details/62233031
- elasticsearch中mapping的_source和store的笔记
0.故事引入 无意中看到了ES的mapping中有store字段,作为一个ES菜鸡,有必要对这个字段进行下笔记. 1._source _source字段我在们进行检索时相当重要, ES默认检索只会返回 ...
- elasticsearch中mapping的_source和store的笔记(转)
原文地址: https://www.cnblogs.com/zklidd/p/6149120.html 0.故事引入 无意中看到了ES的mapping中有store字段,作为一个ES菜鸡,有必要对这个 ...
- Elasticsearch学习随笔(二)-- Index 和 Doc 查询新建API总结
本文着重总结Elasticsearch的常见API了,进行分析. Index API 初始化Index,设置shards和replica PUT http://localhost:9200/firew ...
随机推荐
- C#一例绘制字体不清晰的解决办法
public static Bitmap GetPieWithText(String text, Color color, Color fontColor,Font font) { ; Bitmap ...
- 三十五、minishell(3)
35.1 内容 在当前的 minishell 中,如果执行 date clear 命令等,minishell 会停止: 这是因为引入进程组的时候,mshell 放置在前台进程组,同时之后在子进程中又创 ...
- C#水晶报表教程
http://apps.hi.baidu.com/share/detail/24298108 水晶报表是一个功能强大的报表工具,现在已经被Microsoft Visual Studio 2005(下文 ...
- 使用Hexo在github上搭建个人博客
最近正好在学习前端开发,想着搭建一个属于自己的个人博客,把自己的技能树整理整理,温故而知新. 如果你有前端开发经验,那么搭建这样的博客就很简单了. 一 什么是Hexo Hexo 是一个快速.简 ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Regularization)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Regularization Welcome to the second assignment of this week. Deep ...
- chrome性能分析
Chrome开发者工具之JavaScript内存分析 前端性能优化 —— 前端性能分析 Chrome DevTools - 性能监控
- GDI+学习---2.GDI+编程模式及组成类
在使用GDI+的时候,您不必像在GDI中那样关心设备场景句柄,只需简单地创建一个Graphics对象,然后以您熟悉的面向对象的方式(如myGraphicsObject.DrawLine(paramet ...
- linux一些比较重要的环境变量。配置文件
永久添加环境变量PATH 方法一:编辑/etc/profile.d/NAME.sh 写入这句话export PATH=/PATH/TO/SOMEWHRER:$PATH 永久修改动态库文件搜索路径 方法 ...
- java SPI & spring factories
SPI 全称为 (Service Provider Interface) ,是JDK内置的一种服务提供发现机制.SPI是一种动态替换发现的机制, 比如有个接口,想运行时动态的给它添加实现,你只需要添加 ...
- Django学习手册 - pycharm 安装/建立第一个网站hello world
步骤阐述: 1.下载 pycharm 安装包,安装pycharm 2.打开pycharm软件,新建工程项目 3.新建APP,配置url,启动项目 步骤1: pycharm 官网下载: https:// ...