Paper | 多任务学习的鼻祖
论文:Multitask learning
Caruana, Rich. "Multitask learning." Machine learning 28.1 (1997): 41-75.
Over 3600 citations (2019).
1. MTL的定义
Multi-task learning (MTL) is a subfield of machine learning in which multiple learning tasks are solved at the same time, while exploiting commonalities and differences across tasks.
Notice, MTL is a collection of ideas, techniques, and algorithms, not one algorithm.
E.g., k-nearest neighbor and decision trees.
2. MTL的机制
这部分我们主要设计一些简单的实验,来说明MTL的机制,并且纠正一些错误的观点。
这部分主要参考:Multitask Learning (R.CARUANA, 1997), 3531 citations.
2.1. Representation Bias
这一部分告诉我们:如果任务之间是无关的,那么多任务会起反作用。
假设任务T有两个极小值点A和B,任务T'有两个极小值点A和C。也就是说,这两个任务共享一个极小值点A。
经过精心设计,任务T落入A和B的概率相同,任务T'同理。
In the first, we selected the minima so that nets trained on T alone are equally likely to find A or B, and nets trained on
T' alone are equally likely to find A or C.
然后,作者让两个任务在同一个网络中进行训练。结果发现,这些网络通常会落入共同极小值点A。这说明:在MTL任务中,如果某些任务偏好一种对共享层的表示,那么其他任务也会对其产生偏好。
Nets trained on both T and T 0 usually fall into A for both tasks. This shows that MTL tasks prefer hidden layer representations that other tasks prefer.
当然了,前提是这种表示对所有任务都是局部最优的。
其次,作者改变了任务T的极小值点:T非常容易落入B,而不太容易落入A。T'的极小值点不变,落入A和C的概率相同。
此时再同时训练,作者发现:T'很难影响T的偏好,T仍然总是落入B。同时,T'落入C的概率大大增加了!
这表明:在T的影响下,共享层更偏好于远离极小值点B,这影响到了其他共享这一共享层的任务。
T creates a “tide” in the hidden layer representation towards B that flows away from A. T' has no preference for A or C, but is subject to the tide created by T.
这一部分告诉我们:如果两个任务鲜有关联,那么放在同一个网络训练的后果就是:两个任务都会偏离它们的共同极值点(局部,弱),因此共享层是没有意义的。
个人认为,这样反倒有可能限制二者的学习能力,因为两个任务被迫共享没有意义的隐藏层。
2.2. Uncorrelated Tasks May Help?
Holmstrom等人在1992年发现,在BP过程中添加噪声,有时可以提高模型的泛化能力。
有人就想:如果MTL网络中任务之间是无关的,那么它们和共享层之间的BP过程,彼此互为噪声(没有一致性的BP)。既然添加噪声可以提高泛化能力,那么uncorrelated tasks是否能互相促进呢?
作者设计了一个实验。对已有的MTL任务集和一个MTL网络,在训练时,extra tasks的training signals是随机提供的。
此时,如果MTL受益于“噪声”,那么该MTL网络将胜过STL网络;如果MTL受益于任务关联性,那么MTL网络的表现将不如STL网络。
实验证明,MTL要比STL更差。因此MTL一定是受益于相关任务的,这一点无需再质疑。
3. MTL的用途
3.1. Using the Future to Predict the Present
假设我们要设计一个肺炎诊断系统。该系统的输入是病人的体检数据(身高,体重,白细胞指标等),输出即是否得肺炎。
参加体检的有没患肺炎的:做了简单的检查就离开了;也有患肺炎入院的:入院后还进行了进一步的体检。
这两部分体检的数据,我们都有。前者就是所谓的"present",后者就是所谓的"future"。
前者是直接可用的,但后者是不能直接作为训练数据的!因为后者全部来源于肺炎病人,直接作为输入训练很有可能导致泛化能力的严重退化。
那么后者就要被浪费了吗?此时,MTL就提供了一个全新的方法:将这部分数据作为extra任务的输出标签。此时,该任务就可以帮助主任务更好地构建hidden layer representation。
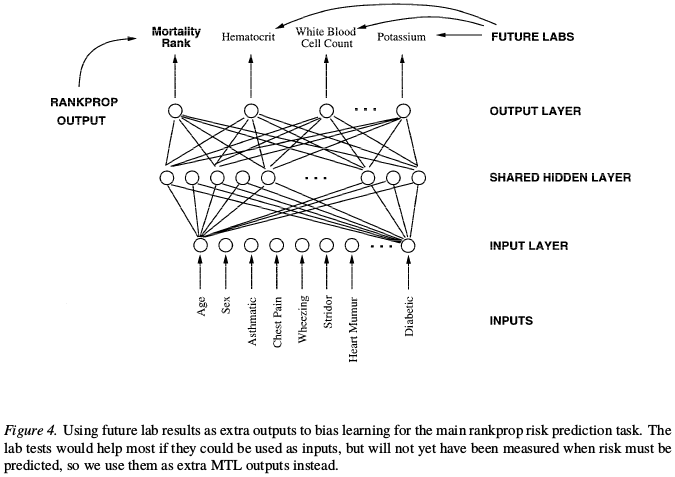
实验表明,新构建的MTL任务,比STL任务的错误率要低5%以上。(参见Multitask learning P9)
更常见的情形是:来自"future"的数据没法在训练时实时获取,但可以在运行过程中获取而用于进一步调整模型。
比如,在自动驾驶任务中,交通标线lane markings是很重要的信息。虚实,单双,黄白,都有各自的意义。
但对于一辆正在行驶的车辆而言,它只能获取一定范围内的lane marking,远处的只能在事后获取。
假设我们将预测lane markings作为extra task,显然该任务对我们的主线任务有很大的帮助。我们可以将实时获取的lane markings作为之前预测结果的label,迭代训练我们的MTL模型。
3.2. Time Series Prediction
实现时序预测问题最简单的方法是:将每一个时刻对应一个输出。
这实际上就是我们的RNN。
3.3. Using Extra Tasks to Focus Attention
刚刚我们提到,lane markings对自动驾驶任务很重要。但在实际应用中,lane markings往往只占输入图片中的一小部分,并且在快速变化甚至消失,很容易被忽略。但它又很重要。
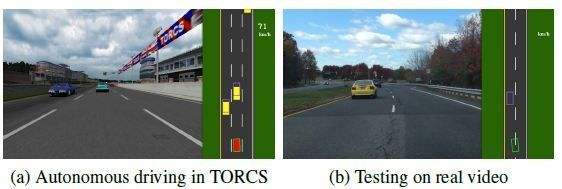
为此,我们将预测标线作为extra task,强迫网络建立起与标线相关的support,这样主线任务能从中受益。
3.4. Quantization Smoothing
我们的训练数据中,几乎都是经过量化得到的。如果我们能补偿量化带来的精度损失,那么模型的预测精度将会提高。
- 方案1:加入量化更细致的支线任务。
- 方案2:加入量化方式与主线任务不同的支线任务。
回到我们的肺炎诊断模型。肺炎诊断是一个复杂的问题,但我们将其简单地归为二分类问题,实际上是非常不合理的。
为了增强模型的预测平滑性,我们可以增加一个支线任务:预测留院时间。
该支线任务非常复杂。高危病人既有可能长时间留园,也有可能很快死亡。因此,该任务强迫我们的网络学习更加复杂的映射。
3.5. Some Inputs Work Better as Outputs
刚刚提到,有些特征无法事先得到,或是容易被忽略,因此我们将其作为输出。还有一些特征,我们将其作为输出,比作为输入更好。
参见Multitask learning P21。
这是一个人为设计的问题,此外还有一些更自然的应用。比如,当特征中存在噪声时,作为输出通常比作为输入更好。我们所谓的Dropout方法,实际上就等价于在输出中增加噪声。
3.6. 其他MTL方法
- KNN:KNN的关键在于衡量样本之间的距离。
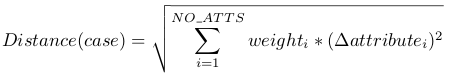
在加入其他任务一起衡量距离后,表现会更好。参见Multitask learning P23。 - Decision tree:在自上而下的推导过程中,主线任务和支线任务一起决定是否分叉。如果这些任务是相关的,那么决策会更合理。
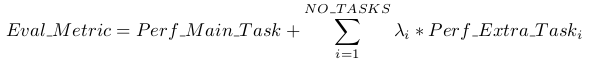
具体是计算information gain。可以引入参数lambda来控制支线任务的权重。
4. 讨论
4.1. Predictions for Multiple Tasks
MTL trains many tasks in parallel on one learner, but this does not mean one learned model should be used to make predictions for many tasks.
The reason for training multiple tasks on one learner is so one task can benefit from the information contained in the training signals of other tasks, not to reduce the number of models that must be learned.
比如我们的KNN和Decision tree,支线任务可以有权重。
这里举一个例子。NETtalk是MTL在1989年的一个代表性工作,可以根据输入的句子,同时学习phonemes和stresses,最终输出句子的英文读音。研究发现,当phoneme网络最优时,stress网络已经严重过拟合。
此时,我们应该给两个网络分配不同的学习率,或进行snapshot,不同时刻的网络给不同任务使用。
4.2. Architecture
Regularization methods such as weight decay can be used with MTL. By reducing the effective number of free parameters in the model, regularization promotes sharing.
Too strong a bias for sharing, however, can hurt performance.
MTL performance often drops if the size of the shared hidden layer is much smaller than the sum of the sizes of the STL hidden layers that would provide good performance on the tasks when trained separately.
4.3. What Are Related Tasks?
No clear definition. 事实上,CVPR 2018的best paper还在讨论这一问题。
要注意的是,如果两个任务同时训练时互相促进,不能证明它们相关。
例如,如果在BP网络中增加噪声,那么网络的泛化能力会增强,因为这相当于给hidden layer增加了正则项。但显然噪声任务与主线任务无关。
4.4. Transfer Learning
Sequential transfer learning differ from MTL, where the goal is to learn a better model for one task by learning all available extra tasks in parallel. MTL is a kind of parallel transfer.
5. 番外:生物学启发
人工神经网络在20世纪80年代末和90年代初达到巅峰,随后迅速衰落,其中一个重要原因是深度神经网络的发展严重受挫。
人们发现,如果网络的层数加深,那么最终网络的输出结果对于初始几层的参数影响微乎其微,整个网络的训练过程无法保证收敛。
同时,人们发现大脑具有不同的功能区域,每个区域专门负责同一类的任务,例如视觉图像识别, 语音信号处理和文字处理等等。在这一阶段,计算机科学家为不同的任务发展出不同的算法。例如,为了语音识别,人们发展了隐马尔科夫链模型;为了人脸识别,发展了Gaber滤波器,SIFT滤波,马尔科夫随机场的图模型。因此,在这个阶段,人们倾向于发展专用(task-specific)算法。
但是在2000年后,一系列生物学突破打破了人类对大脑的认识。
- 2000年,Jitendra Sharma等人发现小鼠的视觉、听觉神经系统是通用的。Sharma把幼年鼬鼠的视觉神经和听觉神经剪断,交换后接合,眼睛接到了听觉中枢,耳朵接到了视觉中枢。鼬鼠长大后,依然发展出了视觉和听觉。
- 2009年,Vuillerme等人让盲人用舌头掌握了“视觉”。他们将摄像机的输出表示成二维微电极矩阵,放在舌头表面。盲人经过一段时间的学习训练,可以用舌头“看到”障碍物。
- 2011年,Thaler等研究发现,盲人的视觉中枢经过训练,可以通过回声来探测并规避大的障碍物。
种种研究表明,大脑实际上是一台“万用学习机器”(Universal learning Machine)。那么,神经网络是否也应如此呢?
Paper | 多任务学习的鼻祖的更多相关文章
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- caffe实现多任务学习
Github: https://github.com/Haiyang21/Caffe_MultiLabel_Classification Blogs 1. 采用多label的lmdb+Slice L ...
- DLNg[结构化ML项目]第二周迁移学习+多任务学习
1.迁移学习 比如要训练一个放射科图片识别系统,但是图片非常少,那么可以先在有大量其他图片的训练集上进行训练,比如猫狗植物等的图片,这样训练好模型之后就可以转移到放射科图片上,模型已经从其他图片中学习 ...
- 【论文笔记】多任务学习(Multi-Task Learning)
1. 前言 多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法.在机器学习领域,标准的算法理论是一次学习一个任务,也就 ...
- 深度神经网络多任务学习(Multi-Task Learning in Deep Neural Networks)
https://cloud.tencent.com/developer/article/1118159 http://ruder.io/multi-task/ https://arxiv.org/ab ...
- keras函数式编程(多任务学习,共享网络层)
https://keras.io/zh/ https://keras.io/zh/getting-started/functional-api-guide/ https://github.com/ke ...
- 多任务学习Multi-task-learning MTL
https://blog.csdn.net/chanbo8205/article/details/84170813 多任务学习(Multitask learning)是迁移学习算法的一种,迁移学习可理 ...
- [译]深度神经网络的多任务学习概览(An Overview of Multi-task Learning in Deep Neural Networks)
译自:http://sebastianruder.com/multi-task/ 1. 前言 在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI.为了达到这个目标,我 ...
- ubuntu之路——day11.6 多任务学习
在迁移学习transfer learning中,你的步骤是串行的sequential process 在多任务学习multi-task learning中,你试图让单个神经网络同时做几件事情,然后这里 ...
随机推荐
- 基于mysql创建库的报错解决小记mysql ERROR 1044 (42000): Access denied for user ''@'localhost' to database
mysql ERROR 1044 (42000): Access denied for user ''@'localhost' to database异常处理 1.找到find / -name my. ...
- java api 批量数据库操作
Statement.class:executeBatch() implement interface: PreparedStatement implement class: JdbcOdbcPrepa ...
- 自己实现ArrayList
思路: 一 载体 ArrayList是一个集合容器,必然要有一个保存数据的载体. public class MyArraylist { private final static int INIT_CO ...
- 9. maps
C++有vertor,java有HashMap,C语言想使用则需要自行封装,不同的类型还需要再封装,特别麻烦. 看看Go语言的map的使用方法:var member map[string]int,创建 ...
- mysql concat筛选查询重复数据
SELECT * from (SELECT *,concat(field0,field1)as c from tableName) tt GROUP BY c HAVING count(c) > ...
- 记录一次程序输出和DB查询不匹配的问题
今天发生一件很神奇的事情,我用TP读取DB数据,然后打印出来的数据,和直接通过sequal pro查询出来的数据(某一列),怎么对都对不起来,我尝试 清空TP缓存 MYSQL服务重启 mac重启 都无 ...
- 关于图片无法输出的问题使用ob_clean()
前两天相当于炸锅了,用户量在三百万左右,用户一直使用二维码在门店进行消费,晚上八九点钟时 ,居然全都打不开了 原图 出问题的图 本该是二维码的出现不了,代码使用的是PHP的qrcode,蒙圈了,查询了 ...
- C#.GetHashCode方法简单比较
- lodash 判断一个数据是否包含另一个数组
if (_.intersection(v.ids, value).length == value.length) { this.groupListExtData.push(v.names); } ...
- error: ModuleNotFoundError: No module named 'ConfigParser'
(env2.7) Kaitlyns-Mac:bin kaitlyn$ pip install MySQL-python Looking in indexes: https://pypi.tuna.ts ...