Django的URL路由系统
一. URL配置
URL配置就像Django所支撑网站的目录.它的本质是URL与要为该URL调用的视图之间的映射表.你就是以这种方式告诉Django,对于哪个URL调用的这段代码.
基本格式
from django.conf.urls import url
#循环urlpatterns,找到对应的函数执行,匹配上一个路径就找到对应的函数执行,就不再往下循环了,并给函数床底一个参数request,和wsgiref的environ类似,就是请求信息的所有内容
urlpatterns = [
url(正则表达式,views.函数,{"参数":别名}),
]
现在普遍使用Django2.0版本的路由系统,向下兼容1.x版本的语法
from django.urls import path urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail),
]
参数说明
(1) 正则表达式: 一个正则表达式字符串
(2) views视图函数: 一个可调用的对象,通常为一个视图函数或一个指定视图函数路径的字符串
(3) 参数: 可选的要传递给视图函数的默认参数(字典形式)
(4)别名: 一个可选的name参数
二. 正则表达式详解
基本配置
from django .conf.urls import url
from app(应用) import views
urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003), #思考:
如果用户想看2004、2005、2006....等,你要写一堆的url吗,
是不是在articles后面写一个正则表达式/d{4}/就行啦,网址里面输入
127.0.0.1:8000/articles/1999/试一下看看
url(r'^articles/([0-9]{4})/$', views.year_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), #思考,
如果你想拿到用户输入的什么年份,并通过这个年份去数据库里面匹配对应年份的文章,你怎么办?
怎么获取用户输入的年份啊,分组/(\d{4})/,一个小括号搞定
url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
]
注意事项
1. urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续.
2. 若要从URL中捕获一个值,只需要在它周围放置一对圆括号(分组匹配).
3.不需要添加一个前导的反斜杠(也就是写在正则最前面的那个/),因为每个URL都有.例如,应该是^articles而不是^/articles.
4.每个正则表达式前面的'r'是可选的但建议加上
5.^articles& 以什么开头以什么结尾,严格限制路径.
补充说明
# 是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
APPEND_SLASH=True
Django settings.py配置文件中默认没有 APPEND_SLASH这个参数,但DJango默认这个参数是APPEND_SLASH = True.其作用是自动在网址结尾加上'/'.其效果就是:我们定义了urls.py:
from django.conf.urls import url
from app01 import views urlpatterns = [
url(r'^blog/$', views.blog),
访问 http://www.example.com/blog 时,默认将网址自动转换为 http://www.example/com/blog/ 。
如果在settings.py中设置了 APPEND_SLASH=False,此时我们再请求 http://www.example.com/blog 时就会提示找不到页面。
三. 分组命名匹配
上面的实例使用简单的正则表达式分组匹配(通过圆括号) 来捕获URL中的值并以位置参数形式形式传递给视图.
在更高级的用法中,可以使用分组命名匹配的正则表达式组来捕获URL中的值并以关键字参数形式传递给视图.
在Python的正则表达式中,分组命名正则表达式组的语法(?P<name>pattern),其中name是组的名称,pattern是要匹配的模式.
下面是以上URLconf使用命名组的重写:
from django.conf.urls import url from . import views urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003), #主意正则匹配出来的是字符串,
即便是你在url里边写的是2003数字,匹配出来的也是字符串.
url(r'^articles/(\d{4})/$', views.year_archive),#year_archive(request,2003),
小括号表示分组,有分组,name这个分组得到的是用户输入的内容,就会作为对应函数的位置参数传进去,
别忘了形参要写两个.
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),#某年的,
(?P<year>[0-9]{4}),这是命名参数(正则命名匹配),那么函数year_archive(request,year),
形参名称必须是year这个名字.而且注意如果你这个正则后面没有$符号,即便是输入了月份路径,
也会被它拦截下来,因为它的正则也能匹配上
url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
#某年某月的
url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$',
views.article_detail), #某年某月某日的
]
这个实现与前面的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给试图函数.
例如,针对url /articles/2017/12/相当于按以下方式调用视图函数:
views.month_archive(request, year="2017", month="12"),year和month的位置可以换,
没所谓了,因为是按照名字来取数据的.
URLconf匹配位置
URLconf在请求的URL上查找,将它当做一个普通的Python字符串.不包括GET和POST参数以及域名.
例如,http://www.example.com/myapp/ 请求中,URLconf 将查找myapp/。
在http://www.example.com/myapp/?page=3 请求中,URLconf 仍将查找myapp/。
URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的POST、GET、HEAD等等 —— 都将路由到相同的函数。
捕获的参数永远都是字符串
每个在URLconf中捕获的参数都作为一个普通的Python字符串传递给视图,无论正则表达式使用的是什么匹配方式.例如:
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
传递到试图函数views.year_archive()中的year参数永远是一个字符串类型.
视图函数中指定默认值
# urls.py中
from django.conf.urls import url from . import views urlpatterns = [
url(r'^blog/$', views.page),
url(r'^blog/page(?P<num>[0-9]+)/$', views.page),
] # views.py中,可以为num指定默认值
def page(request, num="1"):
pass
在上面的例子中,两个URL模式指向相同的view - views.page - 但是第一个模式并没有从URL中捕获任何东西。
如果第一个模式匹配上了,page()函数将使用其默认参数num=“1”,如果第二个模式匹配,page()将使用正则表达式捕获到的num值。
include其他的URLconfs(也叫URL分发)
问大家一个问题,views和models文件是不是都放在每一个app应用里面了啊,而urls.py这个文件放在哪了,是不是放在项目文件夹里面了,说明什么,说明是不是所有的app都在使用它,如果你一个项目有10个应用,每个应用有100个url,那意味着你要在urls文件里面要写多少条url对应关系,并且所有的app的url都写在了这一个urls文件里面啊,这样好吗,当然也没有问题,但是耦合程度太高了,所以django在url这里给你提供了一个分发接口,叫做include.
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^blog/', include('blog.urls')), # 可以包含其他的URLconfs文件
url(r'^app01/',include('app01.urls')),#别忘了要去app01这个应用下创建一个urls.py
的文件,现在的意思是凡是以app01开头的路径请求,都让它去找app01下面的urls文件中去找对应的视图函数
,还要注意一点,此时的这个文件里面的那个app01路径不能用$结尾,因为如果写了$,
就没办法匹配app01/后面的路径了.
app01的urls.py的内容:(其实就是将全局的urls.py里面的内容copy一下,放到你在app01文件夹下创建的那个urls.py文件中,把不是这个app01应用的url给删掉就行了)
from django.conf.urls import url
#from django.contrib import admin
from app01 import views urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^articles/2003/', views.special_case_2003,{'foo':'xxxxx'}),
url(r'^articles/(\d{4})/(\d{2})/', views.year_archive), ]
如果我们想通过输入http://127.0.0.1:8000/app01/,看到app01这个应用的首页,怎么办?就像我现在输入一个http://127.0.0.1:8000来查看网站的首页,怎么办,也就是说我后面不加任何路径,就看你网址的首页,怎么办,一般网站的根路径都是网站的首页,对不对
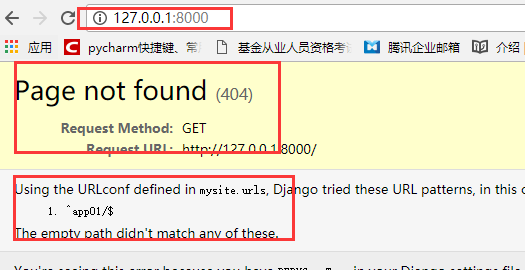
看下面这种写法可不可以:


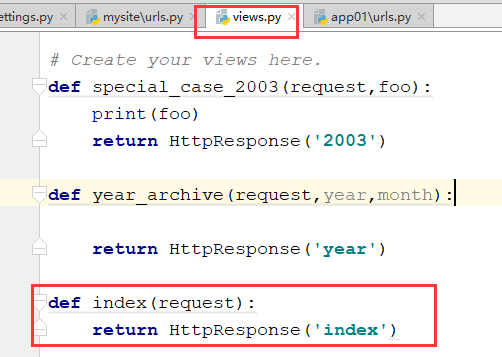
views.py里面写函数index:
输入网址:
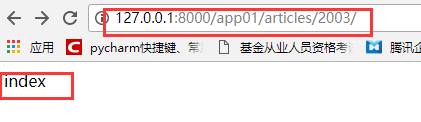
发现都跑到index这个函数里面去执行了,也就是说,全部被这个没有匹配规则的url获取到了.
所以正确写法,匹配根路径的解法:
url(r'^$',views.index),#以空开头,还要以空结尾,写在项目的urls.py文件里面就是项目的首页,写在应用文件夹里面的urls.py文件中,那就是app01的首页.
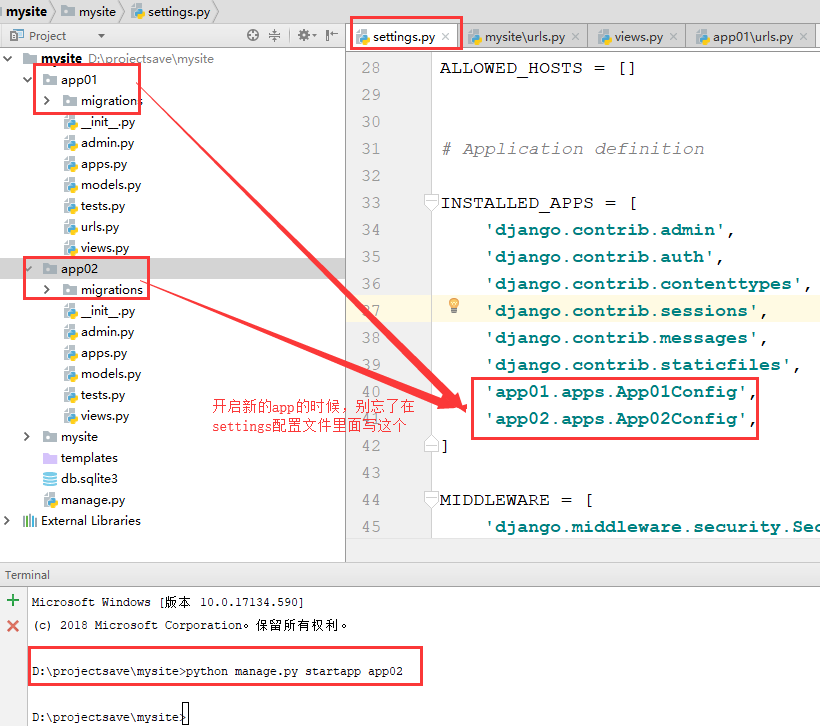
还有注意一点,就是加app的时候,需要进行配置:(startapp app名字)
四.命名URL(别名) 和 URL的反向解析
简单来说就是可以给我们的URL匹配规则起个名字,一个URL匹配模式起一个名字。这样我们以后就不需要写死URL代码了,只需要通过名字来调用当前的URL。
举个简单的例子:
url(r'^home', views.home, name='home'), #给我的url匹配模式起名(别名)为home,别名不需要改,
路径你就可以随便改了,别的地方使用这个路径,就用别名来搞.
url(r'^index/(\d*)', views.index, name='index'), # 给我的url匹配模式起名为index
在模板里这样引用:
{% url 'home' %} #模板选择的时候,被django解析成了这个名字对应的url,这个过程叫做反向解析
在views函数中可以这样引用:(后面再讲这个视图函数应用反向解析的内容,上面的是模板应用反向解析的过程)
from django.urls import reverse
reverse("index", args=("2018", ))
例子:(考虑下面的URLconf)
from django.conf.urls import url from . import views urlpatterns = [
# ...
url(r'^articles/([0-9]{4})/$', views.year_archive, name='news-year-archive'),
# ...
]
根据这里的设计,某一年nnnn对应的归档的URL是/articles/nnnn/。
你可以在模板的代码中使用下面的方法获得它们:
<a href="{% url 'news-year-archive' 2012 %}">2012 Archive</a>
<ul>
{% for yearvar in year_list %}
<li>
<a href="{% url 'news-year-archive' yearvar %}">{{ yearvar }}Archive</a>
</li>
</ul>
在Python 代码中,这样使用:
from django.urls import reverse
from django.shortcuts import redirect def redirect_to_year(request):
# ...
year = 2006
# ...
return redirect(reverse('news-year-archive', args=(year,)))
如果出于某种原因决定按年归档文章发布的URL应该调整一下,那么你将只需要修改URLconf 中的内容。
在某些场景中,一个视图是通用的,所以在URL 和视图之间存在多对一的关系。对于这些情况,当反查URL 时,只有视图的名字还不够。
注意
为了完成上面例子中的URL 反查,你将需要使用命名的URL 模式。URL 的名称使用的字符串可以包含任何你喜欢的字符。不只限制在合法的Python 名称。
当命名你的URL 模式时,请确保使用的名称不会与其它应用中名称冲突。如果你的URL 模式叫做comment,而另外一个应用中也有一个同样的名称,当你在模板中使用这个名称的时候不能保证将插入哪个URL。
在URL 名称中加上一个前缀,比如应用的名称,将减少冲突的可能。我们建议使用myapp-comment 而不是comment。
Django的URL路由系统的更多相关文章
- Django之URL路由系统
一 URL配置 Django 1.11版本 URLConf官方文档 URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表.你就是以这 ...
- Django之URL(路由系统)用法
路由系统 路由系统概念 简而言之,路由系统就是路径和视图函数的一个对应关系.django的路由系统作用就是使views里面处理数据的函数与请求的url建立映射关系.使请求到来之后,根据urls.py里 ...
- 【Django】url(路由系统)
1.单一路由对应 url(r'^index/',views.index), 2.基于正则的路由 url(r'^index/(\d*)', views.index), url(r'^manage/(?P ...
- Django学习:url路由系统
一.MTV模型 1.Django的MTV分别代表: Model(模型):和数据库相关的,负责业务对象与数据库的对象(ORM) Template(模板):放所有的html文件 模板语法:目的是将白变量( ...
- python django基础二URL路由系统
URL配置 基本格式 from django.conf.urls import url #循环urlpatterns,找到对应的函数执行,匹配上一个路径就找到对应的函数执行,就不再往下循环了,并给函数 ...
- django 中的路由系统(url)
路由系统 根据Django约定,一个WSGI应用里最核心的部件有两个:路由表和视图.Django框架 的核心功能就是路由:根据HTTP请求中的URL,查找路由表,将HTTP请求分发到 不同的视图去处理 ...
- day 66 Django基础二之URL路由系统
Django基础二之URL路由系统 本节目录 一 URL配置 二 正则表达式详解 三 分组命名匹配 四 命名URL(别名)和URL反向解析 五 命名空间模式 一 URL配置 Django 1.11 ...
- day 53 Django基础二之URL路由系统
Django基础二之URL路由系统 本节目录 一 URL配置 二 正则表达式详解 三 分组命名匹配 四 命名URL(别名)和URL反向解析 五 命名空间模式 一 URL配置 Django 1.11 ...
- URL路由系统-命名空间
命名空间 1.工程Django下的urs.py from django.conf.urls import url,include from django.urls import path,re_pat ...
随机推荐
- python写的压缩软件
import tkinterimport tkinter.filedialogimport osimport zipfileimport tkinter.messagebox #创建住窗口root = ...
- Python面向对象1:类与对象
Python的面向对象- 面向对象编程 - 基础 - 公有私有 - 继承 - 组合,Mixin- 魔法函数 - 魔法函数概述 - 构造类魔法函数 - 运算类魔法函数 # 1. 面向对象概述(Objec ...
- jQuery文档操作
jQuery文档操作 1.jq文档结构 var $sup = $('.sup'); $sup.children(); // sup所有的子级们 $sup.parent(); // sup的父级(一个, ...
- FAIR开源Detectron:整合全部顶尖目标检测算法
昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标检测平台. 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标 ...
- 机器学习入门07 - 验证 (Validation)
原文链接:https://developers.google.com/machine-learning/crash-course/validation/ 1- 检查直觉 将一个数据集划分为训练集和测试 ...
- [原创]k8exe2bat任意文件转Bat工具(WebShell无法上传EXE解决方案)
http://qqhack8.blog.163.com/blog/static/114147985201126105626755/ 这是我2011年的东西了,当时用此方法可免杀很多马,至今依然有很大的 ...
- Spring面试底层原理的那些问题,你是不是真的懂Spring?
1.什么是 Spring 框架?Spring 框架有哪些主要模块?Spring 框架是一个为 Java 应用程序的开发提供了综合.广泛的基础性支持的 Java 平台.Spring帮助开发者解决了开发中 ...
- odoo开发笔记 -- self详解
python中一切皆对象! odoo基于python开发,那么odoo中也可以理解成一切皆对象. 我们在python中定义类的时候,一般会用到self,用来表示当前对象自己. 那么odoo中的self ...
- app 压力测试
monkey工具详解 https://blog.csdn.net/jffhy2017/article/details/54572400 ----------------------- Android ...
- Nginx安装echo模块
echo-nginx-module 模块可以在Nginx中用来输出一些信息,可以用来实现简单接口或者排错. 项目地址:https://github.com/openresty/echo-nginx-m ...