深度学习框架PyTorch一书的学习-第六章-实战指南
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter6-实战指南
希望大家直接到上面的网址去查看代码,下面是本人的笔记
将上面地址的代码下载到本地后进行操作
1.安装依赖
(deeplearning) userdeMacBook-Pro:dogcat- user$ pip install -r requirements.txt
...
Successfully built fire ipdb torchnet
Installing collected packages: fire, tqdm, ipdb, torchnet
Successfully installed fire-0.1. ipdb-0.12 torchnet-0.0. tqdm-4.31.
在https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter6-实战指南处将需要的数据下载下来,并放在./data/train/和./data/test1处
2.训练
必须首先启动visdom:
(deeplearning) userdeMBP:~ user$ python -m visdom.server
It's Alive!
然后使用如下命令启动训练:
# 在gpu0上训练,并把可视化结果保存在visdom 的classifier env上
python main.py train --train-data-root=./data/train --use-gpu --env=classifier
详细的使用命令 可使用
python main.py help
3.测试
python main.py test --data-root=./data/test --batch-size= --load-path='checkpoints/squeezenet.pth'
4.代码分析
在从事大多数深度学习研究时,程序都需要实现以下几个功能:
- 模型定义
- 数据处理和加载
- 训练模型(Train&Validate)
- 训练过程的可视化
- 测试(Test/Inference)
1)该网络介绍
Dogs vs. Cats是一个传统的二分类问题,其训练集包含25000张图片,均放置在同一文件夹下,命名格式为<category>.<num>.jpg, 如cat.10000.jpg、dog.100.jpg,测试集包含12500张图片,命名为<num>.jpg,如1000.jpg。参赛者需根据训练集的图片训练模型,并在测试集上进行预测,输出它是狗的概率。最后提交的csv文件如下,第一列是图片的<num>,第二列是图片为狗的概率。
id,label
,0.889
,0.01
...
2)文件组织架构
前面提到过,程序主要包含以下功能:
- 模型定义
- 数据加载
- 训练和测试
首先来看程序文件的组织结构:
├── checkpoints/
├── data/
│ ├── __init__.py
│ ├── dataset.py
│ └── get_data.sh
├── models/
│ ├── __init__.py
│ ├── AlexNet.py
│ ├── BasicModule.py
│ └── ResNet34.py
└── utils/
│ ├── __init__.py
│ └── visualize.py
├── config.py
├── main.py
├── requirements.txt
├── README.md
其中:
checkpoints/: 用于保存训练好的模型,可使程序在异常退出后仍能重新载入模型,恢复训练data/:数据相关操作,包括数据预处理、dataset实现等models/:模型定义,可以有多个模型,例如上面的AlexNet和ResNet34,一个模型对应一个文件utils/:可能用到的工具函数,在本次实验中主要是封装了可视化工具config.py:配置文件,所有可配置的变量都集中在此,并提供默认值main.py:主文件,训练和测试程序的入口,可通过不同的命令来指定不同的操作和参数requirements.txt:程序依赖的第三方库README.md:提供程序的必要说明
3)__init__.py文件
可以看到,几乎每个文件夹下都有__init__.py,一个目录如果包含了__init__.py 文件,那么它就变成了一个包(package)。
__init__.py可以为空,也可以定义包的属性和方法,但其必须存在,其它程序才能从这个目录中导入相应的模块或函数。例如在data/文件夹下有__init__.py,则在main.py 中就可以from data.dataset import DogCat。而如果在__init__.py中写入from .dataset import DogCat,则在main.py中就可以直接写为:from data import DogCat,或者import data; dataset = data.DogCat,相比于from data.dataset import DogCat更加便捷。
4)数据加载
数据的相关处理主要保存在data/dataset.py中。关于数据加载的相关操作,在上一章中我们已经提到过,其基本原理就是使用Dataset提供数据集的封装,再使用Dataloader实现数据并行加载。Kaggle提供的数据包括训练集和测试集,而我们在实际使用中,还需专门从训练集中取出一部分作为验证集。
对于这三类数据集,其相应操作也不太一样,而如果专门写三个Dataset,则稍显复杂和冗余,因此这里通过加一些判断来区分。对于训练集,我们希望做一些数据增强处理,如随机裁剪、随机翻转、加噪声等,而验证集和测试集则不需要。下面看dataset.py的代码:
# coding:utf8
import os
from PIL import Image
from torch.utils import data
import numpy as np
from torchvision import transforms as T class DogCat(data.Dataset): def __init__(self, root, transforms=None, train=True, test=False):
"""
主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据
"""
self.test = test
imgs = [os.path.join(root, img) for img in os.listdir(root)] # test1: data/test1/.jpg
# train: data/train/cat..jpg if self.test:
# 如果是进行测试,截取得到数据的数字标码,如上面的8973,根据key=8973的值进行排序,返回对所有的图片路径进行排序后返回
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-].split('/')[-]))
else:
#如果是进行训练,截取得到数据的数字标识,如上面的10004,根据key=10004的值进行排序,返回对所有的图片路径进行排序后返回
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-])) imgs_num = len(imgs) #然后就可以得到数据的大小 if self.test:
# 如果是进行测试
self.imgs = imgs
elif train:
#如果是进行训练,使用前70%的数据
self.imgs = imgs[:int(0.7 * imgs_num)]
else:
#如果是进行验证,使用后30%的数据
self.imgs = imgs[int(0.7 * imgs_num):] if transforms is None:
# 数据转换操作,测试验证和训练的数据转换有所区别 # 对数据进行归一化
normalize = T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 当是测试集和验证集时进行的操作
if self.test or not train:
self.transforms = T.Compose([
T.Resize(), #重新设定大小
T.CenterCrop(), #从图片中心截取
T.ToTensor(), #转成Tensor格式,大小范围为[,]
normalize #归一化处理,大小范围为[-,]
])
else:
self.transforms = T.Compose([
T.Resize(),
T.RandomReSizedCrop(), #从图片的任何部位随机截取224*224大小的图
T.RandomHorizontalFlip(), #随机水平翻转给定的PIL.Image,翻转概率为0.
T.ToTensor(),
normalize
]) def __getitem__(self, index):
"""
一次返回一张图片的数据
"""
img_path = self.imgs[index]
if self.test:
#如果是测试,得到图片路径中的数字标识作为label
label = int(self.imgs[index].split('.')[-].split('/')[-])
else:
#如果是训练,判断图片路径中是猫狗来设定label,猫为0,狗为1
label = if 'dog' in img_path.split('/')[-] else
data = Image.open(img_path) #打开该路径获得数据
data = self.transforms(data) #然后对图片数据进行transform
return data, label #最后得到统一的图片信息和label信息 def __len__(self): #图片数据的大小
return len(self.imgs)
关于数据集使用的注意事项,在上一章中已经提到,将文件读取等费时操作放在__getitem__函数中,利用多进程加速。避免一次性将所有图片都读进内存,不仅费时也会占用较大内存,而且不易进行数据增强等操作。
另外在这里,我们将训练集中的30%作为验证集,可用来检查模型的训练效果,避免过拟合。
在使用时,我们可通过dataloader加载数据。
#进行训练,定义训练数据和label集合train_dataset
train_dataset = DogCat(opt.train_data_root, train=True)
#开始进行数据的加载,将数据打乱(shuffle = True),
#随机将数据分批,一批有opt.batch_size个,并行处理,打开opt.num_workers个进程
trainloader = DataLoader(train_dataset,
batch_size = opt.batch_size,
shuffle = True,
num_workers = opt.num_workers)
#显示得到的数据
for ii, (data, label) in enumerate(trainloader):
train() #然后进行训练
5)模型定义
模型的定义主要保存在models/目录下,其中BasicModule是对nn.Module的简易封装,提供快速加载和保存模型的接口
#coding:utf8
import torch as t
import time class BasicModule(t.nn.Module):
"""
封装了nn.Module,主要是提供了save和load两个方法
""" def __init__(self):
super(BasicModule,self).__init__()
self.model_name=str(type(self))# 默认名字 def load(self, path):
"""
可加载指定路径的模型
"""
self.load_state_dict(t.load(path)) def save(self, name=None):
"""
保存模型,默认使用“模型名字+时间”作为文件名
"""
if name is None:
#存储到文件夹checkpoints下面
prefix = 'checkpoints/' + self.model_name + '_'
name = time.strftime(prefix + '%m%d_%H:%M:%S.pth')
t.save(self.state_dict(), name)
return name def get_optimizer(self, lr, weight_decay): #优化器
return t.optim.Adam(self.parameters(), lr=lr, weight_decay=weight_decay) class Flat(t.nn.Module):
"""
把输入reshape成(batch_size,dim_length)
""" def __init__(self):
super(Flat, self).__init__()
#self.size = size def forward(self, x):
return x.view(x.size(), -) #得到的是批数据的大小
在实际使用中,直接调用model.save()及model.load(opt.load_path)即可。
其它自定义模型一般继承BasicModule,然后实现自己的模型。其中alexNet.py实现了AlexNet,resNet34实现了ResNet34。在models/__init__py中,代码如下:
from .alexnet import AlexNet
from .resnet34 import ResNet34
from .squeezenet import SqueezeNet
# from torchvision.models import InceptinV3
# from torchvision.models import alexnet as AlexNet
alexnet.py为:
# coding:utf8
from torch import nn
from .basic_module import BasicModule class AlexNet(BasicModule):
"""
code from torchvision/models/alexnet.py
结构参考 <https://arxiv.org/abs/1404.5997>
""" def __init__(self, num_classes=):
super(AlexNet, self).__init__() self.model_name = 'alexnet' self.features = nn.Sequential(
nn.Conv2d(, , kernel_size=, stride=, padding=),
nn.ReLU(inplace=True), # inplace-选择是否进行覆盖运算
nn.MaxPool2d(kernel_size=, stride=),
nn.Conv2d(, , kernel_size=, padding=),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=, stride=),
nn.Conv2d(, , kernel_size=, padding=),
nn.ReLU(inplace=True),
nn.Conv2d(, , kernel_size=, padding=),
nn.ReLU(inplace=True),
nn.Conv2d(, , kernel_size=, padding=),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=, stride=),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear( * * , ),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(, ),
nn.ReLU(inplace=True),
nn.Linear(, num_classes),
) def forward(self, x):
x = self.features(x)
x = x.view(x.size(), * * )
x = self.classifier(x)
return x
resnet34.py为:
# coding:utf8
from .basic_module import BasicModule
from torch import nn
from torch.nn import functional as F class ResidualBlock(nn.Module):
"""
实现子module: Residual Block
""" def __init__(self, inchannel, outchannel, stride=, shortcut=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, , stride, , bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, , , , bias=False),
nn.BatchNorm2d(outchannel))
self.right = shortcut def forward(self, x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out) class ResNet34(BasicModule):
"""
实现主module:ResNet34
ResNet34包含多个layer,每个layer又包含多个Residual block
用子module来实现Residual block,用_make_layer函数来实现layer
""" def __init__(self, num_classes=):
super(ResNet34, self).__init__()
self.model_name = 'resnet34' # 前几层: 图像转换
self.pre = nn.Sequential(
nn.Conv2d(, , , , , bias=False),
nn.BatchNorm2d(),
nn.ReLU(inplace=True),
nn.MaxPool2d(, , )) # 重复的layer,分别有3,,,3个residual block
self.layer1 = self._make_layer(, , )
self.layer2 = self._make_layer(, , , stride=)
self.layer3 = self._make_layer(, , , stride=)
self.layer4 = self._make_layer(, , , stride=) # 分类用的全连接
self.fc = nn.Linear(, num_classes) def _make_layer(self, inchannel, outchannel, block_num, stride=):
"""
构建layer,包含多个residual block
"""
shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, , stride, bias=False),
nn.BatchNorm2d(outchannel)) layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut)) for i in range(, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers) def forward(self, x):
x = self.pre(x) x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x) x = F.avg_pool2d(x, )
x = x.view(x.size(), -)
return self.fc(x)
这样在主函数中就可以写成:
from models import AlexNet
或
import models
model = models.AlexNet()
或
import models
model = getattr('models', 'AlexNet')()
其中最后一种写法最为关键,这意味着我们可以通过字符串直接指定使用的模型,而不必使用判断语句,也不必在每次新增加模型后都修改代码。新增模型后只需要在models/__init__.py中加上from .new_module import new_module即可。
其它关于模型定义的注意事项,在上一章中已详细讲解,这里就不再赘述,总结起来就是:
- 尽量使用
nn.Sequential(比如AlexNet) - 将经常使用的结构封装成子Module(比如GoogLeNet的Inception结构,ResNet的Residual Block结构)
- 将重复且有规律性的结构,用函数生成(比如VGG的多种变体,ResNet多种变体都是由多个重复卷积层组成)
6)工具函数——实现可视化visdom
在项目中,我们可能会用到一些helper方法,这些方法可以统一放在utils/文件夹下,需要使用时再引入。在本例中主要是封装了可视化工具visdom的一些操作,其代码如下,在本次实验中只会用到plot方法,用来统计损失信息。
# coding:utf8
import visdom
import time
import numpy as np class Visualizer(object):
"""
封装了visdom的基本操作,但是你仍然可以通过`self.vis.function`
调用原生的visdom接口
""" def __init__(self, env='default', **kwargs):
self.vis = visdom.Visdom(env=env,use_incoming_socket=False, **kwargs) # 画的第几个数,相当于横座标
# 保存(’loss',23) 即loss的第23个点
self.index = {}
self.log_text = '' def reinit(self, env='default', **kwargs):
"""
修改visdom的配置
"""
self.vis = visdom.Visdom(env=env, **kwargs)
return self def plot_many(self, d):
"""
一次plot多个
@params d: dict (name,value) i.e. ('loss',0.11)
"""
for k, v in d.items():
self.plot(k, v) def img_many(self, d):
for k, v in d.items():
self.img(k, v) def plot(self, name, y, **kwargs):
"""
self.plot('loss',1.00)
"""
x = self.index.get(name, )
self.vis.line(Y=np.array([y]), X=np.array([x]),
win=name,
opts=dict(title=name),
update=None if x == else 'append',
**kwargs
)
self.index[name] = x + def img(self, name, img_, **kwargs):
"""
self.img('input_img',t.Tensor(,))
self.img('input_imgs',t.Tensor(,,))
self.img('input_imgs',t.Tensor(,,,))
self.img('input_imgs',t.Tensor(,,,),nrows=) !!!don‘t ~~self.img('input_imgs',t.Tensor(,,),nrows=)~~!!!
"""
self.vis.images(img_.cpu().numpy(),
win=name,
opts=dict(title=name),
**kwargs
) def log(self, info, win='log_text'):
"""
self.log({'loss':,'lr':0.0001})
""" self.log_text += ('[{time}] {info} <br>'.format(
time=time.strftime('%m%d_%H%M%S'),
info=info))
self.vis.text(self.log_text, win) def __getattr__(self, name):
return getattr(self.vis, name)
7)配置文件
在模型定义、数据处理和训练等过程都有很多变量,这些变量应提供默认值,并统一放置在配置文件中,这样在后期调试、修改代码或迁移程序时会比较方便,在这里我们将所有可配置项放在config.py中。
# coding:utf8
import warnings
import torch as t class DefaultConfig(object):
env = 'default' # visdom 环境
vis_port = # visdom 端口
model = 'SqueezeNet' # 使用的模型,名字必须与models/__init__.py中的名字一致 train_data_root = './data/train/' # 训练集存放路径
test_data_root = './data/test1' # 测试集存放路径
load_model_path = None # 加载预训练的模型的路径,为None代表不加载 batch_size = # batch size
use_gpu = True # user GPU or not
num_workers = # how many workers for loading data
print_freq = # print info every N batch debug_file = '/tmp/debug' # if os.path.exists(debug_file): enter ipdb
result_file = 'result.csv' max_epoch =
lr = 0.001 # initial learning rate
lr_decay = 0.5 # when val_loss increase, lr = lr*lr_decay
weight_decay = 0e- # 损失函数
可配置的参数主要包括:
- 数据集参数(文件路径、batch_size等)
- 训练参数(学习率、训练epoch等)
- 模型参数
这样我们在程序中就可以这样使用:
import models
from config import DefaultConfig opt = DefaultConfig()
lr = opt.lr
model = getattr(models, opt.model)
dataset = DogCat(opt.train_data_root)
这些都只是默认参数,在这里还提供了更新函数,根据字典更新配置参数:
def _parse(self, kwargs):
"""
根据字典kwargs 更新 config参数
"""
# 更新配置参数
for k, v in kwargs.items():
if not hasattr(self, k):
# 警告还是报错,取决于你个人的喜好
warnings.warn("Warning: opt has not attribut %s" % k)
setattr(self, k, v) opt.device =t.device('cuda') if opt.use_gpu else t.device('cpu') # 打印配置信息
print('user config:')
for k, v in self.__class__.__dict__.items():
if not k.startswith('_'):
print(k, getattr(self, k))
这样我们在实际使用时,并不需要每次都修改config.py,只需要通过命令行传入所需参数,覆盖默认配置即可。
例如:
opt = DefaultConfig()
new_config = {'lr':0.1,'use_gpu':False}
opt.parse(new_config)
opt.lr == 0.1
8)main.py
1>fire
2017年3月谷歌开源的一个命令行工具fire^3 ,通过pip install fire即可安装。下面来看看fire的基础用法,假设example.py文件内容如下:
import fire def add(x, y):
return x + y def mul(**kwargs):
a = kwargs['a']
b = kwargs['b']
return a * b if __name__ == '__main__':
fire.Fire()
那么我们可以使用:
python example.py add # 执行add(, )
python example.py mul --a= --b= # 执行mul(a=, b=), kwargs={'a':, 'b':}
python example.py add --x= --y== # 执行add(x=, y=)
可见,只要在程序中运行fire.Fire(),即可使用命令行参数python file <function> [args,] {--kwargs,}。fire还支持更多的高级功能,具体请参考官方指南^4 。
2>main.py
在主程序main.py中,主要包含四个函数,其中三个需要命令行执行,main.py的代码组织结构如下:
def train(**kwargs):
"""
训练
"""
pass def val(model, dataloader):
"""
计算模型在验证集上的准确率等信息,用以辅助训练
"""
pass def test(**kwargs):
"""
测试(inference)
"""
pass def help():
"""
打印帮助的信息
"""
print('help') if __name__=='__main__':
import fire
fire.Fire()
根据fire的使用方法,可通过python main.py <function> --args=xx的方式来执行训练或者测试。
1》训练
训练的主要步骤如下:
- 定义网络
- 定义数据
- 定义损失函数和优化器
- 计算重要指标
- 开始训练
- 训练网络
- 可视化各种指标
- 计算在验证集上的指标
训练函数的代码如下:
def train(**kwargs):
#根据传入的参数更改配置信息
opt._parse(kwargs)
vis = Visualizer(opt.env,port = opt.vis_port) # step1: configure model配置模型
model = getattr(models, opt.model)() #默认使用模型SqueezeNet
if opt.load_model_path: # 加载预训练的模型的路径
model.load(opt.load_model_path)
model.to(opt.device) #使用的是GPU还是CPU # step2: data加载数据
train_data = DogCat(opt.train_data_root,train=True) #训练数据
val_data = DogCat(opt.train_data_root,train=False) #测试数据
train_dataloader = DataLoader(train_data,opt.batch_size,
shuffle=True,num_workers=opt.num_workers)
val_dataloader = DataLoader(val_data,opt.batch_size,
shuffle=False,num_workers=opt.num_workers) # step3: criterion and optimizer ,损失函数和优化器
criterion = t.nn.CrossEntropyLoss()
lr = opt.lr
optimizer = model.get_optimizer(lr, opt.weight_decay) # step4: meters,统计指标:平滑处理之后的损失,还有混淆矩阵
loss_meter = meter.AverageValueMeter() #能够计算所有数的平均值和标准差,用来统计一个epoch中损失的平均值
confusion_matrix = meter.ConfusionMeter() #用来统计分类问题中的分类情况,是一个比准确率更详细的统计指标
previous_loss = 1e10 # train,开始训练
for epoch in range(opt.max_epoch): #迭代次数 loss_meter.reset()
confusion_matrix.reset() for ii,(data,label) in tqdm(enumerate(train_dataloader)): # train model
input = data.to(opt.device)
target = label.to(opt.device) optimizer.zero_grad()
score = model(input)
loss = criterion(score,target)
loss.backward()
optimizer.step() # meters update and visualize,# 更新统计指标以及可视化
loss_meter.add(loss.item())
# detach 一下更安全保险
confusion_matrix.add(score.detach(), target.detach()) if (ii + )%opt.print_freq == :
vis.plot('loss', loss_meter.value()[]) # 进入debug模式
if os.path.exists(opt.debug_file):
import ipdb;
ipdb.set_trace() model.save() # validate and visualize,计算验证集上的指标及可视化
val_cm,val_accuracy = val(model,val_dataloader) vis.plot('val_accuracy',val_accuracy)
#loss_meter.value()返回的是loss列表的mean,std平均数和标准差,[0]则得到其平均数
vis.log("epoch:{epoch},lr:{lr},loss:{loss},train_cm:{train_cm},val_cm:{val_cm}".format(
epoch = epoch,loss = loss_meter.value()[],val_cm = str(val_cm.value()),train_cm=str(confusion_matrix.value()),lr=lr)) # update learning rate,如果损失不再下降,则降低学习率
if loss_meter.value()[] > previous_loss:
lr = lr * opt.lr_decay
# 第二种降低学习率的方法:不会有moment等信息的丢失
for param_group in optimizer.param_groups:
param_group['lr'] = lr previous_loss = loss_meter.value()[]
这里用到了PyTorchNet^5里面的一个工具: meter。meter提供了一些轻量级的工具,用于帮助用户快速统计训练过程中的一些指标。AverageValueMeter能够计算所有数的平均值和标准差,这里用来统计一个epoch中损失的平均值。confusionmeter用来统计分类问题中的分类情况,是一个比准确率更详细的统计指标。例如对于表格6-1,共有50张狗的图片,其中有35张被正确分类成了狗,还有15张被误判成猫;共有100张猫的图片,其中有91张被正确判为了猫,剩下9张被误判成狗。相比于准确率等统计信息,混淆矩阵更能体现分类的结果,尤其是在样本比例不均衡的情况下。
表6-1 混淆矩阵
| 样本 | 判为狗 | 判为猫 |
|---|---|---|
| 实际是狗 | 35 | 15 |
| 实际是猫 | 9 | 91 |
PyTorchNet从TorchNet^6迁移而来,提供了很多有用的工具,但其目前开发和文档都还不是很完善,本书不做过多的讲解。
2》验证
验证相对来说比较简单,但要注意需将模型置于验证模式(model.eval()),验证完成后还需要将其置回为训练模式(model.train()),这两句代码会影响BatchNorm和Dropout等层的运行模式。验证模型准确率的代码如下。
@t.no_grad()
def val(model,dataloader):
"""
计算模型在验证集上的准确率等信息
"""
# 把模型设为验证模式
model.eval() confusion_matrix = meter.ConfusionMeter()
for ii, (val_input, label) in tqdm(enumerate(dataloader)):
val_input = val_input.to(opt.device)
score = model(val_input)
confusion_matrix.add(score.detach().squeeze(), label.type(t.LongTensor)) # 把模型恢复为训练模式,要养成习惯,不实用验证模式后要将其调整回来
model.train() #计算准确率
cm_value = confusion_matrix.value()
accuracy = . * (cm_value[][] + cm_value[][]) / (cm_value.sum())
return confusion_matrix, accuracy
3》测试:
测试时,需要计算每个样本属于狗的概率,并将结果保存成csv文件。测试的代码与验证比较相似,但需要自己加载模型和数据。
@t.no_grad() # pytorch>=0.5
def test(**kwargs):
opt._parse(kwargs) #根据输入更改相应配置的值 # configure model,设置使用的模型,并将其设置为验证模式
model = getattr(models, opt.model)().eval()
if opt.load_model_path:
model.load(opt.load_model_path)
model.to(opt.device) # data
train_data = DogCat(opt.test_data_root,test=True)
test_dataloader = DataLoader(train_data,batch_size=opt.batch_size,shuffle=False,num_workers=opt.num_workers)
results = []
for ii,(data,path) in tqdm(enumerate(test_dataloader)):
input = data.to(opt.device)
score = model(input)
probability = t.nn.functional.softmax(score,dim=)[:,].detach().tolist()
# label = score.max(dim = )[].detach().tolist() #将批数据中图像数据的路径和其可能性结果结合在一起,得到批数据的结果
batch_results = [(path_.item(),probability_) for path_,probability_ in zip(path,probability) ] #将这一批数据结果存储在总结果中
results += batch_results
write_csv(results,opt.result_file) return results def write_csv(results,file_name): #将得到的结果写到file_name文件中,是一个.csv文件
import csv
with open(file_name,'w') as f:
writer = csv.writer(f)
writer.writerow(['id','label']) #设置行标签
writer.writerows(results) #然后将数据写入
4》帮助函数
为了方便他人使用, 程序中还应当提供一个帮助函数,用于说明函数是如何使用。程序的命令行接口中有众多参数,如果手动用字符串表示不仅复杂,而且后期修改config文件时,还需要修改对应的帮助信息,十分不便。这里使用了Python标准库中的inspect方法,可以自动获取config的源代码。help的代码如下:
def help():
"""
打印帮助的信息: python file.py help
""" print("""
usage : python file.py <function> [--args=value]
<function> := train | test | help
example:
python {} train --env='env0701' --lr=0.01
python {} test --dataset='path/to/dataset/root/'
python {} help
avaiable args:""".format(__file__)) from inspect import getsource
source = (getsource(opt.__class__))
print(source)
当用户执行python main.py help的时候,会打印如下帮助信息:
(deeplearning) userdeMacBook-Pro:dogcat- user$ python main.py help
usage : python file.py <function> [--args=value]
<function> := train | test | help
example:
python main.py train --env='env0701' --lr=0.01
python main.py test --dataset='path/to/dataset/root/'
python main.py help
avaiable args:
class DefaultConfig(object):
env = 'default' # visdom 环境
vis_port = # visdom 端口
...
9)使用
正如help函数的打印信息所述,可以通过命令行参数指定变量名.下面是三个使用例子,fire会将包含-的命令行参数自动转层下划线_,也会将非数值的值转成字符串。所以--train-data-root=data/train和--train_data_root='data/train'是等价的。
# 训练模型
python main.py train
--train-data-root=data/train/
--lr=0.005
--batch-size=
--model='ResNet34'
--max-epoch = # 测试模型
python main.py test
--test-data-root=data/test1
--load-model-path='checkpoints/resnet34_00:23:05.pth'
--batch-size=
--model='ResNet34'
--num-workers= # 打印帮助信息
python main.py help
10)本地运行:
1》训练命令为:
python main.py train --env=main --train-data-root=./data/train/ --lr=0.005 --batch-size= --model='ResNet34' --max-epoch=
指明visdom可视化工具的env为main,训练数据在文件夹./data/train/下,学习率设置为0.005,批处理大小为32,使用的模型是ResNet34,循环轮数是100次,返回的结果为:
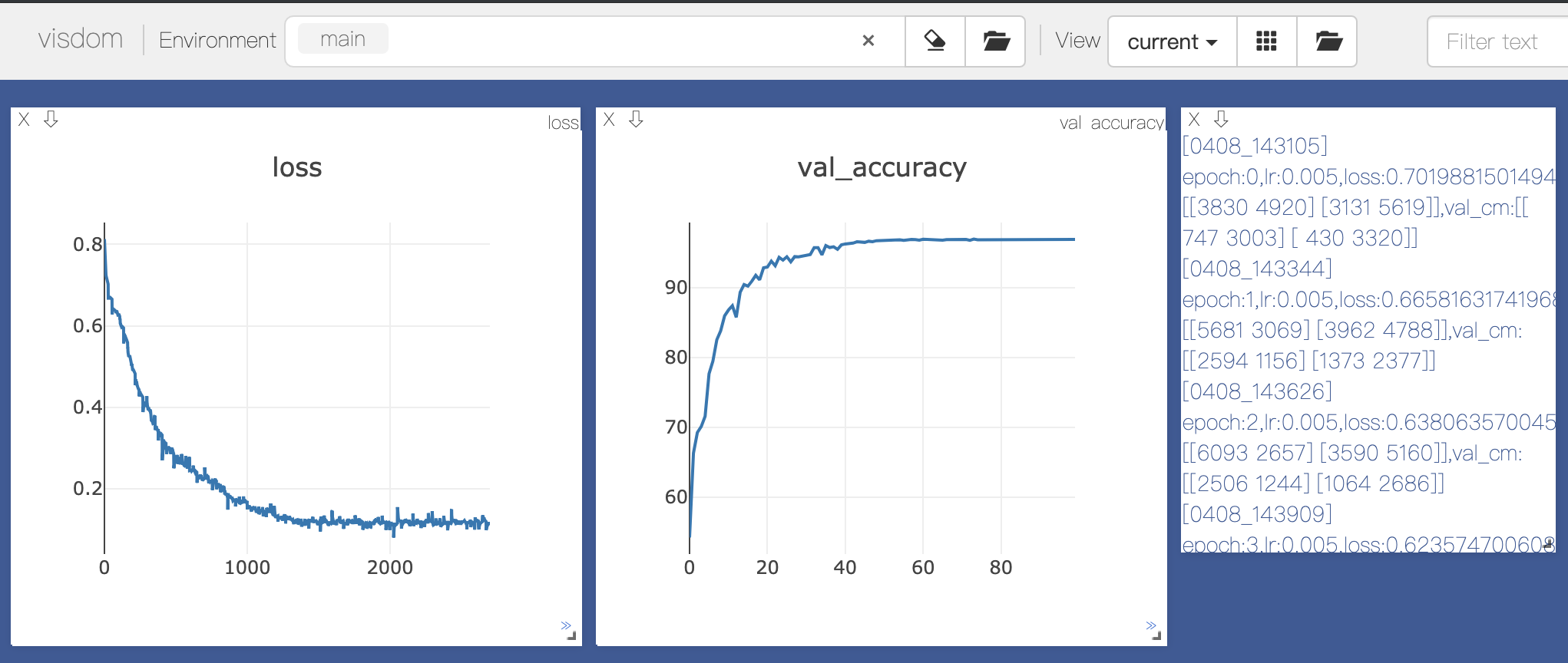
可见训练的效果不错,loss图表示损失在减少,val_accuracy图表示验证集的准确率在上升
此时checkpoint中会生成100次轮询生成的参数值,以.pth文件结尾的,可以随机选择60次轮训后训练生成的参数值来进行测试,然后查看结果看测试的效果
⚠️这里因为linux上没安装可视化工具,所以我是在Linux服务器上训练,然后从~/.visdom文件夹中将main.json下载到本地的~/.visdom文件夹中进行查看
2》测试命令为:
python main.py test --test-data-root=./data/test1 --load-model-path='checkpoints/resnet34_0408_12:02:48.pth' --batch-size= --model='ResNet34' --num-workers= --result-file=result1.csv
test-data-root指明测试集所在的文件夹,load-model-path指明使用的是那个训练后的参数,result-file说明将测试结果存储在result1.csv文件中
深度学习框架PyTorch一书的学习-第六章-实战指南的更多相关文章
- 深度学习框架PyTorch一书的学习-第五章-常用工具模块
https://github.com/chenyuntc/pytorch-book/blob/v1.0/chapter5-常用工具/chapter5.ipynb 希望大家直接到上面的网址去查看代码,下 ...
- 深度学习框架PyTorch一书的学习-第四章-神经网络工具箱nn
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 本章介绍的nn模块是构建与autogr ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-2-autograd
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 torch.autograd就是为了方 ...
- 深度学习框架PyTorch一书的学习-第一/二章
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 pytorch的设计遵循tensor- ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-1-Tensor
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 Tensor Tensor可以是一个数 ...
- 深度学习框架PyTorch一书的学习-第七章-生成对抗网络(GAN)
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter7-GAN生成动漫头像 GAN解决了非监督学习中的著名问题:给定一批样本,训 ...
- 《深度学习框架PyTorch:入门与实践》的Loss函数构建代码运行问题
在学习陈云的教程<深度学习框架PyTorch:入门与实践>的损失函数构建时代码如下: 可我运行如下代码: output = net(input) target = Variable(t.a ...
- 神工鬼斧惟肖惟妙,M1 mac系统深度学习框架Pytorch的二次元动漫动画风格迁移滤镜AnimeGANv2+Ffmpeg(图片+视频)快速实践
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_201 前段时间,业界鼎鼎有名的动漫风格转化滤镜库AnimeGAN发布了最新的v2版本,一时间街谈巷议,风头无两.提起二次元,目前国 ...
- 《深度学习框架PyTorch:入门与实践》读书笔记
https://github.com/chenyuntc/pytorch-book Chapter2 :PyTorch快速入门 + Chapter3: Tensor和Autograd + Chapte ...
随机推荐
- if判断
<!-- 查询用户信息 --> <select id="queryUser3" parameterType="org.pine.mybatis.util ...
- Spider-two
一.网络数据加密:1. md5 / sha1 不可逆加密算法: 结果是十六进制数, 结果不可逆, 多用于文件验证 import hashlib md5_obj = hashlib.md5() sha1 ...
- leaflet计算多边形面积
上一篇介绍了使用leaflet绘制圆形,那如何计算圆形的面积呢? 1.使用数学公式计算,绘制好圆形后,获取中心点以及半径即可 2.使用第三方工具计算,如turf.js. 这里turf的area方法入参 ...
- Git 常用命令及操作总结
Git常用命令及操作总结 By:授客 QQ:1033553122 利用TortoiseGit克隆源码库到本地 1.安装TortoiseGit 2.打开Git,进入到源码库,点击图示红色选框框选按钮,弹 ...
- loadrunner脚本优化-ParameterList参数类型介绍
脚本优化-Parameter List参数类型介绍 by:授客 QQ:1033553122 篇幅问题,这里采用网盘下载的方式和大家分享: 百度网盘分享: 链接: http://pan.baidu.co ...
- java读取excel文件的代码
如下内容段是关于java读取excel文件的内容,应该能对各朋友有所用途. package com.zsmj.utilit; import java.io.FileInputStream;import ...
- HtmlAgilityPack 的东西
之前都是用正则抓取页面,本人正则不咋地,有些东西用抓取来很费劲,呵呵 在网上看到别人推荐一个 HtmlAgilityPack 的东西,网上找了资料,自己写了个抓取网页的例子,框架用的ASP.NET M ...
- [20190312]关于增量检查点的疑问(补充).txt
[20190312]关于增量检查点的疑问(补充).txt --//有人问我以前写一个帖子的问题,关于增量检查点的问题,链接如下:http://blog.itpub.net/267265/viewspa ...
- 大话C#之委托
开篇先来扯下淡,上篇博客LZ在结尾说这篇博客会来说说C#中的事件.但是当LZ看完事件之后发现事件是以委托为基础来实现的,于是LZ就自作主张地在这篇博客中先来说说委托,还烦请各位看官见谅!!!另外关于委 ...
- PHP is much better than you think
Rants about PHP are everywhere, and they even come from smart guys.When Jeff Atwood wrote yet anothe ...