谱聚类算法(Spectral Clustering)优化与扩展
谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在社交网络中广泛应用。本文将讲述进一步扩展其应用场景:首先是User-Item协同聚类,即spectral coclustering,之后再详述谱聚类的进一步优化。
1 Spectral Coclustering
1.1 协同聚类(Coclustering)
在数据分析中,聚类是最常见的一种方法,对于一般的聚类算法(kmeans, spectral clustering, gmm等等),聚类结果都类似图1所示,能挖掘出数据之间的类簇规律。
 图1 聚类结果图
图1 聚类结果图
即使对于常见的数据User-Item评分矩阵(常见于各社交平台的数据之中,例如音乐网站的用户-歌曲评分矩阵,新闻网站的用户-新闻评分矩阵,电影网站的用户-电影评分矩阵等等),如表1所示。在聚类分析中,也常常将数据计算成User-User的相似度关系或Item-Item的相似度关系,计算方法诸如应用Jaccard距离,将User或Item分别当成Item或User的特征,再在此基础上计算欧氏距离、cos距离等等。
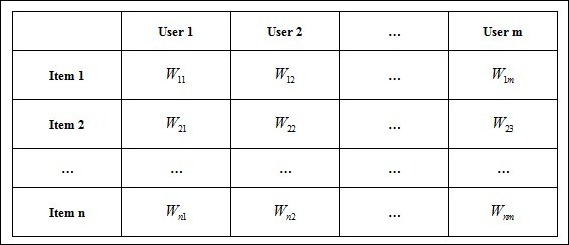
表1 User-Item评分矩阵
但是如果能聚类成如图2中的coclustering关系,将User和Item同时聚类,将使得数据结果更具意义,即在音乐网站中的用户和歌曲coclustering结果表明,某些用户大都喜欢某类歌曲,同时这类歌曲也大都只被这群用户喜欢着。这样,不管是用于何种场景(例如歌曲推荐),都将带来极大的益处。
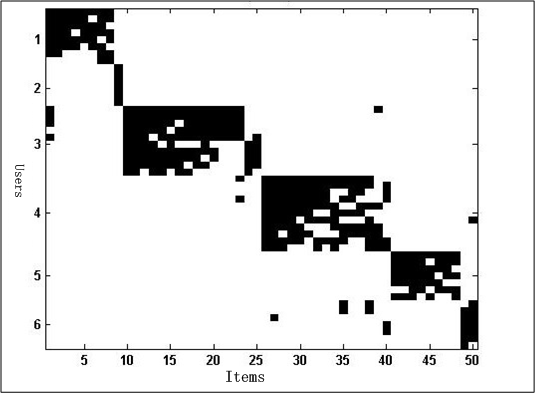 图2 coclustering图
图2 coclustering图
1.2 Spectral Coclustering
对于User-Item评分矩阵,这是一个典型的二部图(Bipartite Grap),Item-User矩阵A,假设A为N*M,即N个item和M个user,可展开成:
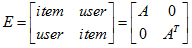 其中E为(M+N)*(M+N)的方阵,且对称。
其中E为(M+N)*(M+N)的方阵,且对称。
对于A的二部图,只存在Item与User之间的邻接边,在Item(User)之间不存在邻接边。再用谱聚类原理——将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间距离尽量距离较远。这样的聚类结果将Cut尽量少的边,分割出User和Item的类,如果类记Ci(U,I)为第i个由特定的User和Item组成的类,由谱聚类原理,Cut掉的Ci边为中的User或Item与其它类Cj(j≠i)的边,且其满足某种最优Cut方法,简单地说,Cut掉的User到其它类Cj(j≠i)的Item的边,可理解为这些User与其它Item相似关系较小;同样Cut掉的Item到其它类Cj(j≠i)的User的边,可理解为这些Item与其它User相似关系较小。这正好满足coclusering的定义。
在谱聚类的基础上,再实现Spectral Coclustering,十分简单, 将E直接当成谱聚类的邻接矩阵即可,至于求Laplacian矩阵、求特征值、计算Kmeans,完成与谱聚类相同。
PS:更多详情,请参见参考文献1。
2 谱聚类的半监督学习
假设有大量新闻需要聚类,但对于其中的部分新闻,编辑已经人工分类好了,例如(Ni1,Ni2, …, Nim),为分类好的第i类,那么对于人工分类好的数据,就相当于聚类中的先验知识(或正则)。
在聚类时,可相应在邻接矩阵E中增加类彼此间邻接边,并使得其邻接权重较大,这样生成的邻接矩阵为E’。这样,再对此邻接矩阵E’做谱聚类,聚类结果将在一定程度上维持人工分类的结果,并达到聚类的目的。
PS:更多详情,请参见参考文献2,不过谱聚类的半监督学习,都有点扯。
参考文献:
1 Inderjit S. Dhillon. Co-clustering documents and words using Bipartite Spectral Graph Partitioning;
2 W Chen. Spectral clustering: A semi-supervised approach;
3 Wen-Yen Chen, Yangqiu Song, Hongjie Bai, Chih-Jen Lin, Edward Y. Chang. Parallel Spectral Clustering in Distributed Systems.
----
谱聚类算法(Spectral Clustering)优化与扩展的更多相关文章
- 谱聚类算法(Spectral Clustering)
谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法--将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间距离尽量距离较远,以达到常见的聚类的 ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 谱聚类(Spectral clustering)(2):NCut
作者:桂. 时间:2017-04-13 21:19:41 链接:http://www.cnblogs.com/xingshansi/p/6706400.html 声明:欢迎被转载,不过记得注明出处哦 ...
- 谱聚类(Spectral clustering)分析(1)
作者:桂. 时间:2017-04-13 19:14:48 链接:http://www.cnblogs.com/xingshansi/p/6702174.html 声明:本文大部分内容来自:刘建平Pi ...
- 谱聚类(Spectral clustering)(1):RatioCut
作者:桂. 时间:2017-04-13 19:14:48 链接:http://www.cnblogs.com/xingshansi/p/6702174.html 声明:本文大部分内容来自:刘建平Pi ...
- 谱聚类(Spectral Clustring)原理
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 谱聚类算法—Matlab代码
% ========================================================================= % 算 法 名 称: Spectral Clus ...
- Standford机器学习 聚类算法(clustering)和非监督学习(unsupervised Learning)
聚类算法是一类非监督学习算法,在有监督学习中,学习的目标是要在两类样本中找出他们的分界,训练数据是给定标签的,要么属于正类要么属于负类.而非监督学习,它的目的是在一个没有标签的数据集中找出这个数据集的 ...
- 谱聚类算法及其代码(Spectral Clustering)
https://blog.csdn.net/liu1194397014/article/details/52990015 https://blog.csdn.net/u011089523/articl ...
随机推荐
- 【golang-GUI开发】Qt项目的打包发布
这是本系列的第三篇文章,前两篇我们讲了qt的安装和编译,今天我们讲一讲程序的打包. 好像我们现在都没怎么讲到qt的使用,因为想要放开手脚写代码,一些基础是要打牢的. 不过请放心,下一篇文章开始我们就会 ...
- Keras入门(二)模型的保存、读取及加载
本文将会介绍如何利用Keras来实现模型的保存.读取以及加载. 本文使用的模型为解决IRIS数据集的多分类问题而设计的深度神经网络(DNN)模型,模型的结构示意图如下: 具体的模型参数可以参考文章 ...
- c# 解密微信encryptedData字段
参考链接:https://www.cnblogs.com/jetz/p/6384809.html 我写了一个工具方法,直接照搬链接中的方法,还有一个工具类. public class Encrypt ...
- echarts X轴显示不全 有省略
代码如下: xAxis: [ { type: 'category', data: result.weekListAndYear,//result.weekList, axisLabel:{ // in ...
- 【WebSocket No.3】使用WebSocket协议来做服务器
写在开始 上面一篇写了一篇使用WebSocket做客户端,然后服务端是socke代码实现的.传送门:webSocket和Socket实现聊天群发 本来我是打算写到一章上的,毕竟实现的都是一样的功能,后 ...
- 【Java每日一题】20170216
20170215问题解析请点击今日问题下方的“[Java每日一题]20170216”查看(问题解析在公众号首发,公众号ID:weknow619) package Feb2017; public cla ...
- 搭建基于nginx-rtmp-module的流媒体服务器
1.业务流程图 2.软件下载 2.1 windows下载obs 2.2 linux 安装nginx(附加rtmp模块) 1.cd /usr/local 2.mkdir nginx 3.cd nginx ...
- 缓存MEMCACHE php调用(一)
在项目中,涉及大访问量时,合理的使用缓存能减轻数据库的压力,同时提升用户体验.即在非实时性的需求的前提下,一小段时间内(若干秒),用于显示的数据从缓存中获取的,而不用直接读取数据库,能有效的减少数据库 ...
- 查询文章的上下篇Sql语句
直接开入正题 文章内容页一般都会有上一篇和下一篇的功能: 那么查询上下篇的sql语句应该怎么写呢:示例数据表:zmd_article自增主键:id当前文章id:10 肯定有人说,这简单啊id+1和id ...
- vue从入门到进阶:过滤器filters(五)
Vue.js 允许你自定义过滤器,可被用于一些常见的文本格式化.过滤器可以用在两个地方:双花括号插值和 v-bind 表达式 (后者从 2.1.0+ 开始支持).过滤器应该被添加在 JavaScrip ...