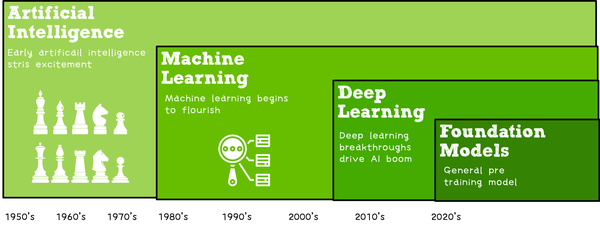
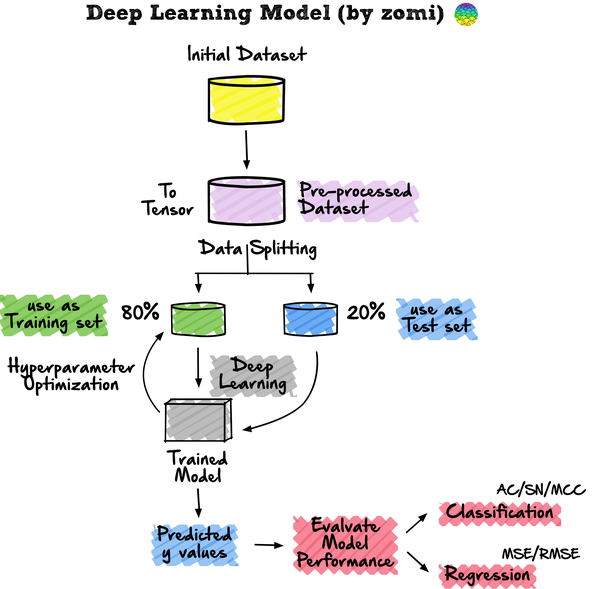
AI系统——机器学习和深度学习算法流程
- 终于考上人工智能的研究僧啦,不知道机器学习和深度学习有啥区别,感觉一切都是深度学习
- 挖槽,听说学长已经调了10个月的参数准备发有2000亿参数的T9开天霹雳模型,我要调参发T10准备拿个Best Paper

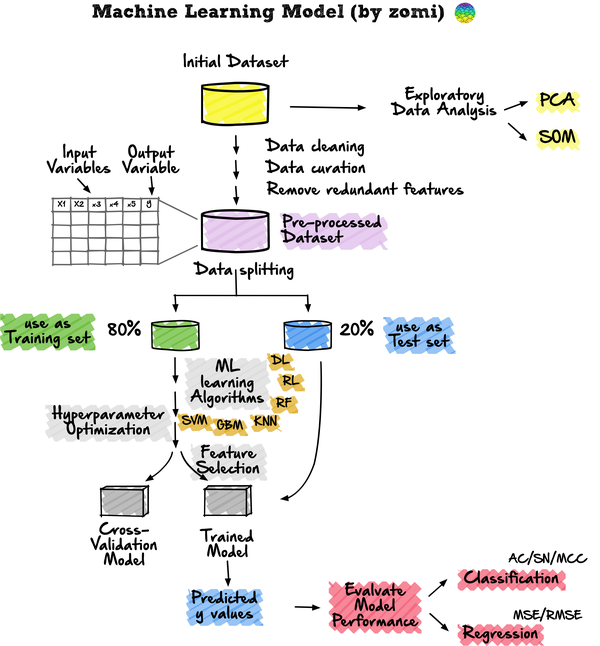
探索性数据分析方法简单来说就是去了解数据,分析数据,搞清楚数据的分布。主要注重数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。
- 描述性统计:平均数、中位数、模式、标准差。
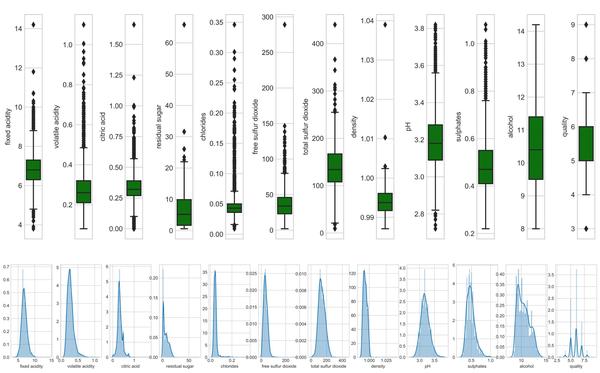
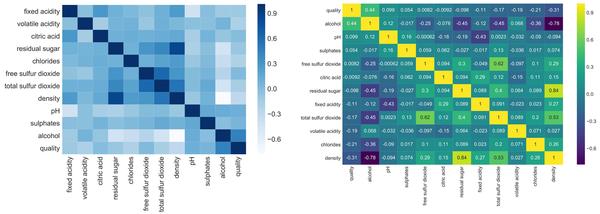
- 数据可视化:热力图(辨别特征内部相关性)、箱形图(可视化群体差异)、散点图(可视化特征之间的相关性)、主成分分析(可视化数据集中呈现的聚类分布)等。
- 数据整形:对数据进行透视、分组、过滤等。
例如对图像进行resize成统一的大小或者分辨率。
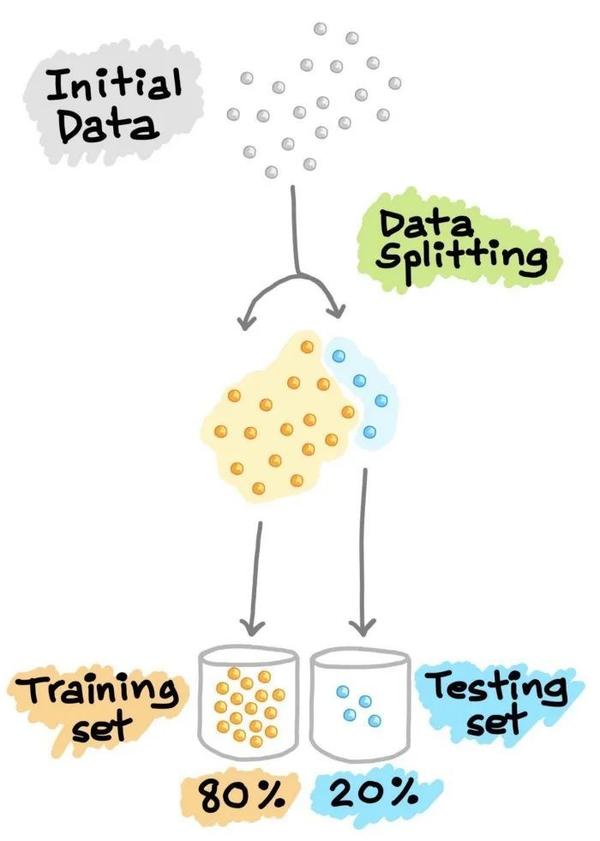
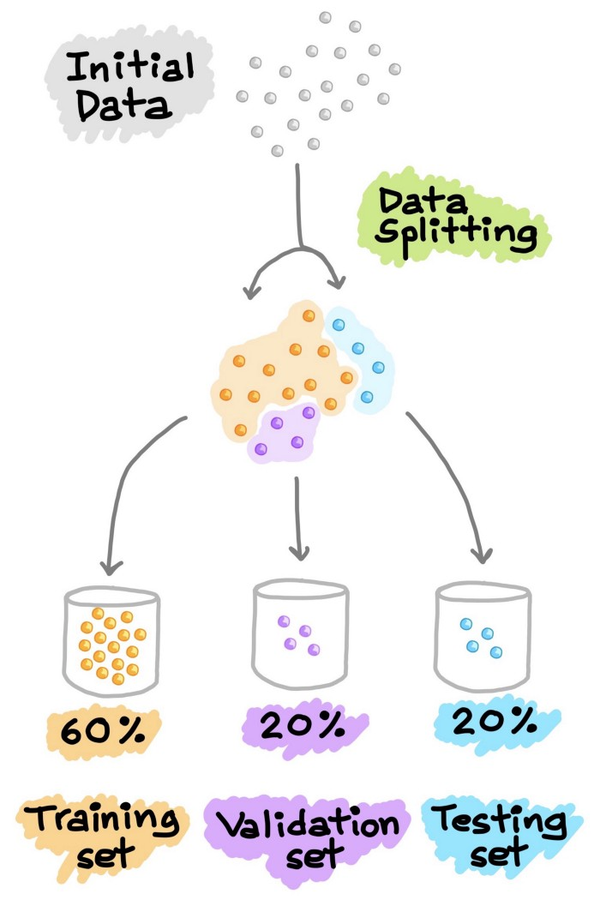
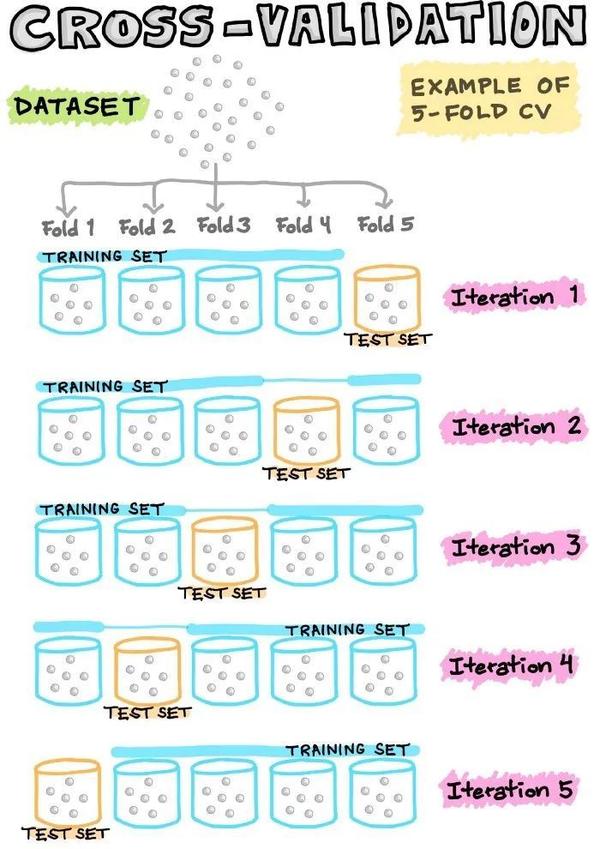
这种交叉验证的方法在机器学习流程中被广泛的使用,但是深度学习中使用得比较少哈。
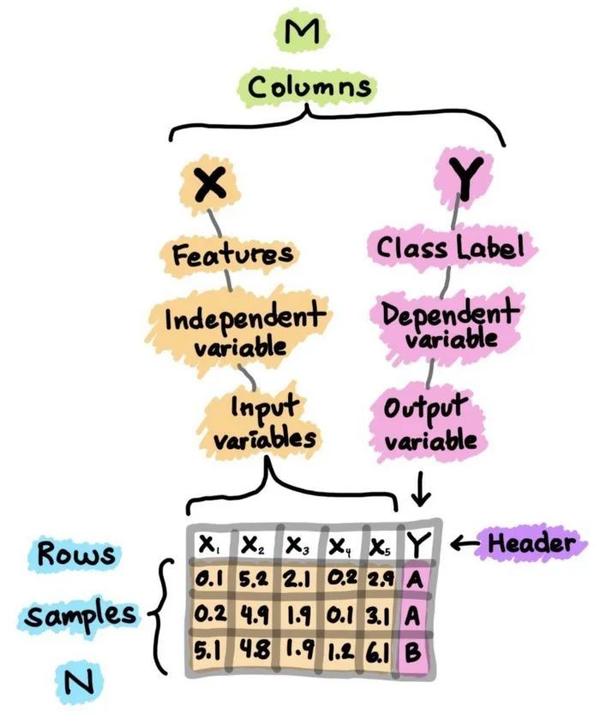
- 监督学习:是一种机器学习任务,建立输入X和输出Y变量之间的数学(映射)关系。这样的(X、Y)对构成了用于建立模型的标签数据,以便学习如何从输入中预测输出。
- 无监督学习:是一种只利用输入X变量的机器学习任务。X变量是未标记的数据,学习算法在建模时使用的是数据的固有结构。
- 强化学习:是一种决定下一步行动方案的机器学习任务,它通过试错学习(trial and error learning)来实现这一目标,努力使reward回报最大化。
以随机森林为例。在使用randomForest时,通常会对两个常见的超参数进行优化,其中包括mtry和ntree参数。mtry(maxfeatures)代表在每次分裂时作为候选变量随机采样的变量数量,而ntree(nestimators)代表要生长的树的数量。
- [1] https://github.com/dataprofessor/infographic
- [2] 陈仲铭. 《深度学习:原理与实践》.[M]
AI系统——机器学习和深度学习算法流程的更多相关文章
- 一张图看懂AI、机器学习和深度学习的区别
AI(人工智能)是未来,是科幻小说,是我们日常生活的一部分.所有论断都是正确的,只是要看你所谈到的AI到底是什么. 例如,当谷歌DeepMind开发的AlphaGo程序打败韩国职业围棋高手Lee Se ...
- AI、机器学习、深度学习、神经网络
1.AI:人工智能(Artificial Intelligence) 2.机器学习:(Machine Learning, ML) 3.深度学习:Deep Learning 人工功能的实现是让机器自己学 ...
- 认识:人工智能AI 机器学习 ML 深度学习DL
人工智能 人工智能(Artificial Intelligence),英文缩写为AI.它是研究.开发用于模拟.延伸和扩展人的智能的理论.方法.技术及应用系统的一门新的技术科学. 人工智能是对人的意识. ...
- 机器学习、深度学习以及人工智能正在快速演进(ML、DL、AI)
机器学习.深度学习以及人工智能正在快速演进 机器学习.深度学习和人工智能(ML.DL和AI)是彼此相关的概念,他们正在改变不知多少行业,改变其自身管理模式,同时改变做出决策的方式.显然,ML.DL和A ...
- [AI开发]一个例子说明机器学习和深度学习的关系
深度学习现在这么火热,大部分人都会有‘那么它与机器学习有什么关系?’这样的疑问,网上比较它们的文章也比较多,如果有机器学习相关经验,或者做过类似数据分析.挖掘之类的人看完那些文章可能很容易理解,无非就 ...
- 【AI in 美团】深度学习在OCR中的应用
AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索.推荐.广告.风控.智能调度 ...
- 近200篇机器学习&深度学习资料分享
编者按:本文收集了百来篇关于机器学习和深度学习的资料,含各种文档,视频,源码等.并且原文也会不定期的更新.望看到文章的朋友能够学到很多其它. <Brief History of Machine ...
- AI安全初探——利用深度学习检测DNS隐蔽通道
AI安全初探——利用深度学习检测DNS隐蔽通道 目录 AI安全初探——利用深度学习检测DNS隐蔽通道 1.DNS 隐蔽通道简介 2. 算法前的准备工作——数据采集 3. 利用深度学习进行DNS隐蔽通道 ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
随机推荐
- IOS 真机调试和发布相关证书
一.成员介绍1. Certification(证书)证书是对电脑开发资格的认证,每个开发者帐号有一套,分为两种:1) Developer Certification(开发证书)安装在电脑上 ...
- 任务日历关联(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 有时候吧,一件大事是由N件小事组成的,而这N件小事当中,不是每件事都可以在周末停下来的,当然也不是所有的事都必须在周末完成 ...
- 韩顺平JDBC学习笔记
第一节 JDBC概述 1.1 JDBC原理图 Java不可能具体地去操作数据库,因为数据库有许多种,直接操作数据库是一种很低效且复杂的过程. 因此,Java引入JDBC,规定一套操作数据库的接口规范, ...
- CF716A Crazy Computer 题解
Content 有一个电脑,如果过了 \(c\) 秒之后还没有任何打字符的操作,就把屏幕上面所有的字符清空.现在,给定 \(n\) 次打字符的时间 \(t_1,t_2,...,t_n\),求最后屏幕剩 ...
- TFTP协议介绍-python实现tftp客户端
1. TFTP协议介绍 TFTP(Trivial File Transfer Protocol,简单文件传输协议) 是TCP/IP协议族中的一个用来在客户端与服务器之间进行简单文件传输的协议 特点: ...
- 谷歌protobuf(protocol-buffers)各种开发语言数据类型转换说明
官方文档:https://developers.google.cn/protocol-buffers/docs/proto proto2 proto3
- SpringBoot 整合Spring Security框架
引入maven依赖 <!-- 放入spring security依赖 --> <dependency> <groupId>org.springframework.b ...
- JAVA发送POST请求携带JSON格式字符串参数
import org.apache.commons.lang.StringUtils; import org.apache.http.HttpEntity; import org.apache.htt ...
- c++之面试题(1)
题目 有十瓶药,每瓶里都装有100片药,其中有八瓶里的药每片重10克,另有两瓶里的药每片重9克.用一个蛮精确的小秤,只称一次,如何找出份量较轻的那两个药瓶? 解法 1.分别给10个药瓶按照斐波那契数列 ...
- 【LeetCode】1410. 实体解析器 HTML Entity Parser HTML
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 替换 日期 题目地址:https://leetcode ...