混部之殇-论云原生资源隔离技术之CPU隔离(一)
作者
蒋彪,腾讯云高级工程师,10+年专注于操作系统相关技术,Linux内核资深发烧友。目前负责腾讯云原生OS的研发,以及OS/虚拟化的性能优化工作。
导语
混部,通常指在离线混部(也有离在线混部之说),意指通过将在线业务(通常为延迟敏感型高优先级任务)和离线任务(通常为 CPU 消耗型低优先级任务)同时混合部署在同一个节点上,以期提升节点的资源利用率。其中的关键难点在于底层资源隔离技术,严重依赖于 OS 内核,而现有的原生 Linux kernel 提供的资源隔离能力在面对混部需求时,再次显得有些捉襟见肘(或至少说不够完美),仍需深度 Hack,方能满足生产级别的需求。
(云原生)资源隔离技术主要包括 CPU、memory、IO 和网络,4个方面。本文聚焦于 CPU 隔离技术和相关背景,后续(系列)再循序渐进,逐步展开到其他方面。
背景
无论在 IDC,还是在云场景中,资源利用率低都绝对是大部分用户/厂商面临的共同难题。一方面,硬件成本很高(大家都是靠买,而且绝大部分硬件(核心技术)掌握于别人手中,没有定价权,议价能力也通常很弱),生命周期还很短(过几年还得换新);另一方面,极度尴尬的是这么贵的东西无法充分利用,拿 CPU 占用率来说,绝大部分场景的平均占用率都很低(如果我拍不超过20%(这里指日均值,或周均值),相信大部分同学都不会有意见,这就意味着,贼贵的东西实际只用了不到五分之一,如果你还想正经的居家过日子,想必都会觉得心疼。
因此,提升主机(节点)的资源利用率是一项非常值得探索,同时收益非常明显的任务。解决思路也非常直接,
常规的思维模式:多跑点业务。说起来容易,谁没试过呢。核心困难在于:通常的业务都有明显的峰谷特征
你希望的样子可能是这样的:
但现实的样子多半是这样的:
而在为业务做容量规划是,需要按 Worst Case 做(假设所有业务的优先级都一样),具体来说,从 CPU 层面的话,就需要按 CPU 峰值(可能是周峰值、甚至月/年峰值)的来规划容量(通常还得留一定的余量,应对突发),

而现实中大部分情况是:峰值很高,但实际的均值很低。因此导致了绝大部分场景中的 CPU 均值都很低,实际 CPU 利用率很低。
前面做了个假设:“所有业务的优先级都一样”,业务的 Worst Case 决定了整机的最终表现(资源利用率低)。如果换种思路,但业务区分优先级时,就有更多的发挥空间了,可以通过牺牲低优先级业务的服务质量(通常可以容忍)来保证高优先级业务的服务质量,如此能部署在适量高优先级业务的同时,部署更多的业务(低优先级),从而整体上提升资源利用率。
混部(混合部署)因此应运而生。这里的“混”,本质上就是“区分优先级”。狭义上,可以简单的理解为“在线+离线”(在离线)混部,广义上,可以扩展到更广的应用范围:多优先级业务混合部署。
其中涉及的核心技术包括两个层面:
- 底层资源隔离技术。(通常)由操作系统(内核)提供,这是本(系列)文章的核心关注点。
- 上层的资源调度技术。(通常)由上层的资源编排/调度框架(典型如 K8s)提供,打算另做系列文章展开,仍请期待。
混部也是业界非常热门的话题和技术方向,当前主流的头部大厂都在持续投入,价值显而易见,也有较高的技术门槛(壁垒)。相关技术起源甚早,颇有渊源,大名鼎鼎的 K8s(前身 Borg)其实源于 Google 的混部场景,而从混部的历史和效果看,Google 算是行业内的标杆,号称 CPU 占用率(均值)能做到60%,具体可参考其经典论文:
https://dl.acm.org/doi/pdf/10.1145/3342195.3387517
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43438.pdf
当然,腾讯(云)在混部方向的探索也很早,也经历了几次大的技术/方案迭代,至今已有不错的落地规模和成果,详情又需起另外的话题,不在本文探讨。
技术挑战
如前面所说,混部场景中,底层资源隔离技术至关重要,其中的“资源”,整体上分为4个大类:
- CPU
- Memory
- IO
- 网络
本文聚焦于 CPU 隔离技术,主要分析在 CPU 隔离层面的技术难点、现状和方案。
CPU隔离
前面说的4类资源中,CPU 资源隔离可以说是最基础的隔离技术。一方面,CPU 是可压缩(可复用)资源,复用难度相对较低,Upstream的解决方案可用性相对较好;另一方面,CPU 资源与其他资源关联性较强,其他资源的使用(申请/释放)往往依赖于进程上下文,间接依赖于 CPU 资源。举例来说,当 CPU 被隔离(压制)后,其他如 IO、网络的请求可能(大部分情况)因为 CPU 被压制(得不到调度),从而也随之被压制。
因此,CPU 隔离的效果也会间接影响其他资源的隔离效果,CPU 隔离是最核心的隔离技术。
内核调度器
具体来说,落地到 OS 中,CPU 隔离本质上完全依赖于内核调度器实现,内核调度器是负载分配 CPU 资源的内核基本功能单元(很官方的说法),具体来说(狭义说),可以对应到我们接触最多的 Linux 内核的默认调度器:CFS 调度器(本质上是一个调度类,一套调度策略)。
内核调度器决定了何时、选取什么任务(进程)到 CPU 上执行,因此决定了混部场景中在线和离线任务的 CPU 运行时间,从而决定了 CPU 隔离效果。
Upstream kernel隔离效果
Linux 内核调度器默认提供了5个调度类,实际业务能用的基本上只有两种:
- CFS
- 实时调度器(rt/deadline)
混部场景中,CPU 隔离的本质在于需要:
- 当在线任务需要运行时,尽力压制离线任务
- 当在线任务不运行时,离线任务利用空闲CPU运行
对于“压制”,基于 Upstream kernel(基于 CFS),有如下几种思路(方案):
优先级
可以降低离线任务的优先级,或提升在线任务的优先级实现。在不修改调度类的情况下(基于默认的 CFS),可以动态调整的优先级范围为:[-20, 20)
时间片的具体表现为单个调度周期内可分得的时间片,具体来说:
- 普通优先级0与最低优先级19之间的时间片分配权重比为:1024/15,约为:68:1
- 最高优先级-20与普通优先级0之间的时间片分配权重比为:88761/1024,约为:87:1
- 最高优先级-20和最低优先级19之间的时间片分配权重比为:88761/15,约为:5917:1
看起来压制比还比较高,加入通过设置离线任务的优先级为20,在线保持默认0(通常的做法),此时在线和离线的时间片分配权重为68:1。
假设单个调度周期长度为24ms(大部分系统的默认配置),看起来(粗略估算),单个调度周期中离线能分配到的时间片约为24ms/69=348us,可占用约1/69=1.4%的CPU。
实际的运行逻辑还有点差异:CFS 考虑吞吐,设置了单次运行的最小时间粒度保护(进程单次运行的最小时间):sched_min_granularity_ns,多数情况设置为10ms,意味着离线一旦发生抢占后,可以持续运行10ms的时间,也就意味着在线任务的调度延迟(RR切换延迟)可能达10ms。
Wakeup 时也有最小时间粒度保护(Wakeup时,被抢占任务的最小运行时间保证):sched_wakeup_granularity_ns,多数情况设置为4ms。意味着离线一旦运行后,在线任务的 wakeup latency(另一种典型的调度延迟)也可能达4ms。
此外,调整优先级并不能优化抢占逻辑,具体来说,在实施抢占时(wakeup 和周期性),并不会参考优先级,并不会因为优先级不同,而实时不同的抢占策略(不会因为离线任务优先级低,而压制其抢占,减少抢占时机),因此有可能导致离线产生不必要的抢占,从而导致干扰。
Cgroup(CPU share)
Linux内核提供了 CPU Cgroup(对应于容器pod),可以通过设置 Cgroup 的 share 值来控制容器的优先级,也就是说可以通过调低离线 Cgroup 的 share 值来实现“压制"目的。对于 Cgroup v1 来说,Cgroup 的默认 share 值为1024,Cgruop v2 的默认 share(weight) 值为100(当然还可以调),如果设置离线 Cgroup 的 share/weight 值为1(最低值),那么,在CFS中,相应的时间片分配权重比分别为:1024:1和100:1,对应的CPU占用分别约为0.1%和1%。
实际运行逻辑仍然受限于 sched_min_granularity_ns 和 sched_wakeup_granularity_ns。逻辑跟优先级场景类似。
与优先级方案类似,抢占逻辑未根据 share 值优化,可能存在额外的干扰。
特殊 policy
CFS中还提供了一个特殊的调度 policy:SCHED_IDLE,专用于运行优先级极低的任务,看起来是专为”离线任务“设计的。SCHED_IDLE 类任务本质上是有一个权重为3的 CFS 任务,其与普通任务的时间片分配权重比为:1024:3,约为334:1,此时离线任务的 CPU 占用率约为0.3%。时间片分配如:

实际运行逻辑仍然受限于 sched_min_granularity_ns 和 sched_wakeup_granularity_ns。逻辑跟优先级场景类似。
CFS 中对于 SCHED_IDLE 任务做了特殊的抢占逻辑优化(压制 SCHED_IDLE 任务对其他任务的抢占,减少抢占时机),因此,从这个角度看,SCHED_IDLE 为”适配“(虽然 Upstream 本意并非如此)混部场景迈进了一小步。
此外,由于 SCHED_IDLE 是 per-task 的标记,并无 Cgroup 级别的 SCHED_IDLE 标记能力,而 CFS 调度时,需要先选 (task)group,然后再从 group 中选 task ,因此对于云原生场景(容器)混部来说,单纯使用 SCHED_IDLE 并不能发挥实际作用。
整体看,虽然 CFS 提供了优先级(share/SCHED_IDLE 原理上类似,本质都是优先级),并可根据优先级对低优先级任务进行一定程度的压制,但是,CFS 的核心设计在于”公平“,本质上无法做到对离线的”绝对压制“,即使设置”优先级“(权重)最低,离线任务仍能获得固定的时间片,而获得的时间片不是空闲的 CPU 时间片,而是从在线任务的时间片中抢到的。也就是说,CFS 的”公平设计“,决定了无法完全避免离线任务对在线的干扰,无法达到完美的隔离效果。
除此之外,通过(极限)降低离线任务的优先级(上述几种方案本质都是如此)的方式,本质上,还压缩了离线任务的优先级空间,换句话说,如果还想进一步在离线任务之间区分优先级(离线任务之间也可能有 QoS 区分,实际可能有这样的需求),那就无能为力了。
另,从底层实现的角度看,由于在线和离线均使用 CFS 调度类,实际运行时,在线和离线共用运行队列(rq),叠加计算 load,共用 load balance 机制,一方面,离线在做共用资源(比如运行队列)操作时需要做同步操作(加锁),而锁原语本身是不区分优先级的,不能排除离线干扰;另一方面,load balance 时也无法区分离线任务,对其做特殊处理(比如激进 balance 防止饥饿、提升 CPU 利用率等),对于离线任务的 balance 效果无法控制。
实时优先级
此时,你可能会想,如果需要绝对抢占(压制离线),为何不用实时调度类(RT/deadline)呢?实时调度类相比于 CFS,刚好达到”绝对压制“的效果。
确实如此。但是,这种思路下,只能将在线业务设置为实时,离线任务保持为 CFS,如此,在线能绝对抢占离线,同时如果担心离线被饿死的话,还有 rt_throttle 机制来保证离线不被饿死。
看起来”完美“,其实不然。这种做法的本质,会压缩在线任务的优先级空间和生存空间(与之前调低离线任务优先级的结果相反),结果是在线业务只能用实时调度类(尽管大部分在线业务并不满足实时类型的特征),再无法利用 CFS 的原生能力(比如公平调度、Cgroup 等,而这恰恰是在线任务的刚需)。
简单来看,问题在于:实时类型并不能满足在线任务自身运行的需要,本质上看在线业务自身并不是实时任务,如此强扭为实时后,会有比较严重的副作用,比如系统任务(OS 自带的任务,比如各种内核线程和系统服务)会出现饥饿等。
总结一下,对于实时优先级的方案:
- 认可实时类型对于 CFS 类型的”绝对压制“能力(这正是我们想要的)
- 但当前 Upstream kernel 实现中,只能将在线任务设置为比 CFS 优先级更高的实时类型,这是实际应用场景中无法接受的。
优先级反转
说到这,你心里可能还有一个巨大的问号:”绝对压制“后,会有优先级反转问题吧?怎么办?
答案是:的确存在优先级反转问题
解释下这种场景下的优先级反转的逻辑:如果在线任务和离线任务之间有共享资源(比如内核中的一些公共数据,如 /proc 文件系统之类),当离线任务因访问共享资源而拿到锁(抽象一下,不一定是锁)后,如果被”绝对压制“,一直无法运行,当在线任务也需要访问该共享资源,而等待相应的锁时,优先级反转出现,导致死锁(长时间阻塞也可能)。优先级反转是调度模型中需要考虑的一个经典问题。
粗略总结下优先级反转发生的条件:
- 在离线存在共享资源。
- 存在共享资源的并发访问,且使用了睡眠锁保护。
- 离线拿到锁后,被完全绝对压制,没有运行的机会。这句话可以这样理解:所有的 CPU 都被在线任务100%占用,导致离线没有任何运行机会。(理论上,只要有空闲 CPU,离线任务就可能通过 load balance 机制利用上)
在云原生混部场景中,对于优先级反转问题的处理方法(思路),取决于看待该问题的角度,我们从如下几个不同的角度来看,
- 优先级反转发生可能性有多大?这取决于实际的应用场景,理论上如果在线业务和离线业务之间不存在共享资源,其实就不会发生优先级反转。在云原生的场景中,大体上分两种情况:
(1)安全容器场景。此场景中,业务实际运行于”虚拟机“(抽象理解)中,而虚拟机自身保证了绝大部分资源的隔离性,这种场景中,基本可以避免发生优先级反转(如果确实存在,可以特事特办,单独处理)
(2)普通容器场景。此场景中,业务运行于容器中,存在一些共享资源,比如内核的公共资源,共享文件系统等。如前面分析,在存在共享资源的前提下,出现优先级反转的条件还是比较严苛的,其中最关键的条件是:所有 CPU 都被在线任务100%占用,这种情况在现实的场景中,是非常少见的,算是非常极端的场景,现实中可以单独处理这样的”极端场景“
因此,在(绝大部分)真实云原生场景中,我们可以认为,在调度器优化/hack 足够好的前提下,可以规避。
- 优先级反转如何处理?虽然优先级反转仅在极端场景出现,但如果一定要处理的话(Upstream 一定会考虑),该怎么处理?
(1)Upstream 的想法。原生 Linux kernel 的 CFS 实现中,为最低优先级(可以认为是 SCHED_IDLE )也保留了一定的权重,也就意味着,最低优先级任务也能得到一定的时间片,因此可以(基本)避免优先级反转问题。这也是社区一直的态度:通用,即使是极度极端的场景,也需要完美cover。这样的设计也恰恰是不能实现”绝对压制“的原因。从设计的角度看,这样的设计并无不妥,但对于云原生混部场景来说,这样的设计并不完美:并不感知离线的饥饿程度,也就是说,在离线并不饥饿的情况下,也可能对在线抢占,导致不必要的干扰。
(2)另一种想法。针对云原生场景的优化设计:感知离线的饥饿和出现优先级反转的可能性,但离线出现饥饿并可能导致优先级反转时(也就是迫不得已时),才进行抢占。如此一方面能避免不一样的抢占(干扰),同时还能避免优先级反转问题。达到(相对)完美的效果。当然,不得不承认,这样的设计不那么 Generic,不那么 Graceful,因此 Upstream 也基本不太可能接受。
超线程干扰
至此,还漏了另一个关键问题:超线程干扰。这也是混部场景的顽疾,业界也一直没有针对性的解决方案。
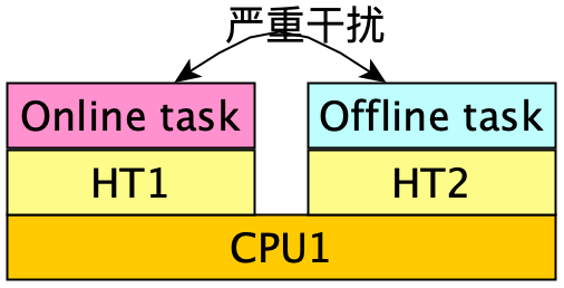
具体的问题是,由于同一个物理 CPU 上的超线程共享核心的硬件资源,比如 Cache 和计算单元。当在线任务和离线任务同时运行在一对超线程上时,相互之间会因为硬件资源争抢,而出现相互干扰的情况。而 CFS 在设计时也完全没有考虑这个问题
导致结果是,在混部场景中,在线业务的性能受损。实际测试使用 CPU 密集型 benchmark,因超线程导致的性能干扰可达40%+。
注:Intel 官方的数据:物理 core 性能差不多只能1.2倍左右的单核性能。
超线程干扰问题是混部场景中的关键问题,而 CFS 在最初设计时是(几乎)完全没有考虑过的,不能说是设计缺失,只能说是 CFS 并不是为混部场景而设计的,而是为更通用的、更宏观的场景而生。
Core scheduling
说到这,专业(搞内核调度)的同学可能又会冒出一个疑问:难道没听说过 Core scheduling 么,不能解决超线程干扰问题么?
听到这,不得不说这位同学确实很专业,Core Scheduling 是内核调度器模块 Maintainer Perter 在2019年提交的一个新 feature(基于更早之前的社区中曾提出的 coscheduling 概念),主要的目标在于解决(应该是 mitigation 或者是 workaround) L1TF 漏洞(由于超线程之间共享 cache 导致数据泄露),主要应用场景为:云主机场景中,避免不同的虚拟机进程运行于同一对超线程上,导致数据泄露。
其核心思想是:避免不同标记的进程运行于同一对超线程上。
现状是:Core scheduling patchset 在经过长达v10的版本的迭代,近2年的讨论和 improve/rework 之后,终于,就在最近(2021.4.22),Perter 发出了看似可能进入(何时能进入还不好说) master 的版本(还不太完整):
https://lkml.org/lkml/2021/4/22/501
关于这个话题,值得一个单独的深入的分享,不在这里展开。也请期待...
这里直接抛(个人)观点(轻拍):
- Core scheduling 确实能用来解决超线程干扰问题。
- Core scheduling 设计初衷是解决安全漏洞(L1TF),并非为混部超线程干扰而设计。由于需要保障安全,需要实现绝对隔离,需要复杂(开销大)的同步原语(比如 core 级别的 rq lock),重量级的 feature 实现,如 core 范围的 pick task,过重的 force idle。另外,还有配套的中断上下文的并发隔离等。
- Core scheduling 的设计和实现太重、开销太大,开启后性能 regression 严重,并不能区分在线和离线。不太适合(云原生)混部场景。
本质还是:Core scheduling 亦非为云原生混部场景而设计。
结论
综合前面的分析,可以抽象的总结下当前现有的各种方案的优点和问题。
基于 CFS 中的优先级(share/SCHED_IDLE 类似)方案,优点:
- 通用。能力强,能全面hold住大部分的应用场景
- 能(基本)避免优先级反转问题
问题:
- 隔离效果不完美(没有绝对压制效果)
- 其他各种小毛病(不完美)
基于实时任务类型的方案,优点:
- 绝对压制,隔离效果完美
- 有机制避免优先级反转(rt_throttle)
问题:
- 不适用。在线任务不能(大部分情况)用实时任务类型。
- 有机制(rt_throttle)避免优先级反转,但开启后,隔离效果就不完美了。
基于 Core scheduling 解决超线程干扰隔离,优点:
- 完美超线程干扰隔离效果
问题:
- 设计太重,开销太大
结语
Upstream Linux kernel 为考虑通用性,设计的优雅,难以满足特定场景(云原生混部)中的极致需求,若想追求卓越和极致,还需要深度 Hack,而 TencentOS Server 一直在路上。(听着耳熟?确实以前也这么说过!
关于 Linux kernel 的内核调度器的具体实现和代码分析(基于5.4内核(Tkernel4)),我们后续会陆续推出相应的解析系列文章,在探讨云原生场景的痛点的同时,结合相应的代码分析,以期降低 Linux 内核神秘感,探讨更广阔的 Hack 空间。敬请期待。
思考
如果想要让在线业务使用 CFS (利用 CFS 的强大能力),同时又想具备”绝对压制“的能力,理想的做法应该怎么办?(感觉答案就要呼之欲出了!
如果不需要完美隔离效果(绝对压制),同时需要处理优先级反转,还需要”接近完美“的隔离效果,还想尽量利用现有机制(不想太大的调度器 Hack,风险更小),那又该怎么办?(仔细看看前面的各种现有方案的分析总结,感觉也快接近答案了)
混部之殇-论云原生资源隔离技术之CPU隔离(一)的更多相关文章
- 灵雀云CTO陈恺:从“鸿沟理论”看云原生,哪些技术能够跨越鸿沟?
灵雀云CTO陈恺:从“鸿沟理论”看云原生,哪些技术能够跨越鸿沟? 历史进入2019年,放眼望去,今天的整个技术大环境和生态都发生了很大的变化.在己亥猪年春节刚刚过去的早春时节,我们来梳理和展望一下整个 ...
- 【转载】Linux cgroup资源隔离各个击破之 - cpu隔离1
Linux cgroup 有两个子系统支持CPU隔离.一个是cpu子系统,另一个是cpuset子系统. cpu子系统根据进程设置的调度属性,选择对应的CPU资源调度方法 .1. 完全公平调度 Comp ...
- 腾讯TencentOS 十年云原生的迭代演进之路
导语 TencentOS Server (又名 Tencent Linux 简称 Tlinux) 是腾讯针对云的场景研发的 Linux 操作系统,提供了专门的功能特性和性能优化,为云服务器实例中的应用 ...
- 使用 Iceberg on Kubernetes 打造新一代云原生数据湖
背景 大数据发展至今,按照 Google 2003年发布的<The Google File System>第一篇论文算起,已走过17个年头.可惜的是 Google 当时并没有开源其技术,& ...
- 腾讯云联合中国信通院&作业帮等首发《降本之源-云原生成本管理白皮书》
在11月4日举办的2021腾讯数字生态大会云原生专场上,腾讯云联合中国信通院.作业帮等率先在国内重磅发布了<降本之源-云原生成本管理白皮书>(简称白皮书),基于腾讯云在业内最大规模的 Ku ...
- 给 K8s API “做减法”:阿里巴巴云原生应用管理的挑战和实践
作者 | 孙健波(天元) 阿里巴巴技术专家本文整理自 11 月 21 日社群分享,每月 2 场高质量分享,点击加入社群. 早在 2011 年,阿里巴巴内部便开始了应用容器化,当时最开始是基于 LXC ...
- 云原生生态周报 Vol. 19 | Helm 推荐用户转向 V3
作者| 禅鸣.忠源.天元.进超.元毅 业界要闻 Helm 官方推荐用户迁移到 V3 版本 Helm 官方发布博客,指导用户从 v2 迁移到 v3,这标志着官方开始正式推进 helm 从 v2 转向 v ...
- 进击的 Java ,云原生时代的蜕变
作者| 易立 阿里云资深技术专家 导读:云原生时代的来临,与Java 开发者到底有什么联系?有人说,云原生压根不是为了 Java 存在的.然而,本文的作者却认为云原生时代,Java 依然可以胜任&qu ...
- CNCF 宣布成立应用交付领域小组,正式开启云原生应用时代
作者|赵钰莹 作为云原生领域的顶级开源社区, Cloud Native Computing Foundation (云原生基金会,以下简称 CNCF)近日宣布成立 Application Delive ...
随机推荐
- python基础学习之集合set
.集合:set 特点:无序,不可重复(自动去重),可更改,可以与元组.列表互相转换 格式:s = {'x','y','z'} 转换:(转回用set) s = {'x','y','z'} ...
- BIMFACE二次开发SDK 开源C#版
[ BIMFace.SDK.CSharp ] 是基于微软.NET 技术封装的用于 BIMFACE 二次开发的通用类库.其中封装了BIMFace服务端API,包含基础API.文件上传API.文件转换AP ...
- JWT加密解密方法
public static string Key { get; set; } = "123456789987654321";//解密串 /// <summary> // ...
- Anchor-Free总结
目录 Anchor-Free综述 一. CornerNet 1.1 概述 1.2 模块介绍 1.2.1 Heatmap 1.2.2 Offset 1.2.3 Grouping Corners 1.2. ...
- 6、Spring教程之自动装配
自动装配说明 自动装配是使用spring满足bean依赖的一种方法 spring会在应用上下文中为某个bean寻找其依赖的bean. Spring中bean有三种装配机制,分别是: 在xml中显式配置 ...
- lms框架即将发布第一个版本了
lms微服务框架介绍 LMS框架旨在帮助开发者在.net平台下,通过简单的配置和代码即可快速的使用微服务进行开发. LMS通过.net框架的主机托管应用,内部通过dotnetty/SpanNetty实 ...
- 新动能 · 新机遇:SaaS软件提供商 Zoho 25 周年战略再升级
25年,在历史的长河中不过转眼一瞬:但是对于创造者来说,25年足以颠覆一个时代...... 作为世界级云应用服务商,Zoho已经走过了25年的砥砺岁月.从ManageEngine到Zoho云服务,从工 ...
- Jenkins-k8s-helm-eureka-harbor-githab-mysql-nfs微服务发布平台实战
基于 K8S 构建 Jenkins 微服务发布平台 实现汇总: 发布流程设计讲解 准备基础环境 K8s环境(部署Ingress Controller,CoreDNS,Calico/Flannel) 部 ...
- vue-router 监控全局路由,在路由中改变vuex中的状态值
- Recoil 默认值及数据级联的使用
Recoil 中默认值及数据间的依赖 通过 Atom 可方便地设置数据的默认值, const fontSizeState = atom({ key: 'fontSizeState', default: ...