GO学习-(33) Go实现日志收集系统2
Go实现日志收集系统2
一篇文章主要是关于整体架构以及用到的软件的一些介绍,这一篇文章是对各个软件的使用介绍,当然这里主要是关于架构中我们agent的实现用到的内容
关于zookeeper+kafka
我们需要先把两者启动,先启动zookeeper,再启动kafka
启动ZooKeeper:./bin/zkServer.sh start
启动kafka:./bin/kafka-server-start.sh ./config/server.properties
操作kafka需要安装一个包:go get github.com/Shopify/sarama
写一个简单的代码,通过go调用往kafka里扔数据:
package main import (
"github.com/Shopify/sarama"
"fmt"
) func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
msg := &sarama.ProducerMessage{}
msg.Topic = "nginx_log"
msg.Value = sarama.StringEncoder("this is a good test,my message is zhaofan")
client,err := sarama.NewSyncProducer([]string{"192.168.0.118:9092"},config)
if err != nil{
fmt.Println("producer close err:",err)
return
}
defer client.Close() pid,offset,err := client.SendMessage(msg)
if err != nil{
fmt.Println("send message failed,",err)
return
}
fmt.Printf("pid:%v offset:%v\n",pid,offset)
}
config.Producer.RequiredAcks = sarama.WaitForAll 这里表示是在给kafka扔数据的时候是否需要确认收到kafka的ack消息
msg.Topic = "nginx_log" 因为kafka是一个分布式系统,假如我们要读的是nginx日志,apache日志,我们可以根据topic做区分,同时也是我们也可以有不同的分区
我们将上述代码执行一下,就会往kafka中扔一条消息,可以通过kakfa中自带的消费者命令查看:
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic nginx_log --from-beginning

我们可以将最后的代码稍微更改一下,更改为循环发送:
for{
pid,offset,err := client.SendMessage(msg)
if err != nil{
fmt.Println("send message failed,",err)
return
}
fmt.Printf("pid:%v offset:%v\n",pid,offset)
time.Sleep(2*time.Second)
}
这样当我们再次执行的程序的时候,我们可以看到客户端在不停的消费到数据:
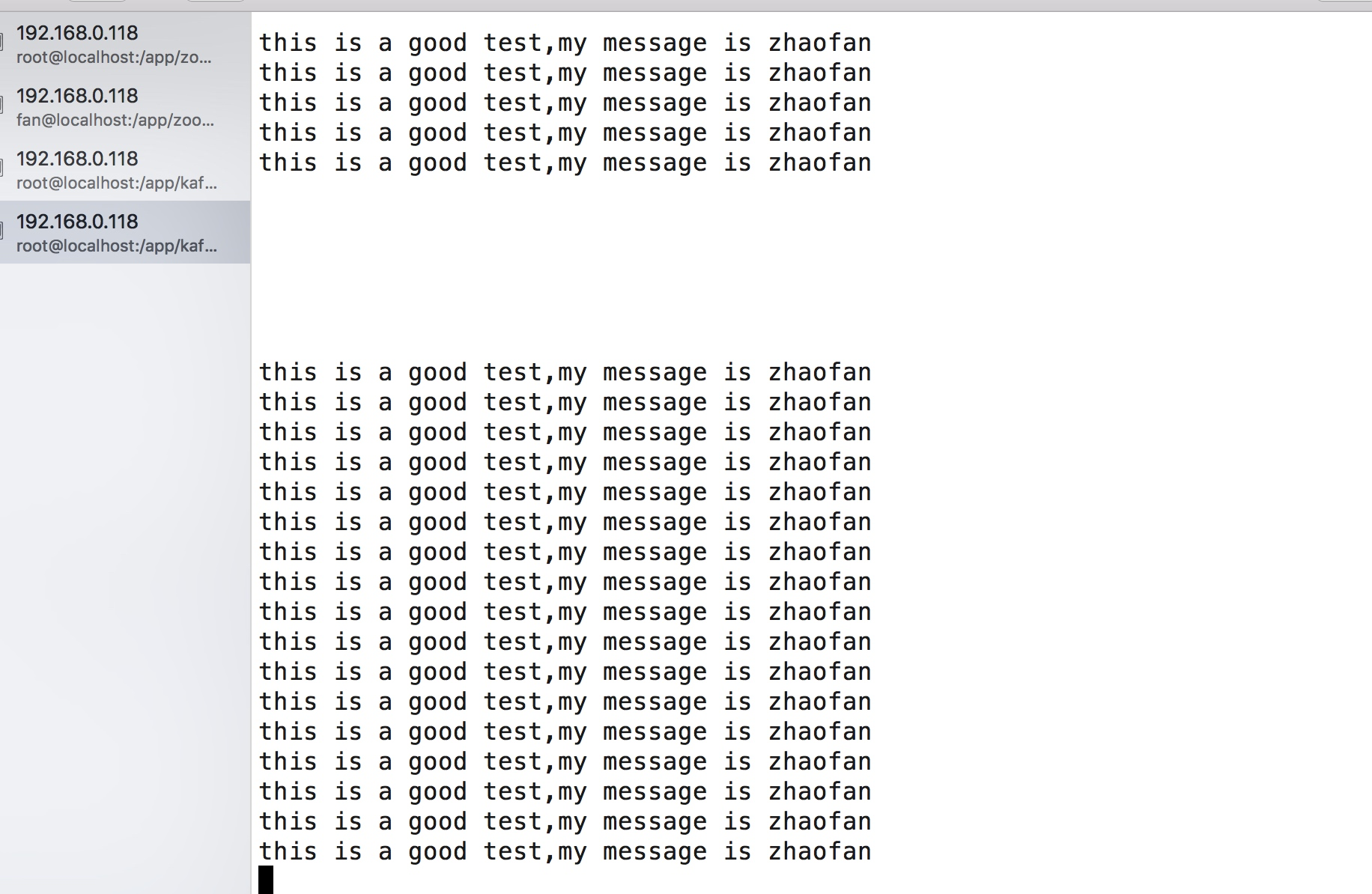
这样我们就实现一个kakfa的生产者的简单的demo
接下来我们还需要知道一个工具的使用tailf
tailf
我们的agent需要读日志目录下的日志文件,而日志文件是不停的增加并且切换文件的,所以我们就需要借助于tailf这个包来读文件,当然这里的tailf和linux里的tail -f命令虽然不同,但是效果是差不多的,都是为了获取日志文件新增加的内容。
而我们的客户端非常重要的一个地方就是要读日志文件并且将读到的日志文件推送到kafka
这里需要我们下载一个包:go get github.com/hpcloud/tail
我们通过下面一个例子对这个包进行一个基本的使用,更详细的api说明看:https://godoc.org/github.com/hpcloud/tail
package main import (
"github.com/hpcloud/tail"
"fmt"
"time"
) func main() {
filename := "/my.log"
tails,err := tail.TailFile(filename,tail.Config{
ReOpen:true,
Follow:true,
Location:&tail.SeekInfo{Offset:0,Whence:2},
MustExist:false,
Poll:true,
}) if err !=nil{
fmt.Println("tail file err:",err)
return
} var msg *tail.Line
var ok bool
for true{
msg,ok = <-tails.Lines
if !ok{
fmt.Printf("tail file close reopen,filenam:%s\n",tails,filename)
time.Sleep(100*time.Millisecond)
continue
}
fmt.Println("msg:",msg.Text)
}
}
最终实现的效果是当你文件里面添加内容后,就可以不断的读取文件中的内容
日志库的使用
这里是通过beego的日志库实现的,beego的日志库是可以单独拿出来用的,还是非常方便的,使用例子如下:
package main import (
"github.com/astaxie/beego/logs"
"encoding/json"
"fmt"
) func main() {
config := make(map[string]interface{})
config["filename"] = "/log/logcollect.log"
config["level"] = logs.LevelTrace
configStr,err := json.Marshal(config)
if err != nil{
fmt.Println("marshal failed,err:",err)
return
}
logs.SetLogger(logs.AdapterFile,string(configStr))
logs.Debug("this is a debug,my name is %s","stu01")
logs.Info("this is a info,my name is %s","stu02")
logs.Trace("this is trace my name is %s","stu03")
logs.Warn("this is a warn my name is %s","stu04")
}
简单版本logagent的实现
这里主要是先实现核心的功能,后续再做优化和改进,主要实现能够根据配置文件中配置的日志路径去读取日志并将读取的实时推送到kafka消息队列中
关于logagent的主要结构如下:
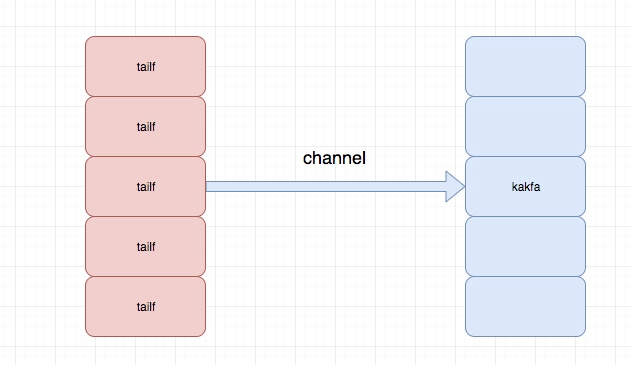
程序目录结构为:
├── conf
│ └── app.conf
├── config.go
├── kafka.go
├── logs
│ └── logcollect.log
├── main.go
└── server.go
app.conf :配置文件
config.go:用于初始化读取配置文件中的内容,这里的配置文件加载是通过之前自己实现的配置文件热加载包处理的,博客地址:http://www.cnblogs.com/zhaof/p/8593204.html
logcollect.log:日志文件
kafka.go:对kafka的操作,包括初始化kafka连接,以及给kafka发送消息
server.go:主要是tail 的相关操作,用于去读日志文件并将内容放到channel中
所以这里我们主要的代码逻辑或者重要的代码逻辑就是kafka.go 以及server.go
kafka.go代码内容为:
// 这里主要是kafak的相关操作,包括了kafka的初始化,以及发送消息的操作
package main import (
"github.com/Shopify/sarama"
"github.com/astaxie/beego/logs"
) var (
client sarama.SyncProducer
kafkaSender *KafkaSender
) type KafkaSender struct {
client sarama.SyncProducer
lineChan chan string
} // 初始化kafka
func NewKafkaSender(kafkaAddr string)(kafka *KafkaSender,err error){
kafka = &KafkaSender{
lineChan:make(chan string,100000),
}
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true client,err := sarama.NewSyncProducer([]string{kafkaAddr},config)
if err != nil{
logs.Error("init kafka client failed,err:%v\n",err)
return
}
kafka.client = client
for i:=0;i<appConfig.KafkaThreadNum;i++{
// 根据配置文件循环开启线程去发消息到kafka
go kafka.sendToKafka()
}
return
} func initKafka()(err error){
kafkaSender,err = NewKafkaSender(appConfig.kafkaAddr)
return
} func (k *KafkaSender) sendToKafka(){
//从channel中读取日志内容放到kafka消息队列中
for v := range k.lineChan{
msg := &sarama.ProducerMessage{}
msg.Topic = "nginx_log"
msg.Value = sarama.StringEncoder(v)
_,_,err := k.client.SendMessage(msg)
if err != nil{
logs.Error("send message to kafka failed,err:%v",err)
}
}
} func (k *KafkaSender) addMessage(line string)(err error){
//我们通过tailf读取的日志文件内容先放到channel里面
k.lineChan <- line
return
}
server.go的代码为:
package main import (
"github.com/hpcloud/tail"
"fmt"
"sync"
"github.com/astaxie/beego/logs"
"strings"
) type TailMgr struct {
//因为我们的agent可能是读取多个日志文件,这里通过存储为一个map
tailObjMap map[string]*TailObj
lock sync.Mutex
} type TailObj struct {
//这里是每个读取日志文件的对象
tail *tail.Tail
offset int64 //记录当前位置
filename string
} var tailMgr *TailMgr
var waitGroup sync.WaitGroup func NewTailMgr()(*TailMgr){
tailMgr = &TailMgr{
tailObjMap:make(map[string]*TailObj,16),
}
return tailMgr
} func (t *TailMgr) AddLogFile(filename string)(err error){
t.lock.Lock()
defer t.lock.Unlock()
_,ok := t.tailObjMap[filename]
if ok{
err = fmt.Errorf("duplicate filename:%s\n",filename)
return
}
tail,err := tail.TailFile(filename,tail.Config{
ReOpen:true,
Follow:true,
Location:&tail.SeekInfo{Offset:0,Whence:2},
MustExist:false,
Poll:true,
}) tailobj := &TailObj{
filename:filename,
offset:0,
tail:tail,
}
t.tailObjMap[filename] = tailobj
return
} func (t *TailMgr) Process(){
//开启线程去读日志文件
for _, tailObj := range t.tailObjMap{
waitGroup.Add(1)
go tailObj.readLog()
}
} func (t *TailObj) readLog(){
//读取每行日志内容
for line := range t.tail.Lines{
if line.Err != nil {
logs.Error("read line failed,err:%v",line.Err)
continue
}
str := strings.TrimSpace(line.Text)
if len(str)==0 || str[0] == '\n'{
continue
} kafkaSender.addMessage(line.Text)
}
waitGroup.Done()
} func RunServer(){
tailMgr = NewTailMgr()
// 这一部分是要调用tailf读日志文件推送到kafka中
for _, filename := range appConfig.LogFiles{
err := tailMgr.AddLogFile(filename)
if err != nil{
logs.Error("add log file failed,err:%v",err)
continue
} }
tailMgr.Process()
waitGroup.Wait()
}
可以整体演示一下代码实现的效果,当我们运行程序之后我配置文件配置的目录为:
log_files=/app/log/a.log,/Users/zhaofan/a.log
我通过一个简单的代码对对a.log循环追加内容,你可以从kafka的客户端消费力看到内容了:
GO学习-(33) Go实现日志收集系统2的更多相关文章
- GO学习-(35) Go实现日志收集系统4
Go实现日志收集系统4 到这一步,我的收集系统就已经完成很大一部分工作,我们重新看一下我们之前画的图: 我们已经完成前面的部分,剩下是要完成后半部分,将kafka中的数据扔到ElasticSear ...
- GO学习-(34) Go实现日志收集系统3
Go实现日志收集系统3 再次整理了一下这个日志收集系统的框,如下图 这次要实现的代码的整体逻辑为: 完整代码地址为: etcd介绍 高可用的分布式key-value存储,可以用于配置共享和服务发现 ...
- GO学习-(32) Go实现日志收集系统1
Go实现日志收集系统1 项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机 ...
- Go语言学习之11 日志收集系统kafka库实战
本节主要内容: 1. 日志收集系统设计2. 日志客户端开发 1. 项目背景 a. 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 b. 当系统机器比较少时,登陆到服务器上查看即可 ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- 容器云平台No.9~kubernetes日志收集系统EFK
EFK介绍 EFK,全称Elasticsearch Fluentd Kibana ,是kubernetes中比较常用的日志收集方案,也是官方比较推荐的方案. 通过EFK,可以把集群的所有日志收集到El ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
随机推荐
- 原创:纯CSS美化单复选框(checkbox、radio)
最重要的一点,隐藏选择框本身.不多说了,上代码: <!doctype html> <html> <head> <meta charset="utf- ...
- Scrum Meeting 目录 && alpha 第一次Scrum Meeting博客
是兄弟就来摸鱼小组 Scrum Meeting 博客汇总 一.Alpha阶段 标号 标题 1 [alpha]第一次Scrum Meeting(见本文) 二.Beta阶段 会议安排 时间 4月23日8时 ...
- 使用netty实现socks5协议
一.socks5协议简介 SOCKS是一种网络传输协议,主要用于客户端与外网服务器之间通讯的中间传递. SOCKS是"SOCKetS"的缩写[注 1]. 当防火墙后的客户端要访问外 ...
- 【SpringBoot】SpringBoot2.x整合定时任务和异步任务处理
SpringBoot2.x整合定时任务和异步任务处理 一.项目环境 springboot2.x本身已经集成了定时任务模块和异步任务,可以直接使用 二.springboot常用定时任务配置 1.在启动类 ...
- 编译Android 4.4.4 r1的源码刷Nexus 5手机详细教程
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/54562606 网上关于编译Android源码的教程已经很多了,但是讲怎么编译And ...
- Xposed框架中XSharePreference的使用
本文博客地址:https://blog.csdn.net/QQ1084283172/article/details/81194406 在Xposed框架的模块编写中,通常希望我们自己写的Android ...
- Fidder抓包软件的使用
Fiddler是一款强大的Web调试工具,它能记录所有客户端和服务器的HTTP和HTTPS请求.Fiddler是通过改写HTTP代理,让数据从它那通过,来监控并且截取到数据.当然Fiddler很屌,在 ...
- Windows核心编程 第七章 线程的调度、优先级和亲缘性(下)
7.6 运用结构环境 现在应该懂得环境结构在线程调度中所起的重要作用了.环境结构使得系统能够记住线程的状态,这样,当下次线程拥有可以运行的C P U时,它就能够找到它上次中断运行的地方. 知道这样低层 ...
- Python技术栈性能测试工具Locust入门
Locust是一款Python技术栈的开源的性能测试工具.Locust直译为蝗虫,寓意着它能产生蝗虫般成千上万的并发用户: Locust并不小众,从它Github的Star数量就可见一斑: 截止文章写 ...
- 【python】Leetcode每日一题-设计停车系统
[python]Leetcode每日一题-设计停车系统 [题目描述] 请你给一个停车场设计一个停车系统.停车场总共有三种不同大小的车位:大,中和小,每种尺寸分别有固定数目的车位. 请你实现 Parki ...