MMF的初步介绍:一个规范化的视觉-语言多模态任务框架
在VQA, Image Caption等任务中,构建模型是一件工作量较大的工作。有没有什么能减少这些重复的工作量呢?与此同时,Pytorch,tensorflow等开源的深度学习工具包发布,大大减少了研究人员在构建模型上的重复工作。于是,有机构开始着手以Pytorch为基础,构建了VQA的框架。由Facebook AI Research实验室使用python语言,以pytorch为基础,编写的框架MMF解决了这个问题。同时,MMF不仅包括了VQA,还有其它的很多VL多模态任务,如Image Caption等。
如何运行MMF框架
MMF的官方代码在Github上可以看到,而且附带了大量的说明。同时,其官方网站https://mmf.sh/上也有较为详细的介绍。但是初学者很容易”乱花渐欲迷人眼“,所以我就根据自己以前运行MMF的一些经验教训,介绍几个重点的内容,方便小白入门理解。

- MMF框架是用python语言写成的,使用了大量Pytorch工具包中的代码。所以要顺利运行代码,需要一些python的基础知识。python是脚本语言,和C++、Java等语言有所不同,python是边解释边执行的。其本身并没有严格的一个”主程序入口“,也就是每一个文件理论上都可以执行。当然,为了规范,python还是会用一些语法规则模拟出一个主程序入口。如果工程中一个.py文件中有类似的如下语句,那么这个文件很大几率就是要运行的程序的入口,执行这个文件一般就可以运行程序。
- if __name__=="__main__":
- function() #do something
- if __name__=="__main__":
- 深度学习模型是千变万化的,仅各种参数就有很多种组合,如果仅仅依靠执行一个文件不能灵活地满足实验中参数修改的需求。python提供了一种方便调整参数的方法,使用如下格式。当然,可修改的参数arg1,arg2,…,argn要在文件的代码中定义。
- python executeFile.py --arg1 arg2 ...
- 以上的方法还是有些不太灵活,python中还支持这样的方式:将参数配置,编写成能够被读取的.yaml格式的文件,例如default.yaml,dataset.yaml等。调用yaml配置文件的代码需要在文件中定义好。当训练时,执行程序通过调用存储在具体位置的yaml配置文件,从中获取参数配置,例如使用哪一种方式训练,使用哪一种数据集,迭代次数,batch_size等信息。这样,当训练计划有变时,我们只需要改变相应的yaml配置文件中的参数,执行同样的指令仍然可以实现程序的调整运行。该类型的指令如下:
- python configs/default.yaml dataset=XXX train_val '''类似的格式,不是完全符合'''
在mmf/setup.py中,对这种命令格式进行了进一步的打包,3中的指令,变为以下类型。在该更改中,会涉及到setuptools工具包,具体的使用说明请查阅该python工具包的文档。
- mmf_run configs/default.yaml dataset=XXX train_val '''类似的格式,不是完全符合'''
如果你已经学习了python的一些基本的语法知识,同时了解以上几种python程序运行方式,那么你离成功运行程序成功前进了一大步。因为你知道了程序的入口,也就把握住了整体。
下一步。就是为程序配置各种文件环境了。因为python程序的一大特点是有很多种封装好可下载的工具包,一些程序的编写离不开这些包的支持,所以你需要确认一下requirement.txt中的各种要求有没有满足,没有的要下载到正确的位置。这方面的知识,包括pytorch的安装使用,其它包的安装,如果包下载速度慢如何使用镜像网站资源进行快速下载,anaconda、cuda等的安装。这些问题各种网站上已经有详细的说明解答,我就不多说了。
安装、配置好各种文件后,我们继续按照mmf的说明一步一步进行。
下一步,就是mmf的直接运行,相关步骤在mmf的官方网站上写的已经比较清楚了:

在Quickstart中,以运行VQA中经典的M4C模型为样例,通过在Linux的终端输入training下方的命令行,进行运行。
注意,训练时会使用到很多参数,但以上的命令行中出现的config,dataset,model,run_type这些都是不可或缺的参数,而其它没有输入指明的,都是采用已经配置好的默认参数,这些参数可以在配置文件如 mmf/configs/defaults.yaml , mmf/configs/models/ 等位置中找到,并且可以通过修改这些数值更改默认选项。
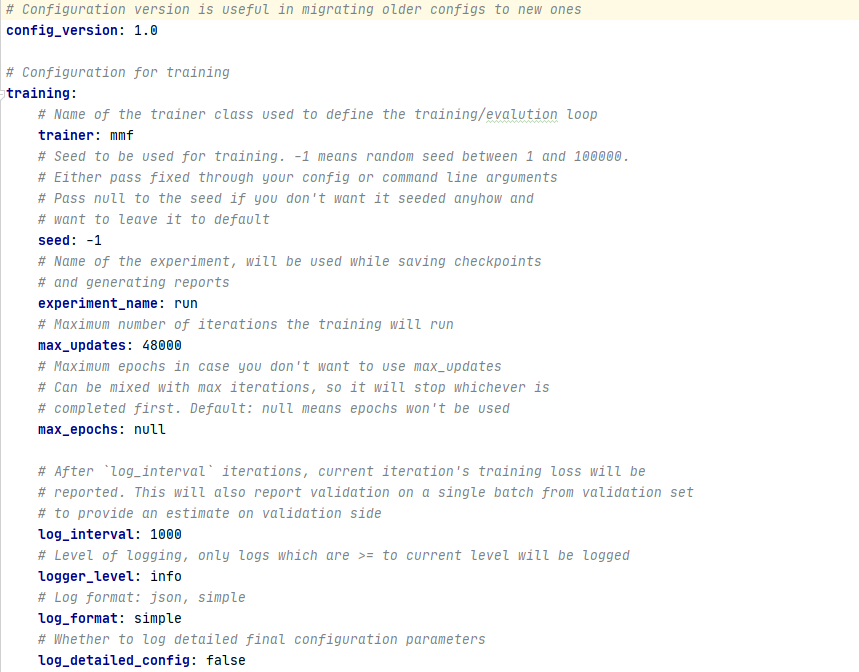
当然,你也可以在命令行中添加这些参数,让这一次的运行参数改变:
- mmf_run config=projects/m4c/configs/textvqa/defaults.yaml \
- datasets=textvqa \
- model=m4c \
- run_type=train_val \
- training.batch_size=32 \
- training.max_updates=44000 \
- training.log_interval=10 \
- training.checkpoint_interval=100 \
- training.evaluation_interval=1000 \
env.save_dir = /xxx/path_for_save_checkpoint_file \
checkpoint.resume_file = /xxx/path_for_load_specific_checkpoint_file
运行前,最好把requirements.txt 文件中记录的python程序所需要的各种包一次下载好。
输入Quickstart命令后,程序开始运行,首先要载入各种准备数据,评价结果的工具包,以及其它训练参数等。
注意,模型训练需要的数据很大!(约64GB),虽然这个程序会在指定路径检测不到数据集的情况下自动下载数据,但是由于网络等问题,经常会下了半天中断又重新开始,所以建议最好先在本地找个可靠的网络,使用mmf/configs/zoo里面的配置文件中记录的数据集链接,进行下载,然后将压缩文件上传到配置文件configs/dataset中的指定路径下。
后面是模型的载入,模型结构的输出,可以看出模型层数还是非常多的:

打印模型的参数结构后,如果没有问题,模型就开始训练了。在当前调整后的参数下,程序总共迭代44000次,每100次打印结果,训练使用的m4c_decoding_bce_with_mask损失,即BCE二元交叉熵损失,每1000次保存checkpoints文件作为记录,同时计算当前训练参数下,模型在val验证集上的指标得分。一般来说,随着迭代次数的增加,损失loss整体下降。准确率等指标逐渐上升,就说明当前模型训练整体是正确的。


我是在服务器上训练的模型,使用一块GTX2080的显卡,训练结果大约花费了11个小时。尾声阶段,可以看出训练的结果在验证集上的准确率39%左右,这个和M4C的论文Iterative Answer Prediction with Pointer-Augmented,CVPR2020 中提到的结果是基本一样的,这说明我们成功地复现了该模型的代码。

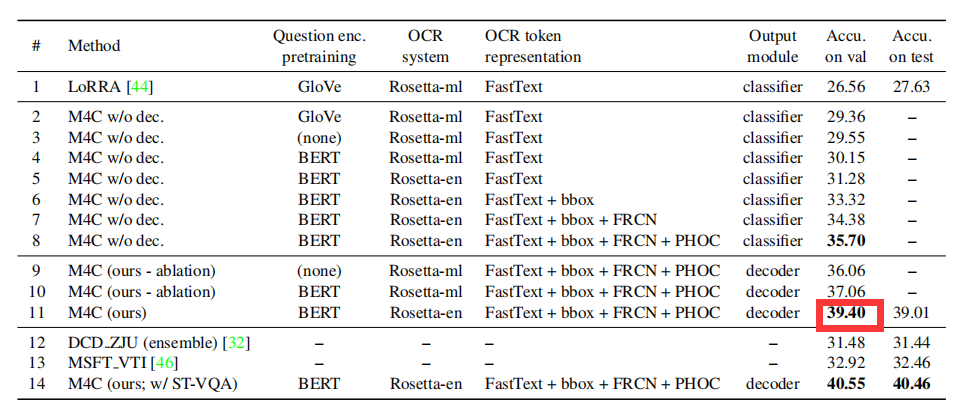
该论文中,还有一个M4C(ours, w/ST-VQA)的情况,这个取得了更高的得分,需要在数据集中添加额外的ST-VQA作为辅助的训练数据集,具体的操作请查阅mmf文档,以及M4C模型多个更改好的配置文件。
MMF的初步介绍:一个规范化的视觉-语言多模态任务框架的更多相关文章
- 一起学微软Power BI系列-官方文档-入门指南(1)Power BI初步介绍
我们在前一篇文章微软新神器-Power BI,一个简单易用,还用得起的BI产品中,我们初步介绍了Power BI的基本知识.由于Power BI是去年开始微软新发布的一个产品,虽然已经可以企业级应用, ...
- 三、Android学习第三天——Activity的布局初步介绍(转)
(转自:http://wenku.baidu.com/view/af39b3164431b90d6c85c72f.html) 三.Android学习第三天——Activity的布局初步介绍 今天总结下 ...
- mxgraph进阶(二)mxgraph的初步介绍与开发入门
mxgraph的初步介绍与开发入门 前言 由于小论文实验需求,需要实现根据用户日志提取出行为序列,然后根据行为序列生成有向图的形式,并且连接相邻动作的弧上标有执行此次相邻动作的频次.为此,在大师兄徐凯 ...
- Html/CSS 初步介绍html和css部分重要标签
&初步介绍html和css部分重要标签& 注:开头书写:<!DOCTYPE html>表明对应标准html代码 先行总结重点 下方给出具体 CSS: 1. position ...
- Django 小实例S1 简易学生选课管理系统 0 初步介绍与演示
Django 小实例S1 简易学生选课管理系统 第0章--初步介绍与演示 点击查看教程总目录 作者自我介绍:b站小UP主,时常直播编程+红警三,python1对1辅导老师. 1 初步介绍 先介绍下这个 ...
- 【STM32】使用SDIO进行SD卡读写,包含文件管理FatFs(五)-文件管理初步介绍
其他链接 [STM32]使用SDIO进行SD卡读写,包含文件管理FatFs(一)-初步认识SD卡 [STM32]使用SDIO进行SD卡读写,包含文件管理FatFs(二)-了解SD总线,命令的相关介绍 ...
- 介绍一个非常好用的跨平台C++开源框架:openFrameworks
介绍一个非常好用的跨平台C++开源框架:openFrameworks 简介 首先需要说明的一点是: openFrameworks 设计的初衷不是为计算机专业人士准备的, 而是为艺术专业人士准备的, 就 ...
- 文件系统:介绍一个高大上的东西 - 零基础入门学习Python030
文件系统:介绍一个高大上的东西 让编程改变世界 Change the world by program 接下来我们会介绍跟Python的文件相关的一些十分有用的模块.模块是什么?不知大家对以下代码还有 ...
- 介绍一个axios调试好用的工具:axios-mock-adapter
上一篇文章中写到用promise时应注意的问题,这一篇文章继续介绍一个可以和axios库配合的好工具: axios-mock-adapter.axios-mock-adapter可以用来拦截http请 ...
随机推荐
- Day09_46_Set集合_SortedSet03
SortedSet03 让SortedSet集合完成比较,还有另外一种方法,那就是单独编写一个比较器. java.util.comparator 在TreeSet集合创建的时候可以在集合中传入一个比较 ...
- Web操作摄像头、高拍仪、指纹仪等设备的功能扩展方案
摘要:信息系统开发中难免会有要操作摄像头.高拍仪.指纹仪等硬件外设,异或诸如获取机器签名.硬件授权保护(加密锁)检测等情况.受限于Web本身运行机制,就不得不使用Active.浏览器插件进行能力扩展了 ...
- 测试报告模板:HTMLTestRunner.py(新版)
报告样式效果: 报告源码:HTMLTestRunner.py 1 """ 2 A TestRunner for use with the Python unit test ...
- linux gcc命令参数
gcc命令参数笔记 1. gcc -E source_file.c -E,只执行到预处理.直接输出预处理结果. 2. gcc -S source_file.c -S,只执行到汇编,输出汇编代码. 3. ...
- poj2175费用流消圈算法
题意: 有n个建筑,每个建筑有ai个人,有m个避难所,每个避难所的容量是bi,ai到bi的费用是|x1-x2|+|y1-y2|+1,然后给你一个n*m的矩阵,表示当前方案,问当前避难方案是否 ...
- CVE-2018-8174(双杀漏洞)复现
目录 CVE-2018-8174双杀漏洞复现一(不稳定) 下载payload MSF监听 CVE-2018-8174双杀漏洞复现二
- WindowsPE 第五章 导出表
导出表 PE中的导出表存在于动态链接库文件里.导出表的主要作用是将PE中存在的函数导出到外部,以便其他人可以使用这些函数,实现代码重用. 5.1导出表的作用 代码重用机制提供了重用代码的动态链接库,它 ...
- 推荐算法-聚类-K-MEANS
对于大型的推荐系统,直接上协同过滤或者矩阵分解的话可能存在计算复杂度过高的问题,这个时候可以考虑用聚类做处理,其实聚类本身在机器学习中也常用,属于是非监督学习的应用,我们有的只是一组组数据,最终我们要 ...
- Android Dex分包之旅
http://yydcdut.com/2016/03/20/split-dex/ http://blog.zongwu233.com/the-touble-of-multidex http://tec ...
- 改善c++程序的150个建议(读后总结)-------27-35
27. 区分内存分配的方式 c++中内存分为5个不同的区 ①栈区 栈是一种特殊的数据结构,其存取数据特点为(先进后出,后进先出).栈区中主要用于存储一些函数的入口地址,函数调用时的实参值以及局部变量. ...