3.k8s核心概念
k8s的核心概念
一. Pod
pod,中文翻译过来叫豆荚,如下图。我们都知道豆荚,一个豆荚里面有很多豆子。豆荚就可以理解为pod,一个个的豆子就可以理解为容器。pod和容器的关系是一个pod里面可以有一个或者多个容器。Pod是k8s部署的最小单位。
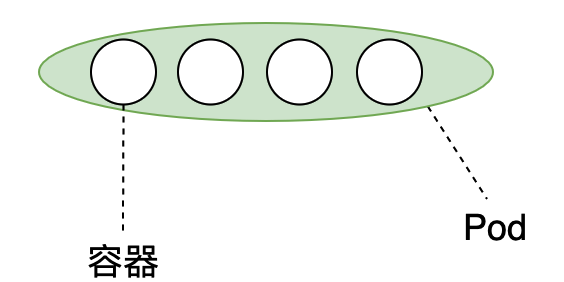
那么pod中容器和容器之间有什么关系呢?
当server api将指令下发给kubelet的时候,kubelet会创建第一个容器,不管创建pod的目标是什么,第一个容器总是不变的,他就是pause。pause是第一个被创建的容器,它的作用有两个:
初始化网络栈
创建对应的veth,网络命名空间,网桥,这些都是初始化网络栈的时候完成的。
挂载网络卷
当我们需要 pod有一定的存储能力,这时就需要给pod挂载到对应的卷,这个卷是被谁挂载的呢?不是被应用容器挂载的,而是被pause挂载的。
初始化好pause,后续可以在pod中安装一个或多个容器。这些容器跟pause共享网络栈,共享数据卷。
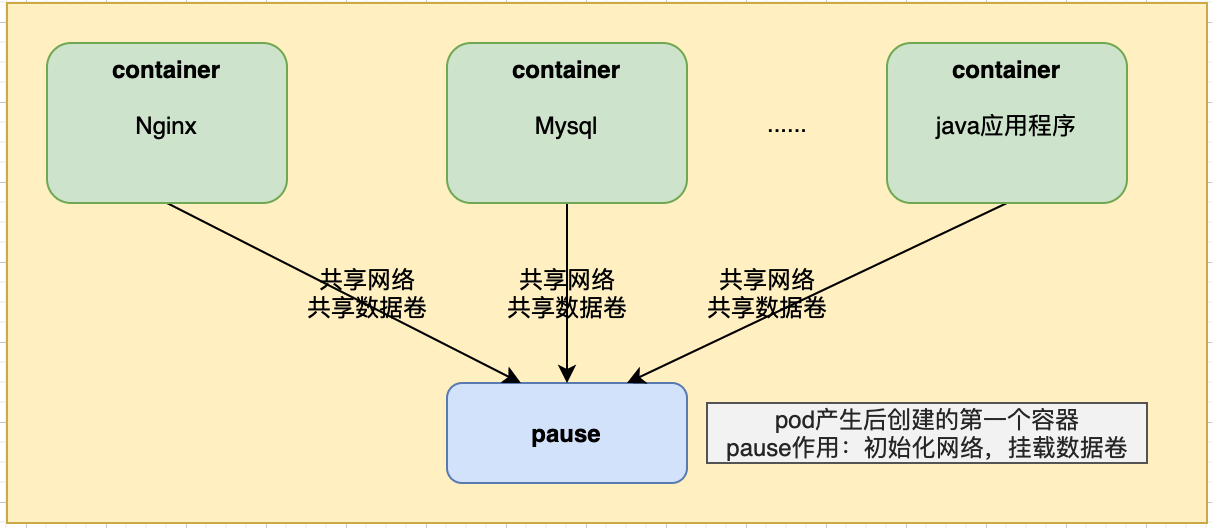
比如,我们在pod中添加了3个容器,nginx,mysql,java应用程序。还可以更多,但最少要有一个container。这些容器共享pause的网络和数据卷。所以,在pod中的容器,容器名、端口号都不能重复,否则会报错。
提示:通常容器关联比较大的应用,放在一个pod中,在同一个pod中可以使用localhost进行访问
1.Pod的类型
1) 自主式Pod
自主式Pod是不被控制器管理的Pod. 这种Pod死亡以后, 不会被重新启动. 这个Pod死了以后, 副本数就达不到期望值了, 也不会有人去创建一个新的Pod来达到副本数的期望值.
在传统情况下, 我们运行一个容器, 每一个容器都是独立存在的, 每个容器都有自己的ip地址, 每个容器都有自己的挂载卷. 但在k8s移植的时候, 就不太容易了. 我们把一个没有在容器里运行的环境转移到或迁移到k8s的环境里, 就比较难迁移.比如:LAMP, 那么A和php之间有联系,我们把A和php分开了, 他俩个是不同的地址, 还要去配置反向代理, 比较费劲.
说的是什么意思呢? 有些组件应该在一起, 并且能互相见面, 也就是通过localhost能访问到. 但是, 使用标准的容器, 你没办法这样做, 除非你把两个进程封装在一个容器内部. K8S给我们建立了一个Pod, Pod是怎样实现的呢?
首先, 要定义一个Pod, 他会先启动第一个容器, 需要注意的是, 只要运行了Pod, 这个容器就会被启动. 这个容器叫pause
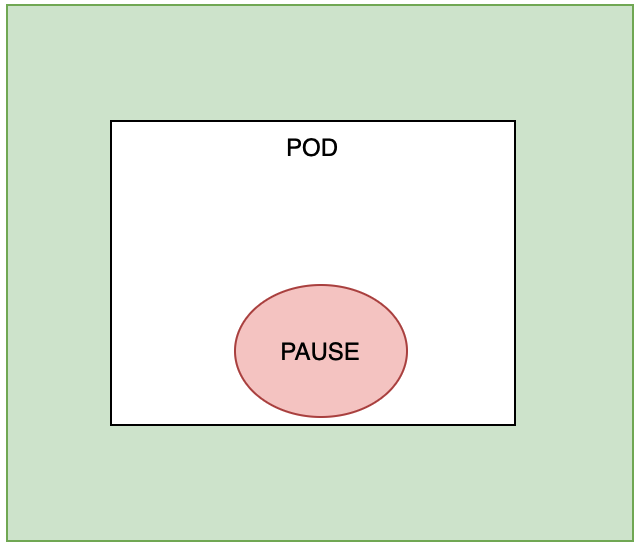
然后, 在Pod里定义了两个容器, 这两个容器不是固定的,几个都可以,至少是一个。 然后这两个容器会共用PAUSE的网络栈和存储卷.
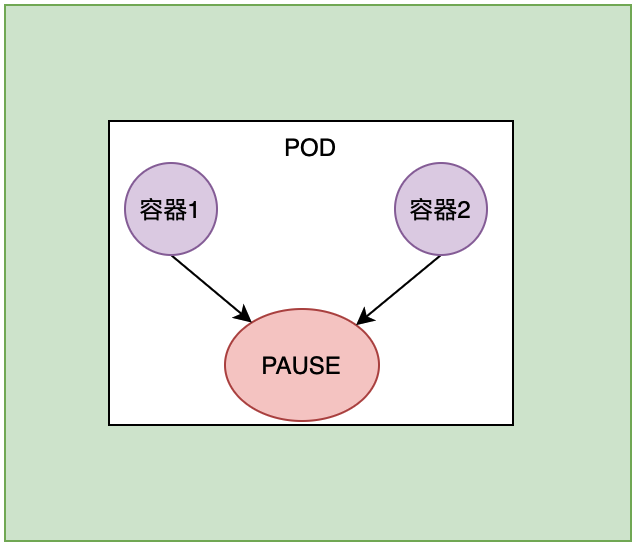
也就是说, 这两个容器没有自己独立的ip地址和存储卷, 或者说, 他们有的是PAUSE或者pod的ip地址. 这两个容器他们尾根隔离, 但是进程不隔离. 也就是说, 如果容器1运行的是php, 容器2运行的是nginx, nginx想要反向代理访问php, 只需要要写localhost:9000即可. 不需要写IP地址+端口映射. 能够直接使用localhost的原因是这两个容器共享的是PAUSE的网络栈.
这样就说明了, 在同一个Pod里, 容器之间的端口不能冲突. 一个pod里不能有两个容器的端口都是80
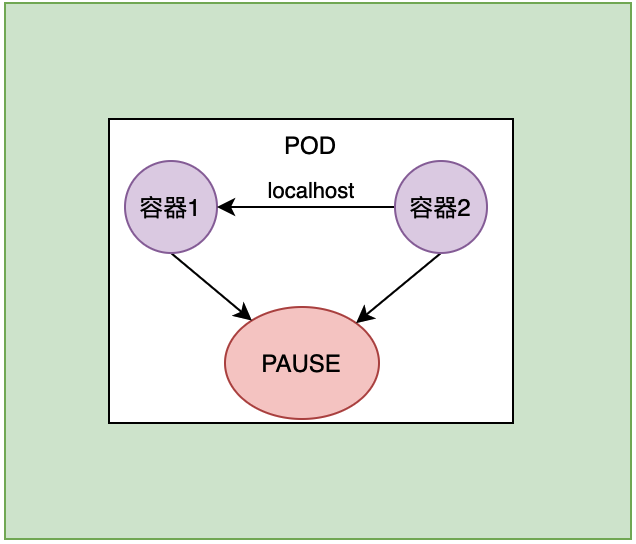
下面一个要说明的是: 共享存储. 这里两个容器除了共享网络, 同时也共享存储卷.
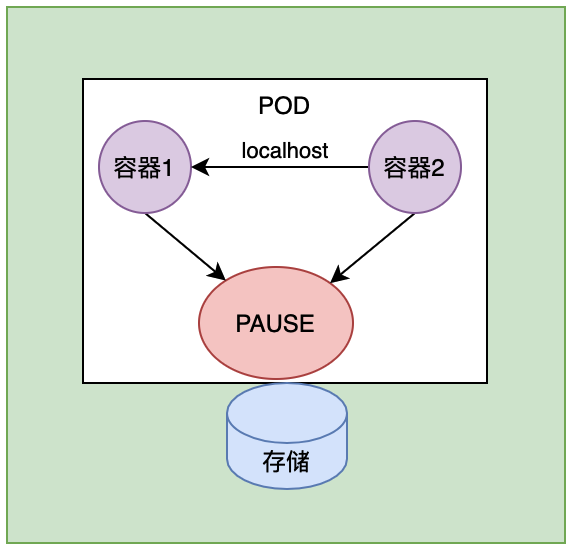
假设PAUSE挂载了一个存储,容器1会共享PAUSE的储存卷,容器2也共享PAUSE的存储卷,也就是说一个pod中的容器共享PAUSE的存储卷
2) 控制器管理的Pod
控制器管理的Pod有三种:ReplicationController & ReplicaSet & Deployment , 这三种控制器有很多相似的地方
i.ReplicationController
ReplicationController简称rc. 它的作用是确保容器应用的副本数始终保持在用户定义的副本数, 这是用户的期望。即如果有容器异常退出, 会自动创建新的Pod来代替; 而如果异常多出来的容器也会自动回收. 在新版本的k8s中, 建议使用ReplicaSet来取代ReplicationController.
ii.ReplicaSet:
ReplicaSet简称rs. 跟ReplicationController没有本质上的区别, 除了名字不同, ReplicaSet支持集合式的selector.
这个集合式的选择器是什么呢?就是在我们创建Pod的时候, 可以给他打标签. 比如: app = http, version = v1版本等等. 我们会打一堆的标签. 当我们想删除容器的时候, 我们可以这样说: 当app=http, version = v1的时候, 执行什么操作. rs支持这种集合方案, 但是rc不支持. 所以在大型项目中, rs比rc会更简单, 更有效率. 所以, 在新版本中, 官方抛弃rc, 全部转用rs.
在小的集群下,有没有标签都没所谓,但当集群越来越大,pod越来越多的时候,标签就很有用了。我们可以通过标签定位某一个pod。
所以,rc适合小集群使用,rs适合多集群,pod量很大的时候使用。rs包含了rc的功能,所以官方都建议使用rs。
iii.Deployment:
虽然replicaSet可以独立使用, 但一般还是建议使用Deployment来自动管理ReplicaSet, 这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持 rolling-update滚动更新, 但Deployment支持) 。Deployment为何要和RS一起使用呢?是因为Deployment本身不能创建Pod。
滚动更新还是很有意义的, 尤其是在生成环境中
比如:我们现在有两个容器, 我们要将现在容器的版本从v1版本升级到v2版本. 这时候, 怎么办呢? 我们可以进行滚动更新.
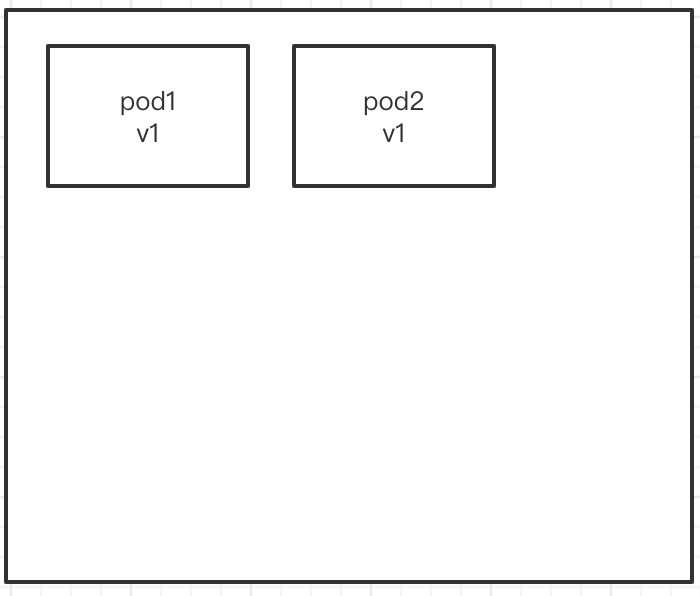
首先, 先生成一个新的pod. 然删除一个旧的pod, 如下如所示. 先生成一个v2版本的pod, 然后删除一个v1版本的pod .再把v2版本的pod挂载到集群上,然后以此类推,所有服务器以此替换。最后,所有服务器就都是v2版本的,这就是滚动更新.
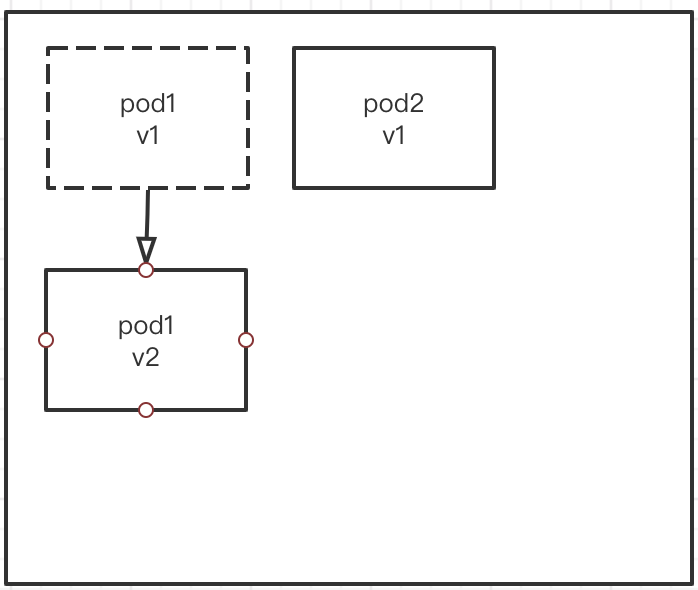
那么, Deployment是如何管理rs并滚动更新的呢?
- 首次部署的时候,要做那些事呢?
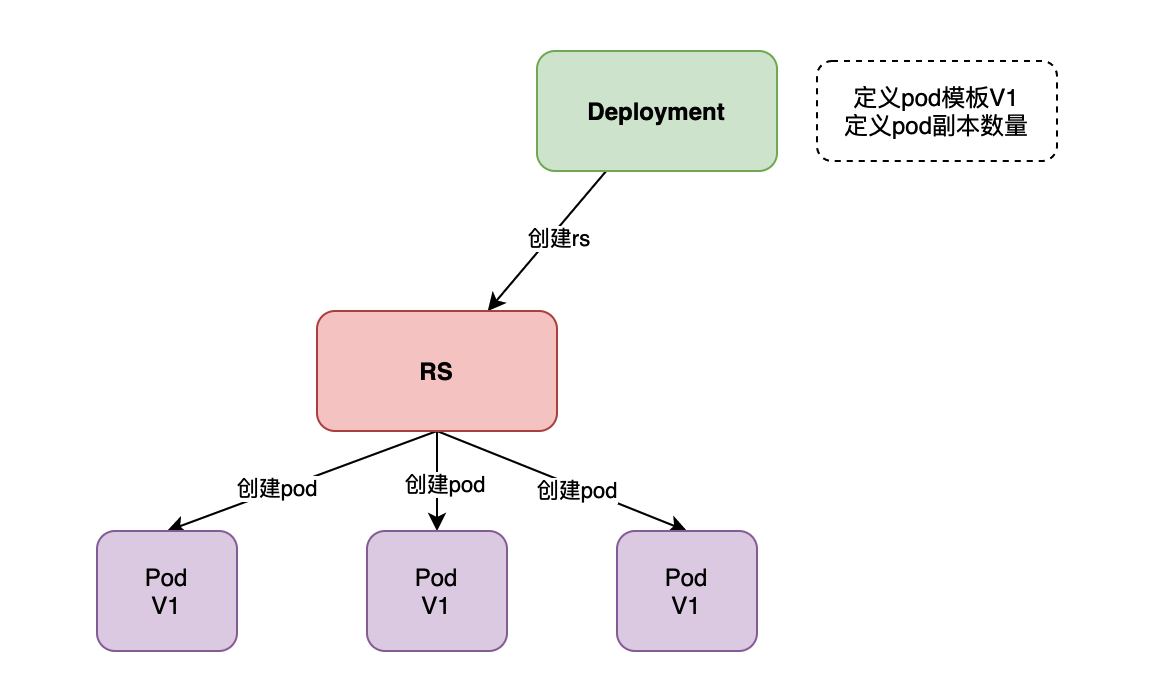
第一步:会创建一个Deployment控制器,在Deployment控制器中定义了pod的模板和副本数量。
第二步,Deployment会主动创建一个RS。也就是说rs不是我们自己定义的, 是Deployment自动生成的. RS会创建多个pod
第三步,RS主动帮我们创建Pod,并维持pod副本数的稳定。
Deployment定义出来以后, 他会定义一个rs, RS会创建多个pod. 如下图
- 当需要更新版本的时候. 怎么做呢?
官方开发出了v2版本,这时我们要进行滚动更新了。如何滚动更新呢?
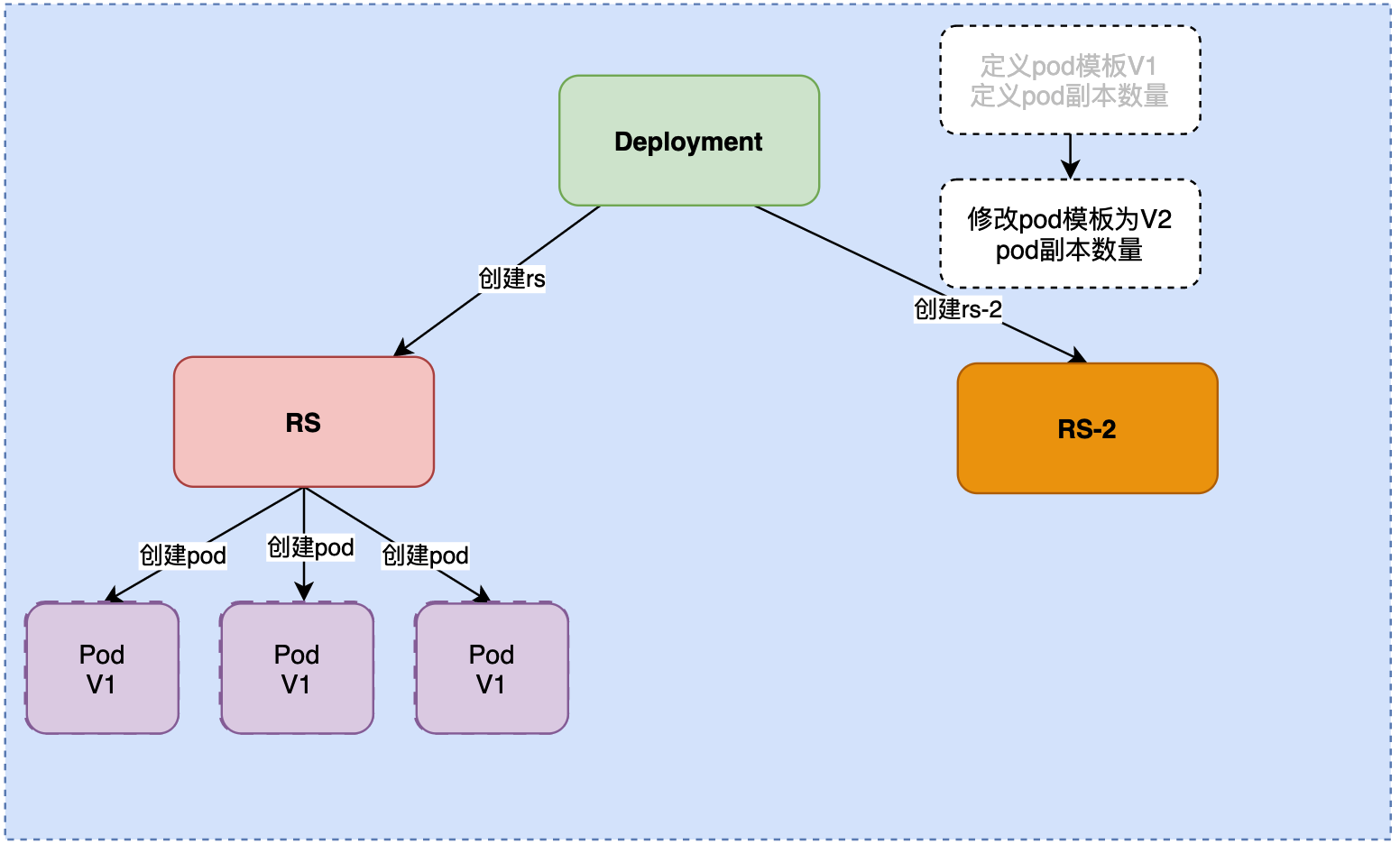
第一步:Deployment会更改pod模板为V2。
第二步:Deployment控制器再创建一个新的RS。我们的期望是从左边的RS迁移到右边的RS。
` 
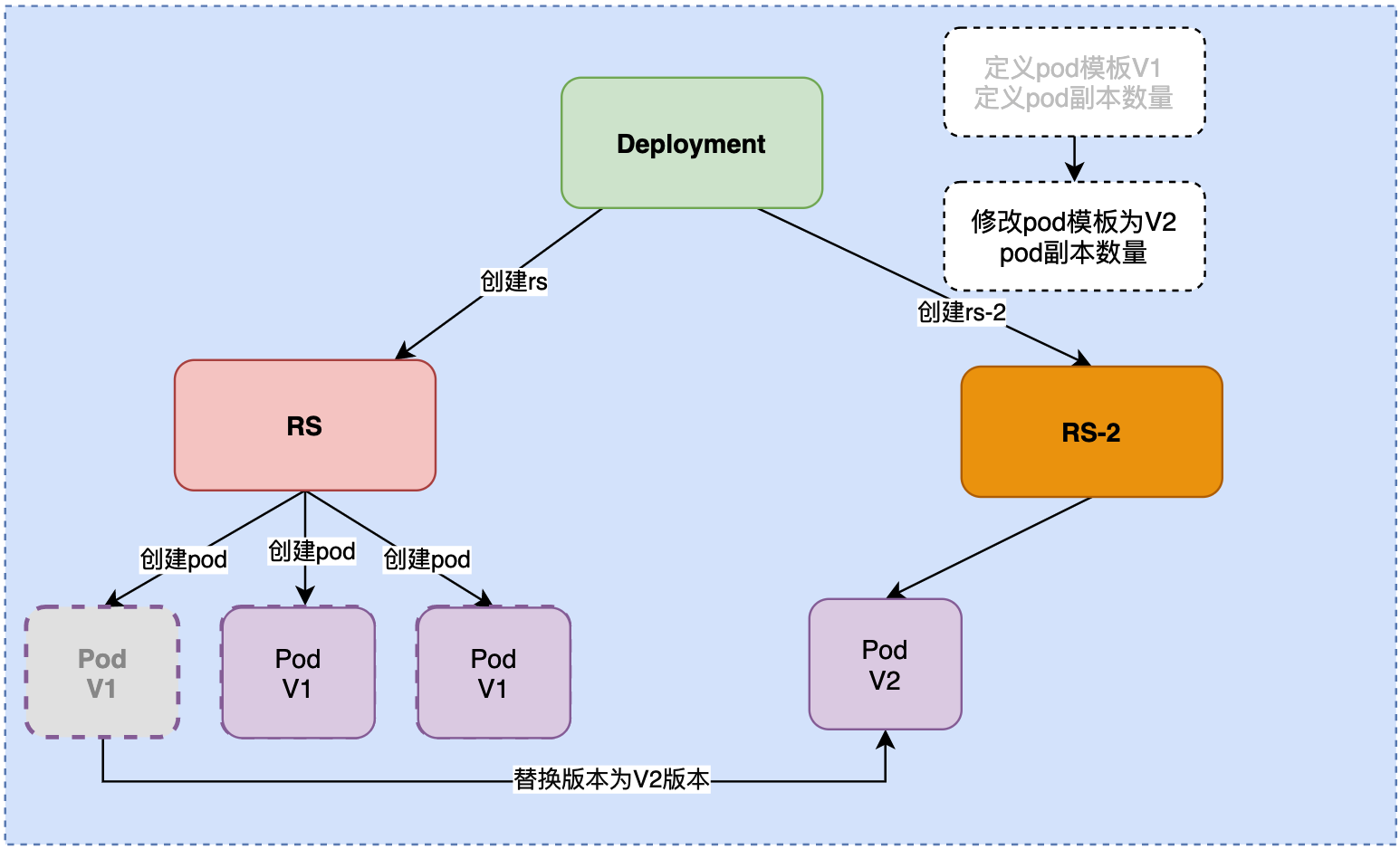
第三步:RS-2再创建一个新的 Pod, 将其升级到v2版本. 然后下掉一个v1版本的Pod
第四步:在创建一个Pod, 将其版本升级到v2, 在下掉一个v1版本的Pod
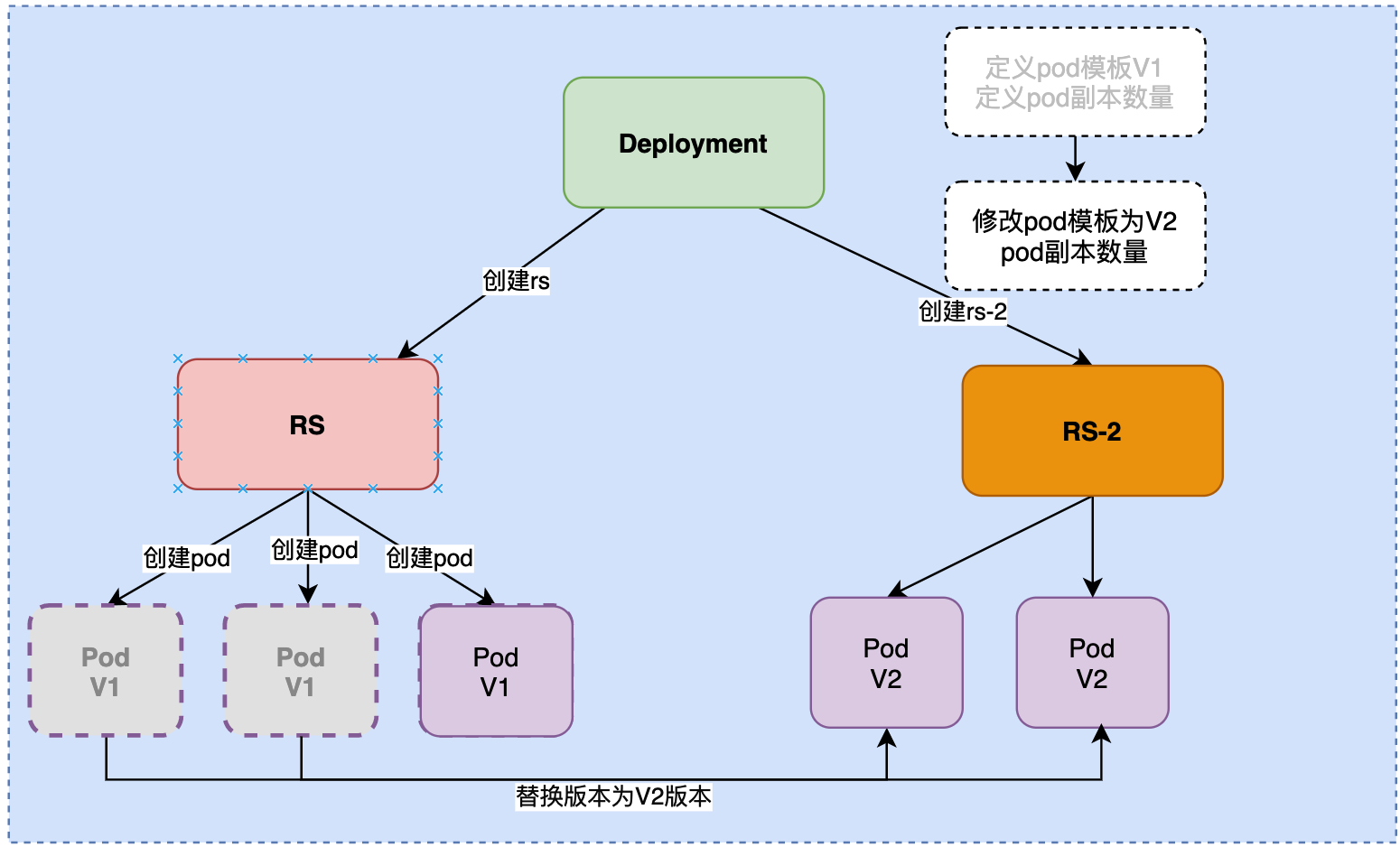
第五步:直至全部下完.
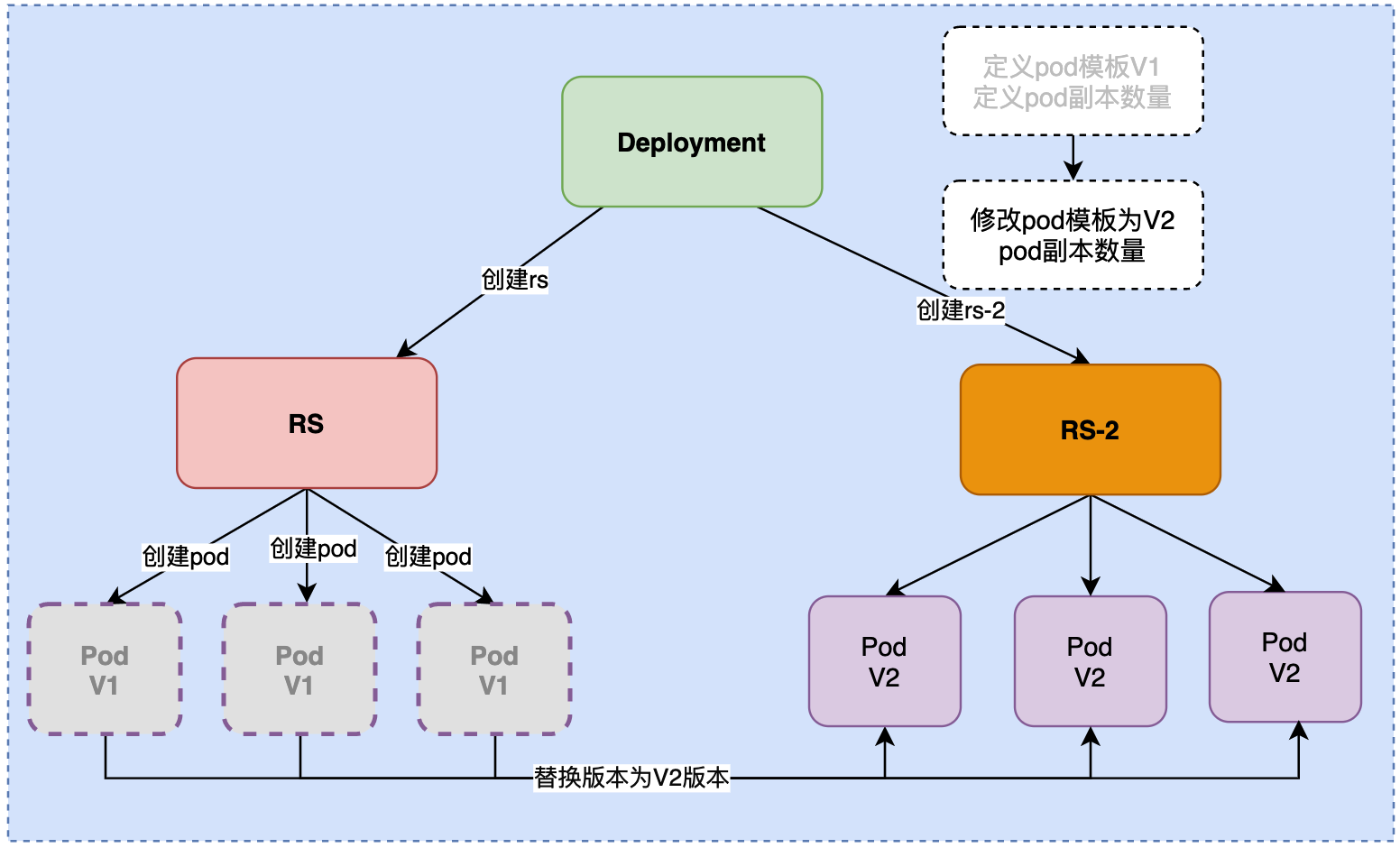
这就是Deployment管理的滚动rolling-update滚动升级。
如果升级的过程中, 发现新版本有一些小bug, 我们还可以回滚. 如何回滚, 执行undo即可. 回滚的逻辑和版本升级的原理一样. 恢复一个v1, 下掉一个v2. 直至全部恢复.
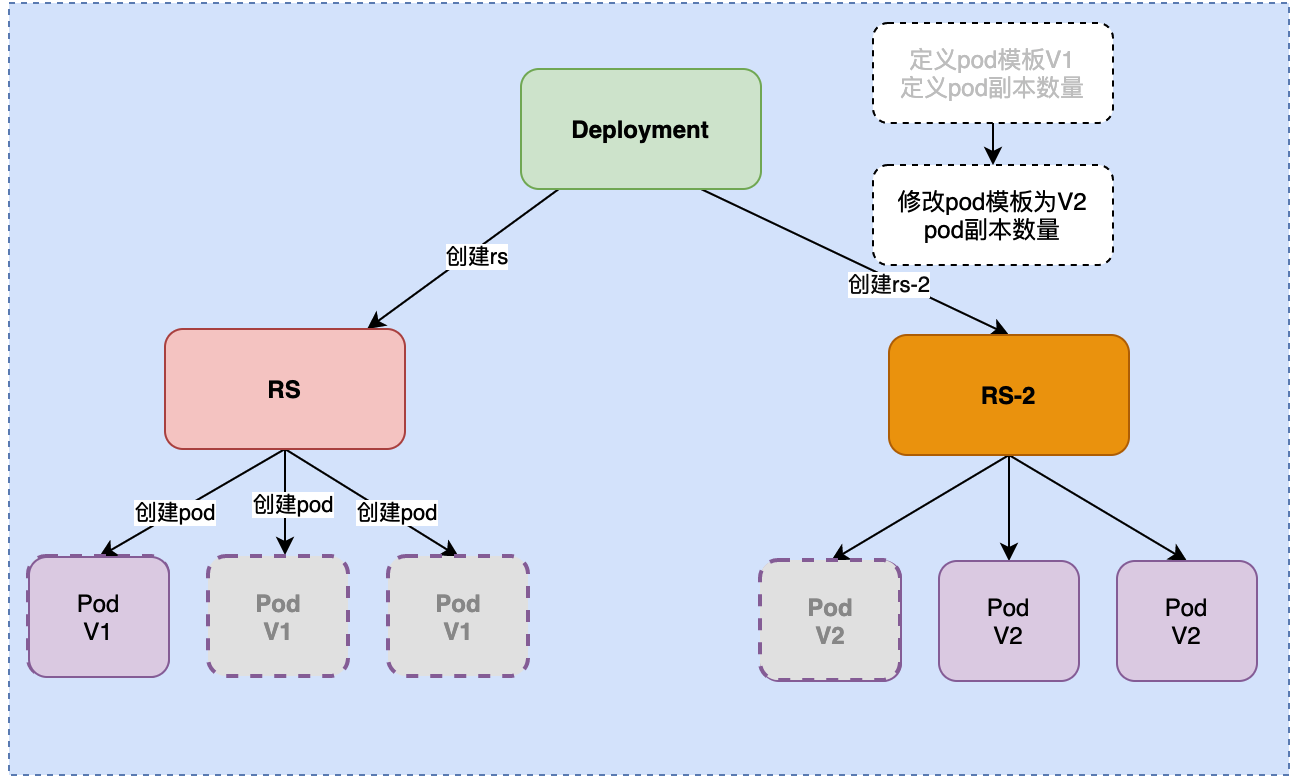
为什么RS能够恢复呢?
因为, 下掉的RS没有被删掉. 只是停用了. 当回滚的时候, 老旧的RS就会被启动.
iv. HPA控制器
Horizontal Pod Autoscaling 简称HPA控制器,仅适用于Deployment和ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩缩容,在vlalpha版本中,可以根据内存和用户自定义的metric扩缩容。
举个例子:
首先,我们创建出一个Deployment控制器或者RS控制器,这个控制器会创建pod副本,在Deployment或者RS之上可以增加一个HPA控制器。HPA也是一个对象, 他是基于RS创建的。HPA控制器可以定义一个阈值,比如CPU使用率大于80%的时候,进行扩容;CPU使用率小于20%的时候进行缩容。pod副本数最小2个,最大20个。
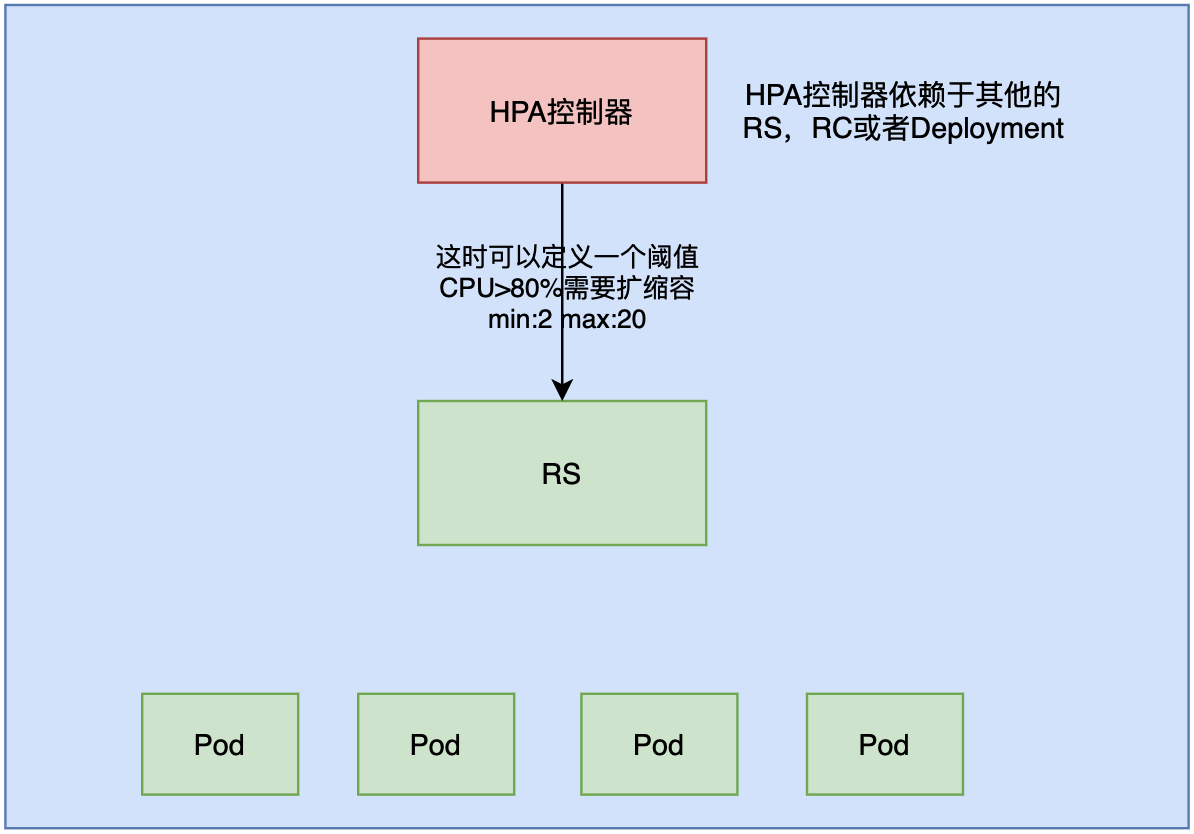
于是,当cpu使用率超过80%的时候,RS会自动进行扩容,最大扩容到20个副本。
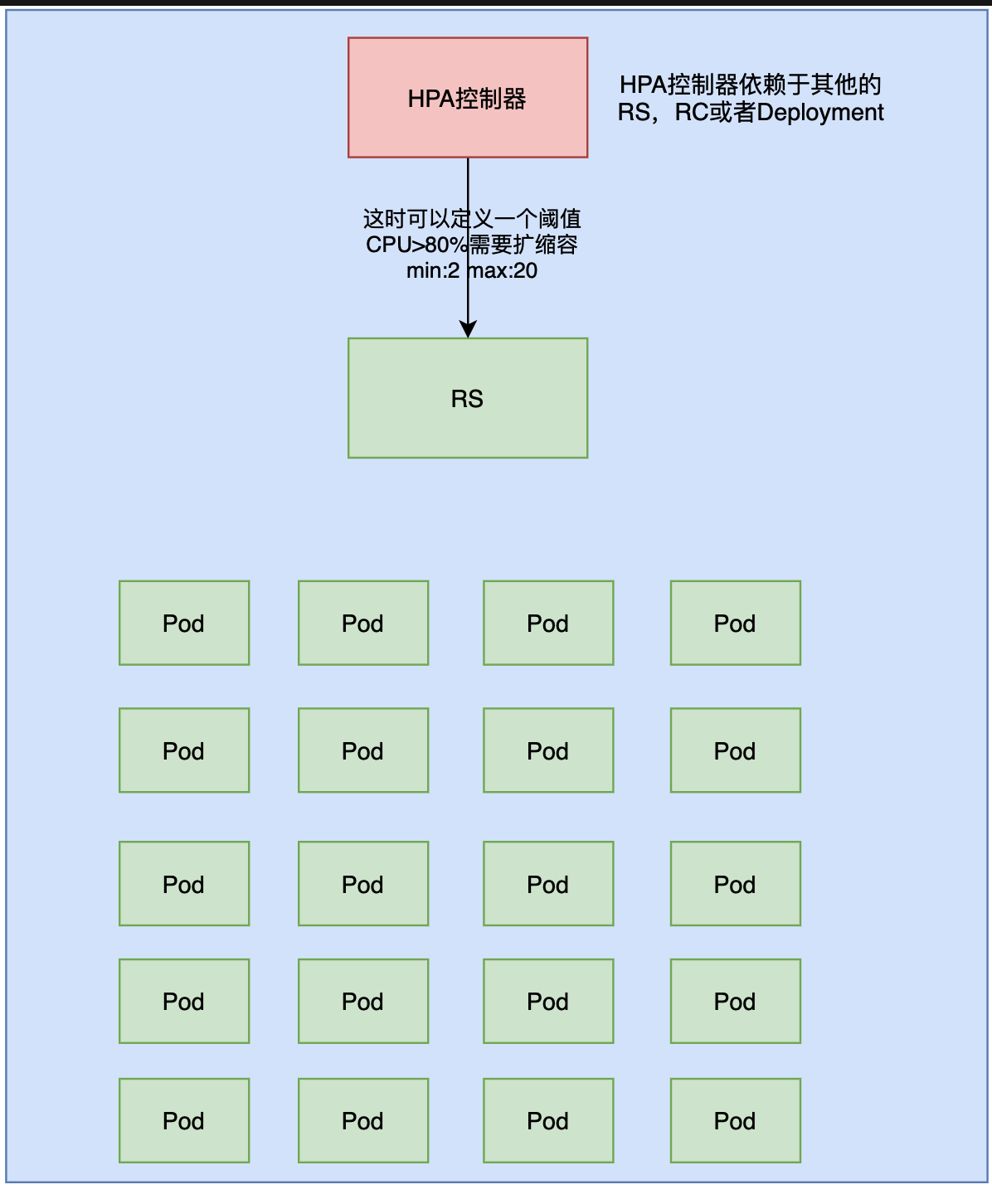
如果创建了20个副本以后,CPU依然大于80%,那么就爱莫能助了。
缩容也是一样的,当cpu使用率很小的时候,就缩容,但最小是2个。也即是减到只剩2个pod, 不能再减了.
这样就达到了一个水平扩展的目的. 这也是HPA帮我们实现的.
v. statefulSet
statefulSet主要解决的是有状态服务的问题. docker主要面对的是无状态服务。
服务的分类:
1. 无状态服务: 踢出去过段时间放回来, 依然能正常工作. 比如LVS调度器, APACHE(http服务)
为什么apache是无状态服务呢? 因为apache中的数据可以通过共享服务来完成. 对于组件本身他不需要数据, 也没有数据的更新. 所以, apache被定义到无状态服务里面.
docker: 对于docker来说, 他更适合运行的是无状态服务.
2. 有状态服务: 踢出集群后过段时间再放回来, 就不能正常工作了, 这样的服务就是有状态服务. 比如: 数据库DBMS, 因为有很大一部分数据缺失了.
Kubernetes的一个难点就是必须要攻克有状态服务. 那么, 有状态服务, 有些数据需要持久化, 需要保存起来, 这时,我们就会引入存储的概念.
主要解决的是有状态服务的问题. docker主要面对的是无状态服务, 无状态服务的含义时, 没有对应的存储需要实时的保留. 或者是把他摘出来, 经过一段时间以后, 放回去依然能够工作. 典型的无状态服务有哪些呢? 比如: apache服务, LVS服务(负载均衡调度器) . 典型的有状态服务有哪些呢?mysql, mongodb, 他们需要实时的对数据进行更新和存储. 把他抽离出集群,再放回来就没办法工作了. statefulSet就是为了解决有状态服务而诞生的. Deployment 和 ReplicaSet是无状态服务
statefulset的应用场景包括:
1>稳定的持久化存储.
即Pod重新调度后还是能访问到相同的持久化数据. 基于PVC来实现.
Pod重新调度指的是Pod死亡以后, 我们会在调度回来。也就是创建一个新的Pod,创建的这个新的Pod取代原来的Pod的时候, 他的存储依然是之前的存储, 并不会变, 并且里面的数据也不会丢失.
2> 稳定的网络标识:
即Pod重新调度后,其PodName和HostName是不变的,也就是说之前的Pod叫什么, 现在Pod就叫什么. 之前的主机名是什么,现在的主机名还是哪个。 基于Headless Service(即没有Cluster IP 的Service)来实现。
3> 有序部署.
有序部署分为扩展和回收两个阶段.
- 有序扩展. 即Pod是有顺序的, 再部署或扩展的时候, 要依据定义的顺序一次进行(即从0到n-1, 在下一个pod运行之前, 所有之前的Pod必须都是Running和Ready的标志), 基于init Containars实现
只有当前一个Pod处于running和ready的状态, 第二个才可以被创建. 为什么需要这样部署呢? 原因是, 我们构建一个集群化, 比如集群里有nginx, apache, mysql. 我们的启动顺序是先启mysql, 再启apache, 再启nginx, 因为他们之间是有依赖关系的. nginx依赖apache, apache依赖mysql. 这就是有序部署.
4> 有序收缩, 有序删除
回收也是一样的是有序的, 不同的是, 他是逆序回收. 从n-1开始, 一直到0.
vi. **DaemonSet: **
确保全部(或一些)Node上运行一个Pod的副本. 当有Pod加入集群时, 也会为他们增加一个Pod副本, 当有Pod从集群移除时, Pod副本也会被回收,删除DeamonSet会删除对应的所有的Pod.
- 这里说的是确保全部或者一些,为什么会是一些呢?这是因为,我们可以在node上打污点,打上污点的node是不被调度的。所以,在DaemonSet运行的时候,打了污点的node是不会被创建的。默认情况下,所有node都会被运行。每个pod只会创建一个副本。
使用DaemonSet的典型用法:
- 运行集群存储daemon, 例如在每个Node上运行glusterd, ceph.
- 在每个节点上运行日志收集daemon, 例如fluentd, logstash.
- 在每个节点上运行监控daemon, 例如Prometheus, Node Exporter.
只要有需求,每个node上都可以运行一个守护进程,去帮我们做一些事情,这个时候就可以使用DaemonSet
vii. Job, CronJob
Job是负责批处理的任务. 仅执行一次的任务, 它保证批处理任务的一个或多个Pod成功结束
比如: 我想备份数据库, 备份代码可以放在Pod里, 我们将其放到Job里去执行,脚本是可以正常执行正常工作。直接在linux操作, 到时间就可以把脚本运行, 执行出来. linux操作系统执行不也是一样的么?
一方面封装成pod, 我们可以重复利用;
另一方面,如果脚本执行意外退出,是没办法重复执行的,job如果判断当前脚本不是正常退出,她会重新执行一遍脚本.直到正常退出为止,并且还可以设置政策退出的次数.
CronJob管理基于时间的Pob, 在特定的时间可以执行
即
》在给定的时间点只运行一次
》周期性的再交给时间点运行
3. 服务发现
k8s是如何实现服务间的调用的呢?这就是接下来要说的服务发现
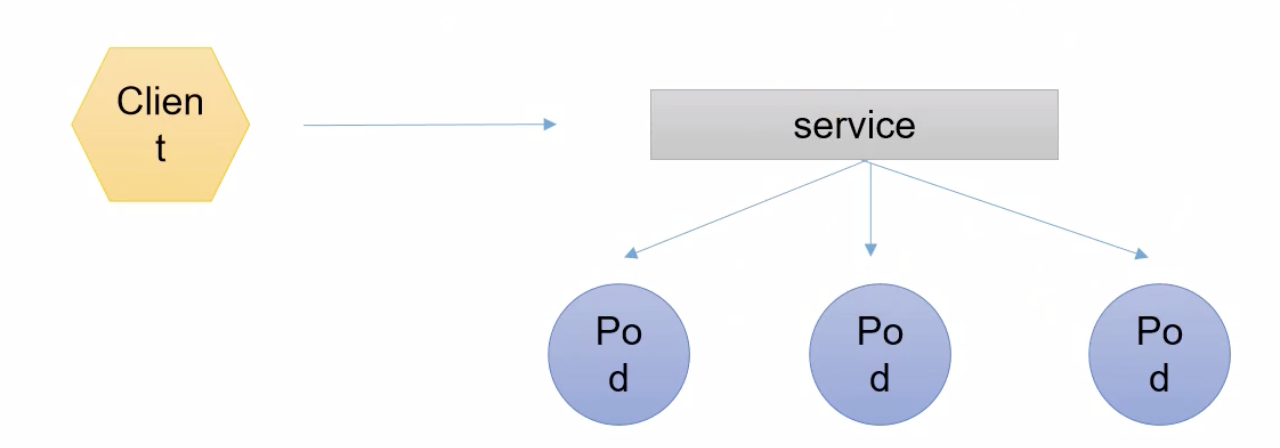
客户端想要访问一组pod, 如果这些pod是无相干的话,是不能通过Service统一代理的. pod需要具有相关性, 比如由同一个rs//rc/deployment创建的, 或者拥有同一组标签, 这样的话可以被service收集到. 即: service去搜集Pod是通过标签去选择到的. 这一点很重要.
选择到以后, service会有自己的ip+port, 客户端就可以访问service的ip+端口. 间接访问pod. 并且这里有一个RR的算法存在.
假设我们现在有一个简单的集群环境:
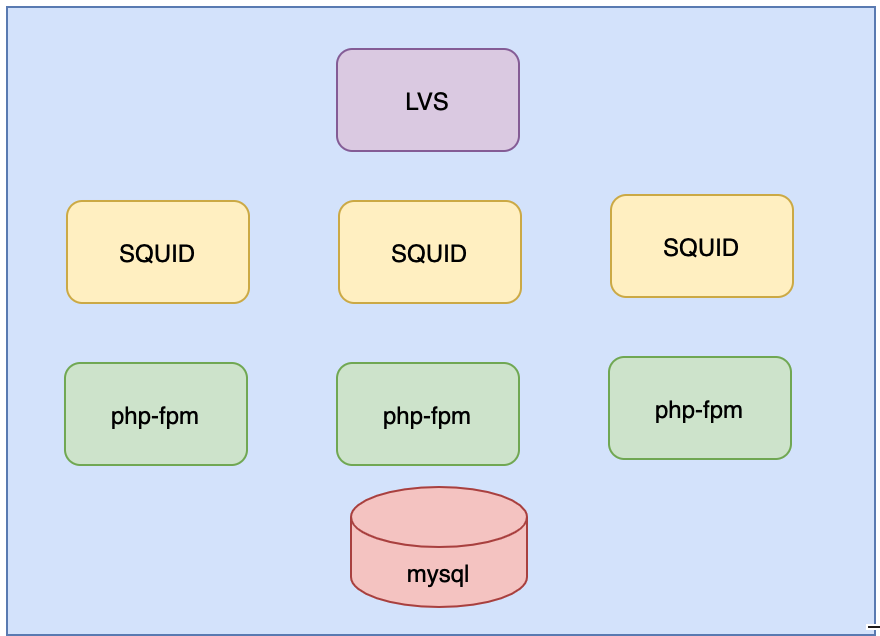
有一个myqsl, 三台apache-fpm, 三台缓存服务器SQUID, 有一个负载均衡器LVS. 我们来分析一下, 如果把这个集群放到k8s中应该如何部署.
1> mysql需要运行在一个Pod中
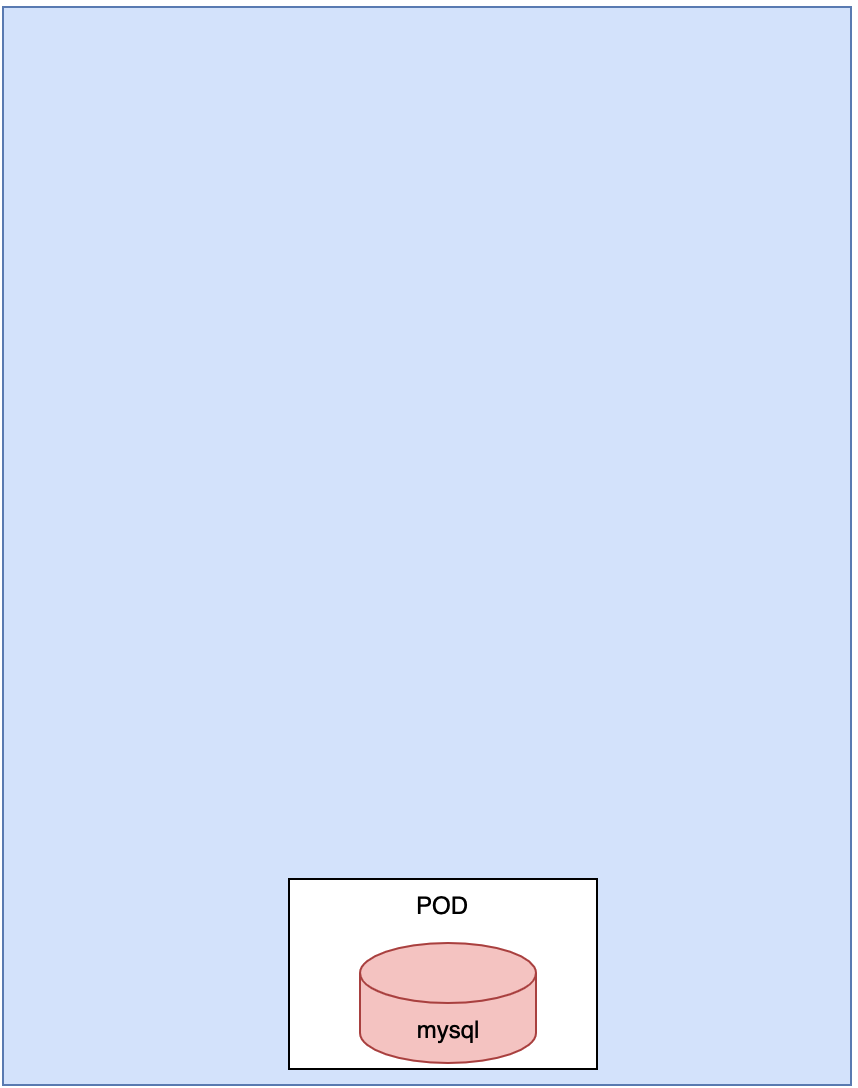
在k8s上创建一个pod,里面在创建一个mysql容器
2> apache-fpm, 有三个, 其实他们都是类似, 所以我们可以把它放到Deployment控制器中创建, Deployment可以配置apache-fpm的副本数有3个副本
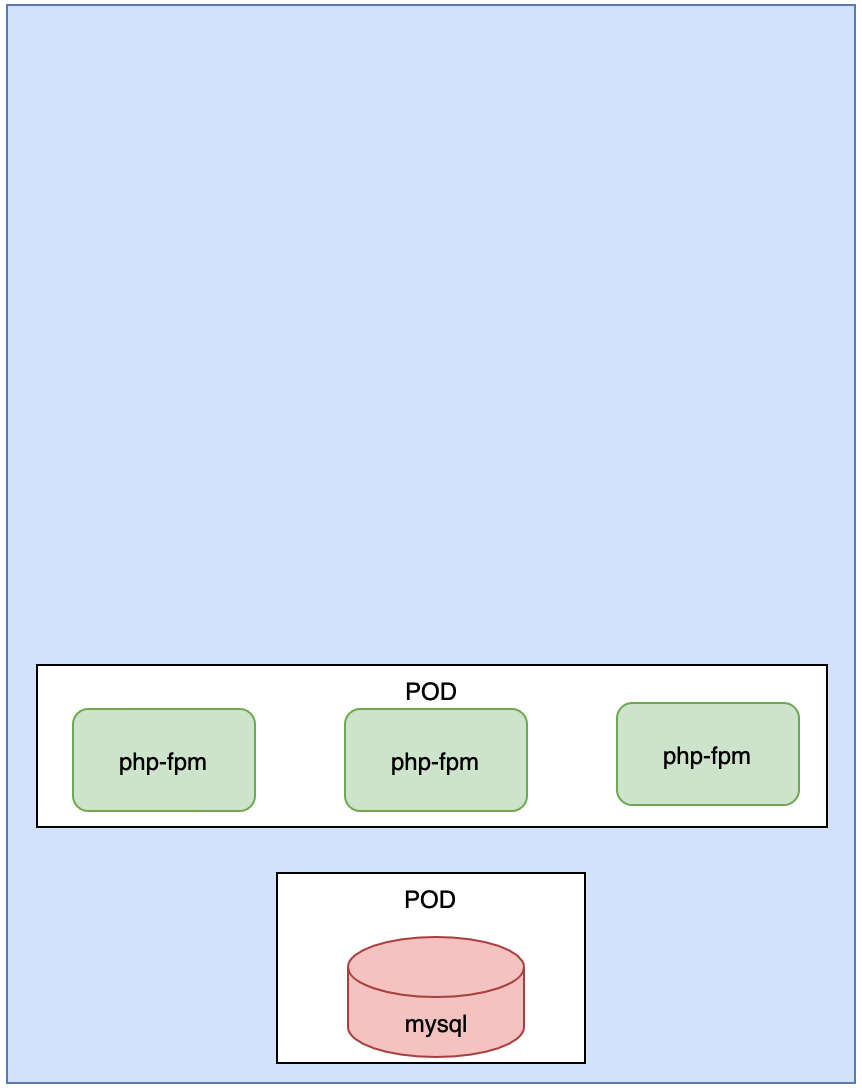
3> SQUID,缓存服务器也有三个, 我们也可以把它放到Deployment控制器中创建.
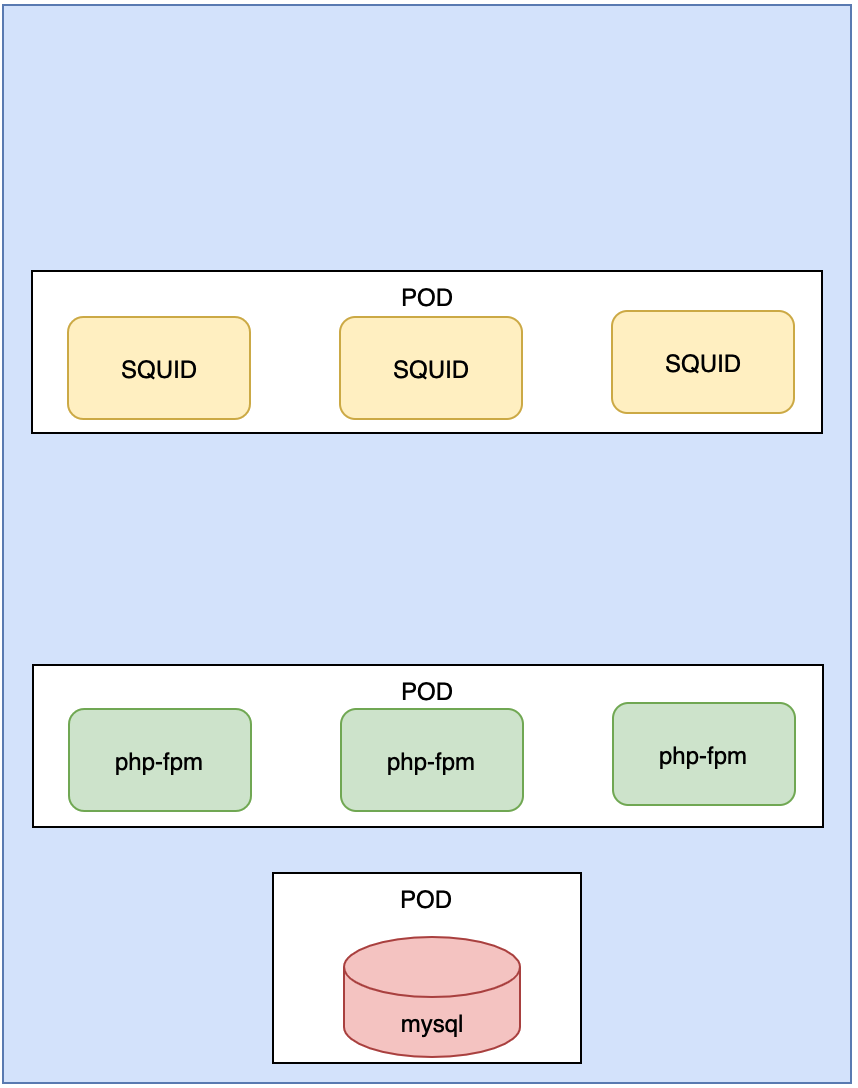
4> LVS, 可以用集群本身的功能, 进行负载调度.
现在这种结构, 我们发现, 如果缓存服务器SQUID想要访问apapche-fpm, 写反向代理的话, 需要写三台服务器. 并且, pod如果退出重新创建, 那么pod的ip地址会变换. 除非采用的是statefulSet, 但是在apache-fpm中使用statefulSet是没有意义, 因为他是一个无状态服务 . 那怎么办呢? 我么可以在前面加一个service, 这个service就是Service-php-fpm的. 他会绑定我们的标签.
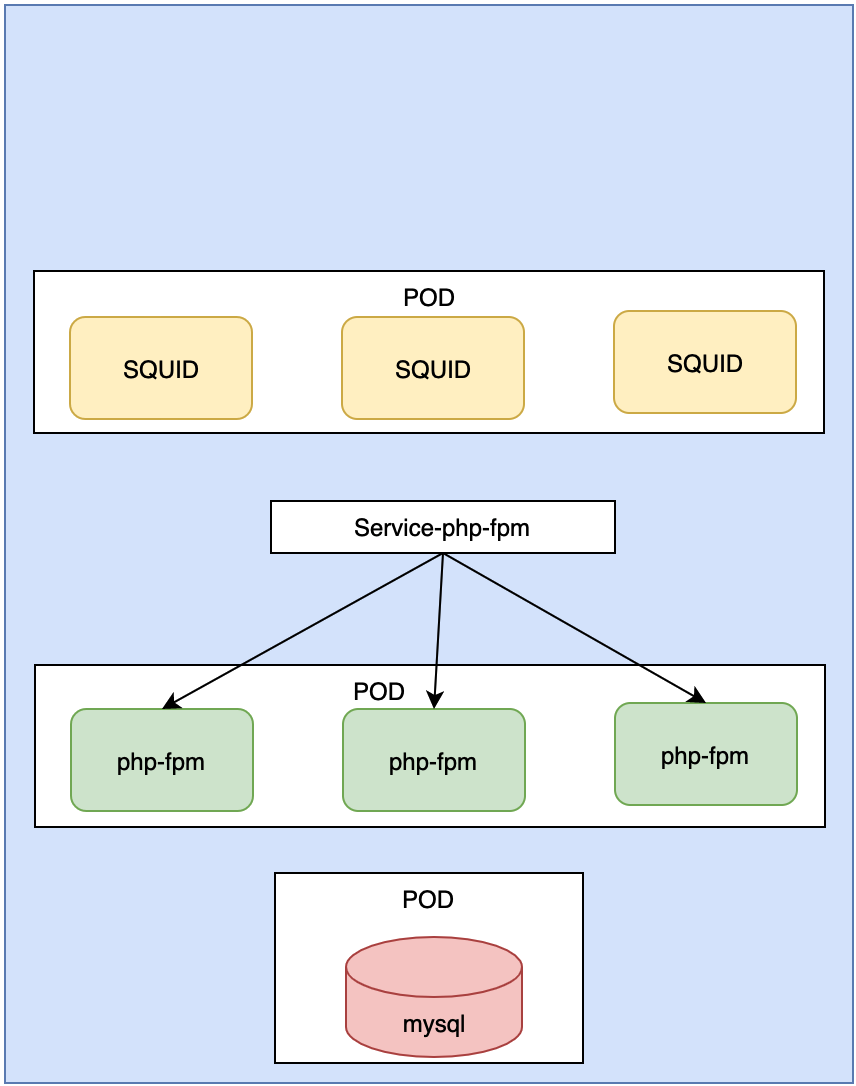
SQUID去进行反向代理设定的时候, 不需要写php-fpm的三个ip地址了, 而且, pod死亡以后, 控制器会把他维持到三个副本, 会在自动创建一个, 新创建的ip地址和原来的是不一样的. SQUID如果在里面填写的是目标ip, 就有问题. 所以, SQUID里面写的是server-php-fpm的地址. 这样SQUID只要执行到Service-php-fpm上面即可.
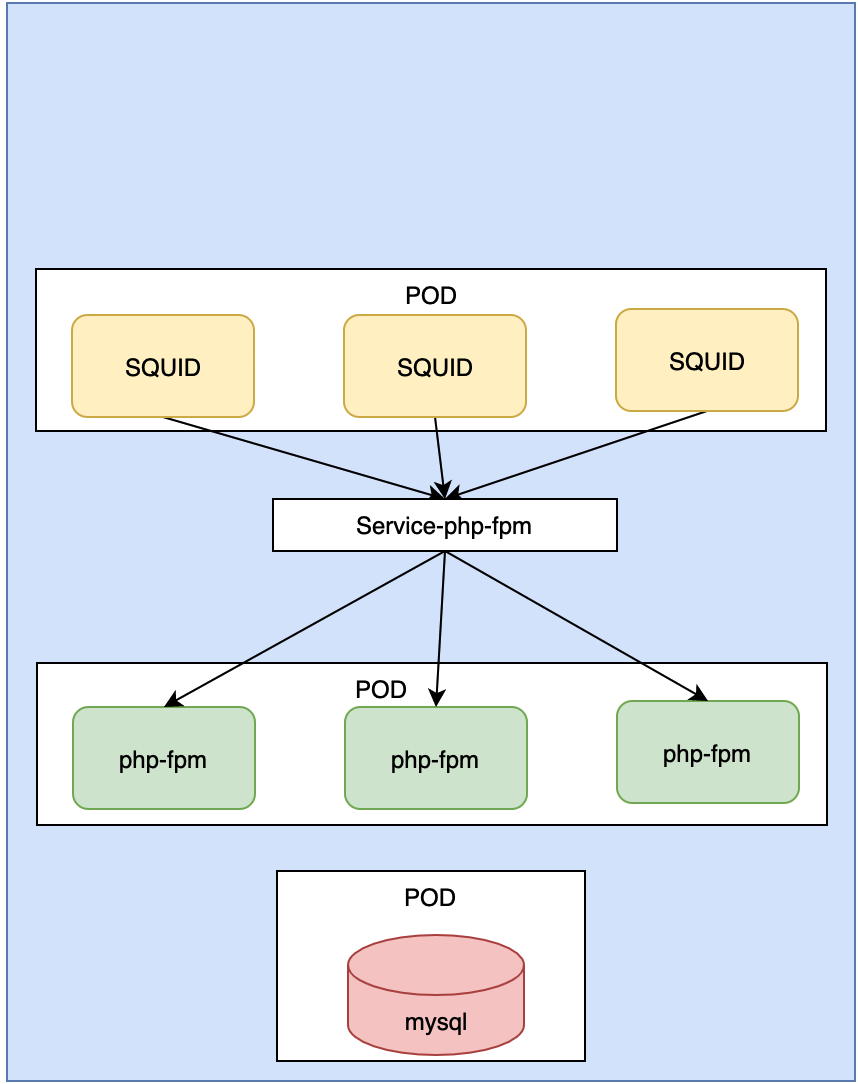
mysql也是一个pod, 我们要求mysql这个pod如果死了,重启, 他的ip地址和主机名是不能变的, 因此我们把它放到statefulSet中.
Kubernetes内部是一个扁平化的网络, 相互之间可以通过localhost请求访问, 所以, 关联关系如下:
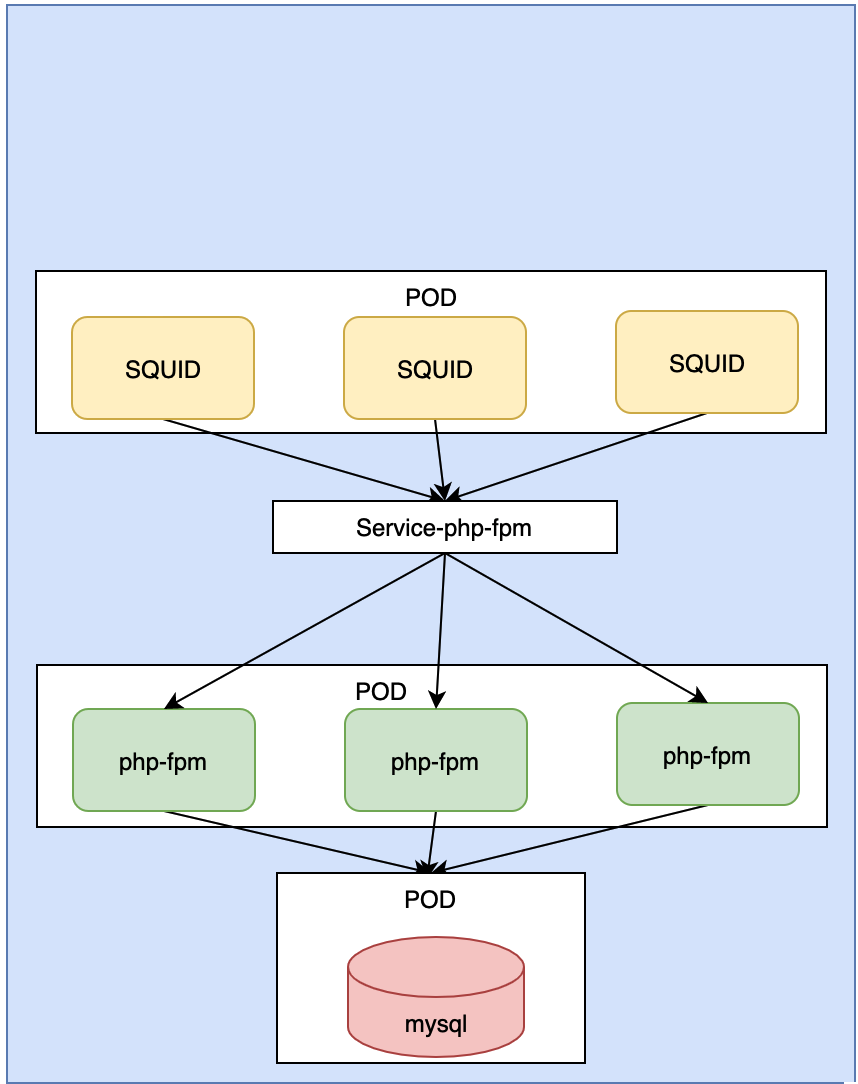
SQUID需要被外网访问, 因此, 我们在SQUID上也可以创建一个Service-SQUID
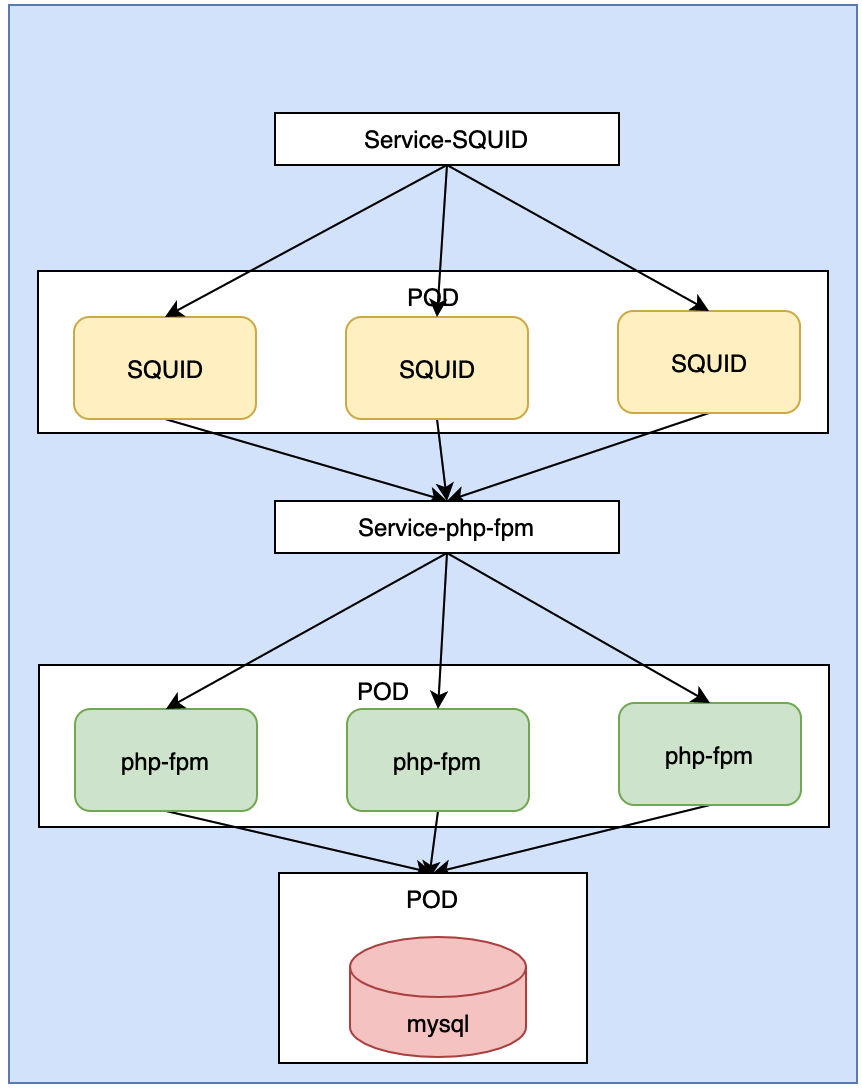
这样,我们就可以把这个架构完整的部署在k8s集群中了.
3.k8s核心概念的更多相关文章
- [转]k8s核心概念
转载自 https://blog.csdn.net/real_myth/article/details/78719244 什么是kubernetes 首先,他是一个全新的基于容器技术的分布式架构领先方 ...
- 从零开始入门 K8s| 阿里技术专家详解 K8s 核心概念
作者| 阿里巴巴资深技术专家.CNCF 9个 TCO 之一 李响 一.什么是 Kubernetes Kubernetes,从官方网站上可以看到,它是一个工业级的容器编排平台.Kubernetes 这个 ...
- 图解 K8s 核心概念和术语
我第一次接触容器编排调度工具是 Docker 自家的 Docker Swarm,主要解决当时公司内部业务项目部署繁琐的问题,我记得当时项目实现容器化之后,花在项目部署运维的时间大大减少了,当时觉得这玩 ...
- K8S核心概念之SVC(易混淆难理解知识点总结)
本文将结合实际工作当中遇到的一些问题和情况来解析SVC的作用以及一些比较易混淆和难理解的概念,方便日后工作用到或者遗忘时可以直接在自己曾经学习总结的博客当中直接查找到. 首先应该清楚SVC的作用是什么 ...
- K8s核心概念详解
kubernetes(通常简称为K8S),是一个用于管理在容器中运行的应用的容器编排工具. Kubernetes不仅有你所需要的用来支持复杂容器应用的所有东西,它还是市面上最方便开发和运维的框架. K ...
- 通过实例快速掌握k8s(Kubernetes)核心概念
容器技术是微服务技术的核心技术之一,并随着微服务的流行而迅速成为主流.Docker是容器技术的先驱和奠基者,它出现之后迅速占领市场,几乎成了容器的代名词.但它在开始的时候并没有很好地解决容器的集群问题 ...
- k8s核心资源之Pod概念&入门使用讲解(三)
目录 1. k8s核心资源之Pod 1.1 什么是Pod? 1.2 Pod如何管理多个容器? 1.3 Pod网络 1.4 Pod存储 1.5 Pod工作方式 1.5.1 自主式Pod 1.5.2 控制 ...
- kubernetes核心概念
摘抄自: https://www.cnblogs.com/zhenyuyaodidiao/p/6500720.html 1.基础架构 1.1 Master Master节点上面主要由四个模块组成:A ...
- Kubernetes 核心概念
什么是Kubernetes? Kubernetes(k8s)是自动化容器操作的开源平台,这些操作包括部署,调度和节点集群间扩展.如果你曾经用过Docker容器技术部署容器,那么可以将Docker看成K ...
随机推荐
- PowerShell 管道符之Where-Object的使用方法
1 Get-Process|Select-Object -Property Name|Where-Object{$_ -match 'QQ'} 可以匹配到QQ为名的结果
- linux 【阿里云服务器】 配置 redis 的正确流程
1.前言 我的域名备案前几天通过了,这篇随笔完整的记录 redis 的安装流程 与各种 问题 的 具体解决方案. 2.操作[跟着步骤来] (1)指令cd /usr/local 进入local文件夹里面 ...
- Eureka原理与架构
一.原理图 Eureka:就是服务注册中心(可以是一个集群),对外暴露自己的地址 提供者:启动后向Eureka注册自己信息(地址,提供什么服务) 消费者:向Eureka订阅服务,Eureka会将对应服 ...
- 还在用visio?这款画图工具才是真的绝!
最近有读者私信我,问我推文的配图是用什么工具画的,很好看,也想学习一下.今天就给大家介绍一下这款画图工具--Draw.io 概述 draw.io是一款免费的网页版画图工具(也有桌面版),支持流程图.U ...
- Keil MDK STM32系列(六) 基于抽象外设库HAL的ADC模数转换
Keil MDK STM32系列 Keil MDK STM32系列(一) 基于标准外设库SPL的STM32F103开发 Keil MDK STM32系列(二) 基于标准外设库SPL的STM32F401 ...
- Linux中的一些基本命令
文章目录 ls cd Linux的目录 文件的权限 1.用户,组,权限 2.文件的权限 文件的基本操作 增:创建文件 删:删除文件 改:修改文件 查:查看 vi/vim 是一个编辑工具,主要用来编辑文 ...
- SQL语句的分类:DQL、DML、DDL、DCL、TCL的含义和用途
MySQL中提供了很多关键字,将这些关键字 和 数据组合起来,就是常说的SQL语句,数据库上大部分的操作都是通过SQL语句来完成.日常工作中经常听到 DML.DDL语句这些名词,使用字母缩写来表达含义 ...
- python 线程池使用
传统多线程方案会使用"即时创建, 即时销毁"的策略.尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器将处于 ...
- 集合框架-Vector集合
1 package cn.itcast.p1.vector.demo; 2 3 import java.util.Enumeration; 4 import java.util.Iterator; 5 ...
- 2022年写的香橙派 OrangePi Zero 用python获取dht11温度和湿度
感谢网上资料和个人的不放弃,终于方便的解决了香橙派 OrangePi Zero用python获取dht11温湿度的问题. 网上关于香橙派的资料比起树莓派真是少之又少,现在香橙派zero能干的活暂时也只 ...