Local Relation Networks for Image Recognition
概
一种特殊的卷积?
主要内容
CNN通过许许多多的filters进行模式匹配(a pattern matching process), 非常低效, 本文提出利用局部相关性来替代这些卷积层.
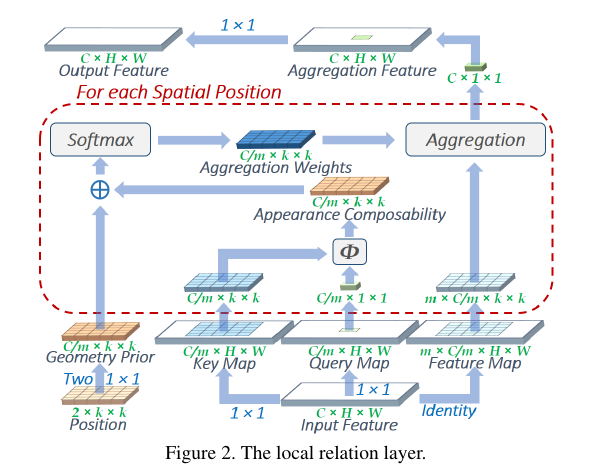
输入特征图\(X \in \mathbb{R}^{C \times H \times W}\);
特征图通过1x1的卷积(channel transformation layer)分别获得key map, query map, 二者的大小均为\(C/m \times H \times W\);
对于query map上的每一个点\(q_{p'}\), 计算其与kxk邻域内的点\(k_p\)间的relation:
\[w(p', p) = \mathrm{softmax}(\Phi(q_{p'}, k_p) + f_{\theta_g}(p - p')),
\]其中
\[\Phi(q_{p'}, k_p) = -(q_{p'}-k_q)^2,
\]\(f_{\theta_g}(p-p')\)是通过两层1x1卷积获得的\(C/m \times k \times k\), 反映了Geometry Prior, 实际上就是相对距离的度量.
注: 因为每个\(p\)都可以用\((h, w)\)来表示点的位置, 故途中的Position是两个通道的.
此时, 对于feature map中的任一点\(p\)都有了对应的\(w\), 通过此可以计算出一个对应的值, 于是可以得到\(C \times H \times W\)的新的特征图, 概特征图反应了点与其对应的kxk邻域内的点的相对关系. 需要注意的是, 图中是\(m \times C/m \times k \times k\)的形式呈现, 这是因为作者令每\(m\)个通道共享一个relation \(w\)(用于减少计算量), 等价于每个点会被作用\(C/ m\)个kernel, 故aggregation weights 是\(C/m\)个通道的.
最后, 再通过1x1的卷积将特征图转换为\(C'\times H \times W\)的输出, 图中应该是作者的笔误.
看起来整个网络的权重似乎很少啊, 都是1x1的卷积.
Local Relation Networks for Image Recognition的更多相关文章
- Paper Reading: Relation Networks for Object Detection
Relation Networks for Object Detection笔记 写在前面:关于这篇论文的背景知识,请参考我前面的两篇随笔(<关于目标检测>和<关于注意力机制> ...
- 【ML】Two-Stream Convolutional Networks for Action Recognition in Videos
Two-Stream Convolutional Networks for Action Recognition in Videos & Towards Good Practices for ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- Spatial-Temporal Relation Networks for Multi-Object Tracking
Spatial-Temporal Relation Networks for Multi-Object Tracking 2019-05-21 11:07:49 Paper: https://arxi ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
随机推荐
- 日常Java 2021/10/10
多态就是同一个行为具有多个不同表现形式的能力 多态就是同一个接口,使用不同的实例而执行不同操作 多态的优点 1.消除类型之间的耦合关系 2.可替换性 3.可扩充性 4.接口性 5.灵活性 6.简化性 ...
- 学习java 7.4
学习内容:遍历字符串要点:for(int i = 0;i < line.length();i++) { System.out.println(line.chatAt(i)); } 字符串拼接: ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 零基础学习java------38---------spring中关于通知类型的补充,springmvc,springmvc入门程序,访问保护资源,参数的绑定(简单数据类型,POJO,包装类),返回数据类型,三大组件,注解
一. 通知类型 spring aop通知(advice)分成五类: (1)前置通知[Before advice]:在连接点前面执行,前置通知不会影响连接点的执行,除非此处抛出异常. (2)正常返回通知 ...
- nodeJs,Express中间件是什么与常见中间件
中间件的功能和分类 中间件的本质就是一个函数,在收到请求和返回相应的过程中做一些我们想做的事情.Express文档中对它的作用是这么描述的: 执行任何代码.修改请求和响应对象.终结请求-响应循环.调用 ...
- 【leetcode】36. Valid Sudoku(判断能否是合法的数独puzzle)
Share Determine if a 9 x 9 Sudoku board is valid. Only the filled cells need to be validated accordi ...
- deque、queue和stack深度探索(下)
deque如何模拟连续空间?通过源码可以看到这个模型就是通过迭代器来完成. 迭代器通过重载操作符+,-,++,--,*和->来实现deque连续的假象,如上图中的 finish-start ,它 ...
- 【Android】修改快捷键,前一步默认是Ctrl + Z,修改后一步
我已经忘了,我什么时候已经习惯前一步是Ctrl + Z,后一步是Ctrl + Y Android Studio默认前一步快捷键是相同的,但是后一步就不是了 Ctrl + Y变成删除一行代码,就是下图D ...
- Output of C++ Program | Set 1
Predict the output of below C++ programs. Question 1 1 // Assume that integers take 4 bytes. 2 #incl ...
- Spring Cloud中,如何解决Feign整合Hystrix第一次请求失败的问题
Spring Cloud中,Feign和Ribbon在整合了Hystrix后,可能会出现首次调用失败的问题,要如何解决该问题呢? 造成该问题的原因 Hystrix默认的超时时间是1秒,如果超过这个时间 ...