Entropy Search for Information-Efficient Global Optimization
@article{hennig2012entropy,
title={Entropy search for information-efficient global optimization},
author={Hennig, Philipp and Schuler, Christian J},
journal={Journal of Machine Learning Research},
volume={13},
number={1},
pages={1809--1837},
year={2012}}
概
贝叶斯优化中的 Entropy Search (EI) 方法.
主要内容
这篇文章关注的是
\]
的问题, 且假设定义域\(I\)是有界的.
一般, 通过高斯过程定义\(f(x)\)的概率替代函数, 假设
y = f(x) + \epsilon, \: \epsilon \sim \mathcal{N}(0, \sigma^2).
\]
在已经观测到\(X = \{x_1, \ldots, x_T\}\)以及\(Y = \{y_1, \ldots, y_T\}\)的基础上, 我们可以求得\(f(x^*)\)的后验分布为以
\sigma_*^2(x^*)=k(x^*, x^*) - k(x^*, X)^T (k(X,X)+\sigma I)^{-1}k(x^*,X)
\]
为均值和方差的正态分布.
我们的目的是在已有这些条件的基础上, 寻找下一个(或多个)评估点.
定义:
p_{min}(x) =p[x = \arg \min f(x)] = \int_{ f:I \rightarrow R} p(f) \prod_{\tilde{x} \in I, \tilde{x} \not = x} \theta[f(\tilde{x})-f(x)] \mathrm{d}f,
\]
其中\(\theta(x) = 1, x\ge0, else \: 0\). \(\prod\)的部分在针对连续型的定义域时需要特别的定义. 显然(1)表示\(x\)为最小值点的概率.
再定义损失函数(当然损失函数不选择KL散度也是可以的, 但这是EI的名字的由来):
\mathcal{L}(p_{min}) = \mathcal{L}_{KL}(p_{min})=-\int_Ip_{min}(x) \log \frac{p_{min}(x)}{b(x)} \mathrm{d}x.
\]
当我们选择\(b(x)\)为\(I\)上的均匀分布的时候, 当我们最小化\(\mathcal{L}\)的时候, \(p_{min}\)会趋向Dirac分布(即某个点处的概率密度为无穷, 其余为0, 显然, 该点我们有足够的信心认为其是\(f(x)\)的最小值点).
但是这样还不够, 我们进一步关心其期望损失(最小化):
\langle \mathcal{L} \rangle_{x} = \int p(y|x) \mathcal{L}(p_{min} (\cdot|Y, X, y, x)) \mathrm{d}y.
\]
通过最小化(3),我们可以获得接下来的评估点.
接下来的问题是如果去估计.
\(p_{min}\)的估计
比较麻烦的是\(\prod\)的部分, 策略是挑选\(N\)个点\(\tilde{x} = \{\tilde{x}_1, \ldots, \tilde{x}_N\}\). 一种是简单粗暴的网格的方式, 但是这种方式往往需要较大的\(N\), 另一种是给定一个测度\(u\), 根据已有的观察\((X, Y)\), 通过\(u(X, Y)\)采样\(\tilde{x}\). 一个好的\(u\)应该在使得令损失能够产生较大变化的区域多采样点, 针对本文的情况 应该在\(p_{min}\)值比较高的地方多采样点.
文中给了俩种方法, 一种直接的方法是\(p_{min}\)可以用蒙特卡洛积分去逼近,
一下是我猜想的用MC积分的方式(文中未给出具体的形式)"
- 根据一定策略选取\(\tilde{x}\);
- 重复J次:
- 根据概率\(p(f)\)采样\(f(\tilde{x}), f(x)\),
- 计算\(\prod\)部分
- 取平均
作者选择的是 Expectation Propagation (EP)的方法, 这种方法能够估计出\(\tilde{x}_i, i=1,\ldots,N\)处的概率\(q_{min}(\tilde{x_i})\): \(f_{min}\)存在于以\(\tilde{x}_i\)为"中心"的一定范围内(文中用step)的概率. 当\(N\)足够的的时候, 这个step正比于\((Nu(\tilde{x}_i))^{-1}\), 则:
\]
这样我们就完成了\(p_{min}\)的估计, 一个更加好的性质是\(q_{min}\)关于\(\mu, \sigma_*\)的导数是有解析表达式的, 且\(Z_u\)是不必计算的(后续最小化过程中可以省略掉).
\(\mathcal{L}_{KL}\)的估计
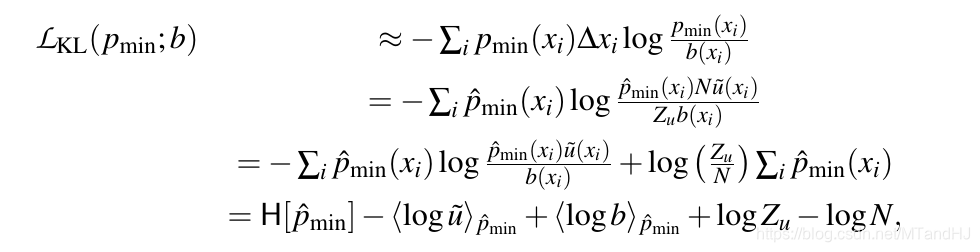
其中\(\hat{p}_{min}=q_{min}\).
\(\langle \Delta \mathcal{L} \rangle\)
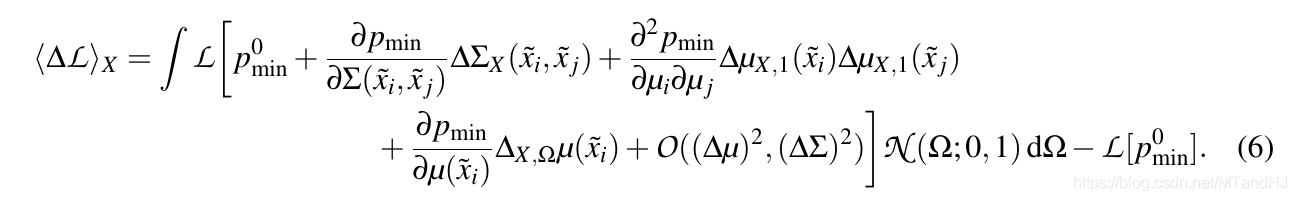
\(\arg \min_X \langle \mathcal{L} \rangle_X\) 用最小化一阶近似替代, 积分可以用MC积分逼近.
最后给出算法:

Entropy Search for Information-Efficient Global Optimization的更多相关文章
- 论文阅读 <Relocalization, Global Optimization and Map Merging for Monocular Visual-Inertial SLAM>
看了一下港科的基于vins拓展的论文<relocalization, global optimization and merging for vins>,在回环的实现部分总体没有什么变化, ...
- Entropy, relative entropy and mutual information
目录 Entropy Joint Entropy Conditional Entropy Chain rule Mutual Information Relative Entropy Chain Ru ...
- 论文笔记系列-Simple And Efficient Architecture Search For Neural Networks
摘要 本文提出了一种新方法,可以基于简单的爬山过程自动搜索性能良好的CNN架构,该算法运算符应用网络态射,然后通过余弦退火进行短期优化运行. 令人惊讶的是,这种简单的方法产生了有竞争力的结果,尽管只需 ...
- Community Cloud零基础学习(二)信誉等级设置 & Global Search设定
当我们创建了Community以后,我们需要对他进行定制页面来使community用户更好的使用.此篇主要描述两点,信誉等级设定以及Global Search 设定.其他的内容后期再慢慢描述. 一. ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
- state-of-the-art implementations related to visual recognition and search
http://rogerioferis.com/VisualRecognitionAndSearch2014/Resources.html Source Code Non-exhaustive lis ...
- First release of mlrMBO - the toolbox for (Bayesian) Black-Box Optimization
We are happy to finally announce the first release of mlrMBO on cran after a quite long development ...
- 贝叶斯优化(Bayesian Optimization)深入理解
目前在研究Automated Machine Learning,其中有一个子领域是实现网络超参数自动化搜索,而常见的搜索方法有Grid Search.Random Search以及贝叶斯优化搜索.前两 ...
- Information retrieval信息检索
https://en.wikipedia.org/wiki/Information_retrieval 信息检索 (一种信息技术) 信息检索(Information Retrieval)是指信息按一定 ...
随机推荐
- 学习java 7.8
学习内容: 被static修饰的不需要创建对象,直接用类名引用即可 内部类访问特点:内部类可以直接访问外部类的成员,包括私有 外部类访问内部类的成员,必须创建对象 成员内部类,内部类为私有,Outer ...
- javascript的原型与原型链
首先套用一句经典名言,JavaScript中万物皆对象. 但是对象又分为函数对象和普通对象. function f1(){}; var f2=function(){}; var f3=new Func ...
- Flink(三)【核心编程】
目录 一.Environment 二.Source 从集合读取数据 从文件读取数据 从kakfa读取数据(常用) 自定义数据源 三.Transform map Rich版本函数 flatMap key ...
- nodejs-CommonJS规范
JavaScript 标准参考教程(alpha) 草稿二:Node.js CommonJS规范 GitHub TOP CommonJS规范 来自<JavaScript 标准参考教程(alpha) ...
- 【STM32】使用DMA+SPI传输数据
DMA(Direct Memory Access):直接存储器访问 一些简单的动作,例如复制或发送,就可以不透过CPU,从而减轻CPU负担 由于本人使用的是正点原子开发板,部分代码取自里面的范例 本篇 ...
- C++ 德才论
输入样例: 14 60 80 10000001 64 90 10000002 90 60 10000011 85 80 10000003 85 80 10000004 80 85 10000005 8 ...
- 【Java】【学习】【监听器】Listener的学习的案例(窗体程序)
JavaWeb 监听器listener 学习与简单应用 Java窗体程序使用监听器 效果:点击按钮,控制台出现文字 代码如下 import javax.swing.*; import java.awt ...
- STL 较详尽总结
STL就是Standard Template Library,标准模板库.这可能是一个历史上最令人兴奋的工具的最无聊的术语.从根本上说,STL是一些"容器"的集合,这些" ...
- python之异步编程
一.异步编程概述 异步编程是一种并发编程的模式,其关注点是通过调度不同任务之间的执行和等待时间,通过减少处理器的闲置时间来达到减少整个程序的执行时间:异步编程跟同步编程模型最大的不同就是其任务的切换, ...
- msfvenom生成payload命令
msfvenom生成payload命令 windows: msfvenom -a x86 --platform Windows -p windows/meterpreter/reverse_tcp L ...