Chapter 3 Observational Studies
Hern\(\'{a}\)n M. and Robins J. Causal Inference: What If.
概
这一章主要讨论的是, 观测得到的数据(而非随机实验)在什么条件下可以视为是随机试验.
outcome predictors: 一些会导致\(Y\)发生的诱因
3.1
我们所考虑的\(A\)和实验中实际的采取的手段\(A\)是相一致的.
采取何种手段\(A\)仅仅与\(L\)有关(这里考虑, \(L, A, Y\)三个元素).
\(\mathrm{Pr}(A|L) > 0\), 即正定性.
下面是一点一点的分析这三个点的重要性.
3.2 Exchangeability
这个对应的是第二点, 即我们要探究是否\(A\)仅仅与\(L\)有关, 从而有可交换性:
\]
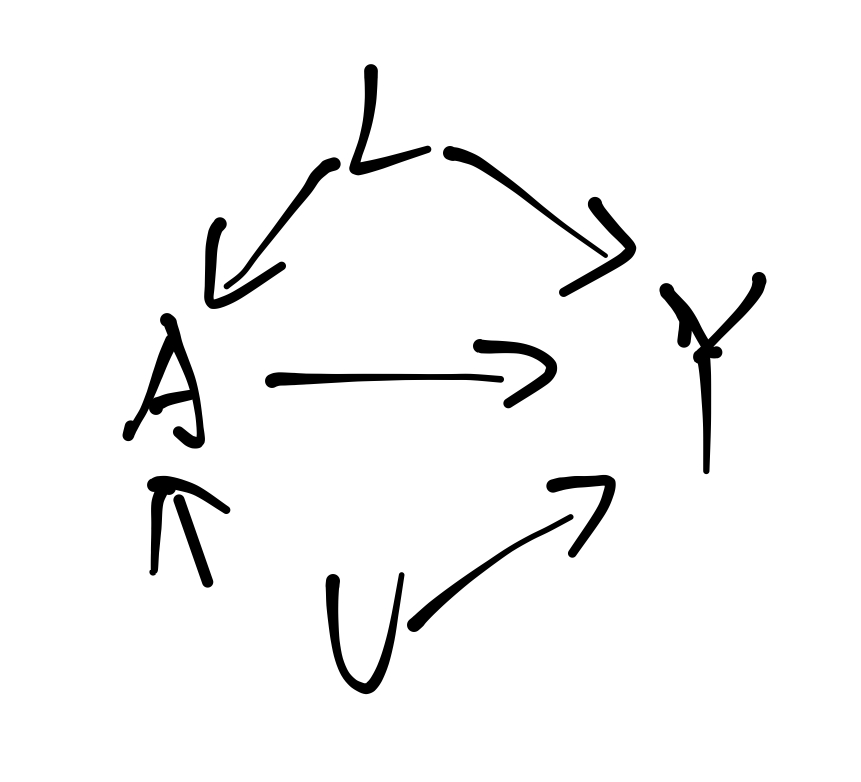
一旦遇到上面的情况, 往往就没有上述可交换性的保证了.
3.3 Positivity
设想\(L\)代表的是一个人是否吸烟, 倘若一个医生仅仅给不吸烟的人进行心脏迁移手术, 即
\]
则我们就完全丢失了这部分信息, 自然也没办法计算casual effect, 因为
\]
压根没有定义.
3.4 Consistency
一致性分类预期结果的一致性, 以及结果和观测数据的一致性
First
现在假设\(A \in \{0, 1\}\), 即代表是否进行心脏移植手术, 但是在实际中, \(A\)并非如此纯粹的0, 1.
实际上, 取决于器材, 外科医生的差别会衍生出不同版本的\(A\).
当然了, 这么讨论下去只会导致不可知论, 我们可以在某种程度上假设, 不过对\(A\)的描述越细致, 即越细分, 最后的结论也会更加精准.
Second
这个一致性, 用公式就是
\]
这个很重要, 因为我们在计算causal effect的时候有这么一步
\]
这个一致性, 个人的理解是, 我们所观察的\(A=a\)有很多版本, 可能与我们所希望的\(Y^a\)并不一致, 导致\(Y^a \not = Y\).
这里有一个微妙的东西, 实在是不知道如何描述了.
Fine Point
3.1 Identifiability of causal effects
指, 倘若不是随机实验, 我们需要一些额外的假设来得以计算causal effect.
3.2 Crossover randomized experiments
p32
这个讨论的是在不同的时间点\(t=0, t=1\).
3.3 Possible worlds
p35
3.4 Attributable fraction
p38
Technical Point
3.1 Positivity for standardization and IP weighting
p32
上一章讲了利用standardization 和 IP weighting 在条件可交换的假定下, 我们可以计算causal effect.
但是, 实际上这同时是需要positivity的假定的.
standardization:
\]
这个式子需要\(\mathbb{E}[Y|A=a, L=l]\), 但是这个在某些\(P(A=a|L=l)=0\)的情况下是没有定义的.
另一方面, IP weighting
\]
其中\(Q(a) = \{l; \mathrm{Pr} (A=a|L=l)>0\}\).
相当于, 认为地目标的集合缩小了.
里头还说, 上述的与
\]
不同, 而且说后者是undefined的, 可是后决定后者才是等价于上面所说的啊.
不过我倒是觉得无所谓的, 毕竟我们应该关心我们所关心的, 限定在\(f(a|L)\not = 0\)才是合适的区域.
3.2 Cheating consistency
p40
Chapter 3 Observational Studies的更多相关文章
- descriptive statistics|inferential statistics|Observational Studies| Designed Experiments
descriptive statistics:组织和总结信息,为自身(可以是population也可以是sample)审视和探索, inferential statistics.从sample中推论p ...
- Weighted Effect Coding: Dummy coding when size matters
If your regression model contains a categorical predictor variable, you commonly test the significan ...
- hbase官方文档(转)
FROM:http://www.just4e.com/hbase.html Apache HBase™ 参考指南 HBase 官方文档中文版 Copyright © 2012 Apache Soft ...
- HBase官方文档
HBase官方文档 目录 序 1. 入门 1.1. 介绍 1.2. 快速开始 2. Apache HBase (TM)配置 2.1. 基础条件 2.2. HBase 运行模式: 独立和分布式 2.3. ...
- 【统计】Causal Inference
[统计]Causal Inference 原文传送门 http://www.stat.cmu.edu/~larry/=sml/Causation.pdf 过程 一.Prediction 和 causa ...
- Propensity Scores
目录 基本的概念 重要的结果 应用 Propensity Score Matching Stratification on the Propensity Score Inverse Probabili ...
- R数据分析:样本量计算的底层逻辑与实操,pwr包
样本量问题真的是好多人的老大难,是很多同学科研入门第一个拦路虎,今天给本科同学改大创标书又遇到这个问题,我想想不止是本科生对这个问题不会,很多同学从上研究生到最后脱离科研估计也没能把这个问题弄得很明白 ...
- Modern C++ CHAPTER 2(读书笔记)
CHAPTER 2 Recipe 2-1. Initializing Variables Recipe 2-2. Initializing Objects with Initializer Lists ...
- Android Programming: Pushing the Limits -- Chapter 7:Android IPC -- ApiWrapper
前面两片文章讲解了通过AIDL和Messenger两种方式实现Android IPC.而本文所讲的并不是第三种IPC方式,而是对前面两种方式进行封装,这样我们就不用直接把Aidl文件,java文件拷贝 ...
随机推荐
- 我好像发现了一个Go的Bug?
从一次重构说起 这事儿还得从一次重构优化说起. 最近在重构一个路由功能,由于路由比较复杂,需求变化也多,于是想通过责任链模式来重构,刚好这段时间也在 Sentinel-Go 中看到相关源码. 用责任链 ...
- 【leetcode】1293 .Shortest Path in a Grid with Obstacles
You are given an m x n integer matrix grid where each cell is either 0 (empty) or 1 (obstacle). You ...
- Camera、音频录制与Vitamio框架
一.Camera 1.概述 Android框架包含了各种相机哥相机功能的支持,是你可以在应用中捕获图像和视频. 在应用能使用设备上的相机之前,先想一想将来会如何使用此硬件: (1)Camera 应该 ...
- Spring Batch(8) -- Listeners
September 29, 2020 by Ayoosh Sharma In this article, we will take a deep dive into different types o ...
- NoSQL之Redis学习笔记
一.NoSQL与Redis 1.什么是NoSQL? NoSQL=Not Only SQL ,泛指非关系型数据库.随着互联网的兴起,传统的关系型数据库已经暴露了很多问题,NoSQL数据库的产生就是为了解 ...
- Ajax请求($.ajax()为例)中data属性传参数的形式
首先定义一个form表单: <form id="login" > <input name="user" type="text&quo ...
- 背包问题-C语言实现
转自:http://blog.csdn.net/tjyyyangyi/article/details/7929665 0-1背包问题 参考: http://blog.csdn.net/liwenjia ...
- RabbitMQ,RocketMQ,Kafka 消息模型对比分析
消息模型 消息队列的演进 消息队列模型 发布订阅模型 RabbitMQ的消息模型 交换器的类型 direct topic fanout headers Kafka的消息模型 RocketMQ的消息模型 ...
- Windows 任务计划部署 .Net 控制台程序
Windows 搜索:任务计划程序 创建任务 添加任务名称 设置触发器:这里设置每10分钟执行一次 保存之后显示 此任务会从每天的 0:10:00 执行第一次后一直循环下去. 在操作选项卡下,选择启动 ...
- java 输入输出IO流:标准输入/输出System.in;System.out;System.err;【重定向输入System.setIn(FileinputStream);输出System.setOut(printStream);】
Java的标准输入输出分别通过System.in和System.out来代表的,在默认情况下它分别代表键盘和显示器,当程序通过System.in来获取输入时,实际上是从键盘读取输入 当程序试图通过 S ...