AutoAssign源码分析
AutoAssign源码分析
一. 简介
关于动机和发展流程,原作者已经在知乎说的非常清楚,主要解决的问题总结如下:
- 联合各个loss(cls、reg、obj),这里前人已经做过很多
- 去除了centerness,这个东西非常难训练
- 去除了预定义的anchor匹配策略
- 去除FCOS类的不同FPN层解决不同尺度目标
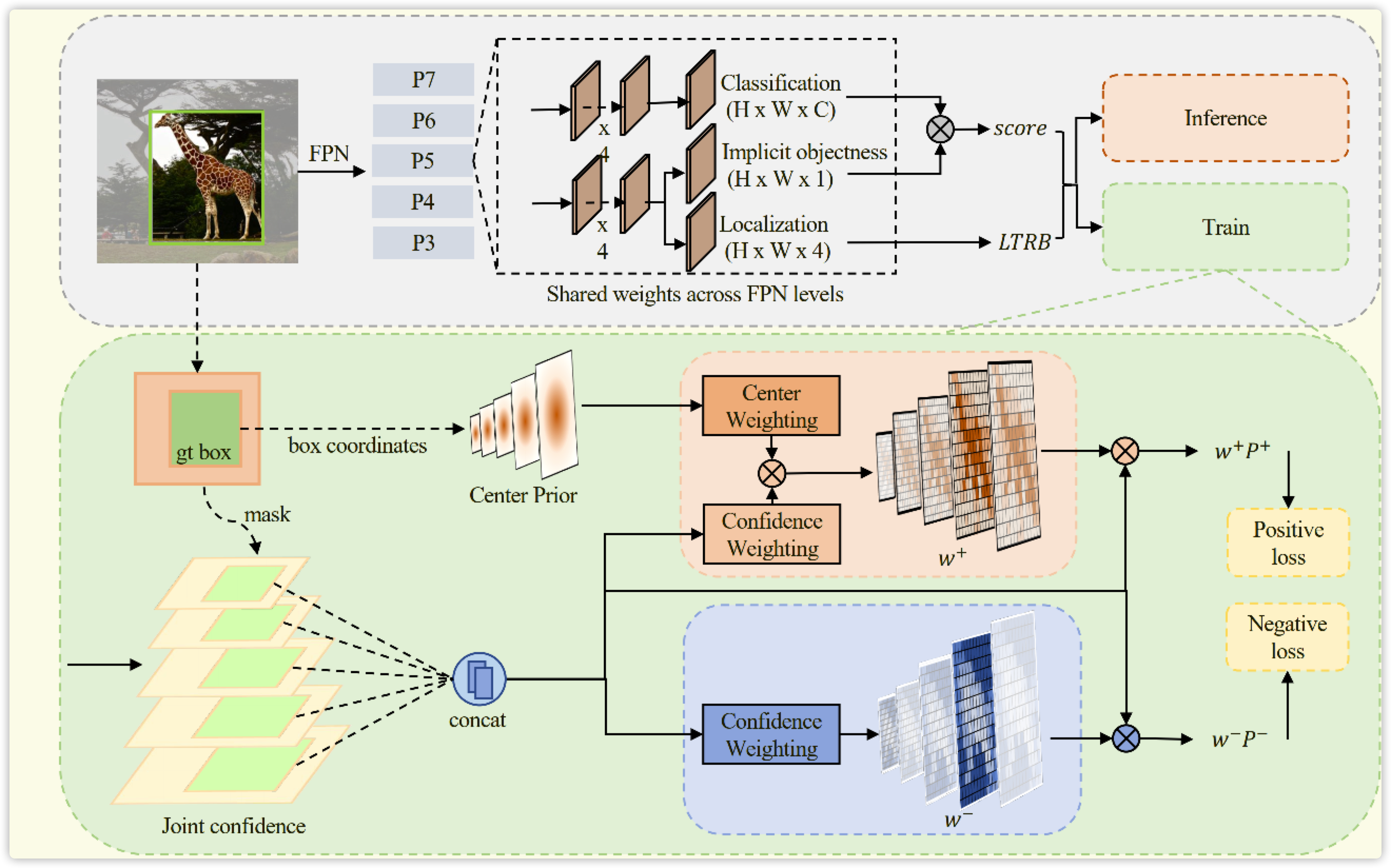
二. 论文理论
2.1 联合表示
为何进行联合表示?由于论文核心就是使用权重一词,而权重关系到 \(cls、reg、obj\) 等值大小,最后始终加权到一起。
论文引入 \(obj\) 参数(和YOLO的前背景类似,区别于centerness),未进行实际的监督,但效果在此处出奇的好,效果如下图所示。类似于一个 \(FCOS \ \ Scale\) 和一些不确定度论文的操作,直接获取一个可学习的 \(Weight\) 和目标进行相关操作。具体为何好,作者未给出实际的理论依据:
首先将 \(cls\) 和 \(obj\) 相乘进行融合,如下公式所示。注意:此处的 \(obj\) 是一个数,比如 \(batch=2,num_{cls}=80,anchor=100\) ,那么分类的结果为 \(2 \times100 \times 80\) ,但是 \(obj=2\times100\times1\) 。因为其表示的意思是:此 \(anchor\) 是前景还是背景。而具体的类别和置信度,全靠 \(cls\) 进行判断。
\]
然后将 \(reg、cls\) 进一步联合表示,其中 \(L^{loc}\) 是计算的 \(IOU、GIOU、DIOU\) 结果,\(L^{cls}\) 是正样本的交叉熵 \(loss\) 。这也就和上面公式(1)对应起来,这里计算的都是正样本(此处表示GT内的anchor) \(loss\).
\]
2.2 正样本权重
这里需要额外补充一点:GT内部的anchor包括正负样本,而GT外部肯定是负样本,这相当于人的先验。
2.1节中 \(L_i(\theta)\) 表示 \(Loss\) ,而内部的值 \(P_i(\theta)\) 就表示某个anchor为正样本的概率值,这个参考交叉熵正样本分类loss公式即可。所以 \(P_i(\theta)=P_i^{+}\) 也就是正样本的概率值(正样本的权重),下式(2)直接进行一个指数变换,相当于放大了正样本的置信度(概率=置信度),同时使用一个超参数进行调节放大倍数,这里其实没有太多其它意义。
\]
\(G(d_i)\) 表示高斯权重,包括四组可学习参数: \(\mu->(x,y)\ 、\ \sigma->(x,y)\) ,每个种类四个参数,COCO数据集共 \(\sigma=80\times2,\mu=80\times2\). 那么公式(3)就很容易理解了,乘以权重以后取平均。 其中可学习参数最重要的作用是防止初始化过拟合(参考了李翔知乎),如果没有高斯可学习参数,那么和正常anchor回归区别不大,假设A,B,C三个anchor,其中初始权重A>B>C,那么在下一轮的训练中依然是A>B>C,N轮之后A>>B>>C。这是一种强者越强的学习方式,完全陷入了和初始化息息相关的问题上了。而可学习的gaussian参数使得中心权重偏大,即使中心anchor初始化较差,后面也能慢慢学习加强,而偏远anchor会越来越差。
\]
正样本的Loss组成包括:\(cls、reg、obj\) ,发现上面的公式全部都已包含,直观上上理解是正确的。
2.3 负样本权重
负样本 \(loss\) 仅包含 \(cls、obj\) ,但是会参考 \(reg\) 的结果。前者不用多说,后者为什么会参考 \(reg\) 的值?因为回归的越好,是负样本的概率越低,正样本的loss会把正样本的 \(reg\) 学习的很好,而负样本的 \(reg\) 一直不学习就渐渐没落了。
\]
\]
负样本包含两个部分,在GT框之外的点全部都是负样本,在GT框之内的点IOU匹配度较差的点。GT框内点匹配度越差,那么负样本的权重越高,如上式(5)(6)所示。权重再乘以 \(\mathcal{P}_{i}(\operatorname{cls} \mid \theta)\) 就得到负样本的loss。
2.4 总的loss
按照2.3和2.4节的推导,很容易得出下式(6)的公式。但是正样本loss中的 \(\sum\) 有点不对称,按公式log完全可以拿到公式里面乘。按照李翔知乎里面说的,防止log的值太大无法收敛,这个地方笔者也没完全理解。
\]
2.5 补充loss
看代码还有一个要点,每个GT框内anchor正样本权重gaussian-map得进行normlize,目的是让gaussian分布在anchor内部。
gaussian_norm_losses.append(
len(gt_instances_per_image) / normal_probs[foreground_idxs].sum().clamp_(1e-12)) # gt数量/全部gaussian权重
'''
......
'''
loss_norm = torch.stack(gaussian_norm_losses).mean() * (1 - self.focal_loss_alpha) # 期望让每个gt内的权重之和等于1(归一化过后容易学习)
三. 论文代码
注释代码地址:https://github.com/www516717402/AutoAssign
论文说的云里雾里,其实代码很简单,论文idea很好。
四. 总结
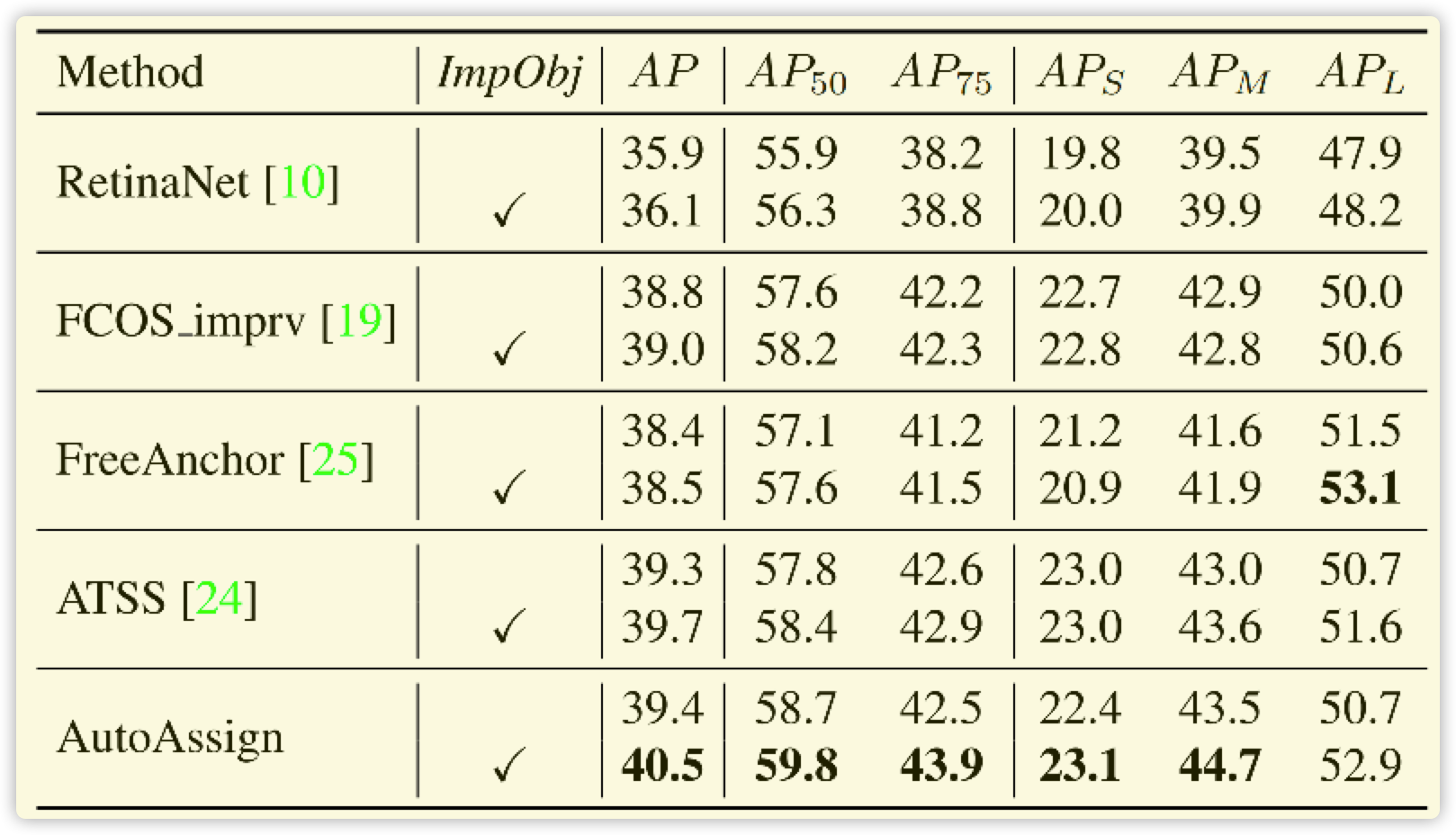
- 此论文肯定下了一番大功夫,细节地方挺多,比如公式(2),再比如加上 \(obj\) 参数。这些东西正常处理都不会加上,因为这篇论文核心就是去掉繁琐的操作,为什么还加上这个操作?那么答案肯定对此论文结果影响很大,论文图表已经证明这个猜想。
- 实际应用有点难推广
- 首先精度没有提升一个档次
- 论文中还是有很多提升细节不明朗
- 前向计算直接使用 \(obj\) 感觉有点不妥,没有直接进行监督有点后怕。。。
- 仅仅有一套gaussian参数(很多人质疑这一点,甜甜圈那种类型的结果如何?)
- 。。。
五. 参考
AutoAssign源码分析的更多相关文章
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- nginx源码分析之网络初始化
nginx作为一个高性能的HTTP服务器,网络的处理是其核心,了解网络的初始化有助于加深对nginx网络处理的了解,本文主要通过nginx的源代码来分析其网络初始化. 从配置文件中读取初始化信息 与网 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- java使用websocket,并且获取HttpSession,源码分析
转载请在页首注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6238826.html 一:本文使用范围 此文不仅仅局限于spring boot,普通的sprin ...
- ABP源码分析二:ABP中配置的注册和初始化
一般来说,ASP.NET Web应用程序的第一个执行的方法是Global.asax下定义的Start方法.执行这个方法前HttpApplication 实例必须存在,也就是说其构造函数的执行必然是完成 ...
- ABP源码分析三:ABP Module
Abp是一种基于模块化设计的思想构建的.开发人员可以将自定义的功能以模块(module)的形式集成到ABP中.具体的功能都可以设计成一个单独的Module.Abp底层框架提供便捷的方法集成每个Modu ...
随机推荐
- js in depth: Object & Function & prototype & __proto__ & constructor & classes inherit
js in depth: Object & Function & prototype & proto & constructor & classes inher ...
- dart2native 使用Dart 在macOS,Windows或Linux上创建命令行工具
下载dart2.6以上 >dart2native --help 编写源文件 // bin\main.dart main(List<String> args) { print('hel ...
- PAA房产智慧社区:解决社区管理服务的痛点难点
社区,是社交与生活的舞台,更是家的延伸.社区之所有能够有所创新发展,得益于借助数字化和智能化.智能化给社区带来的便利体现在社区门禁可以人脸识别:AI的摄像头可以自动捕获异常的现象,便于社区管理员第一时 ...
- [转]Ubuntu16 压缩解压文件命令
原文地址:http://blog.csdn.net/feibendexiaoma/article/details/73739279,转载主要方便随时查阅,如有版权要求,请及时联系. ZIP zip是比 ...
- rabbitMQ高可用方案
普通模式 默认的集群模式,以两个节点(rabbit01.rabbit02)为例来进行说明.对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和r ...
- halo博客安装教程,一款优秀的java开源博客系统
整理了一下,决定用宝塔来管理反代和ssl自动续签,这样比较适合小白. 前置要求 会ssh远程连接.域名已经解析到服务器ip上即可, 安装步骤 按照下面一步一步来,应该是木有问题的哦 ssh连接好,依次 ...
- 1100 Mars Numbers——PAT甲级真题
1100 Mars Numbers People on Mars count their numbers with base 13: Zero on Earth is called "tre ...
- 第43天学习打卡(JVM探究)
JVM探究 请你谈谈你对JVM的理解?Java8虚拟机和之前的变化更新? 什么是OOM,什么是栈溢出StackOverFlowError? 怎么分析? JVM的常用调优参数有哪些? 内存快照如何抓取, ...
- 多Excel文件内容查询工具。
多Excel文件内容查询工具. 告别繁琐重复的体力劳动,一分钟干完一天的活. 码云 github 下载 当需要在多个Excel表格中查询需要的信息是,一个文件一个文件的去查询非常麻烦. 虽然有其他方法 ...
- API版本管理中的沟通问题
转: API版本管理中的沟通问题 产品升级会涉及API的更改,当API改动较大时,最大的问题是如何通知API的使用者(内部人员与使用OPENAPI 的用户),我们不能强迫所有用户立即对API的更改做出 ...