Redis-技术专区-帮从底层彻底吃透AOF技术原理
AOF持久化方式
AOF持久化方式是将redis的操作日志以追加的方式写入磁盘文件中。AOF持久化是以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
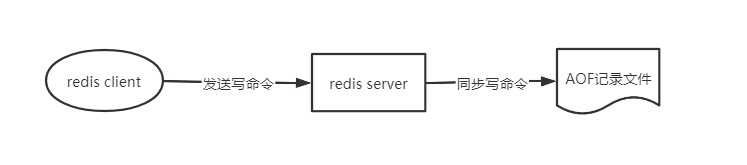
AOF实现方式
- AOF(append only file)持久化是以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。
- AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
AOF优势
该机制可以带来更高的数据安全性,即数据持久性。
Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。
每秒同步:事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。
每次修改:而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。
不同步:可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。
如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
如果日志过大,Redis可以自动启用rewrite机制,压缩和瘦身相关的aof文件。
Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个临时的新文件用于记录此期间有哪些修改命令被执行。
因此在进行rewrite切换时可以更好的保证数据安全性。
AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
AOF命令写入
AOF命令写入的内容直接是文本协议格式。AOF文件是纯文本文件,其内容正是Redis客户端向Redis发送的原始通信协议的内容。
例如:set hello world 这条命令,在AOF缓冲区会追加如下文本:
$3
set
$5
hello
$5
world
- $3 : set指令的长度。set长度 == 3
- set:代表着set指令
- $5:hello key对应的值长度
- hello:key值
- $5:world value对应的值长度
- world:value值
AOF为什么直接采用文本协议格式?可能的理由如下:
- 文本协议具有很好的兼容性。
- 开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免二次处理开销。 - 文本协议具有可读性,方便直接修改和处理。
- 文本协议具有很好的兼容性。
AOF为什么把命令追加到aof_buf中?
- Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。
- 先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
AOF配置
在redis的redis.conf配置文件中:
打开文件,找到 APPEND ONLY MODE 对应内容,默认情况下Redis没有开启AOF(append only file)方式的持久化,通过appendonly参数开启:
- AOF文件的保存位置和RDB文件的位置相同
都是通过dir参数设置的
dir /path
- redis 默认关闭,开启需要手动把no改为yes
appendonly yes
- 指定本地数据库文件名,默认值为 appendonly.aof
appendfilename "appendonly.aof"
Redis支持三种不同的刷写模式,Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制:
每次有数据修改发生时都写入AOF文件中
- 每次收到写命令就立即强制写入磁盘,是最有保证的完全的持久化,但速度也是最慢的,一般不推荐使用
appendfsync always
- 在一般的STAT硬盘上,Redis只能支持大约几百TPS写入,这是最安全也是最慢的方式,显然跟Redis高性能特性背道而驰,不建议配置。
每秒中同步一次,将过去一秒内发生的数据修改写入AOF文件中
- 每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,是受推荐的方式。
appendfsync everysec
- 是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性,理论上只有在系统突然宕机的情况下丢失1s的数据。(严格来说最多丢失1s数据是不准确)
不主动同步,高效但是数据不持久化,由操作系统来决定
- 完全依赖OS的写入,一般为30秒左右一次,性能最好但是持久化最没有保证,不被推荐。
appendfsync no
- 由于操作系统每次同步AOF文件的周期,(即每30秒一次),而且会极大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
Redis服务的AOF文件同步策略:
- always (最安全但是最慢) :同步持久化,每次发生数据变化会立刻写入到磁盘中。性能较差当数据完整性比较好(慢,安全)
- everysec (默认的同步策略):出厂默认推荐,每秒异步记录一次(默认值)
- no (最快但是不安全):不同步
当进程中BGSAVE或BGREWRITEAOF命令正在执行时不阻止主进程中的fsync()调用(默认为no,当存在延迟问题时需调整为yes).
no-appendfsync-on-rewrite no
虽然每次执行更改数据库内容的操作时,AOF都会将命令记录在AOF文件中,但是事实上,由于操作系统的缓存机制,数据并没有真正地写入硬盘,而是进入了系统的硬盘缓存。在默认情况下系统每30秒会执行一次同步操作,以便将硬盘缓存中的内容真正地 写入硬盘,在这30秒的过程中如果系统异常退出则会导致硬盘缓存中的数据丢失。一般来讲启用AOF持久化的应用都无法容忍这样的损失,这就需要Redis在写入AOF文件后主动要求系统将缓存内容同步到硬盘中。
AOF重写机制
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制压缩文件体积。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
AOF重写原理
重写后的AOF文件为什么可以变小?有如下原因:
- 进程内已经超时的数据不再写文件。
- 旧的AOF文件含有无效命令,如del key1、set a 111、set a 222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
- 多条写命令可以合并为一个,如lpush list a、lpush list b、 lpush list c 可以转化为:lpush list a b c。
为了防止合并的数据过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型,以64个元素为界拆分为多条。
AOF重写原理
AOF的工作原理是将写操作追加到文件中,文件的冗余内容会越来越多。所以聪明的 Redis 新增了重写机制。当AOF文件的大小超过所设定的阈值时,Redis就会对AOF文件的内容压缩。
Redis 会fork出一条新进程,读取内存中的数据,并重新写到一个临时文件中。并没有读取旧文件。最后替换旧的aof文件。
需要压缩重写的案例:
AOF带来了另一个问题,持久化文件会变得越来越大。比如,我们调用INCR test命令100次,文件中就必须保存全部的100条命令,但其实99条都是多余的。
- 因为要恢复数据库的状态其实文件中保存一条SET test 100就够了。
为了合并重写AOF的持久化文件,Redis提供了bgrewriteaof命令。收到此命令后,Redis将使用与快照类似的方式将内存中的数据以命令的方式保存到临时文件中,最后替换原来的文件,以此来实现控制AOF文件的合并重写(会将重写过程中接收的的新的指令和生成新的重写后AOF文件中的指令进行合并)。
注意:由于是模拟快照的过程,因此在重写AOF文件时并没有读取旧的AOF文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的AOF文件
AOF重写目的
- AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF文件可以更快地被Redis加载。
AOF重写过程可以手动触发和自动触发:
- 配置重写rewrite触发机制
- 手动触发:直接调用bgrewriteaof命令
- 自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机
- auto-aof-rewrite-min-size: 限制了允许重写的最小AOF文件,通常在AOF文件很小的时候即使其中有些冗余命令也可是可以忽略的。
- auto-aof-rewrite-percentage: 当前的AOF文件大小超过上一次重写的AOF文件大小的百分之多少时会再次进行重写,如果之前没有重写过,则以启动时的AOF大小为依据。
注意,执行AOF重写请求时,父进程依然响应命令,Redis使用"AOF重写缓冲区"保存这部分新数据,防止新AOF文件生成期间丢失这部分数据。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
解释含义:当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。一般都设置为3G,64M太小了, 这里的“一倍”和“64M” 可以通过配置文件修改。
AOF与RDB二者选择的标准(结合上一篇文章)
权衡的标准是对数据的一致性要求和性能之间的平衡。看系统是愿意牺牲一些性能,换取更高的缓存一致性(AOF),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(RDB)。
AOF的执行流程
开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。
AOF的工作流程操作有:
- 命令写入(append)
- 文件同步(sync)
- 文件重写(rewrite)
- 重启加载(load)
AOF流程如下:
- 所有的写入命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务重启时,可以加载AOF文件进行数据恢复。
AOF重启加载
AOF和RDB文件都可以用于服务器重启时的数据恢复。
AOF持久化开启且存在AOF文件时,优先加载AOF文件;
AOF关闭或者AOF文件不存在时,加载RDB文件;
加载AOF/RDB文件城后,Redis启动成功;
AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
根据AOF文件恢复数据
正常情况下,将appendonly.aof 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。但在实际开发中,可能因为某些原因导致appendonly.aof 文件格式异常,从而导致数据还原失败,可以通过命令redis-check-aof --fix appendonly.aof 进行修复 。从下面的操作演示中体会。
若打算使用Redis 的持久化。建议RDB和AOF都开启。其实RDB更适合做数据的备份,
留一后手。AOF出问题了,还有RDB。
AOF 的优缺点
AOF 优点
数据的完整性和一致性更高
AOF劣势
相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB在恢复大数据集时的速度比 AOF 的恢复速度要快。
同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
数据的完整性和一致性更高因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢。
对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
总结
每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
- AOF 的数据完整性比RDB高,但记录内容多了,会影响数据恢复的效率。
- RDB与AOF二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。
- Redis允许同时开启AOF和RDB,既保证了数据安全又使得进行备份等操作十分容易。此时重新启动Redis后Redis会使用AOF文件来恢复数据,因为AOF方式的持久化可能丢失的数据更少。
- 若只打算用Redis 做缓存,可以关闭持久化。
Redis-技术专区-帮从底层彻底吃透AOF技术原理的更多相关文章
- Redis-技术专区-帮从底层彻底吃透RDB技术原理
每日一句 低头是一种能力,它不是自卑,也不是怯弱,它是清醒中的嬗变.有时,稍微低一下头,或者我们的人生路会更精彩. 前提概要 Redis是一个的键-值(K-V)对的内存数据库服务,通常包含了任意个非空 ...
- redis 知识点收集 注意理解底层
学redis,首先要明白其特性,其次要理解明白redis与操作系统底层的关系,这点很重要.这是一个优秀的学习方法,作为计算机专业,应当时刻想着技术和操作系统计算机组成数据结构的联系,听起来有些书生气死 ...
- 《闲扯Redis五》List数据类型底层之quicklist
一.前言 Redis 提供了5种数据类型:String(字符串).Hash(哈希).List(列表).Set(集合).Zset(有序集合),理解每种数据类型的特点对于redis的开发和运维非常重要. ...
- ASP.NET跨平台、分布式技术架构技术栈概览 (迄今为止最全的.NET技术栈)
今天有个学技术的小兄弟问我,现在这么多的技术我要学哪个?我说你根据岗位来学,学好了哪一门都可以在社会上立足,如今已经早已不是我们当年学习IT时候那么单纯了,给他讲了很多,发现现在的技术栈变得层次复杂且 ...
- AOP技术介绍--(.Net平台AOP技术研究)
4.1.Net平台AOP技术概览 .Net平台与Java平台相比,由于它至今在服务端仍不具备与unix系统的兼容性,也不具备类似于Java平台下J2EE这样的企业级容器,使得.Net平台在大型的企业级 ...
- Redis提供的持久化机制(RDB和AOF)
Redis提供的持久化机制 Redis是一种面向"key-value"类型数据的分布式NoSQL数据库系统,具有高性能.持久存储.适应高并发应用场景等优势.它虽然起步较晚,但发展却 ...
- P2P技术详解(一):NAT详解——详细原理、P2P简介
1. IPv4协议和NAT的由来 今天,无数快乐的互联网用户在尽情享受Internet带来的乐趣.他们浏览新闻,搜索资料,下载软件,广交新朋,分享信息,甚至于足不出户获取一切日用所需.企业利用互联网发 ...
- Excel阅读模式/聚光灯开发技术序列作品之三 高级自定义任务窗格开发原理简述—— 隐鹤
Excel阅读模式/聚光灯开发技术序列作品之三 高级自定义任务窗格开发原理简述—— 隐鹤 1. 引言 Excel任务窗格是一个可以用来存放各种常用命令的侧边窗口(准确的说是一个可以停靠在类名为x ...
- Excel阅读模式/聚光灯开发技术之二 超级逐步录入提示功能开发原理简述—— 隐鹤 / HelloWorld
Excel阅读模式/聚光灯开发技术之二 超级逐步录入提示功能开发原理简述———— 隐鹤 / HelloWorld 1. 引言 自本人第一篇博文“Excel阅读模式/单元格行列指示/聚光灯开发技术要 ...
随机推荐
- Python - 浅拷贝的四种实现方式
浅拷贝详解 https://www.cnblogs.com/poloyy/p/15084277.html 方式一:使用切片 [:] 列表 # 浅拷贝 [:] old_list = [1, 2, [3, ...
- 【JavaWeb】EL表达式&过滤器&监听器
EL表达式和JSTL EL表达式 EL表达式概述 基本概念 EL表达式,全称是Expression Language.意为表达式语言.它是Servlet规范中的一部分,是JSP2.0规范加入的内容.其 ...
- Spring Cloud分区发布实践(6)--灰度服务-根据Header选择实例区域
此文是一个完整的例子, 包含可运行起来的源码. 此例子包含以下部分: 网关层实现自定义LoadBalancer, 根据Header选取实例 服务中的Feign使用拦截器, 读取Header Feign ...
- PHP-Audit-Labs-Day2 - filter_var函数缺陷
目录 分析 示例 payload 修复建议 Day02-CTF题解 参考链接 分析 先看源码 // composer require "twig/twig" require 've ...
- Salesforce Integration 概览(六) UI Update Based on Data Changes(UI自动更新基于数据变更)
Salesforce用户界面必须由于Salesforce数据的更改而自动更新.这个场景其实在我所经历的项目中用到的不是特别多,因为客户可能直接点击刷新按钮就直接看到了最新的数据,而不是那种一直不刷新然 ...
- Skywalking-06:OAL基础
OAL 基础知识 基本介绍 OAL(Observability Analysis Language) 是一门用来分析流式数据的语言. 因为 OAL 聚焦于度量 Service . Service In ...
- Java 在PPT中插入OLE对象
PPT幻灯片中支持将文档作为OLE对象插入到PPT幻灯片指定位置,在幻灯片中可直接点击该对象,打开或编辑等.下面以插入Excel工作簿文档为例,介绍如何来插入到幻灯片. 程序运行环境 编译环境:I ...
- 008 PHY(Physical Layer,PHY)
一.PHY PHY((Physical Layer,PHY))是IEEE802.3中定义的一个标准模块,STA(station management entity,管理实体,一般为MAC或CPU)通过 ...
- noip30
T1 一眼看,觉得是个状压,然而又觉得不太行,去打暴力了,然而暴力都打挂的我biss. 正解: 还是暴力,考虑 \(meet \; in \; the \; middle\) 显然对于每个数,只有三种 ...
- exportfs命令 – 管理NFS服务器共享的文件系统
exportfs命令需要参考配置文件"/etc/exportfs".也可以直接在命令行中指定要共享的NFS文件系统. 语法格式: export [参数] [目录] 常用参数: -a ...