(数据科学学习手札131)pandas中的常用字符串处理方法总结
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
在日常开展数据分析的过程中,我们经常需要对字符串类型数据进行处理,此类过程往往都比较繁琐,而pandas作为表格数据分析利器,其内置的基于Series.str访问器的诸多针对字符串进行处理的方法,以及一些top-level级的内置函数,则可以帮助我们大大提升字符串型数据处理的效率。
本文我就将带大家学习pandas中常用的一些高效字符串处理方法,提升日常数据处理分析效率:

2 pandas常用字符串处理方法
pandas中的常用字符串处理方法,可分为以下几类:
2.1 拼接合成类方法
这一类方法主要是基于原有的Series数据,按照一定的规则,利用拼接或映射等方法合成出新的Series,主要有:
2.1.1 利用join()方法按照指定连接符进行字符串连接
当原有的Series中每个元素均为列表,且列表中元素均为字符串时,就可以利用str.join()来将每个列表按照指定的连接符进行连接,主要参数有:
- sep: str型,必选,用于设置连接符
它除了可以简化我们常规使用apply()配合'连接符'.join(列表)`实现的等价过程之外,还可以在列表中包含非字符型元素时自动跳过此次拼接返回缺失值,譬如下面的例子:
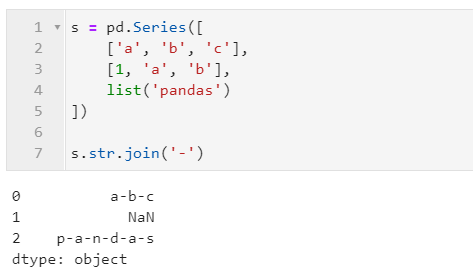
s = pd.Series([
['a', 'b', 'c'],
[1, 'a', 'b'],
list('pandas')
])
s.str.join('-')
2.1.2 利用cat()方法进行字符串拼接
当需要对整个序列进行拼接,或者将多个序列按位置进行元素级拼接时,就可以使用str.cat()方法来加速这个过程,其主要参数有:
- others: 序列型,可选,用于传入待进行按位置元素级拼接的字符串序列对象
- sep: str型,可选,用于设置连接符,默认为
'' - na_rep: str型,可选,用于设置对缺失值的替换值,默认为
None时:- 当
others参数未设置时,返回的拼接结果中缺失项自动跳过 - 当
others参数设置时,两边的序列对应位置上存在缺失值时,拼接结果对应位置返回缺失值
- 当
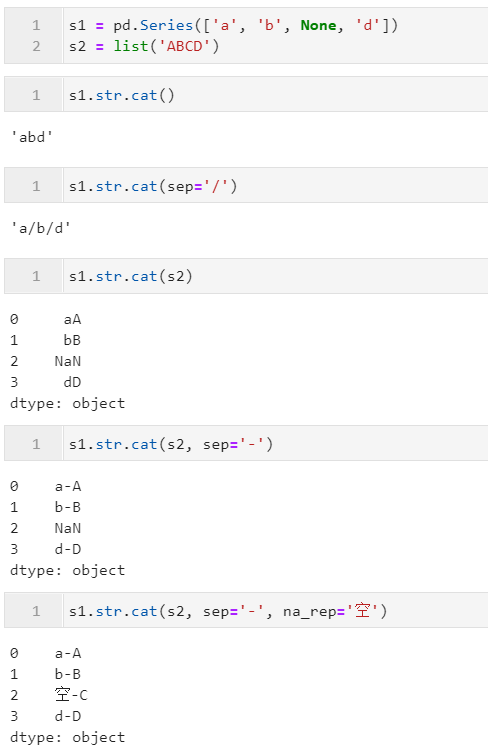
下面是一些简单的例子:
2.2 判断类方法
判断类方法在这里指的是针对字符型Series,按照一定的条件判断从而返回与原序列等长的bool型序列,可进一步辅助数据筛选等操作,在pandas中此类字符串处理方法主要有:
2.2.1 利用startswith()与endswith()匹配字符串首尾
当我们需要判断字符型Series中的每个元素是否以某段字符片段开头或结尾时,就可以使用到startswith()/endswith(),它们的参数一致:
- pat: str型,用于定义要检查的字符片段
- na: 任意对象,当对应位置元素为空值时,用于自定义该位置返回判断结果,默认为
NaN,会原值返回,通常建议设置为False
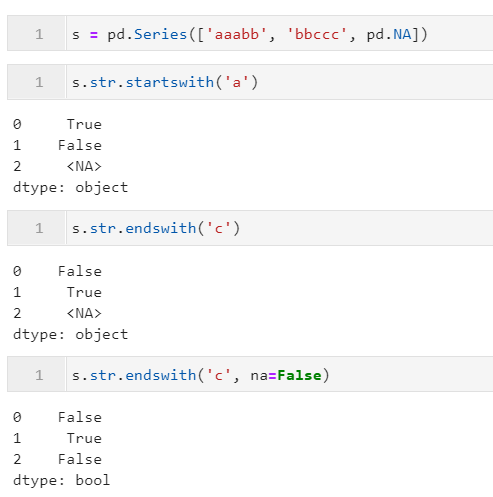
下面是一些简单的例子:
2.2.2 利用contains()判断是否包含指定模式
当我们想要判断字符型Series中每个元素,是否包含指定的字符片段或正则模式时,则可以使用到str.contains()方法,其主要参数有:
- pat: str型,必选,用于定义要检查的字符模式,当
regex=True时表示正则表达式,当regex=False时,表示原始字符串片段 - flags: int型,可选,对应
re模块中的flags参数,用于配合正则表达式模式,实现更多功能,譬如re.IGNORECASE即代表大小写忽略 - na: 用于自定义遇到缺失值时返回的对象,通常建议设置为
False - regex: bool型,用于设置是否将
pat参数视为正则表达式进行解析,默认为True
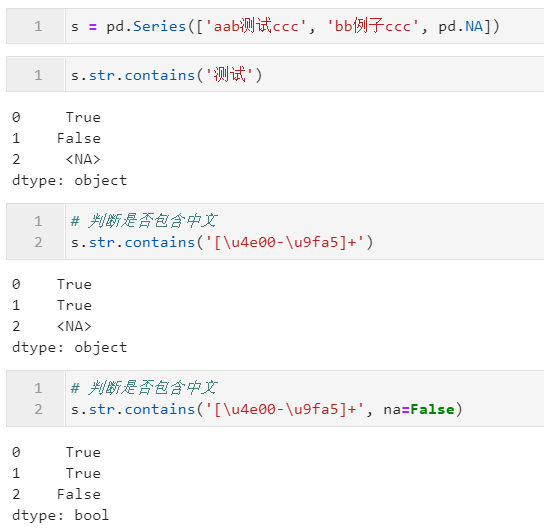
下面是一些简单的例子:
2.2.3 利用match()判断是否以指定正则模式开头
类似前面介绍的startswith(),不同的是,match()支持正则表达式,可以帮助掌握正则表达式的用户拓展匹配能力,其主要参数有:
- pat: str型,必选,用于定义要检查的字符模式,当
regex=True时表示正则表达式,当regex=False时,表示原始字符串片段 - flags: int型,可选,对应
re模块中的flags参数,用于配合正则表达式模式,实现更多功能,譬如re.IGNORECASE即代表大小写忽略 - na: 用于自定义遇到缺失值时返回的对象,通常建议设置为
False
下面是一些简单的例子:
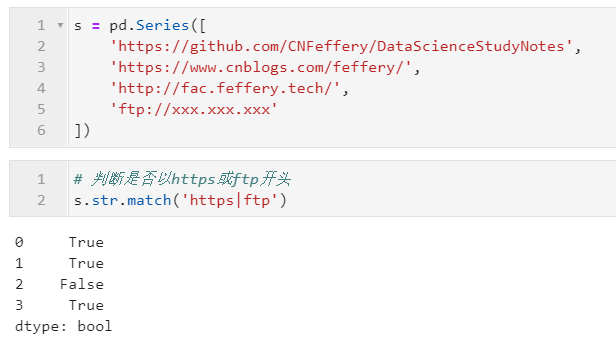
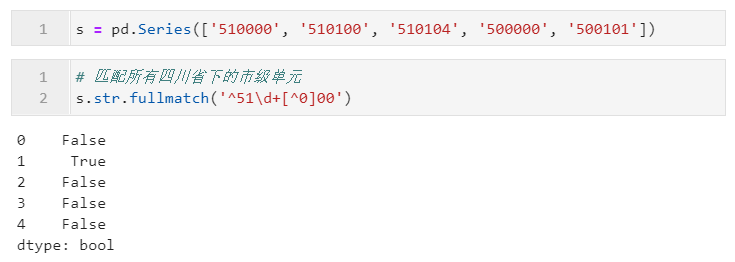
2.2.4 利用fullmatch()判断字符串是否完整满足指定正则模式
上面介绍的match()局限性在于只能从开头匹配是否满足指定正则表达式,而从pandas1.1.0版本开始,新增了fullmatch()方法,可以帮助我们传入正则表达式来判断目标字符串是否可以完全匹配,其参数同match(),下面是一个简单的例子:
2.3 生成型方法
生成型方法这里指的是,基于原有的单列字符型Series数据,按照一定的规则产生出新计算结果的一系列方法,pandas中常用的有:
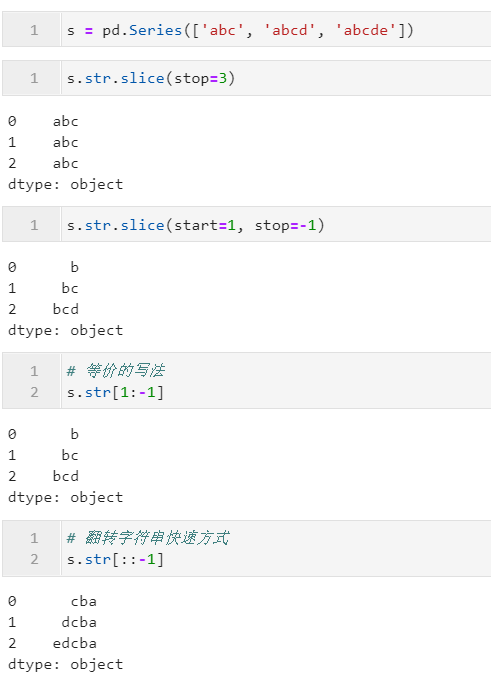
2.3.1 利用slice()进行字符切片
当我们想要对字符型Series进行元素级的切片操作时,就可以用到str.slice(),其三个参数依次为start、stop和step,分别代表切片的开始下标、结束下标与步长,与Python原生的切片方式一致,下面是一些简单的例子(也可以直接使用类似Python中[start:stop:step]):
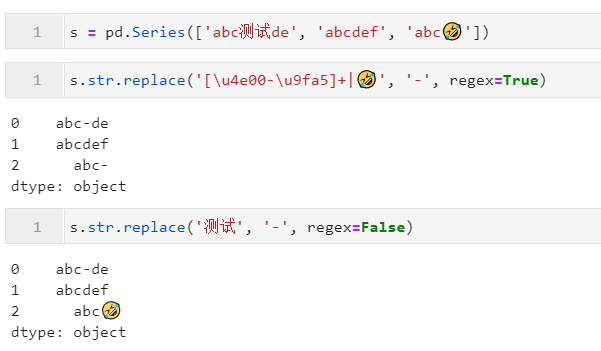
2.3.2 利用replace()对指定字符片段或正则模式进行替换
当我们希望对字符型Series进行元素级的字符片段/正则模式替换时,就可以使用到str.replace()方法,其除了常规的pat、flags、regex等参数外,还有特殊的参数n用于设置每个元素字符串(默认为-1即不限制次数),参数repl用于设置填充的新内容,从开头开始总共替换几次,下面是一些简单的例子:
2.3.3 利用split()按照指定字符片段或正则模式拆分字符串
利用str.split()方法,我们可以基于指定的字符片段或正则模式对原始字符Series进行元素级拆分,主要参数有pat、n,同上文类似的参数设定,另外还有特殊参数expand来设定对于是否以DataFrame中不同列的形式存储拆分结果,默认为False。下面是一些简单的例子:
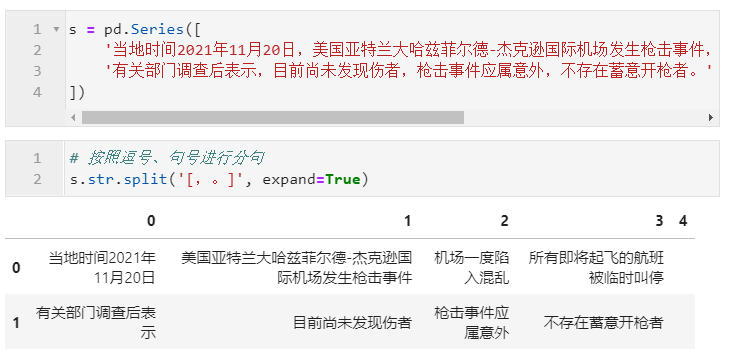
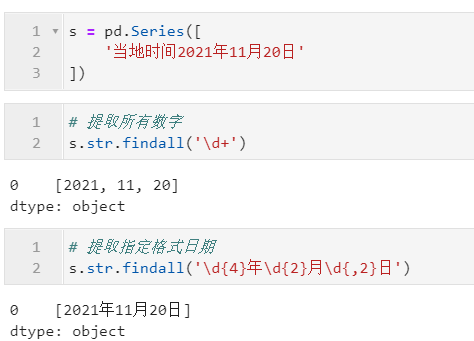
2.3.4 利用findall()提取符合指定模式的片段
利用findall(),可以按照指定的字符片段/正则模式对字符型Series进行元素级提取,可用的参数有pat、flags,下面是一些简单的例子:
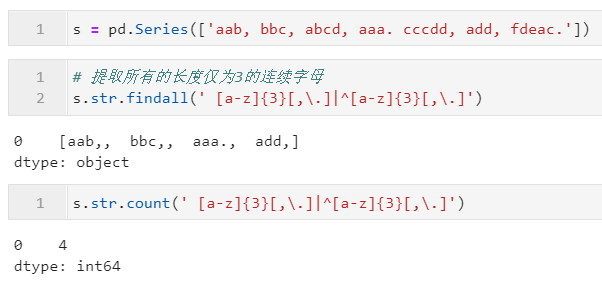
2.3.5 利用count()进行频数统计
通过count(),我们可以对指定的字符片段/正则模式在字符型Series中每个字符串元素中出现的次数进行统计,其参数同上文中的findall(),下面是一些简单的例子:
2.4 特殊型方法
除了上述介绍到的字符串处理方法外,pandas中还有一些特殊方法,可以配合字符串解决更多处理需求,典型的有:
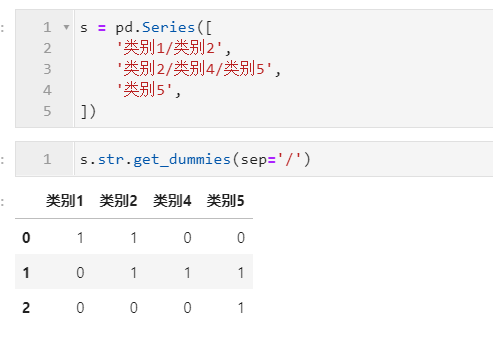
2.4.1 利用get_dummies()方法生成哑变量
在涉及到机器学习特征工程的过程中,我们可以使用到str.get_dummies()方法来对具有固定分隔符的字符串进行哑变量的生成,它只有一个参数sep,用于设置分隔符,暂时不支持正则模式:
2.4.2 利用pd.to_numeric()修复数值错误
有些情况下,我们从外部数据源(如excel表)中读入的数据,由于原始数据文件加工的问题,导致一些数值型字段中的某些单元格混入非数值型字符,如:
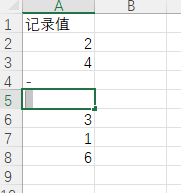
这种情况下,直接读入的数据,本应该为数值型的字段会变成object型:
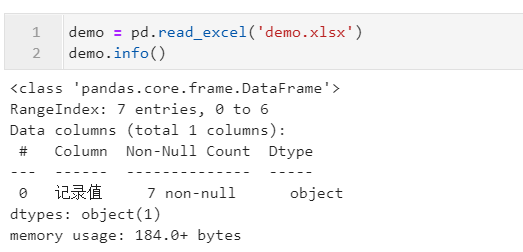
这种时候就可以利用pd.to_numeric()方法,设置参数errors='coerce',就可以将可以合法转为数值型的记录转换为相应的数值,不合法的位置返回缺失值:

以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札131)pandas中的常用字符串处理方法总结的更多相关文章
- (数据科学学习手札21)sklearn.datasets常用功能详解
作为Python中经典的机器学习模块,sklearn围绕着机器学习提供了很多可直接调用的机器学习算法以及很多经典的数据集,本文就对sklearn中专门用来得到已有或自定义数据集的datasets模块进 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- 前端从web服务器或者CDN下载资源
前段时间听到前端同学说前端拿到资源的CDN链接后可以直接从CDN下载资源,不需要经过后端,感觉很神奇,但是一致不明白是怎么实现的,前两天整理了下关于CDN和对象存储的知识,今天搜了下前端直接下载资源的 ...
- 11.2.0.4 ORA-15025 ORA-27041 IBM AIX RISC System/6000 Error: 13: Permission denied
ASM device error ORA-27041 ORA-15025 ORA-15081 (Doc ID 1487475.1) 描述总结:数据库的alert中发现大量ORA-27041 ORA-1 ...
- JUC之Executor,ExecutorService接口,AbstractExecutorService类
java多线程的Executor中定义了一个execut方法,ExecutorService接口继承了Executor接口,并进行了功能的扩展组合,定义了shutdown,shutdownNow,su ...
- 15-ThreadLocalRandom类剖析
ThraedLocalRandom类是JDK7在JUC包下新增的随机数生成器,它弥补了Random类在多线程下的缺陷. Random类及其缺陷 下面看一下java.util.Random的使用方法. ...
- SingleR如何使用自定义的参考集
在我之前的帖子单细胞分析实录(7): 差异表达分析/细胞类型注释里面,我已经介绍了如何使用SingleR给单细胞数据做注释,当时只讲了SingleR配套的参考集.这次就讲讲如何使用自己定义/找到的基因 ...
- C# 如何使用代码添加控件及控件事件
1.首先简单设计一下界面: 添加了Click事件 <Window x:Class="WpfApp.MainWindow" xmlns="http://schemas ...
- Jupyter Notebook配置多个kernel
Jupyter Notebook配置多个kernel 前言: 在anaconda下配置了多个环境,而Jupiter Notebook只是安装在base环境下,为了能在Jupiter Notebook中 ...
- the Agiles Scrum Meeting 1
会议时间:2020.4.9 20:00 1.每个人的工作 今天已完成的工作 前端 学习JavaScript.Vue.ElementUI相关知识 issues:预习任务-前端:JavaScript 预习 ...
- 关于下载pyton第三方库的细节
1.下载Python第三方库有时候国外的网站网速很不好,需要选择国内的镜像网站去下载 阿里云 http://mirrors.aliyun.com/pypi/simple 中国科技大学 https: ...
- 洛谷 P5664 [CSP-S2019] Emiya 家今天的饭
链接: P5664 题意: 给出一个 \(n*m\) 的矩阵 \(a\),选 \(k\) 个格子(\(1\leq k\leq n\)),每行最多选一个,每列最多选\(⌊\dfrac k2⌋\) 个,同 ...