剖析虚幻渲染体系(12)- 移动端专题Part 2(GPU架构和机制)
- 12.4 移动渲染技术要点
- 12.4.1 Tile-based (Deferred) Rendering
- 12.4.2 Hierarchical Tiling
- 12.4.3 Early-Z
- 12.4.4 Transaction Elimination
- 12.4.5 Forward Pixel Kill
- 12.4.6 Hidden Surface Removal
- 12.4.7 Low Resolution Z pass
- 12.4.8 FlexRender
- 12.4.9 Universal Bandwidth Compression
- 12.4.10 Arm Frame Buffer Compression
- 12.4.11 Index-Driven Vertex Shading
- 12.4.12 Pixel Local Storage
- 12.4.13 Subpass
- 12.4.14 Adaptive Scalable Texture Compression
- 12.4.15 big.LITTLE Core
- 12.4.16 其它技术要点
- 12.5 移动GPU架构和机制
- 团队招员
- 特别说明
- 参考文献
12.4 移动渲染技术要点
笔者这段时间研读了近年来Siggraph、GDC关于移动端的Papers,查阅了Qualcomm、Arm、PowerVR等移动端GPU厂商和部分移动设备厂商的开发指南,在本章总结一下目前移动端常见的专用渲染技术。
具体见后面的参考文献列表。
12.4.1 Tile-based (Deferred) Rendering
TBR全称是Tile-based Rendering,译为基于分块的渲染。它是目前移动端GPU架构中应用非常广泛的一种技术,用来加速渲染,减少带宽和能耗。
TBDR全称是Tile-based Deferred Rendering,是TBR的一种改进版,意为基于分块的延迟渲染,最早由PowerVR应用于GPU芯片中。它最显著的不同点在于通过了Early-Z测试的像素不会立即执行像素着色器,而是先标记该像素属于哪个图元。当Tile处理完所有图元(场景中的所有物体),再绘制Tile上所有做了标记的像素。TBDR做到了硬件层级的遮挡像素剔除,减少OverDraw,减少带宽和内存访问。
PowerVR的TBDR在开始渲染之前,会捕获整个场景,这样被遮挡的像素在被像素着色器之前就可以被识别和剔除。每个Tile都被光栅化并单独处理,由于渲染的尺寸很小,使得允许所有数据都保存在非常快的Tile内存中。
与TB(D)R对应的是用于PC的立即渲染(Immediately Rendering,IMR)模式。IMR、TBR、TBDR架构的对比图如下:

IMR、TBR、TBDR架构运行示意图。其中红色椭圆表示带宽高,会引发性能瓶颈。
对于IMR模式的GPU,若忽略并行处理逻辑,则执行的伪代码如下所示:
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
for fragment in primitive:
execute_fragment_shader(fragment)
IMR的GPU硬件架构如下所示:
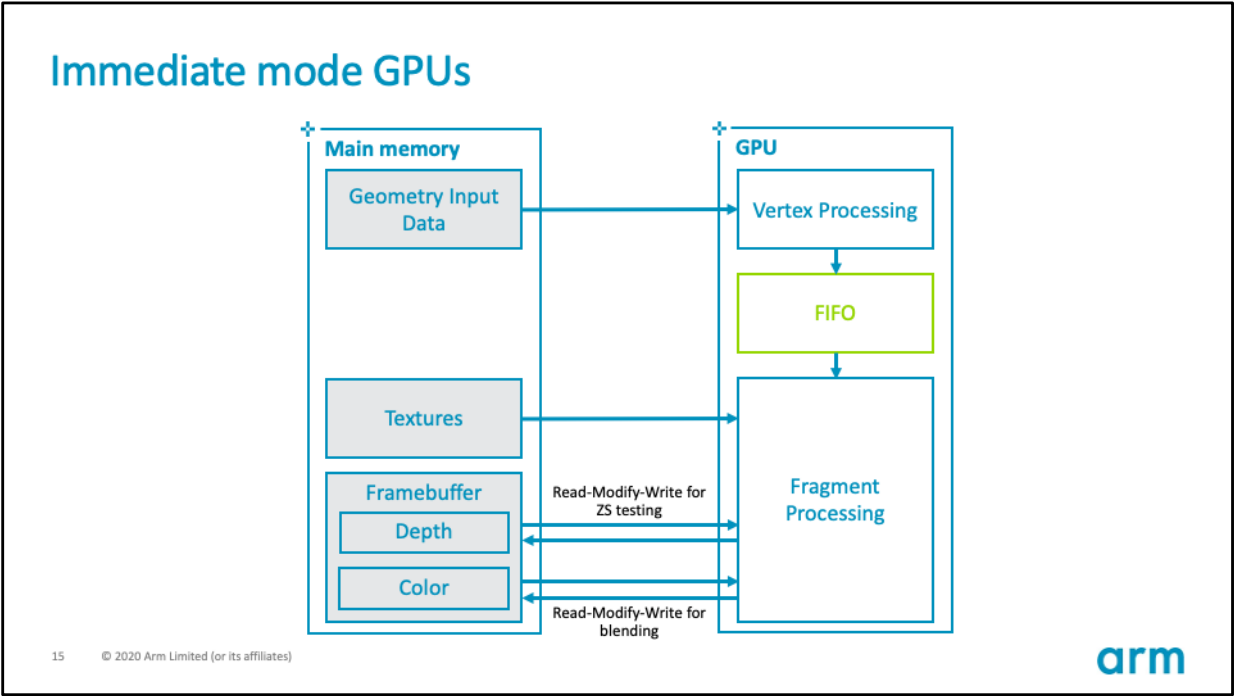
其硬件数据流和内存交互图如下:

IMR模式的GPU的优势在于,顶点着色器和其它几何体相关着色器的输出可以保留在GPU内的芯片上。这些着色器的输出可以存储在FIFO缓冲区,直到管道中的下一阶段准备使用数据,GPU可以使用很少的外部内存带宽存储和检索中间几何结果。
IMR模式的GPU的劣势在于,像素着色在屏幕上跳跃,因为三角形按绘制顺序处理,数据流中的任何三角形都可能覆盖屏幕的任何部分(下图)。意味着活动工作集是整个framebuffer的大小。例如,考虑一个分辨率为1440p的设备,使用32位每像素(BPP)的颜色,32位每像素的填充深度/模板,将提供30MB的总工作集,若全部存储在on chip上,数据量过大,因此必须存储在DRAM的off chip之外。
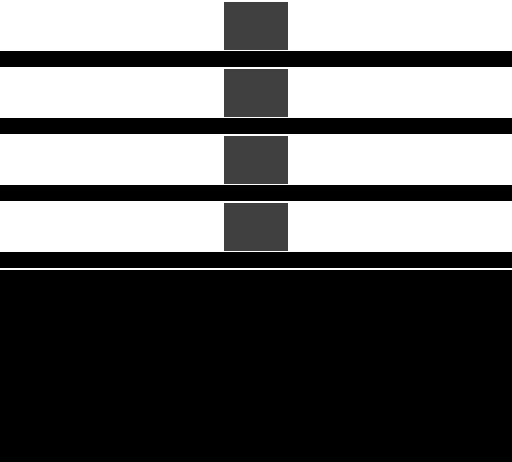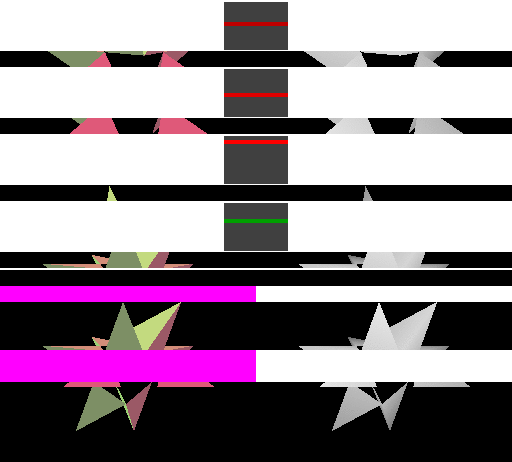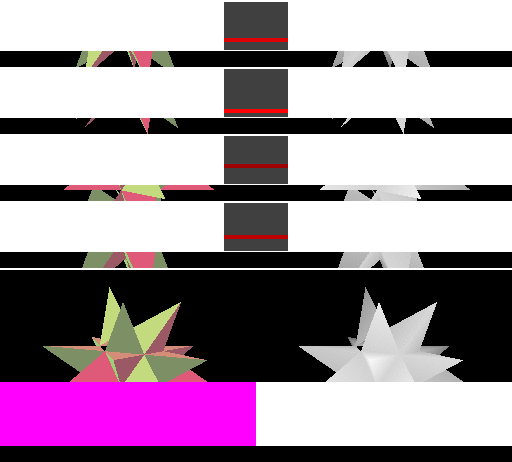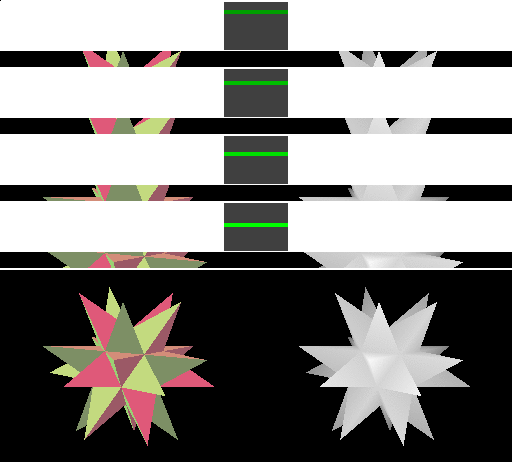
IMR的并行渲染示意图,随机访问遍布全屏幕,导致缓冲命中率大大降低。
在处理高分辨率画面时,放置在内存上的带宽负载可能非常高,因为每个像素都有多个读-修改-写操作。可以通过将最近访问的framebuffer部分保持在靠近GPU的位置来减轻高带宽负载。
TB(D)R的GPU则与IMR GPU不同,它先将屏幕划分成若干个固定大小的区域,然后再执行着色计算。下面是TBR的执行伪代码:
# Pass one
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
append_tile_list(primitive)
# Pass two
for tile in renderPass:
for primitive in tile:
for fragment in primitive:
execute_fragment_shader(fragment)
TB(D)R GPU的硬件架构如下所示:

其硬件数据流和内存交互图如下:

TB(D)R的优势在于,Tile只占整个framebuffer的一小部分。 因此,可以将整个颜色、深度和模板的工作集存储在快速的 on-chip RAM上,与GPU着色器核心紧密耦合。GPU用于深度测试和混合透明像素所需的framebuffer数据无需访问外部内存即可获得,通过减少GPU对通用framebuffer操作所需的外部内存访问数量,可以显著提高像素密集型内容的能源效率。此外,多数情况存在一个深度和模板缓冲,它们是瞬态的,只需要在着色过程中存在。如果明确告诉GPU驱动程序不需要保存附件(Attachment),那么驱动程序就不会将它们写回主存。
以下图形API可以指示驱动程序丢弃附件:
OpenGL ES 2.0:
glDiscardFramebufferEXTOpenGL ES 3.0:
glInvalidateFramebufferVulkan:恰当的渲染通道storeOp
值得一提的是,由于每个Tile的尺寸通常不会很大,使得GPU计算单元访问单个Tile内的数据具有良好的邻域性,能够提升Cache命中率。
当然,天下没有免费的午餐,TB(D)R同样存在一些劣势。例如,GPU必须将几何通道的输出(每个顶点的变化数据和Tile的中间状态)存储到主内存中,着色通道随后读取这些数据。因此,需要在与几何图形相关的额外带宽成本和为framebuffer数据节省的带宽之间取得平衡。同样重要的是要考虑到一些渲染操作,比如曲面细分,对于TBR来说是不成比例的高消耗。曲面细分等操作被设计来适应IMR模式架构的优势,因为几何数据的爆炸可以在on-chip FIFO缓冲区内缓冲,而不是被写回主存储器。
下面以Qualcomm Adreno系列GPU加以说明TB(D)R的架构、运行过程、涉及的渲染技术和优化技巧。

TB(D)R的渲染不同于IMR模式,绘制过程分为分块(Binning Pass)、渲染(Rendering Pass)、解析(Resolve Pass)3个阶段。
分块(Binning Pass)过程大致如下:
设定每个Bin(也被称为Tile)的固定大小(2的N次方,长宽通常相同,具体尺寸因GPU厂商而异,如16x16、32x32、64x64),根据Frame Buffer尺寸设置可见数据流。

转换图元坐标。注意此阶段处理的是索引和顶点数据,某些GPU(如Adreno)会用特殊的简化过的shader(而非完整的Vertex Shader)来处理坐标,以减少带宽和能耗。此阶段通常只有顶点的位置有效,其它顶点数据(纹理坐标、法线、切线、顶点颜色)都会被忽略。
遍历所有图元,标记所有图元覆盖到的块,将可见性数据写入到被覆盖的块数据流中。
将可见性数据流写回系统显存中。
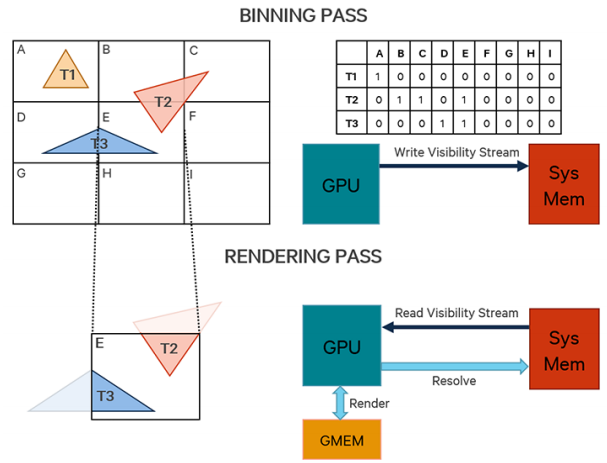
Binning阶段的运行示意图如下:
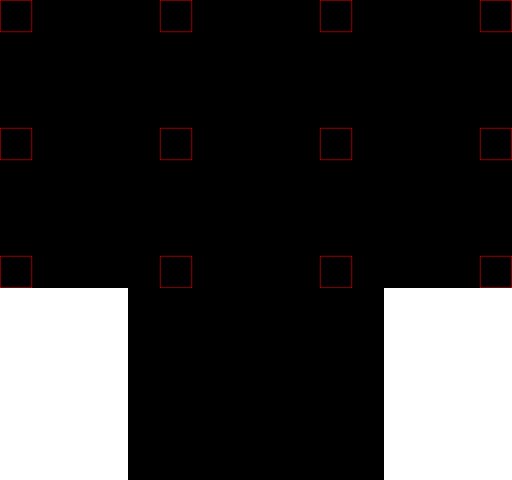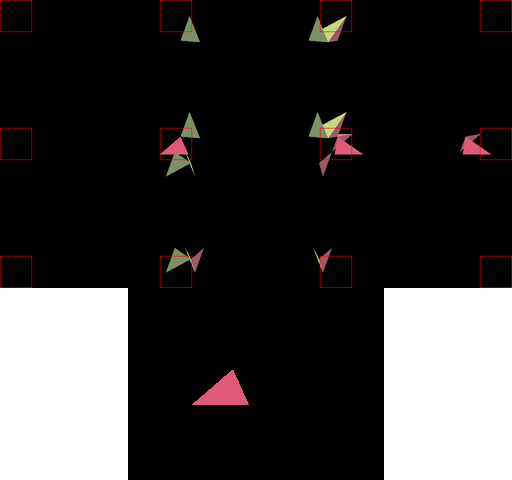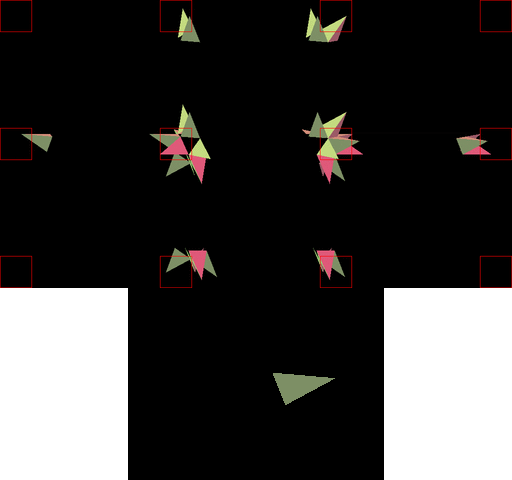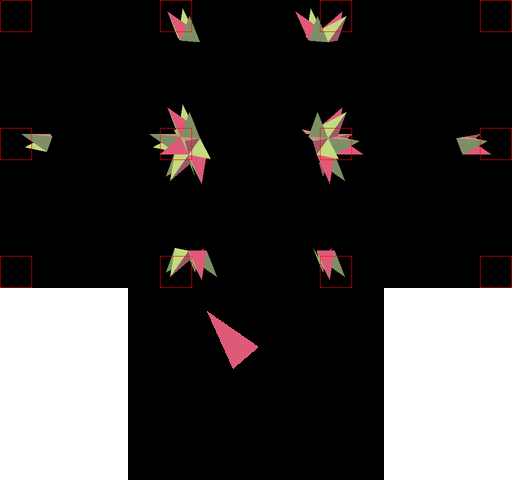
渲染(Rendering Pass)过程大致如下:
- 初始化渲染Pass。
- 遍历所有分块,对每个分块执行以下操作:
- 利用分块的可见性数据流,执行绘制调用。
- 光栅化图元。
- 像素操作(像素着色器、深度模板测试、Alpha测试、混合)。
- 写入像素数据(颜色、深度、模板等等)到分块芯片上的缓冲区(又被称为On-Chip Memory、GMEM、Tiled Memory)。
Rendering阶段的运行示意图如下:
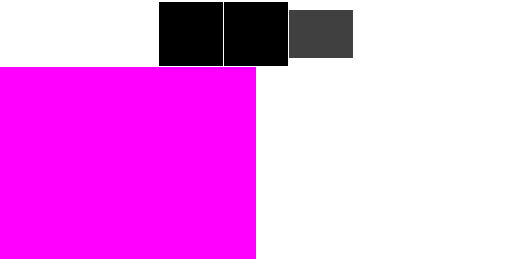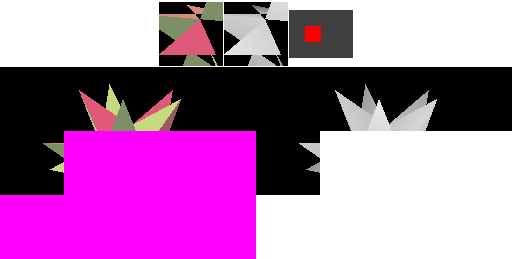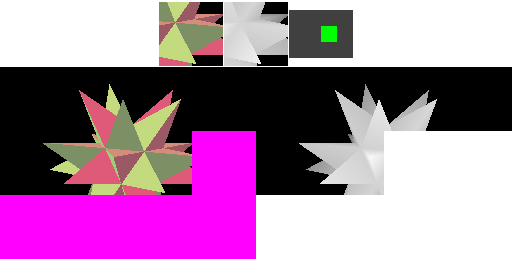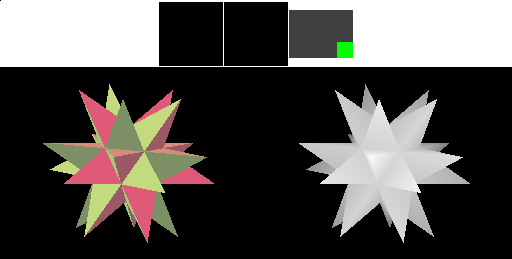
如果GPU上存在多个Tile处理单元,则可以同时处理多个Tile,并且Tile处理单元之间是相互独立的:
解析(Resolve Pass)阶段过程如下:
如果开启了MSAA,在GMEM上的解析颜色、深度等数据(求平均值)。可以减少后续步骤GMEM传输到系统显存的数据总量。

将分块上的所有像素数据(颜色、深度、模板等)写入到系统显存中。
如果不是Frame Buffer的最后一个分块,继续执行下一个分块。
如果是Frame Buffer的最后一个分块,交互缓冲区,执行下一帧的Binning Pass。
解析阶段的运行示意图如下(注意Tile内的像素包含锯齿,下方大画面的是解析完MSAA带抗锯齿的像素):

其中Binning Pass和Rendering Pass通常是分帧处理的,意味着Rendering Pass会落后Binning Pass一帧,以减少Stall,提升吞吐量,提升渲染效率。
基于TB(D)R GPU架构的优化和技术还有很多,后面会涉及到。
12.4.2 Hierarchical Tiling
Hierarchical Tiling译为层级分块,是Arm Midgard系列芯片首次使用的分块技术,顾名思义,它在分层的基础上实现分块。
在这种情况下,使用Hierarchical Tiling允许Midgard使用可变的分块大小,基于进一步分解分块的想法(沿着层次结构向下,见下图),直到分块的复杂性达到预期的大小(或者达到最小的分块复杂性)。这种技术使得Midgard只在必要的情况下使用小尺寸分块,并通过在复杂性较低的场景使用大尺寸分块来节省资源。
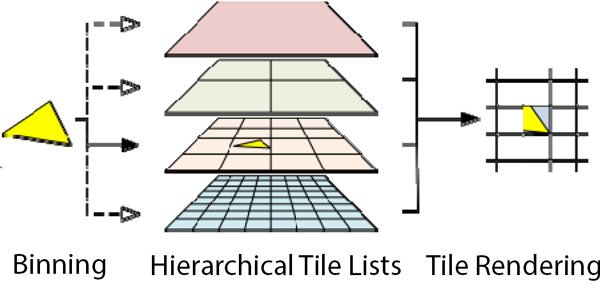
更具体地说,Arm通常将不同层级的分块(bin)设为以下的大小:
- Hierarchy Level 0设为16x16像素;
- Hierarchy Level 1设为32x32像素;
- Hierarchy Level 2设为64x64像素;
- Hierarchy Level 3设为128x128像素;
- ......

系统的目标是找出每个图元覆盖的分块,更新分块的结构信息。
如果是小面积图元(如上图灰色三角形),由于影响到的块比较少,用低层级的块,以节省读取带宽。
如果是大面积图元(如上图蓝色三角形),由于影响到的块比较多,用高层级的块,以节省写入带宽。
对于图元复杂的情况,GPU会采用启发性策略,以自动决定哪种是最佳的分布。
至于启发性策略的具体细节是怎样的,目前还没找到相关资料或文献,如果以后找到了(或有同学提供)再补充。
12.4.3 Early-Z
Early-Z是提前深度测试,提供了一种快速遮挡方法,剔除不需要的渲染Pass的对象(屏幕空间的位置不可见的像素)。Adreno GPU可以以4倍的绘制像素填充率剔除被遮挡的像素。
Early-Z通常发生在Rendering Pass阶段的光栅化之后像素着色之前。(下图)

Early-Z技术可以将很多无效的像素提前剔除,避免它们进入消耗严重的像素着色器。Early-Z剔除的最小单位不是1像素,而是像素块(pixel quad)。下面是其中的一个运行案例。
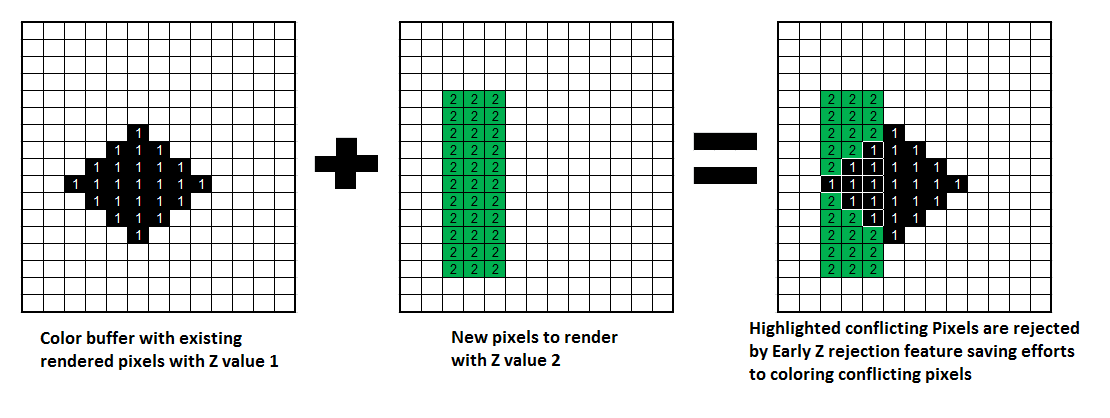
Early-Z运行示意图。左边是已经渲染的存储于深度缓冲的值,全部为1;中间是准备渲染的所有深度值为2的区域;右边利用Early-Z技术剔除了比深度缓冲较大的像素。
为了最大化发挥Early-Z技术,渲染引擎(如UE)会在渲染初期利用专门的Pass(如UE的PrePass),渲染出所有不透明物体的深度,发挥TBR架构的Early-Z技术。对支持TBDR架构的GPU,则无需此步。
但是,以下情况会导致Early-Z失效:
- 开启Alpha Test:由于Alpha Test需要在像素着色器后面的Alpha Test阶段比较,所以无法在像素着色器之前就决定该像素是否被剔除。
- 开启Alpha Blend:启用了Alpha混合的像素很多需要与frame buffer做混合,无法执行深度测试,也就无法利用Early-Z技术。
- 开启Tex Kill:即在shader代码中有像素摒弃指令(DX的discard,OpenGL的clip)。
- 关闭深度测试:Early-Z是建立在深度测试开启的条件下,如果关闭了深度测试,也就无法启用Early-Z技术。
- 开启Alpha To Coverage:Alpha To Coverage会开启多采样,会影响周边像素,而Early-Z阶段无法得知周边像素是否被裁剪,故无法提前剔除。
- 以及其它任何导致需要混合后面颜色的操作。
12.4.4 Transaction Elimination
Transaction Elimination (TE)是Mali GPU架构的一个关键带宽节约功能,可以显著节省芯片系统(SoC)上的能源。
当执行TE时,GPU将当前帧缓冲区与之前渲染的帧进行比较,只对修改过的特定部分进行部分更新,从而大大减少了每帧向外部内存传输的数据量。以Tile为粒度进行比较,使用循环冗余检查(Cyclic Redundancy Check,CRC)签名来确定Tile是否已被修改(具有相同CRC签名的Tile被认定是相同的,从而忽略该Tile的数据的传输)。
循环冗余检查(Cyclic Redundancy Check,CRC)是一种根据网络数据包、计算机文件、内存数据流等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。这里被Mali GPU用来检测本帧的Tile数据和之前的Frame Buffer数据是否相同。

TE技术运行概要。当前帧会每个分块计算一个CRC键值,以便下一帧比较每个分块是否有数据变更,对于无变更的分块取消数据传输。图中右下角的绿色分块和上一帧匹配,不需要传输数据到Frame Buffer。对于互动游戏而言,平均可以减少20%以上的带宽。
执行TE技术对最终图像质量没有影响,可用于GPU支持的所有帧缓存格式的所有应用程序,而无需考虑帧缓存精度要求。另外,需要注意的是,TE发生在Tile写入数据到系统内存(Frame Buffer)期间(下图左下方)。
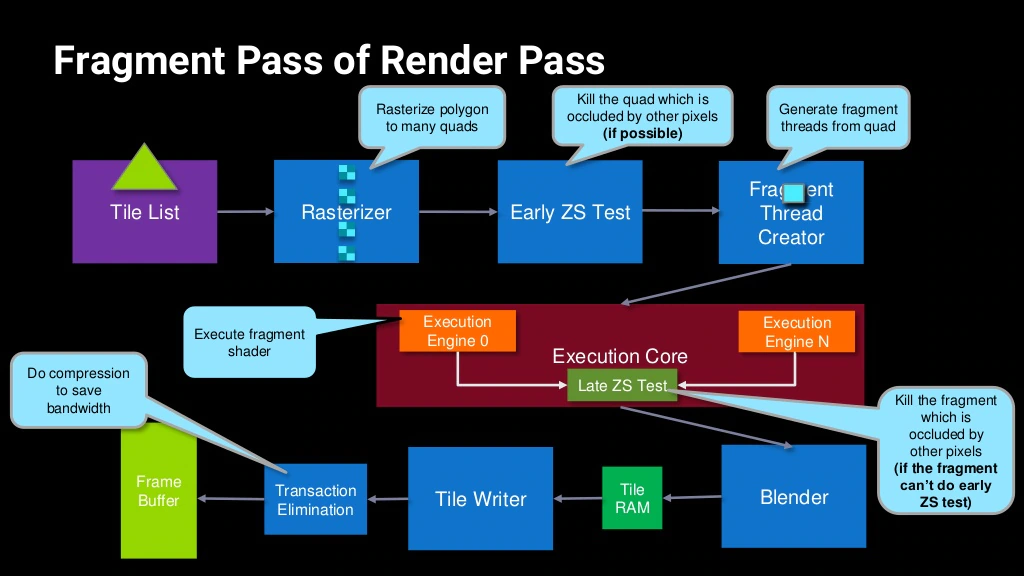
12.4.5 Forward Pixel Kill
Forward Pixel Kill (FPK)是Mali-T62X和T678及之后的芯片内置的一种减少OverDraw的技术。
在支持FPK的GPU中,像素着色的线程即便启动,也不会不可逆转地完成。正在进行的计算可以在任何时候终止,如果渲染管线发现后面的线程将把不透明的数据写入相同的像素位置。因为每个线程都需要有限的时间来完成,所以有一个时间窗口,可以利用它来杀死已经在管道中的像素。实际上,利用管道的深度来模拟对未来的预见效应。
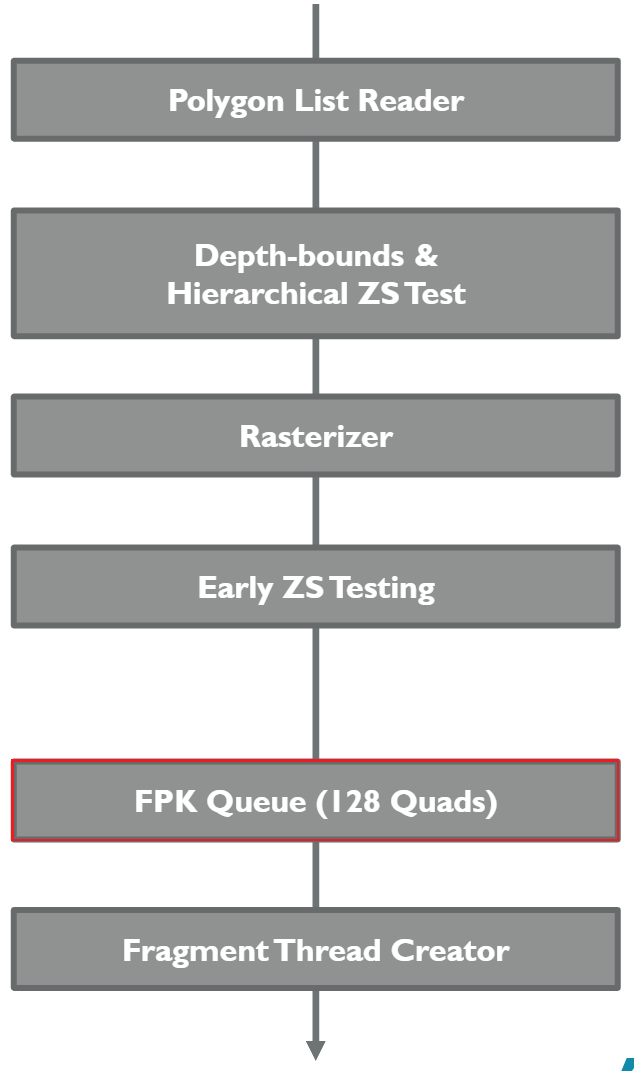
支持FPK的GPU芯片内都存在FIFO(先进先出)缓冲区(介于Early Z测试和像素着色器之间,见下图),用来存储通过了Eearly-Z测试即将进入像素着色计算的Quad。
举个具体的例子说明FPK的运行机制,以下图为例:
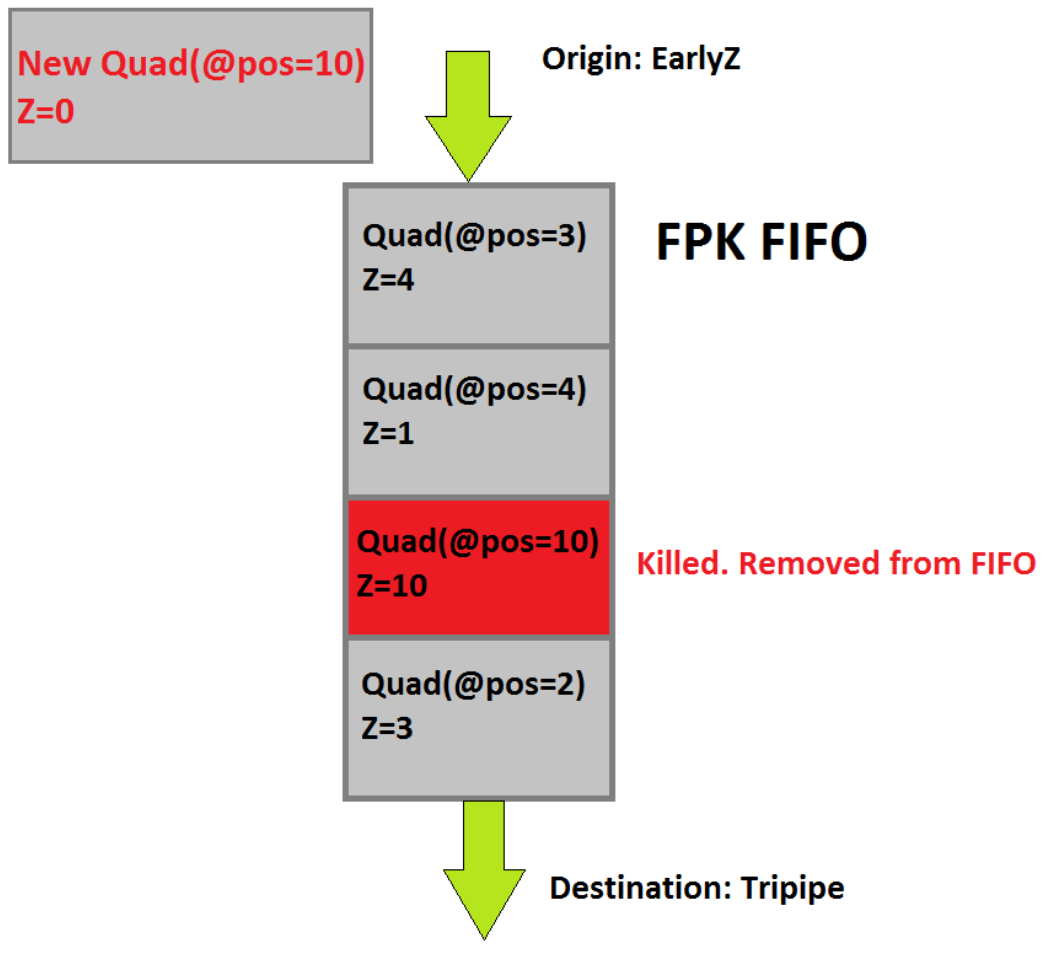
上述图中新的Quad(位置是10,深度是0)通过了EarlyZ测试,即将进入FPK FIFO缓冲区,结果发现FIFO中已经存在位置为10位置为10,新进来的Quad便会替换掉FIFO队列的Quad(因为新的深度更靠近屏幕)。换而言之,FPK FIFO中的Quad会被新进的位置相同深度更小(近)的Quad替换掉。
关于FPK需要补充几点说明:
- FPK剔除粒度是Quad(2x2像素块)。
- FPK只对不透明物体有效。
- FPK必须开启深度测试才能起作用。
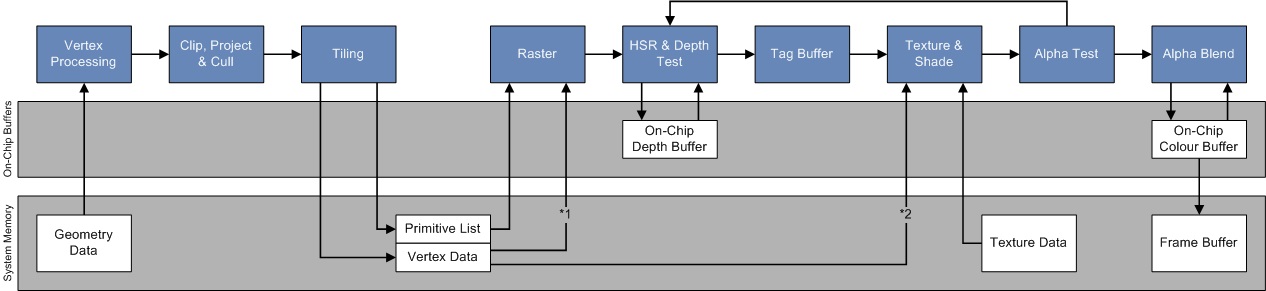
12.4.6 Hidden Surface Removal
Hidden Surface Removal(HSR)译为隐藏表面消除,是PowerVR芯片的专用技术,通过HSR技术,可以实现零OverDraw,而与绘制顺序无关。
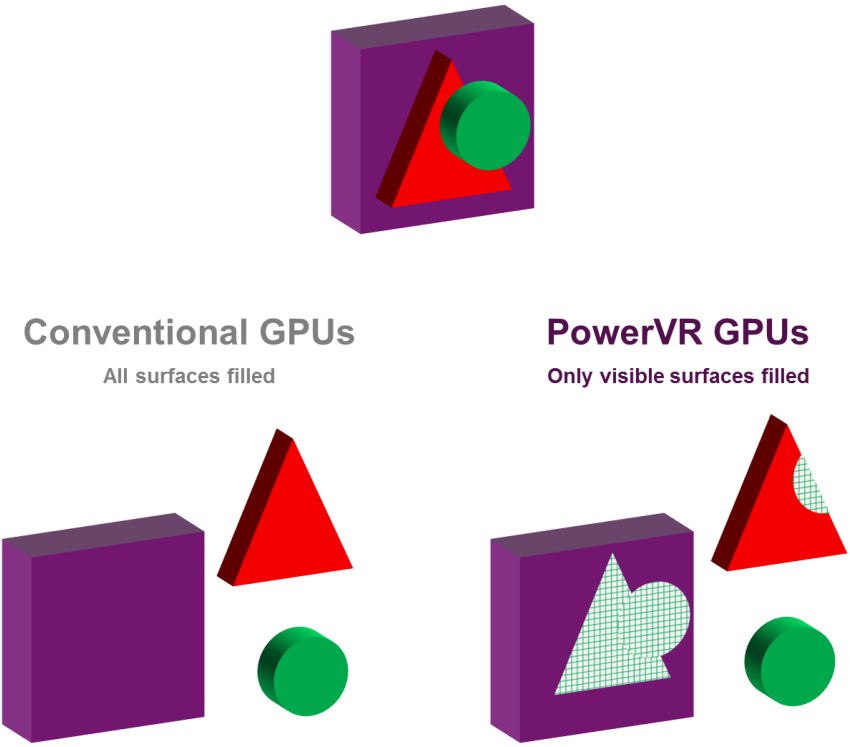
左下是传统GPU,不会对被遮挡的像素执行剔除,而右下展示了PowerVR利用HSR可以做到像素级剔除。
在包含Early-Z测试的架构中,应用程序可以通过从前面到后面提交draw调用来避免一些OverDraw。按照这个顺序提交可以建立深度缓冲区,因此远离相机的被遮挡的像素可以尽早被剔除。然而,这给应用程序带来了额外的负担,因为每次相机或场景中的对象移动时,绘制都必须进行排序。它也不能删除所有的OverDraw,因为逐绘制排序是非常粗糙的。例如,它不能解决由对象交叉引起的OverDraw。 它还可以防止应用程序对绘制调用进行排序,以将图形API状态更改保持在最小值。
使用PowerVR的TBDR,无论物体的提交顺序如何(不排序),HSR将完全避免OverDraw。HSR阶段处于光栅化之后像素着色之前:
12.4.7 Low Resolution Z pass
Low Resolution Z pass简称LRZ,是Adreno A5X及以上的芯片在TBR执行Early-Z剔除时的优化技术。
在Binning Pass阶段,GPU会构造一个低分辨率的Z缓冲区,以LRZ-Tile(注意不是Bin Tile)为粒度来剔除被遮挡的区域,以提高Binning阶段的性能。在测试全分辨率Z缓冲区之前,这个LRZ还可以在Rendering Pass中被用来有效地剔除像素。
这个特性的优点是减少内存访问和带宽,减少渲染图元,不需要应用程序从前到后绘制,提高帧率。
但是,以下几种情况会使LRZ技术失效:
- 在像素着色器中写入深度值。
- 使用了图形API(Vulkan)的次级命令缓冲区(secondary command buffer)。
- 需要IMR直接渲染的任何条件。
12.4.8 FlexRender
FlexRender是Adreno芯片的独有技术,是混合了TBR(Binning)和IMR(Direct Rendering)两种模式的渲染技术,通过在两种模式之间动态切换来最大化性能。

FlexRender运行示意图。Direct Rendering模式下,GPU绕过GMEM直接和系统内存交互;Binning模式下,GPU通过GMEM和系统内存交互。
驱动程序和GPU分析给定渲染目标的渲染参数并自动选择模式,比如渲染目标尺寸很小,会主动切换成IMR模式,以减少渲染消耗(TBR存在基础消耗),如果是执行遮挡剔除,也会切换成IMR模式(哪怕之前处于TBR模式)。
通常情况下,IMR模式要比TBR模式消耗的能量多:
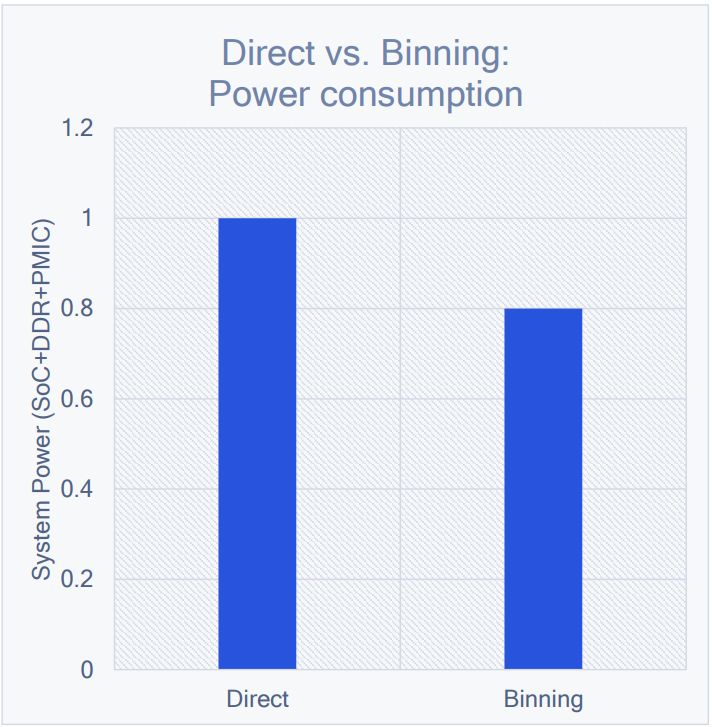
GFXBench Manhattan 3.0监控下的Snapdragon SoC在Direct和Binning模式的能耗对比,后者会省20%左右。
12.4.9 Universal Bandwidth Compression
Universal Bandwidth Compression (UBWC) 是Adreno A5x及之后的芯片加入的通用带宽压缩技术,是一种独特的预测带压缩方案,通过最小化数据带宽,可提高系统内存的有效吞吐量,实现显著的节能。
除了GPU芯片,UBWC技术在应用于Snapdraggon CPU的多个组件上,如显示、视频、相机等。压缩支持YUV和RGB格式,减少内存瓶颈。
UBWC虽然应用于高通的芯片上,但Google Developer Contributes Universal Bandwidth Compression To Freedreno Driver显示该技术实际上是由Freedreno开源驱动器提供。UBWC具体用了何种压缩算法,此文并未提及。
12.4.10 Arm Frame Buffer Compression
Arm Frame Buffer Compression (AFBC)专用于Arm设计的GPU中,解决了在移动设备的热限制下创建越来越复杂的设计的难度。最重要的应用是视频后处理,在许多使用情况下,GPU需要读取视频并在2D或3D场景中使用视频流作为纹理时应用特效。在这种情况下,AFBC可以降低整个系统级带宽和传输空间协调图像数据的电力成本高达50%。
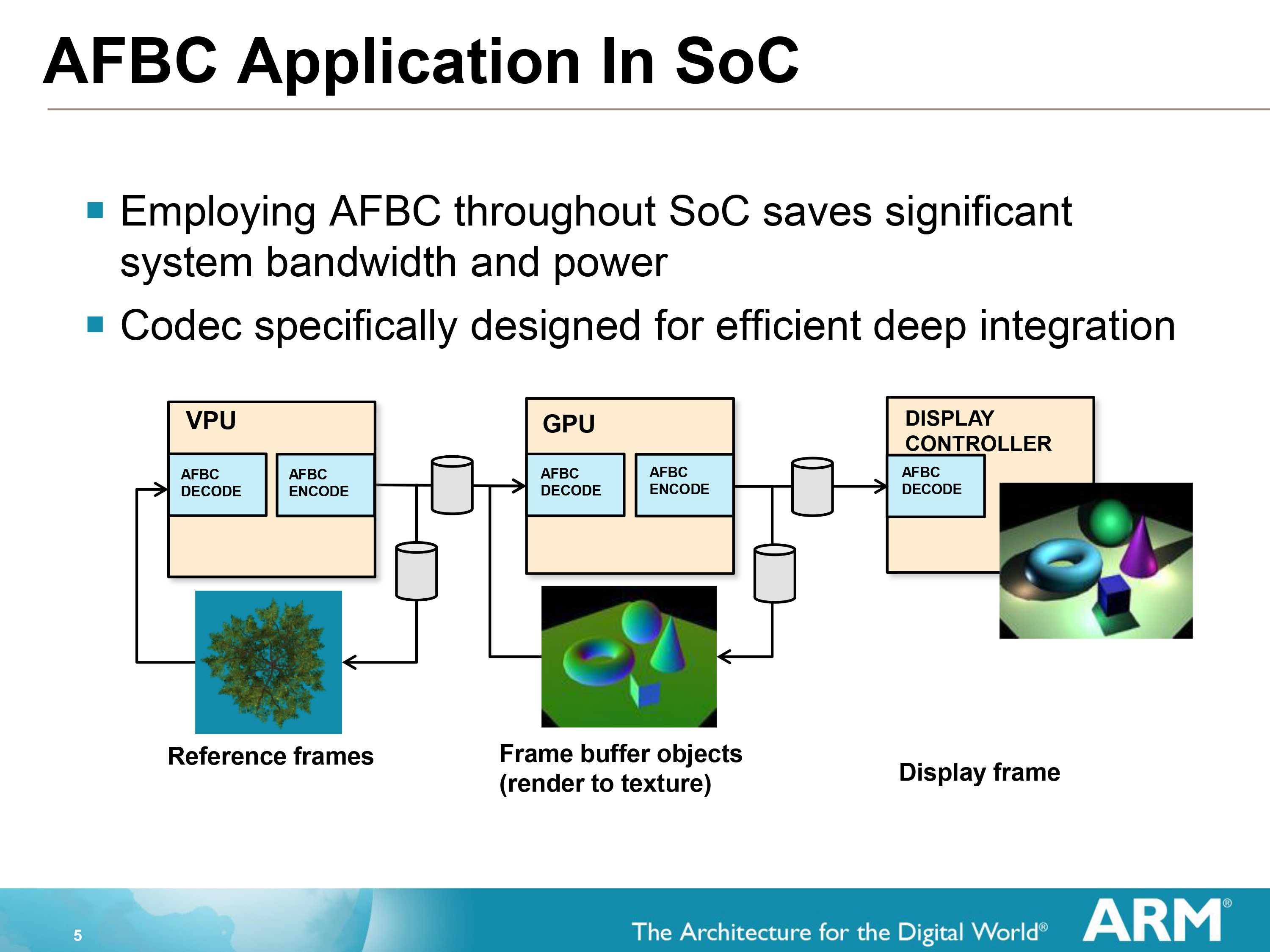
AFBC运行示意图。
作为一种无损的压缩协议和格式,AFBC最小化在SoC的IP块之间的数据传输量。具体低说,AFBC有如下特点:
- 无损压缩格式。压缩格式保留原始图像精度,压缩率和其它无损的压缩标准相媲美。
- 被Mali GPU完全支持。
- 减少能量消耗。主要受益于带宽的减少。
- SoC设计的区域效率高。AFBC可以在设计中以零面积成本添加。
- 有界的最坏情况压缩比。最坏情况(随机访问)的效率下降成4x4级别。
- 支持YUV和RGB格式。YUV压缩比一般为50%。
12.4.11 Index-Driven Vertex Shading
Index-Driven Vertex Shading(IDVS)是Mali GPU内的一种顶点处理优化技术,发生在每个Render Pass的顶点处理阶段。
IDVS的主要特点在于将传统的顶点着色器拆分为两个阶段:
- 第一阶段是位置着色(Position Shading),发生在各类顶点Culling之前,此阶段只转换顶点位置,而不执行顶点的其它操作。
- 第二阶段是可变着色(Varying Shading),发生在各类顶点Culling之后,只处理通过各类Culling的顶点,执行顶点的位置转换之外的其它操作。
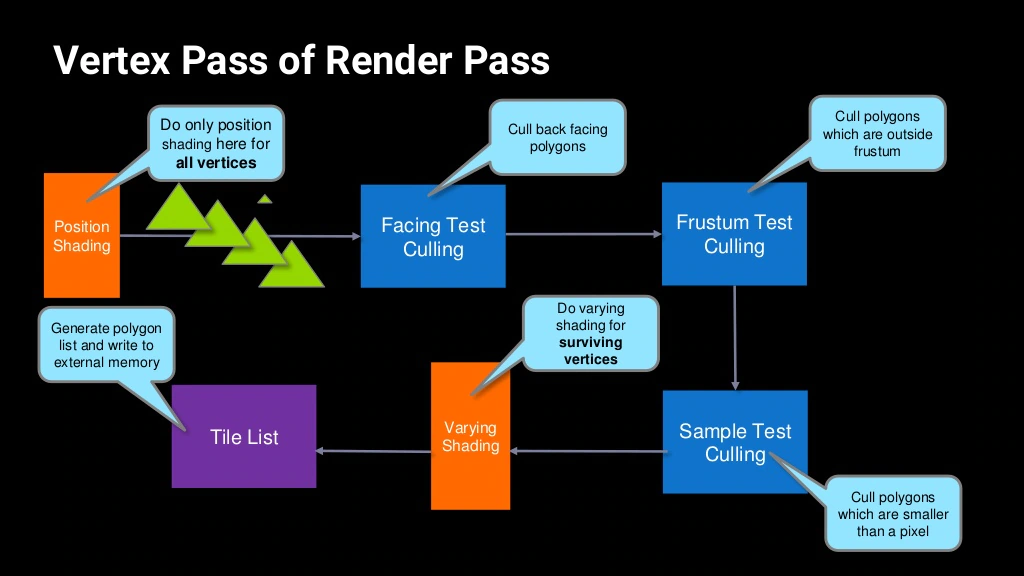
IDVS将顶点着色器拆分为位置着色(Position Shading)和可变着色(Varying Shading)两个阶段。
IDVS技术的优势在于:
Varying Shading大多数情况消耗的性能要比Position Shading大,通过各类顶点Culling阶段剔除掉无效的顶点,从而避免进入消耗大的Varying Shading。
通过匹配IDVS技术的顶点属性布局,可以减少数据读取量,提升Cache命中率,提升性能,降低功耗。匹配IDVS技术的顶点属性布局如下:
将顶点的位置单独成一个数据流,数据流布局如下:
xyz | xyz | xyz | ...
将顶点除位置之外的属性按照SoA(Structure of Array)布局,例如:
color,uv,normal | color,uv,normal | color,uv,normal | ...

IDVS顶点数据流优化及交互示意图。
12.4.12 Pixel Local Storage
Pixel Local Storage(PLS)是OpenGL ES的一种数据存取方式,用PLS声明的数据将保存在GPU的Tile buffer上(下图)。

PLS启用时,渲染管线可以高效地执行颜色操作、混合等。GLSL声明PLS数据关键字有三种,说明如下表:
| 关键字 | 作用 |
|---|---|
| __pixel_localEXT | 可读可写数据。 |
| __pixel_local_inEXT | 只读数据。 |
| __pixel_local_outEXT | 只写数据。 |
PLS的应用以延迟渲染为例,则伪代码如下所示:
// ------GBuffer生成------
__pixel_local_outEXT FragData // 只写数据
{
layout(rgba8) highp vec4 Color;
layout(rg16f) highp vec2 NormalXY;
layout(rg16f) highp vec2 NormalZ_LightingB;
layout(rg16f) highp vec2 LightingRG;
}gbuf;
void main()
{
gbuf.Color = CalcDiffuseColor();
vec3 Normal = CalcNormal();
gbuf.NormalXY = Normal.xy;
gbuf.NormalZ_LightingB.x = Normal.Z;
}
// ------光照累积------
__pixel_localEXT FragData // 可读写数据
{
layout(rgba8) highp vec4 Color;
layout(rg16f) highp vec2 NormalXY;
layout(rg16f) highp vec2 NormalZ_LightingB;
layout(rg16f) highp vec2 LightingRG;
}gbuf;
void main()
{
vec3 Lighting = CalcLighting(gbuf.NormalXY, gbuf.NormalZ_LightingB.x);
gbuf.LightingRG += Lighting.xy;
gbuf.NormalZ_LightingB.y += Lighting.z;
}
// ------最终着色------
__pixel_local_inEXT FragData // 只读数据
{
layout(rgba8) highp vec4 Color;
layout(rg16f) highp vec2 NormalXY;
layout(rg16f) highp vec2 NormalZ_LightingB;
layout(rg16f) highp vec2 LightingRG;
}gbuf;
out highp vec4 FragColor;
void main()
{
FragColor = resolve(gbuf.Color, gbuf.LightingRG, gbuf.NormalZ_LightingB.y);
}
利用PLS执行延迟渲染的运行示意图如下(注意右上方小方块的红色代表渲染几何数据阶段,绿色代表渲染光照阶段):

除了OpenGL ES,Metal、Vulkan、D3D等图形API也提供了相应的接口、关键字或标记支持GPU Tile上的数据操作。
以上代码显示,延迟着色所需的GBuffer数据一直处于PLS之中,最好解析后返回最终颜色,而不需要将GBuffer写回系统内存(下图)。
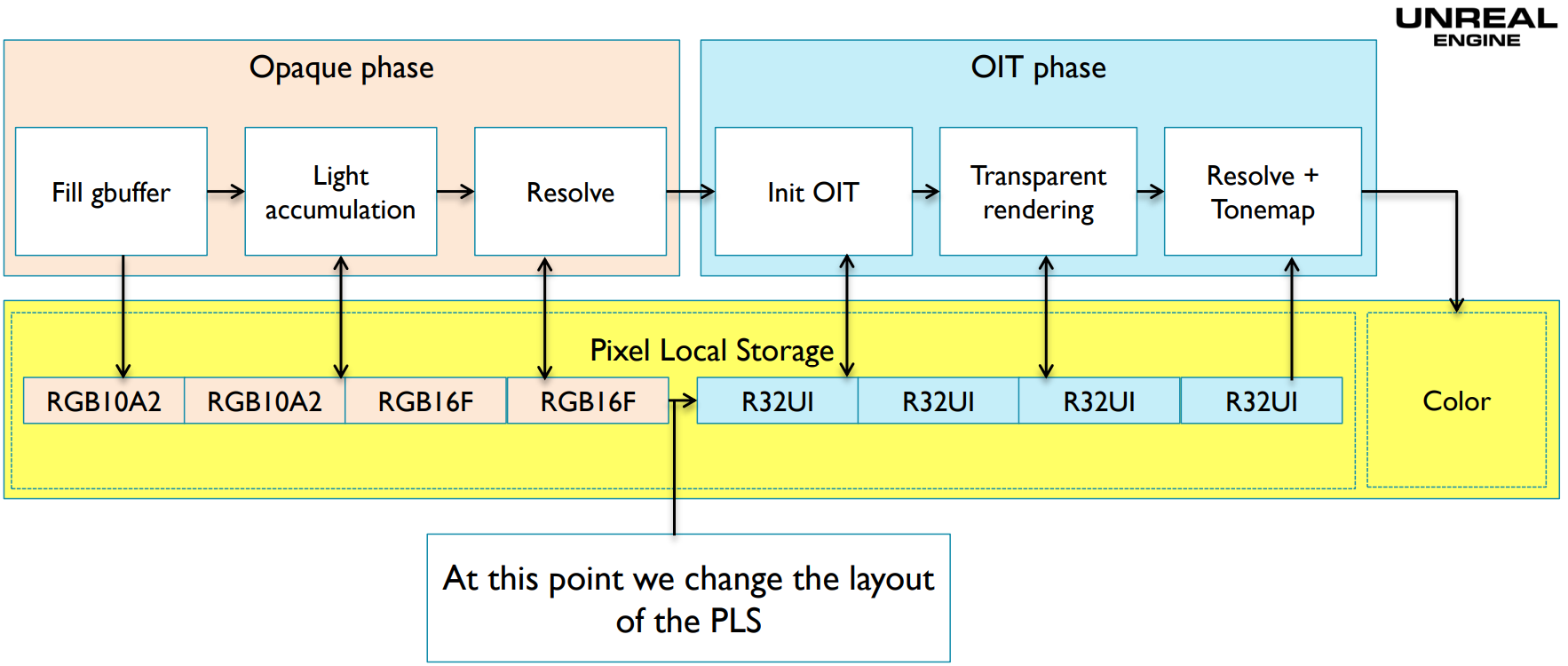
PLS能够提升22%左右的性能:
UE4还利用PLS实现了高效的粒子软混合:

左:粒子一般混合模式;右:粒子软混合模式。
Vulkan也有类似的机制,被称为Subpass,见后面章节。
12.4.13 Subpass
Subpass(子通道)是顺应TB(D)R硬件架构的产物,适用于Vulkan、DX12、Metal等现代图形API,底层原理类似于Pixel Local Storage。
使用Subpass需满足以下几点特殊的要求:
- 所有subpass必须在同一个Render Pass中。
- 不需要采样周边邻域像素。(否则会跨Tile访问数据,无法保持所有数据访问在同一个Tile内)
- GPU支持TB(D)R的硬件架构。
- Vulkan、DX12、Metal等现代图形API。
每个RenderPass和Subpass都可以为每个Attachment指定loadOp和storeOp,以便精确控制它们的存取行为:


subpass的loadOp标记有3种:
- LOAD_OP_LOAD:从全局内存加载Attachment到Tile。
- LOAD_OP_CLEAR:清理Tile缓冲区的数据。
- LOAD_OP_DONT_CARE:不对Tile缓冲区的数据做任何操作,通常用于Tile内的数据会被全部重新,效率高于LOAD_OP_CLEAR。
以上3个标记执行的效率:LOAD_OP_DONT_CARE > LOAD_OP_CLEAR > LOAD_OP_LOAD。Vulkan使用示例代码:
VkAttachmentDescription colorAttachment = {};
colorAttachment.format = VK_FORMAT_B8G8R8A8_SRGB;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
// 标明loadOp为DONT_CARE.
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
subpass的storeOp标记有2种:
- STORE_OP_STORE:将Tile内的数据存储到全局内存。
- STORE_OP_DONT_CARE:不对Tile缓冲区的数据做任何存储操作。
以上两个标记的执行效率:STORE_OP_DONT_CARE > STORE_OP_STORE。Vulkan使用示例代码:
VkAttachmentDescription colorAttachment = {};
colorAttachment.format = VK_FORMAT_B8G8R8A8_SRGB;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
// 标明loadOp为DONT_CARE.
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
// 标明storeOp为DONT_CARE.
colorAttachment.storeOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;
不像OpenGL ES在Shader中有显式的关键字(__pixel_localEXT、__pixel_local_inEXT、__pixel_local_outEXT)来声明Tile内变量,Vulkan为了让Attachment存储到Tile内,必须使用标记TRANSIENT_ATTACHMENT和LAZILY_ALLOCATED:
VkImageCreateInfo imageInfo{VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO};
imageInfo.flags = flags;
imageInfo.imageType = type;
imageInfo.format = format;
imageInfo.extent = extent;
imageInfo.samples = sampleCount;
// Image使用TRANSIENT_ATTACHMENT的标记.
imageInfo.usage = VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT;
VmaAllocation memory;
VmaAllocationCreateInfo memoryInfo{};
memoryInfo.usage = memoryUsage;
// Image所在的内存使用LAZILY_ALLOCATED的标记.
memoryInfo.preferredFlags = VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT;
// 创建Image.
auto result = vmaCreateImage(device.get_memory_allocator(), &imageInfo, memoryInfo, &handle, &memory, nullptr);
使用subpass的loadOp和storeOp进行优化之后,Vulkan的官方测试示例显示可以减少36%的全局内存读取、62%的全局内存写入、7%的片元执行周期:

另外,使用正确的storeOp和loadOp可以高效地在Tile内解析MSAA数据,具体说明如下:
带MSAA的Image(或attachment)必须是瞬态的(transient),通过以下标记可在Render Pass结束时获得解析MSAA后的数据:
- loadOp = LOAD_OP_CLEAR;
- storeOp = STORE_OP_DONT_CARE;
- 使用LAZILY_ALLOCATED的内存标记;
- 在subpass使用pResolveAttachments标记。
对于深度模板的Attachment,也可以获得类似的效果:
- 使用VK_KHR_depth_stencil_resolve标记;
- Vulkan 1.2及以上的API才支持。
通过以上方式可以高效地在Tile内解析掉MSAA数据,而不会传输MSAA数据到全局内存。此外,需要避免使用vkCmdResolveImage接口解析MSAA:
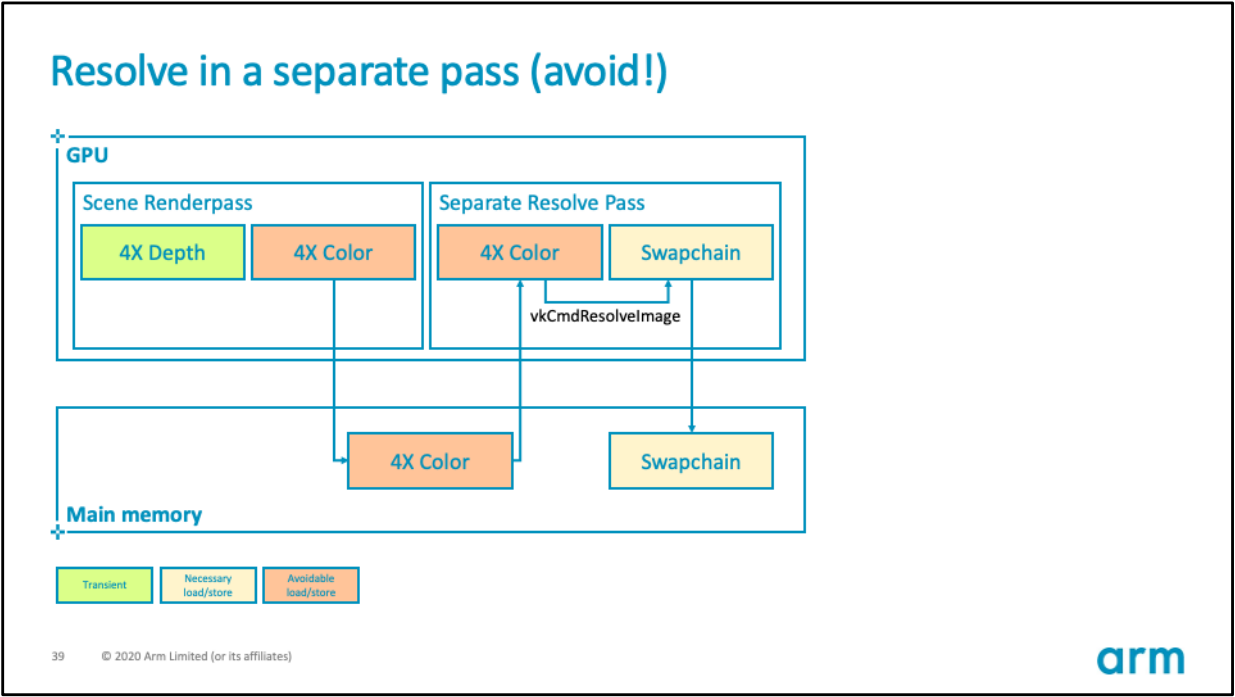

上:使用vkCmdResolveImage解析MSAA的错误示范;下:使用Tile内解析MSAA的正确示范。
使用subpass的loadOp和storeOp对MSAA解析进行优化之后,Vulkan的官方测试示例显示可以减少261%的全局内存读取、440%的全局内存写入!!
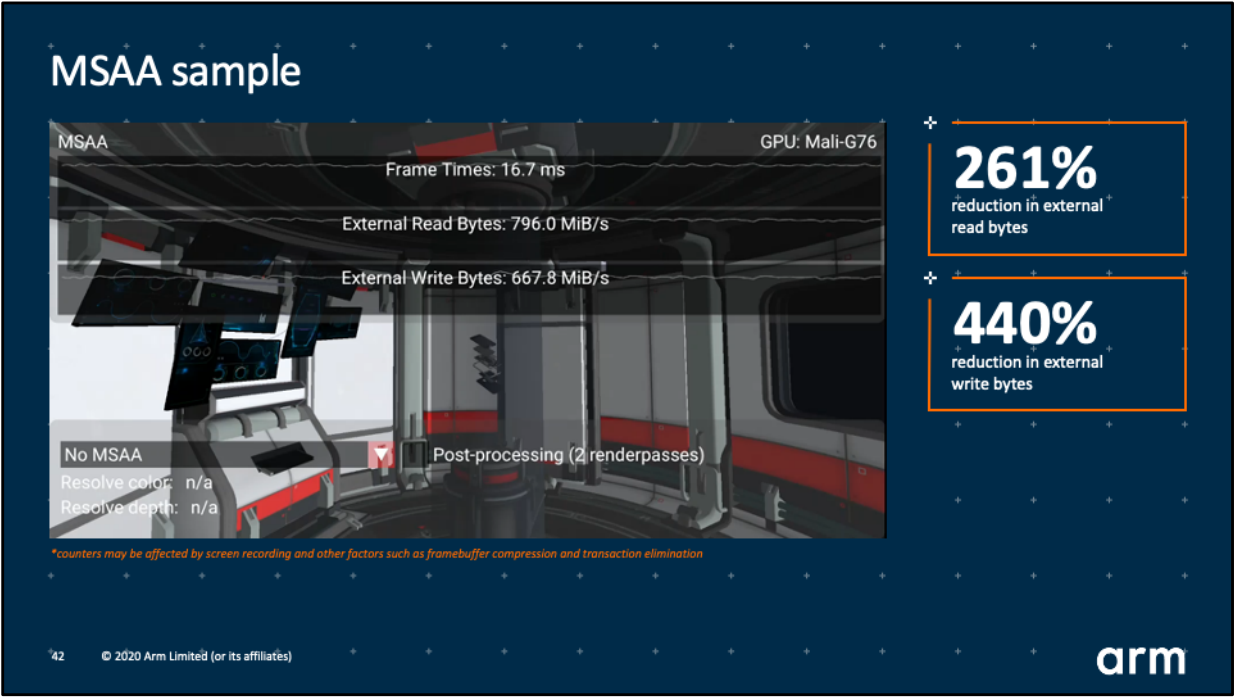
优化效果可见一斑!!还等什么,尽管拿起subpass的有利武器对应用程序进行优化吧!!
更多说明参见Vulkan官方组织KhronosGroup的github:Appropriate use of render pass attachments。
有关UE对Subpass的封装可参见:10.4.4.2 Subpass渲染。
12.4.14 Adaptive Scalable Texture Compression
Adaptive Scalable Texture Compression (ASTC)是Arm和AMD共同研发的一种纹理压缩格式,不同于ETC和ETC2的固定块尺寸(4x4),ASTC支持可变块大小的压缩,从而获得灵活的更大压缩率的纹理数据,降低GPU的带宽和能耗。
ASTC虽然尚未成为OpenGL的标准格式,只是以扩展的形式存在,但目前已经广泛地被主流GPU支持,可谓不是标准的的标准扩展。但在Vulkan中,ASTC已经是标准的特性了。具体地说,ASTC支持以下特性:
格式灵活。ASTC可以压缩1到4个通道之间的数据,包括一个非相关通道,如RGB+A(相关RGB,非相关alpha)。并且块大小可变,如4x4、5x4、6x5、10X5等。
Adreno A5X及以上的GPU芯片支持ASTC以下不同块大小的格式(包含二维和三维):
ASTC_4X4
ASTC_5X4
ASTC_5X5
ASTC_6X5
ASTC_6X6
ASTC_8X5
ASTC_8X6
ASTC_8X8
ASTC_10X5
ASTC_10X6
ASTC_10X8
ASTC_10X10
ASTC_12X10
ASTC_12X12
ASTC_3X3X3
ASTC_4X3X3
ASTC_4X4X3
ASTC_4X4X4
ASTC_5X4X4
ASTC_5X5X4
ASTC_5X5X5
ASTC_6X5X5
ASTC_6X6X5
ASTC_6X6X6
灵活的比特率。ASTC在压缩图像时提供了广泛的比特率选择,在0.89位和8位每texel (bpt)之间。比特率的选择与颜色格式的选择无关。而传统的ETC等格式只能是整数的比特率。
高级格式支持。ASTC可以压缩图像在低动态范围(LDR)、LDR sRGB、高动态范围(HDR)颜色空间,还可以压缩3D体积纹理。
改善图像质量。尽管具有高度的格式灵活性,但在同等比特率下,ASTC在图像质量上的表现优于几乎所有传统的纹理压缩格式(ETC2、PVRCT和BC等)。
格式矩阵全覆盖。在ASTC尚未出现之前,传统的纹理压缩格式支持的颜色格式和比特率的组合相对较少,如下图所示:
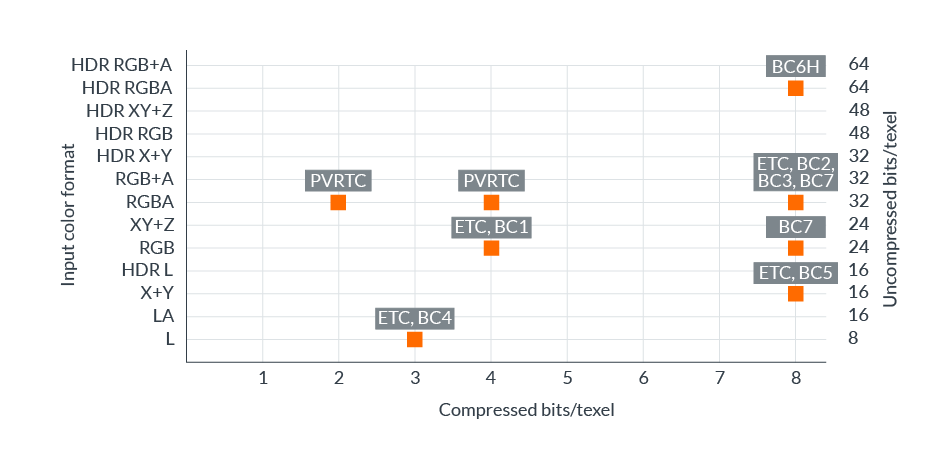
以上格式还受图形API或操作系统限制,因此任何单一平台的压缩选择都非常有限。ASTC的出现解决了上述问题,几乎实现了所需格式矩阵的完整覆盖,为内容创建者提供了广泛的比特率选择。下图显示了可用的格式和比特率:
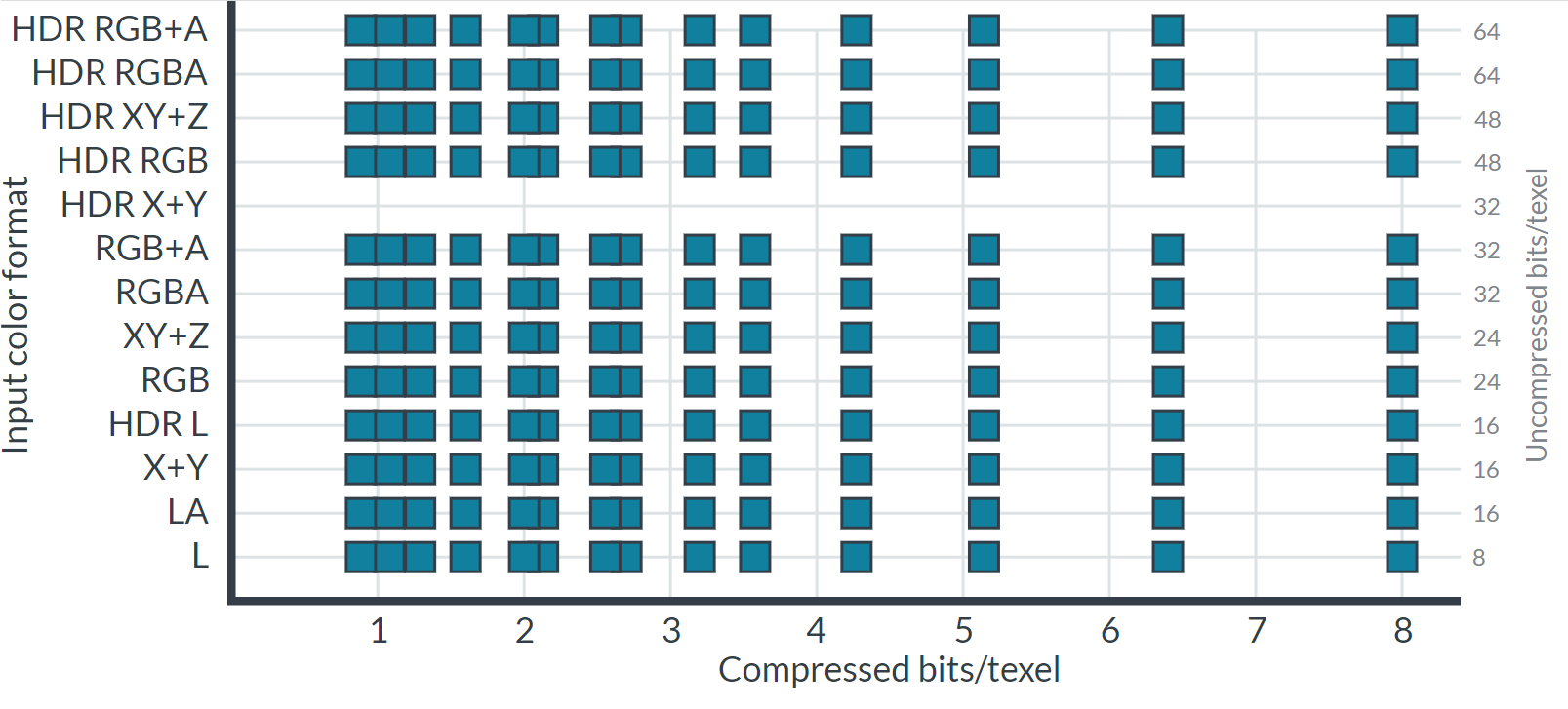
ASCT是如何达成上述目标的呢?答案就在于ASTC用了一种特殊的压缩算法和数据结构。ASTC的算法技术要点和阐述如下:
块压缩
实时图形的压缩格式需要能够快速有效地将随机样本转换为纹理,因此对压缩技术必须做到以下几点:
- 仅给定一个采样坐标,计算内存中数据的地址。
- 能够在不解压太多周围数据的前提下解压随机采样。
所有当代实时压缩格式(包括ASTC)使用的标准解决方案,是将图像分割成固定大小的像素块,然后每个块被压缩成固定数量的输出位。这保证Shader以任意顺序快速访问texels,并具有良好的解压成本。
ASTC中的2D Block footprints范围从4x4 texels到12x12 texels,它们都被压缩成128位输出块。通过将128位除以占用空间中的像素数,便能得到格式比特率,这些比特率范围从8 bpt(\(128 / (4\cdot4)\))到0.89 bpt(\(128 / (12\cdot12)\))。下面是不同比特率的画质对比图:

颜色端点(Color endpoint)
块的颜色数据被编码为两个颜色端点之间的梯度。每个texel沿着梯度选择一个位置,然后在解压期间插值。ASTC支持16色端点编码方案,称为端点模式( endpoint mode)。端点模式的选项允许改变以下内容:
颜色通道的数量。 例如:亮度、亮度+alpha、rgb或rgba。
编码方法。 例如:直接、基数+偏移、基数+比例或量化级别。
数据范围。 例如:低动态范围或高动态范围。
允许逐块选择不同的端点模式和端点颜色BISE量化级别。
颜色分区(Color partition)
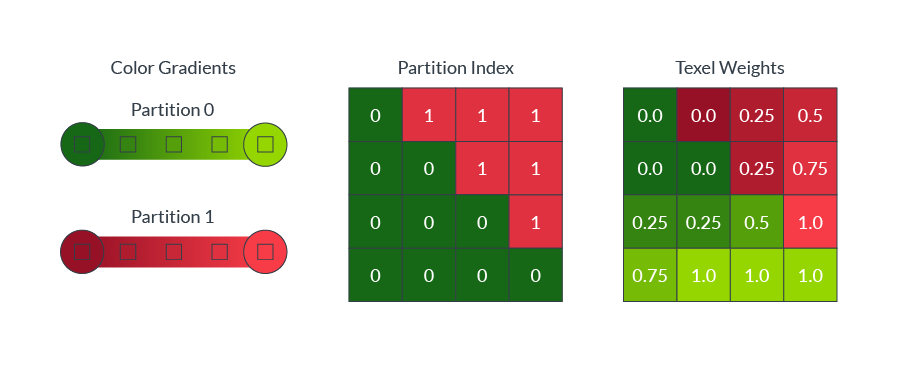
块内的颜色通常是复杂的,单色渐变通常不能准确地捕捉块内的所有颜色。例如,躺在绿色草地上的红球,需要进行两种颜色的划分,如下图所示:
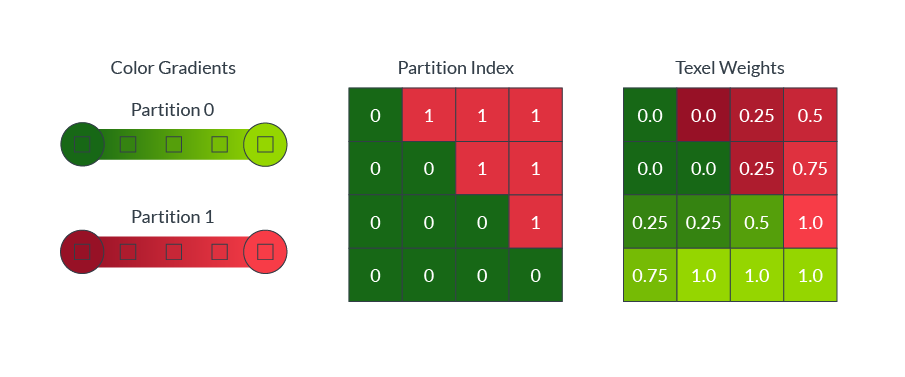
ASTC允许单个块最多引用四个颜色梯度,称为分区。为了解压,每个texel被分配到一个单独的分区。
直接存储每个texel的分区分配将需要大量的解压缩硬件来存储所有块大小。 相反,ASTC使用分区索引作为seed值,以算法生成一系列模式。压缩过程为每个块选择最佳匹配的模式,然后块只需要存储最佳匹配模式的索引。下图显示了8 × 8块大小的2个(图像顶部)、3个(图像中间)和4个(图像底部)分区生成的模式:
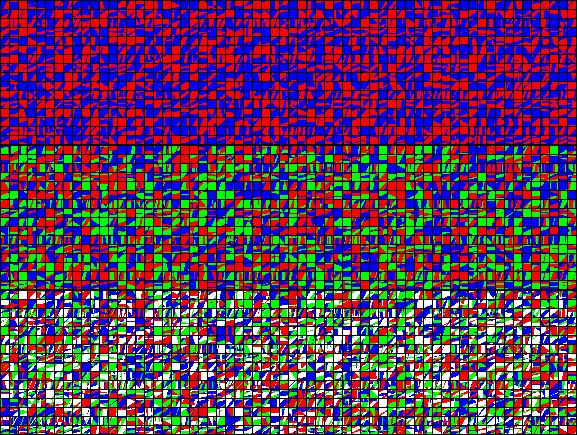
可以在每个块的基础上选择分区的数量和分区索引,并且可以在每个分区上选择不同的颜色端点模式。
颜色编码
ASTC使用渐变来指定每个texel的颜色值。每个压缩块存储渐变的端点颜色,以及每个像素的插值权重。在解压过程中,每个像素的颜色值是根据每个像素的权重在两个端点颜色之间插值生成的。下图显示了各种texel权重的插值:
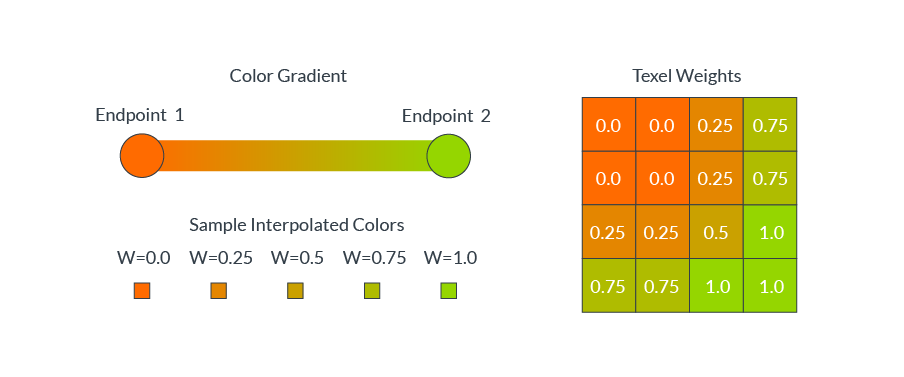
方块通常包含复杂的颜色分布,例如一个红色的球放在绿色的草地上。在这些情况下,单一的颜色梯度不能准确地代表所有不同的texel颜色值。 ASTC允许一个块定义多达四个不同的颜色梯度,称为分区(partition),并可以将每个texel分配到一个单独的分区。下图显示了分区索引是如何为每个texel指定颜色渐变的(两个分区,一个用于红球像素,一个用于绿草像素):
存储字符表(Storing alphabet)
尽管每个像素的颜色和权重值理论上是浮点值,但可以直接存储实际值的位太少了。为了减小存储大小,必须在压缩期间对这些值进行量化。例如,如果对0.0到1.0范围内的每个texel有一个浮点权重,可以选择量化到5个值:0.0、0.25、0.5、0.75和1.0,再使用整数0-4来表示存储中的这五个量化值。
一般情况下,如果选择量化N层,需要能够有效地存储包含N个符号的字符表中的字符。一个N个符号表包含每个字符的log2(N)位信息。如果有一个由5个可能的符号组成的字符表,那么每个字符包含大约2.32位的信息,但是简单的二进制存储需要四舍五入到3位,这浪费了22.3%的存储容量。下图表显示了使用简单的二进制编码存储任意N个符号字符表所浪费的位空间百分比:
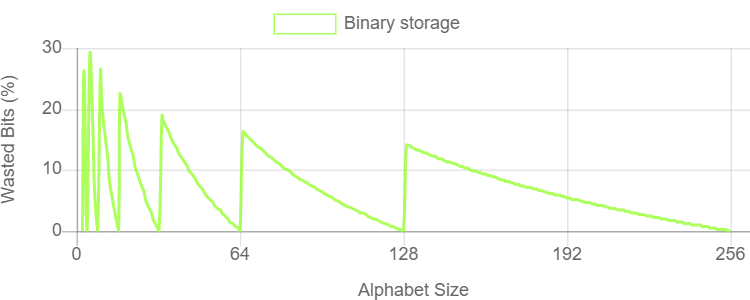
上述图表显示,对于大多数字符大小,使用整数位每个字符浪费大量的存储容量。对于压缩格式来说,效率是至关重要的,因此这是ASTC需要解决的问题。
一种解决方案是将量化级别四舍五入到2的下一次方,这样就不用浪费额外的比特了。然而,这种解决方案迫使编码器消耗了本可以在其它地方使用获得更大收益的比特位,因此此方案降低了图像质量,并非最优解决方案。
五元和三元数(Quint and trit)
一个更有效的解决方案是将三个五元字符组合在一起,而不是将一个五元字符组合成三个位。五个字母中的三个字符有\(5^3=125\)个组合,包含6.97位信息。我们可以以7位的形式存储这三个quint字符,而存储浪费仅为0.5%。
我们也可以用类似的方法构造一个三符号的字母表,称为三个一组,并将五个一组的三个一组字符组合起来。每个字符组有\(3^5=243\)个组合,包含7.92位信息。我们可以以8位的形式存储这5个trit字符,而存储浪费仅为1%。
有界整数序列编码(Bounded Integer Sequence Encoding)
ASTC使用的有界整数序列编码(Bounded Integer Sequence Encoding,BISE)允许使用最多256个符号的任意字符存储字符序列。每一个字符大小都是用最节省空间的位、元和五元进行编码的。
- 包含最多\(2^n-1\)个符号的字母表可以使用每个字符n位进行编码。
- 包含最多\(3\cdot(2^n - 1)\)个符号的字母表可以使用每个字符用n位(m)和一个trit (t)进行编码,并使用方程\((t \cdot 2^n) + m\)重建。
- 包含最多\(5\cdot(2^n - 1)\)个符号的字母表可以使用每个字符用n位(m)和一个quint (q)进行编码,并使用方程\((q \cdot 2^n) + m\)重建。
当序列中的字符数不是3或5的倍数时,必须避免在序列末尾浪费存储空间,因此在编码上添加了另一个约束。如果序列中要编码的最后几个值为零,则已编码位串的最后几个位也必须为零。理想情况下,非零位的数目很容易计算,并且不依赖于先前编码值的大小。这在压缩期间很难妥当处理,但也是可能解决的。意味着不需要在位序列结束后存储任何填充,因为我们可以安全地假设它们是零位。
有了这个约束,通过对bit、trit和quint的智能打包,BISE使用固定位数对N个符号字母表中的S个字符串进行编码:
- S最大值为\(2^N - 1\) ,使用 \(N \cdot S\)位。
- S最大值为\(3\cdot2^N - 1\) ,使用 \(N\cdot S + \text{ceil}(8S / 5)\)位。
- S最大值为\(5\cdot2^N - 1\) ,使用 \(N\cdot S + \text{ceil}(7S / 3)\)位。
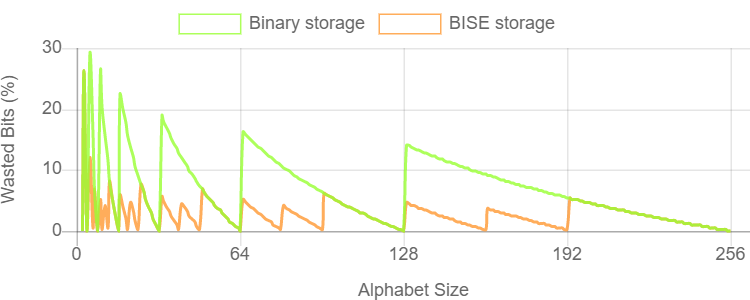
压缩器选择为所存储的字母大小产生最小存储空间的选项。一些使用二进制,一些使用bit和trit,还有一些使用bit和quint。下图显示了BISE存储相对于二进制存储的效率增益:
此外,在压缩过程中,会为每个块选择最佳编码,在计算texel权重值时,除了上述的BISE,还有双平面权重(Dual-plane weights)算法。
ASTC免费自由使用,容易集成,被众多主流系统和硬件支持。支持ASTC需要以下OpenGL扩展:
GL_AMD_compressed_ATC_texture
GL_ANDROID_extension_pack_es31a
相比传统的纹理压缩格式(ETC、BC、PVRTC等),使用ASTC的压缩效果非常明显,画质更贴近原图,压缩率更高:


左:原始法线贴图;中:压缩成ETC的效果;右:压缩成ASTC的效果。
由此带来的直观收益就是占用更少的内存、带宽,每帧大约能减少24.4%的带宽:

关于ASTC的更多详情可参看Adaptive Scalable Texture Compression。
12.4.15 big.LITTLE Core
移动端CPU(注意不是GPU,如Qualcomm Keyo CPU)存在big.LITTLE的组合架构,最早由Arm提出。此架构同时存在big core和little core,big core为了高性能而优化,little core为了能量消耗而优化。
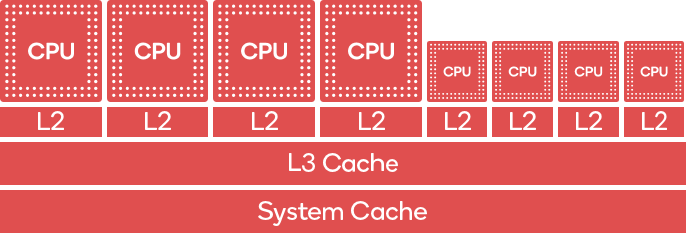
Qualcomm Keyo CPU的big.LITTLE架构。左边4个是big core,执行性能高但耗电量较大,右边4个是little core,执行性能较低但较省电。
big.LITTLE架构的特点如下:
- 通过将两个非常不同的处理器组合在一个SoC中,以应对智能设备在性能方面需求的变化。
- big.LITTLE软件自动处理任务分配到适当的CPU核。操作系统直接感知系统中的高性能和高效率核心,并可以根据性能需求将每个任务动态分配到合适的核心。
理解以及如何使用这种架构的特性对于优化性能和功率效率至关重要,优化得好,将获得更长的游戏时间和游戏的散热。
为了提升big.LITTLE的效率,尽量优先使用little core。假设帧预期时间为16ms (60FPS),开发者可以使用工具(如Snapdragon Profiler)来识别任务,将其移至LITTLE core。例如,一款带有布料模拟的游戏,在big core上执行需要3毫秒,而在little core执行可能需要10毫秒。只要这个执行时间是可以接受的(本例的帧预算是16ms),应该被移到little core中,减少对big core的利用,提高电力效率。
移动端SoC制造厂商(如Qualcomm、Arm)通常提供了相关SDK和API给开发者指定任务在哪种类型的CPU核上运行,具体可参看:Controlling Task Execution。
12.4.16 其它技术要点
除了以上小节涉及的技术要点,实际上移动端芯片或图形API还存在很多其它技术,比如SIMD、SIMT、Unified shader architecture(统一着色器架构,见下图)、Scalar architecture(标量着色器架构)、Tripipe(下下图)等等。更多技术细节可以阅读笔者的另一篇关于GPU的文章:深入GPU硬件架构及运行机制。
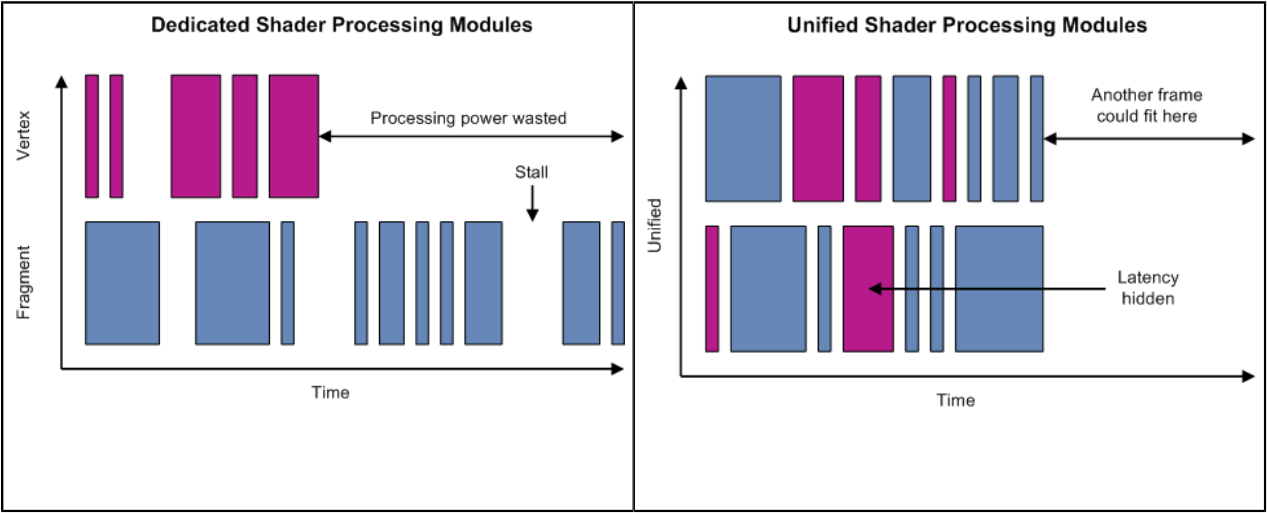
左:分离式着色器处理单元,右:同意着色器处理单元。可见后者的处理器基本处于满负荷运行,从而减少等待和空载,提升整体运算能力。

Mali GPU中的Tripipe结构示意图,包含3个运算单元、1个存取单元和1个纹理单元,拥有128bit带宽,2倍FP64、4倍FP32、8倍FP16的操运算效率。
另外,OpenGL ES还有不少扩展可以提升性能,比如针对纹理子区域读写操作:
KHR_partial_update
EXT_buffer_age
此扩展允许调用者利用Backbuffer的时间指定多个方框绘制帧内容。此技术类似于TE,但不会写数据到Tile缓冲区。
12.5 移动GPU架构和机制
本章将阐述移动端GPU的硬件架构和运行机制。
12.5.1 移动GPU概述
移动端GPU由于便携性,需要考虑PPA三个指标,因此设计一款高性能的GPU异常困难,具有高度的挑战性。目前主要有Qualcomm、Arm、Imagination Tech等GPU制作厂商,他们的代表作分别是Adreno、Mali、PowerVR。移动端的GPU通常集成在SoC之中,和CPU、内存等器件形成有机的硬件架构体系。
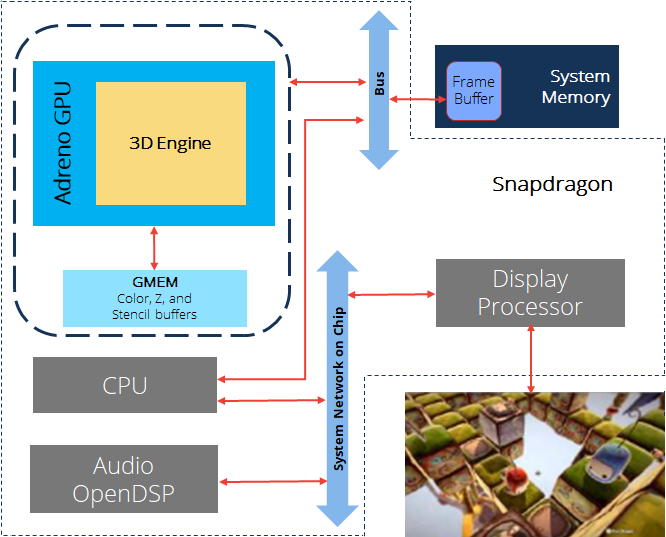
Snapdragon框架图。包含了了CPU、Adreno GPU、内存等元件,通过Bus、Network等进行数据交互。
随着时间推移,移动端硬件随之发展,越来越多新的图形API和渲染特性也被迁移到移动端,具体表现在:
主流GPU支持DX12、Vulkan1.2、OpenGL ES 3.2等图形API,支持VRS、Mesh Shading、Ray Tracing、WaveMath等新的渲染特性。
GPU吞吐量和计算能力大幅提升,包含ALU、Texture、Memory等方面:
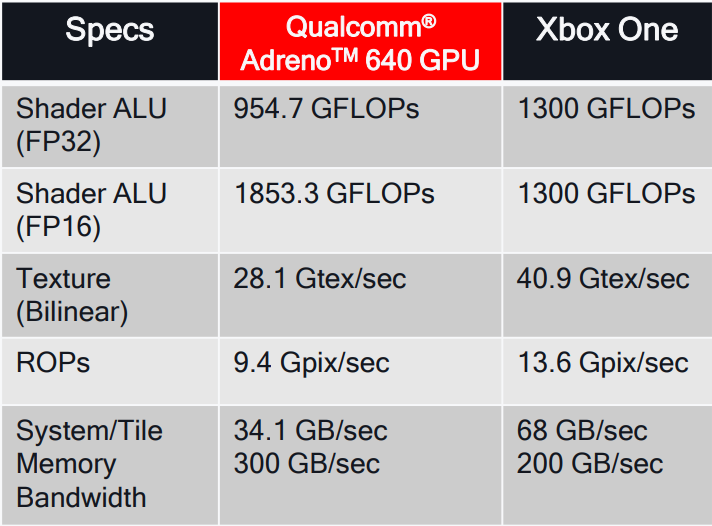
Qualcomm Adreno 640 GPU的性能一览,右侧是Xbox One的性能数据。
内存带宽增加,能耗比提升。
电量节省特性大量涌现。
- Render Target Compression, FP16 math ops, ASTC, Vulkan Subpasses。
- UBWC、AFBC、IDVS、PLS等。
移动端Soc被广泛地应用于VR应用,并带来了诸多专用优化技术。
Compute Shader能力的完善和提升,对OpenCL库的支持趋于完善。
并行数量越来越多,吞吐量提升。
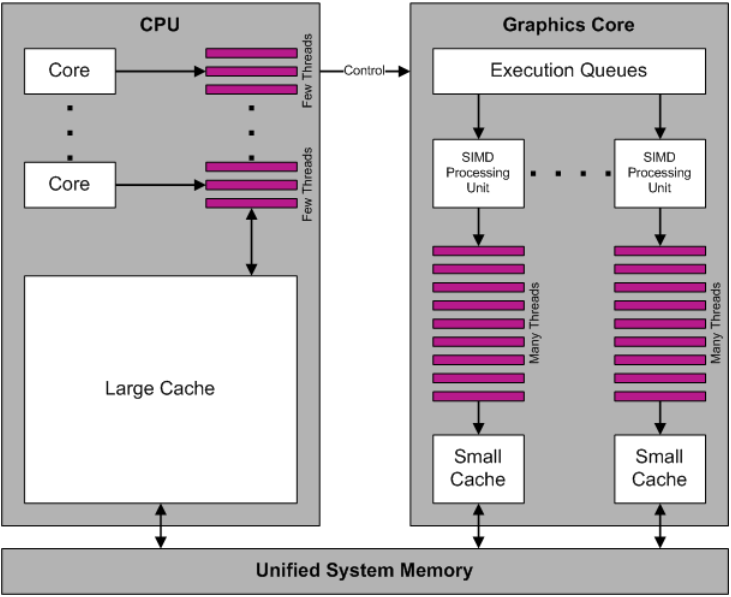
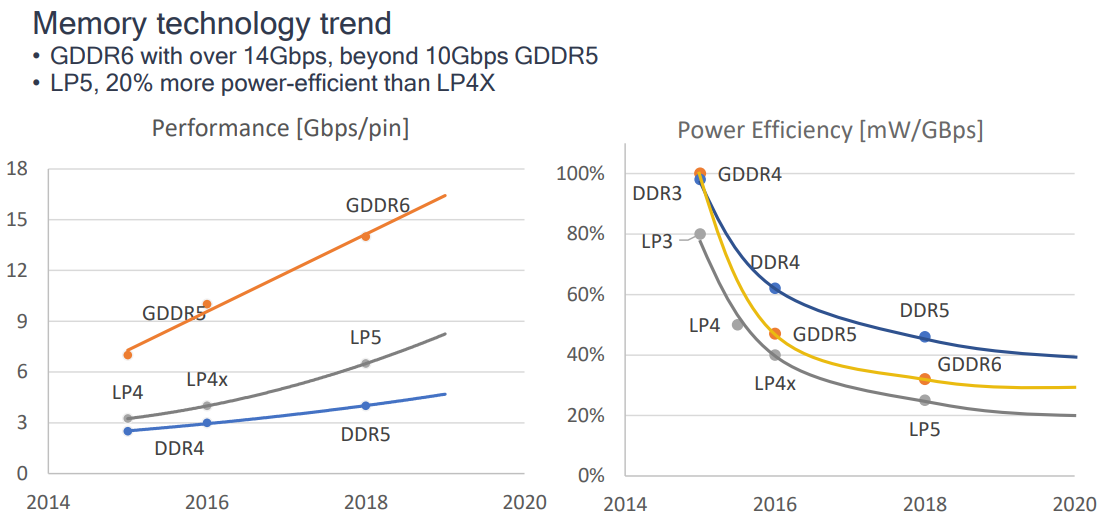
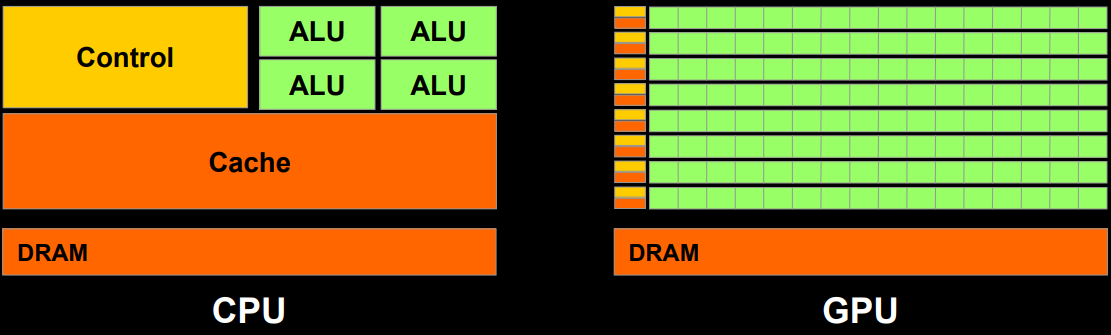
CPU和GPU运行示意图,可知GPU缓存小但拥有数量众多的线程。
移动端GPU架构内的相关概念和名词解析如下:
| 概念 | 全称 | 解析 |
|---|---|---|
| AMBA | Advanced Microcontroller Bus Architecture | 高级微控制器总线架构 |
| AXI | AMBA Advanced eXtensible Interface | AMBA高级可扩展接口 |
| APB | AMBA Advanced Peripherial Bus | AMBA高级外围总线 |
| ACE | AMBA AXI Coherency Extensions | AMBA AXI一致性扩展 |
| GPU | Graphics Processing Unit | 图形处理单元 |
| VPU | Video Processing Unit | 视频处理单元 |
| DPU | Display Processing Unit | 显示处理单元 |
| ISA | Instruction Set Architecture | 指令集架构 |
| SIMD | Single Instruction Multiple Data | 单指令多数据 |
| ISP | Image Synthesis Processor | 合成图像处理器 |
| TSP | Texture and Shading Processor | 纹理和着色处理器 |
12.5.2 移动GPU运行机制
由于每个GPU厂商、每个系列、每代产品的运行机制都可能存在不同,本节就以Mali GPU为例,阐述移动端的GPU运行机制。首先说明一下Arm Mali T880 GPU硬件架构的参数,如下:
16个Shader Core(SC)。
Tile尺寸为16x16(内部4x4~32x32)。
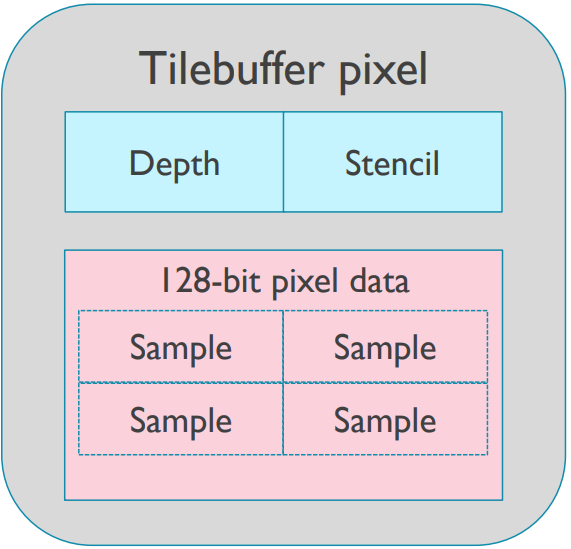
- 可存储深度模板缓冲,128位像素数据。
- 每像素拥有16字节,原始位访问(Raw bit access)。
支持GLES3.2,Vulkan 1.0,CL 1.2,DX 11.2。
4x、8x、16x的MSAA。
Arm Mali T880 GPU硬件架构示意图及其功能描述。
对于Mali GPU,驱动程序通过Job Manager(作业管理器)提交绘制任务,由Job Manager向GPU的绘制硬件创建并提交任务,它们通过内部连接元件交互。

应用程序、驱动程序、GPU、DPU等各个层级的交互简化后的示意图如下:
应用程序、驱动程序、GPU等交互示意图。其中eglSwapBuffers表示帧结束,App会属性绘制命令给驱动程序,驱动程序会编排任务给GPU,GPU绘制完成之后提交结果给DPU。注意它们各个层级之间存在着延时。
首先考察应用层和驱动层的交互。应用程序在调用图形API(如OpenGL ES)时,驱动程序会创建对应的资源架构图:
GPU内部存在以下几种Job(作业)类型:
| 作业名称 | 缩写 | 描述 |
|---|---|---|
| Vertex Job | V | 执行一组顶点的顶点着色器。 |
| Tiler Job | T | Tiling Unit(分块单元,固定功能)分拆转换后的图元到覆盖的分块。 |
| Fragment Job | F | 运行在所有Tile的单一渲染目标的工作。 |
| Job Chain | - | 作业链。 |
以下是GPU作业链的其中一种情形:

作业链示意图。其中作业之间存在依赖关系(箭头所示),只有前序任务完成了,才行执行下一个作业。
CPU、GPU的交互示意图如下,其中CPU通过APB提交任务给GPU,GPU内的Job Manager通过AXI存取共享内存,而CPU也可以通过AXI存取共享内存。
GPU内的Job Manager创建和分配任务示意图如下:

Job Mananger运行示意图。图中分配了3个顶点作业、1个分块作业和2个着色作业。其中分块作业依赖于顶点作业。
对于Shader Core而言,Mali的结构是Tripipe,是统一着色器架构,可以执行VS或PS:
更进一步地,顶点作业运行示意图如下。顶点线程不会写入tile缓冲区,但会直接访问主内存,顶点任务包含了4n个顶点。
片元作业示意图如下:
Fragment Work分为Front-End、Tripipe、Back-End三个阶段。成功经过光栅化、Early-Z、FPK的像素会由Fragment Thread Creator创建线程(以Quad为单位,即2x2个线程),进入Tripipe着色,然后进入Late-Z、混合,最后写入Tile内存。
但是,不是所有移动端GPU的运行机制都跟Mali的一模一样,比如PowerVR的就会诸多不同点:
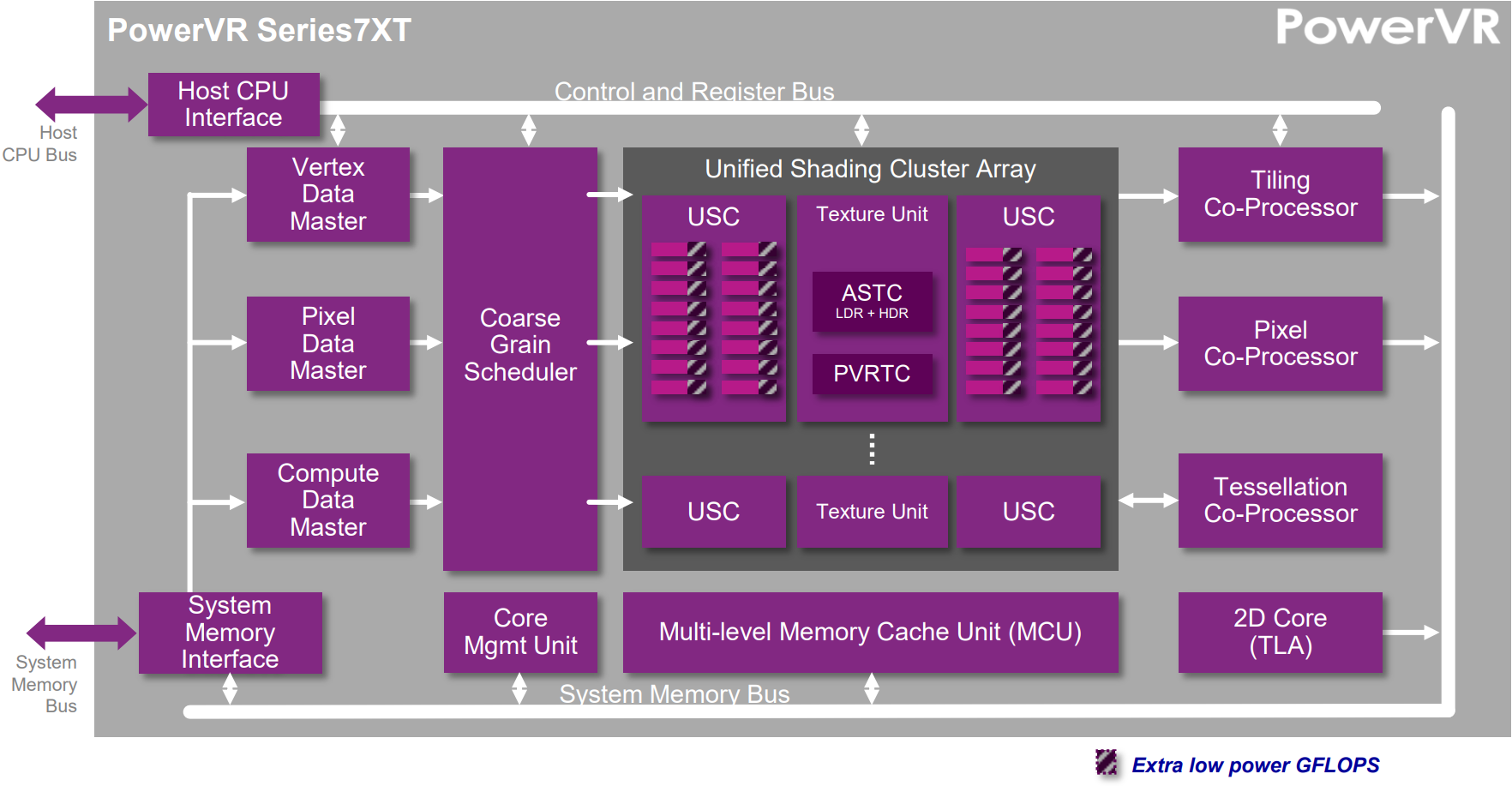
PowerVR Series 7XT架构示意图。
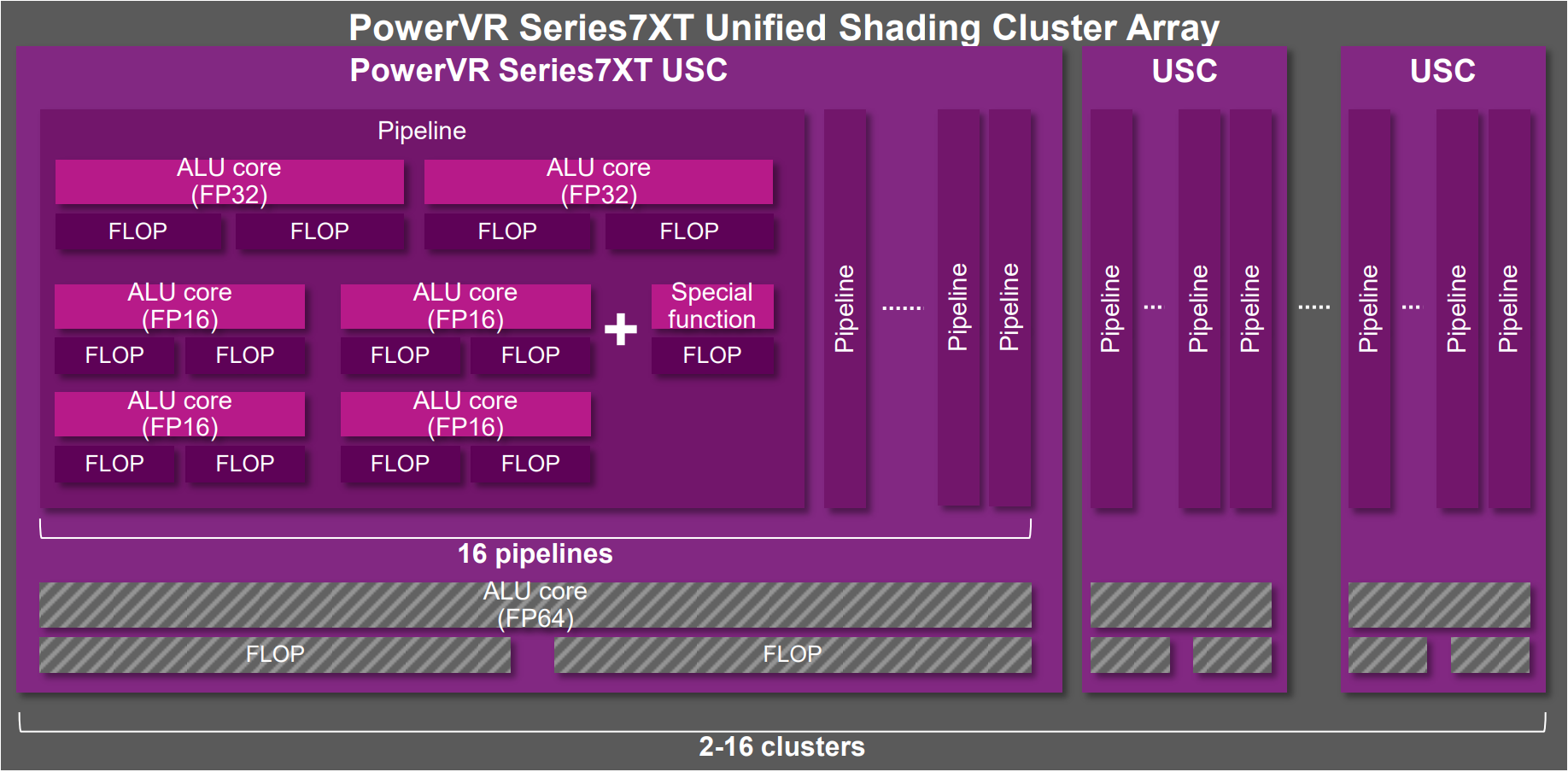
PowerVR Series 7XT统一着色器簇组架构图。
更多PowerVR的介绍可参见:
- PowerVR Series5 Architecture Guide for Developers
- PowerVR Graphics - Latest Developments and Future Plans
12.5.3 并行、卡顿和延时
随着摩尔定律的放缓,现代移动端的SoC朝着多核高并行的方向发展,应用程序能否利用多核性能提升并行效率,很大程序上决定了它的品质和用户体验。
和并行效率相反,卡顿和延时是实时应用(如游戏)的天敌。卡顿意味着帧率低,应用程序运行不够流畅;延时则意味着操作不能及时响应,降低产品的用户体验,甚至会导致用户严重流失。
无论是在PC端还是移动端,渲染管线需要处理的场景越来越复杂,加上多线程等特性,因此或多或少存在着等待、卡顿(Stall)等现象,由此导致了延时(Latency)。这种现象在TB(D)R盛行的移动端渲染管线中尤为明显。
造成卡顿和延时的原因有客观和主观。客观的原因指多线程的协同等待、同步,驱动程序的优化,GPU内部执行机制的良性优化等。而主观方面是指那些没有使用符合特定渲染机制的接口、标记、状态或资源,这类是可以避免和优化的。
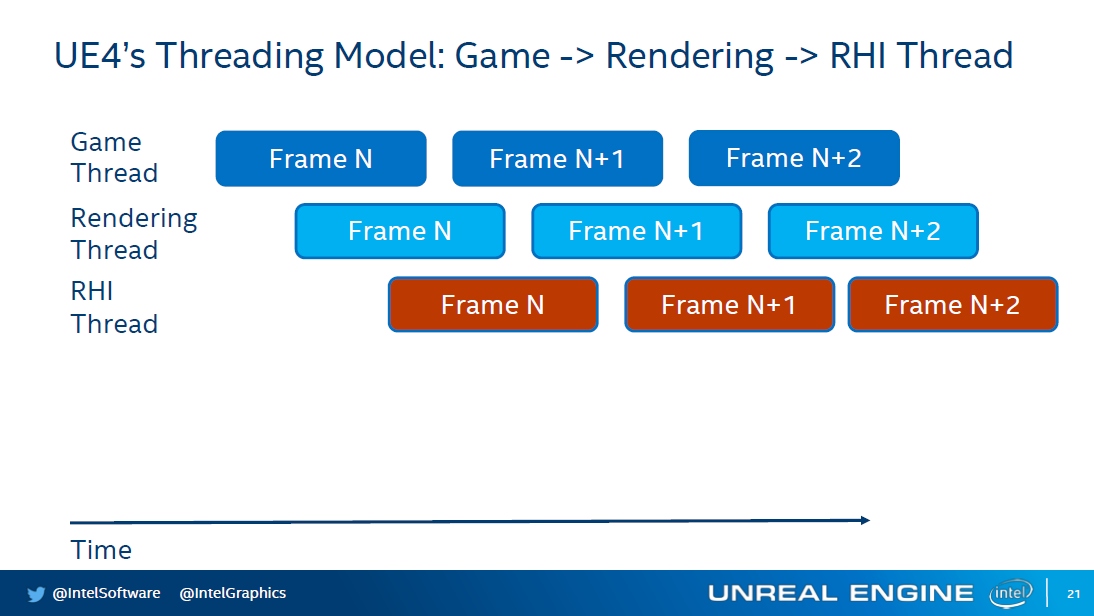
UE存在游戏线程、渲染线程、RHI线程,后面的线程通常会比前面的线程延时一些,它们之间还存在同步和等待,防止前面的线程领先太多时间。

应用程序、驱动程序、GPU、显示器之间的延时示意图,下层会比上层落后一段时间。
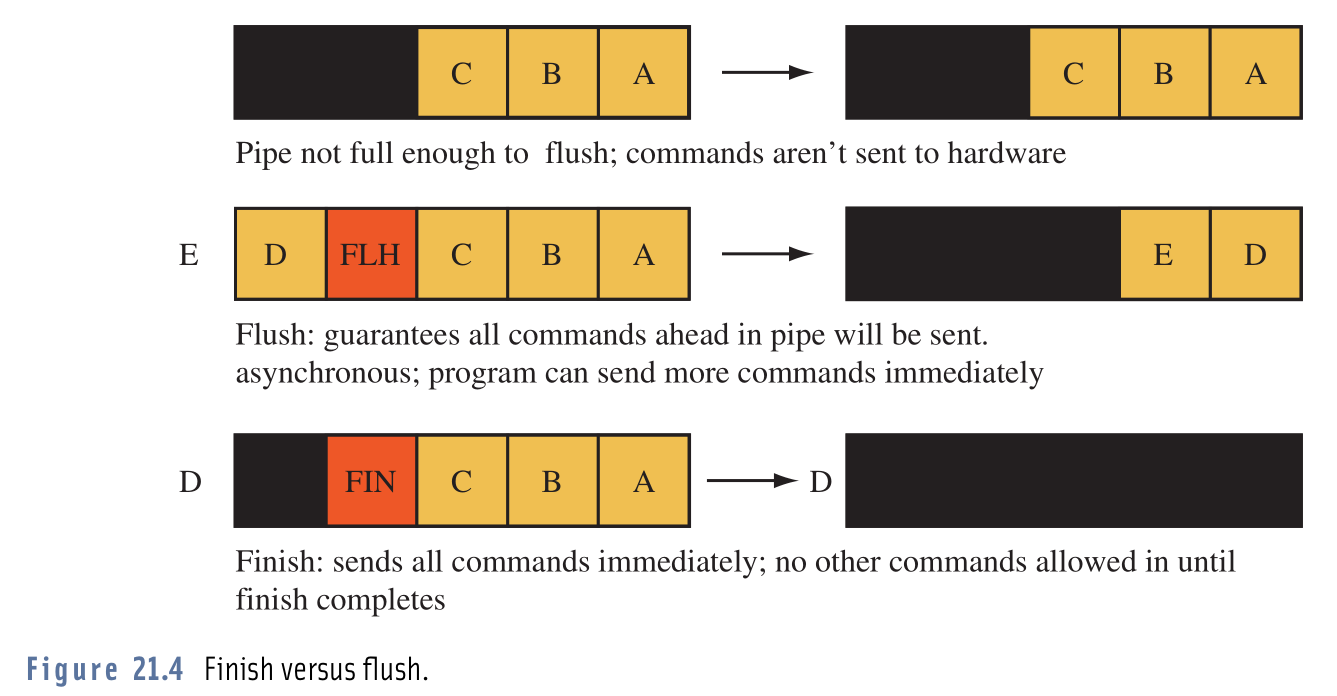
OpenGL的glFinish和glFlush执行示意图。其中glFlush调用之后,不一定会立即刷新渲染指令到GPU,只有当驱动器的渲染命令缓冲区满了才会,因此也可能导致延时。
移动端GPU的TB(D)R较普通的做法是将Binning Pass和Rendering Pass放在不同的帧处理,以提升并行效率,但也会导致延时:
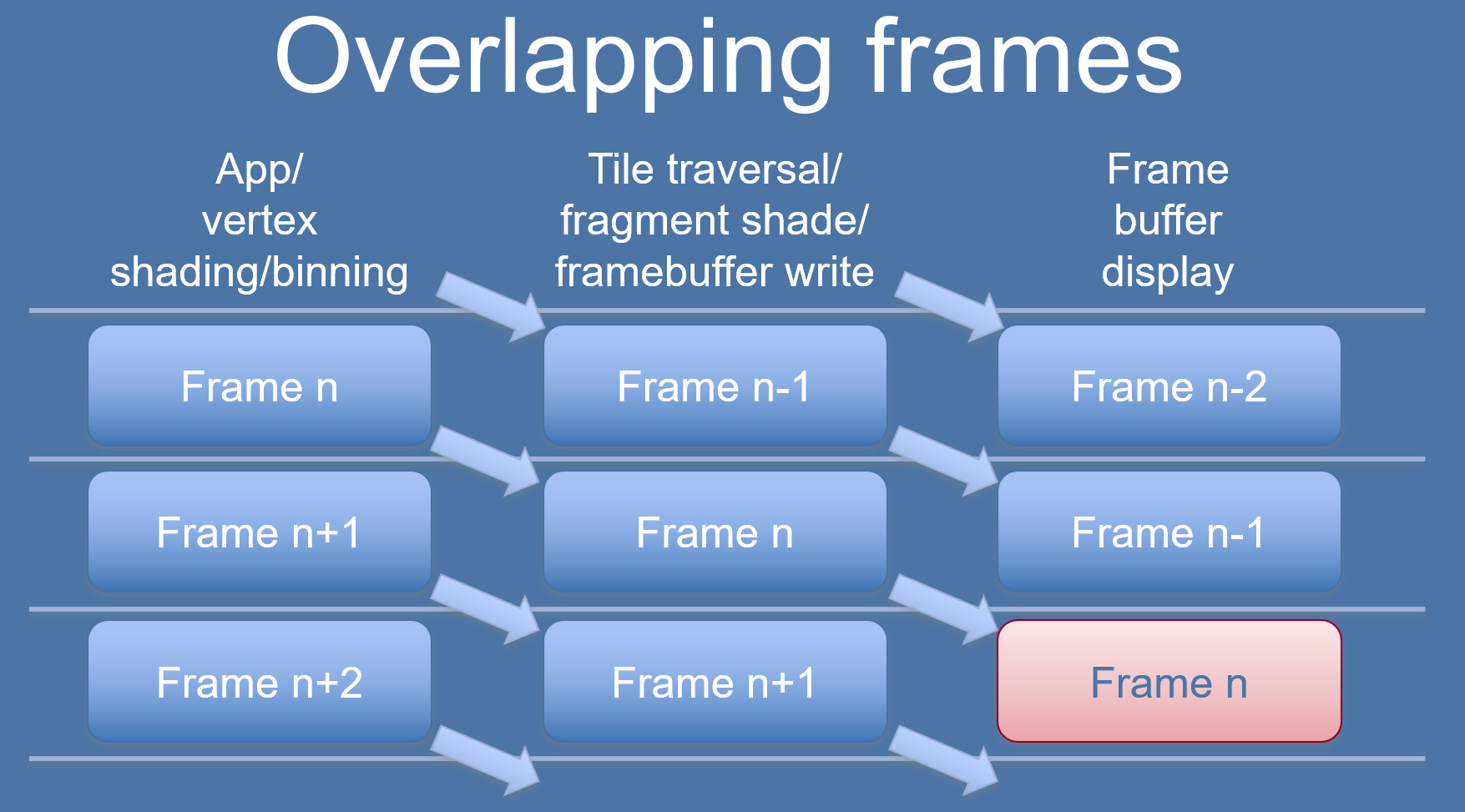
TBR架构中的Binning、Rendering错帧处理示意图。
以上是完美错帧处理的情况,如果有以下情形之一,则会打乱TBR的执行节奏,导致更严重的Stall和延时:
Binning依赖上一帧的数据或资源。
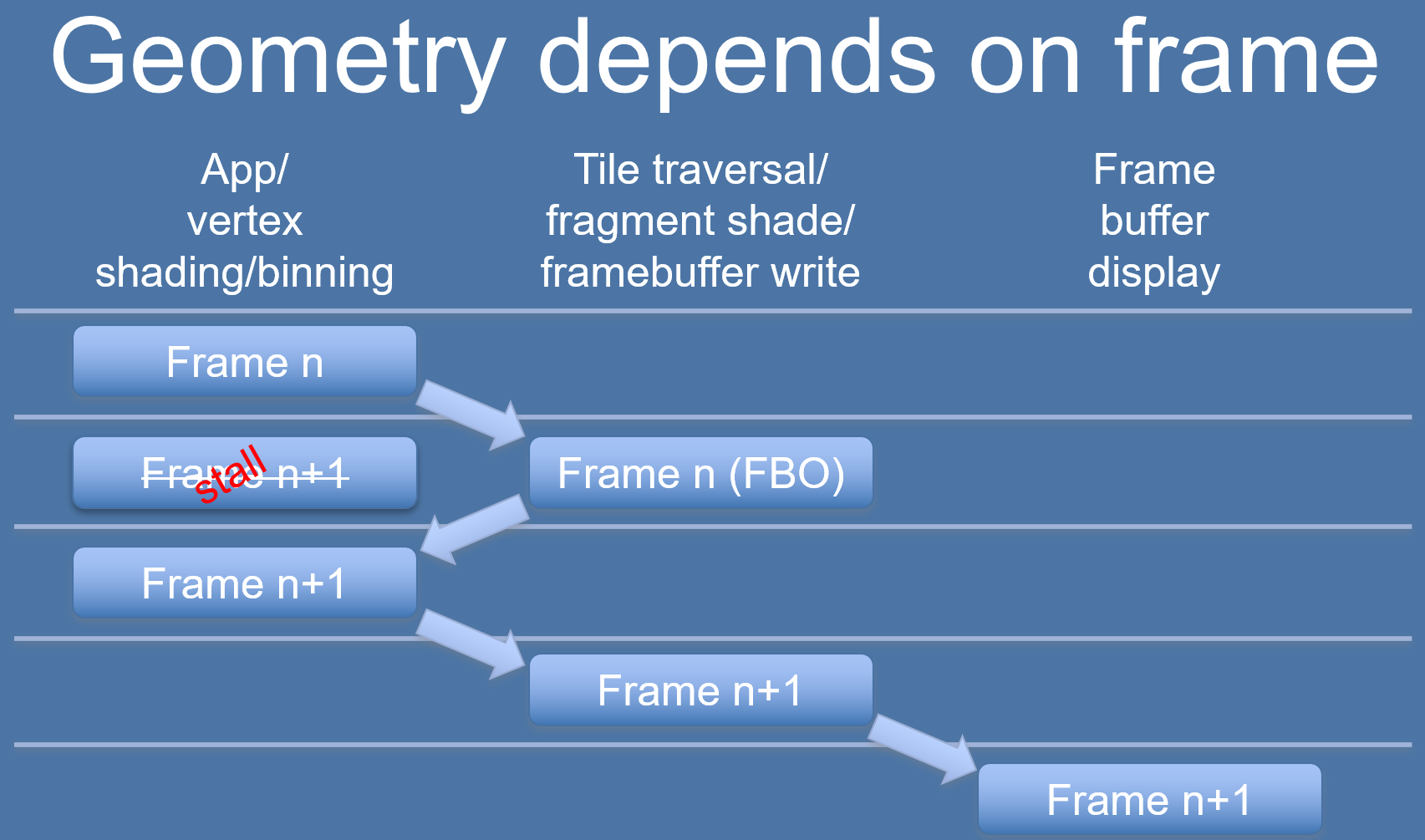
n+1帧的binning需要依赖n帧的Rendering渲染结果,所以不能和n帧的Rendering Pass并行处理,只能延时到下一帧。
这种情况可以通过延时使用解决,比如N帧的binning使用N-1帧的Rendering结果。下图是实时环境立体图的优化案例:
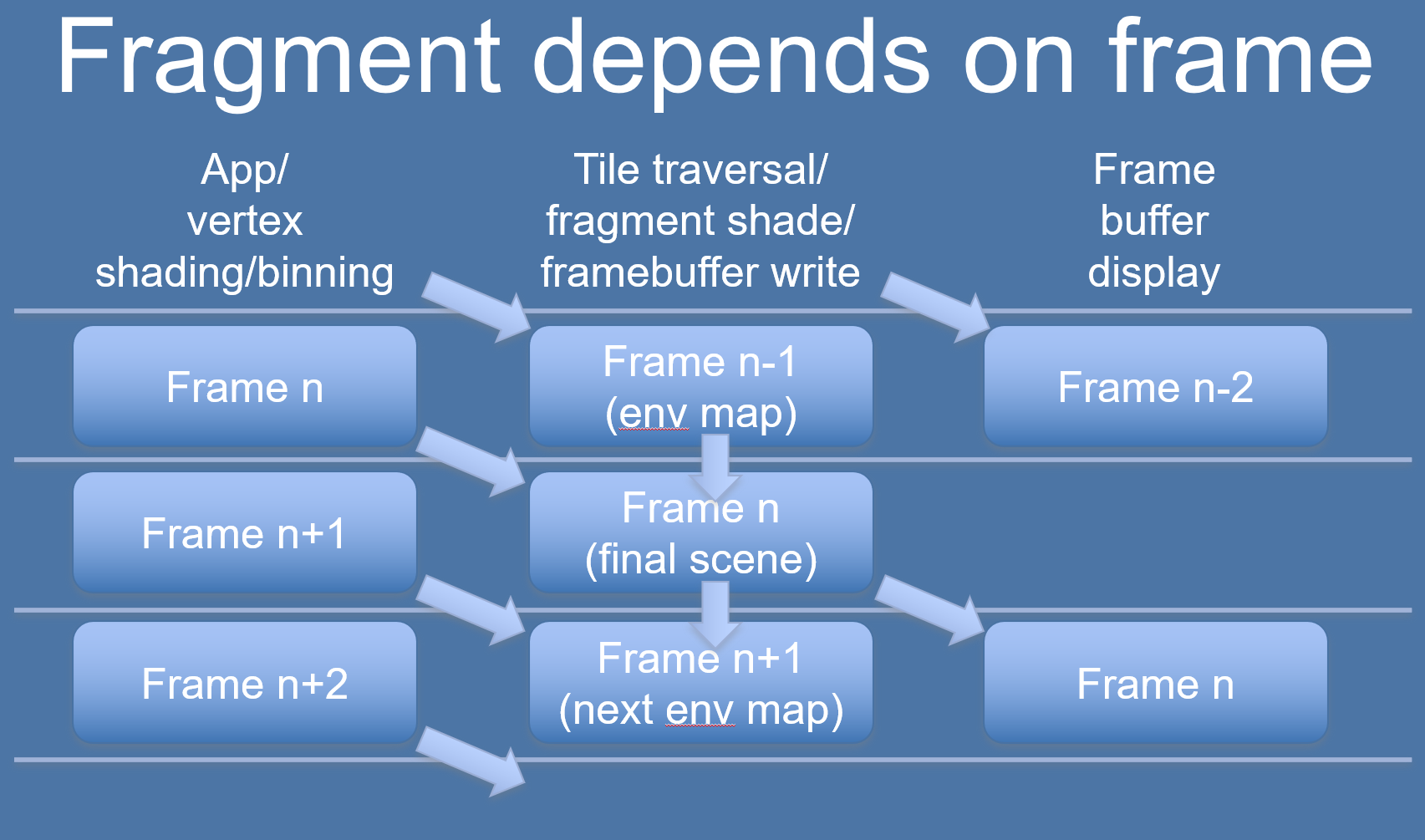
在提交之后、渲染使用之前,要修改数据。例如:
- 像素着色器计算并写入数据到一个帧缓冲对象,使用结果生成位移。
- 从CPU写入纹理,使用它进行渲染,然后再次更新纹理,然后渲染下一帧;像素着色器在纹理更新完成之前不会执行。
Vulkan等现代图形API存在Subpass机制,Subpass可以并行处理(Overlap),也可以指定数据依赖:
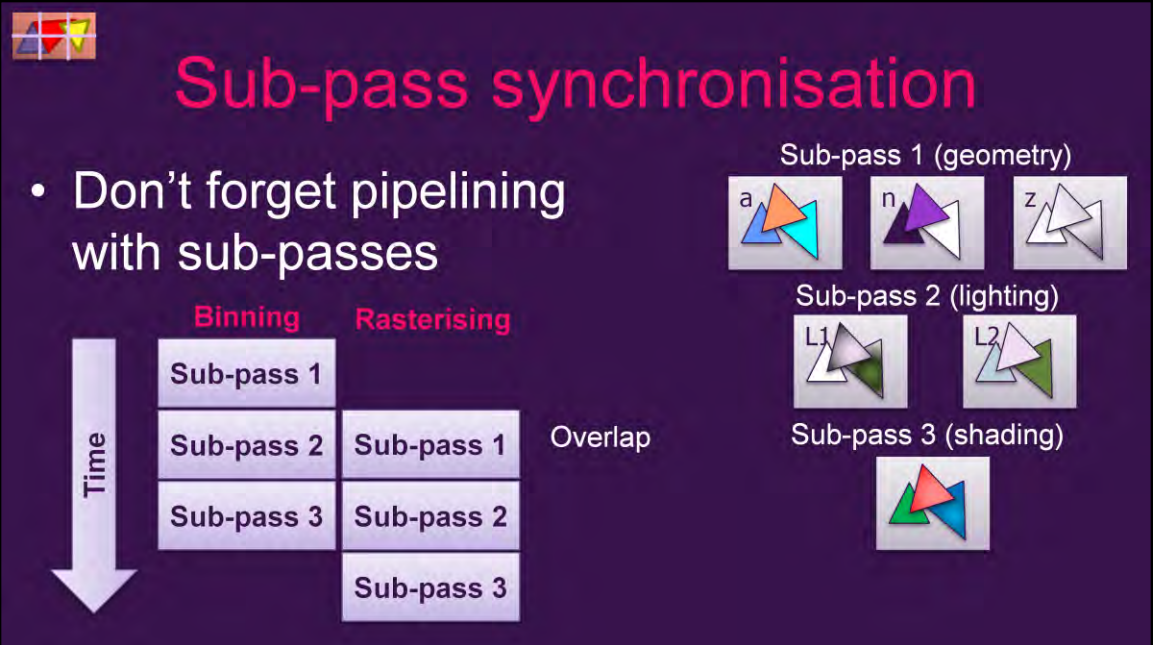

上:subpass的overlap机制i;下:subpass内部和之间的数据依赖。
使用Vulkan、Metal、DX12等现代图形API可以精确指定渲染管线屏障(Barrier)的等待阶段,例如下图使用了默认的PipelineBarrier,会导致Vertex、Fragment处理存在较多的空闲或等待,浪费GPU时间周期:

通过修改屏障需要等待的源阶段和目标阶段,可以缓解这类Stall,提升着色器单元的利用率:

Pipeline Barrier的具体优化示例如下:
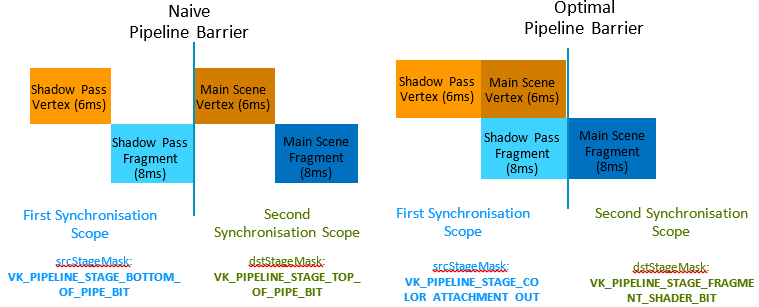
利用Vulkan的Pipeline Barrier优化各个Pass之间的等待阶段,可以减少Stall和延时。图中从28ms下降到22ms。
PowerVR的TBDR架构,会在本帧所有图元处理完Binning数据,才开始渲染阶段,这也许会导致更严重的延时。
除了以上所述的情况会导致延时,还有GPU内部的一些执行情况也会,比如GPU指令组之间存在依赖关系:
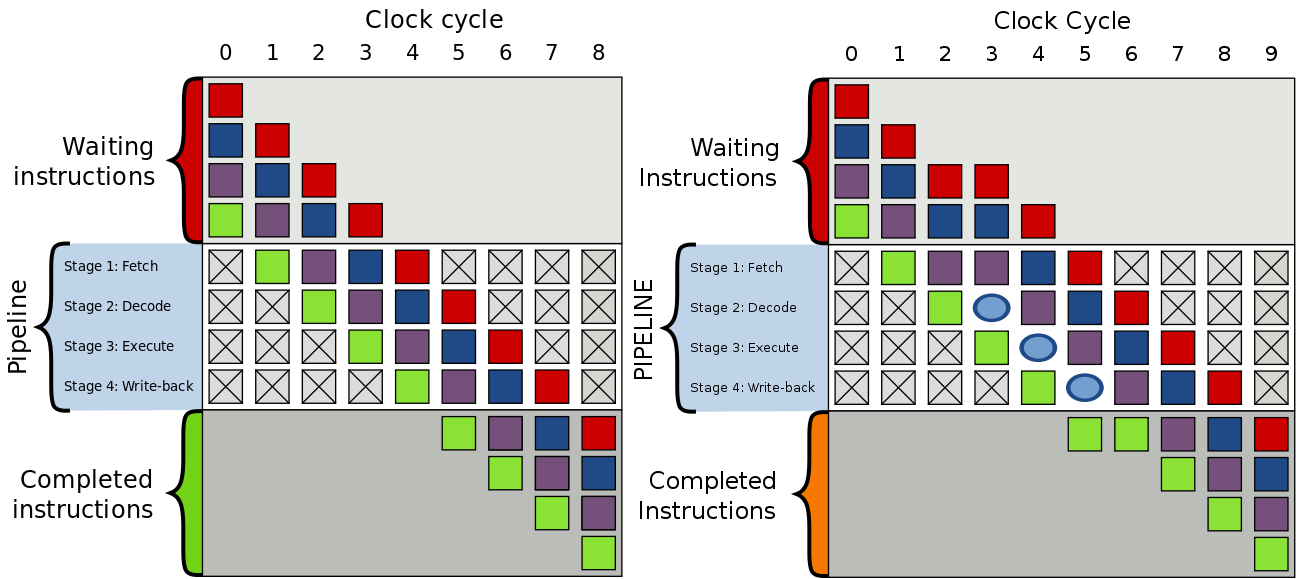
左:GPU指令组正常执行,没有等待的情况;右:GPU指令组被加入了气泡(bubble),导致了延时。
气泡(bubble)的产生是为了解决GPU指令组之间的数据依赖:
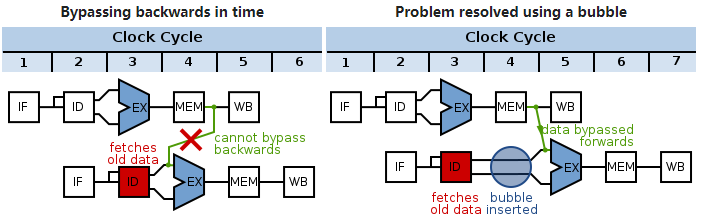
左:下组指令依赖上组数据的写入,如果不处理就会获得旧的数据;右:在下组指令插入气泡,延迟一个时钟周期以保证获取最新的数据。
Shader中的if和for等动态分支循环语句会降低GPU计算单元利用率,拉长它们运行指令的时间:

访问内存的指令也会使GPU计算单元产生Stall,延长计算时间:
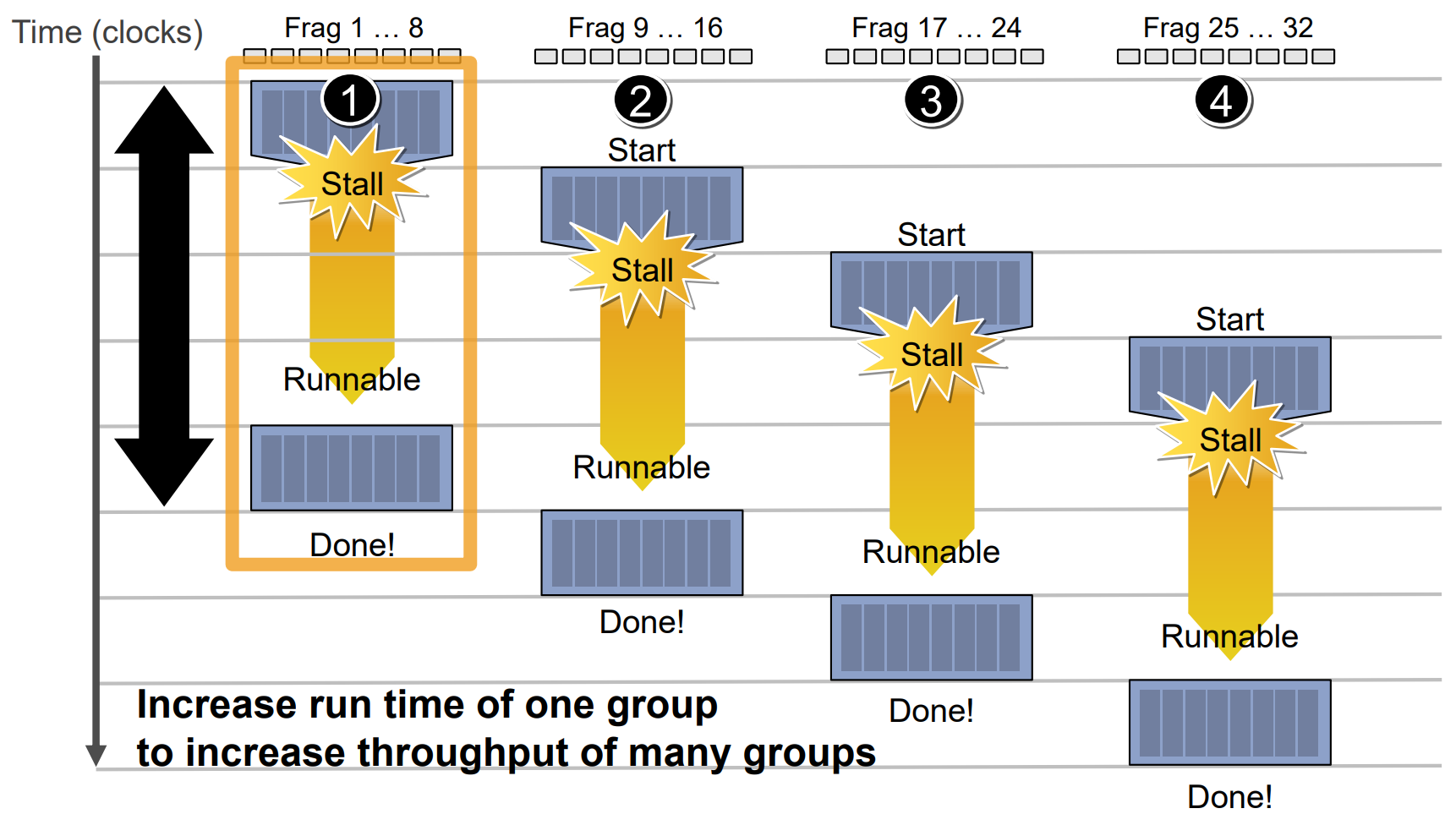
不同于CPU的低延时低吞吐率,GPU天生为了高并行和高吞吐率而设计,但与此同时缓存容量小,Cache命中率低,延时较高:
因此,如果GPU数据结构设计得不好,会极大降低Cache命中率,从而增加计算单元的卡顿和延时。GPU的线程编排器(Thread Schdule)通常会考虑数据关联性,保持同个线程组的线程在同一个缓存行:
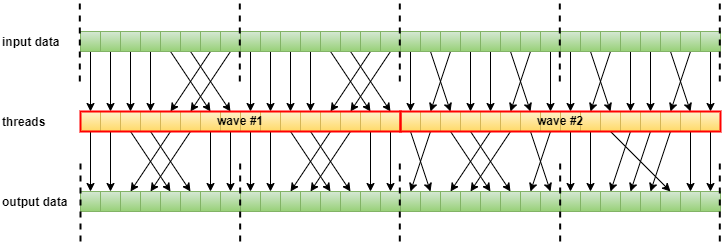
尺寸为16的Wave运行示意图。其中虚线表示线程组之间不能跨界存取数据,以提高线程组内部访问数据的缓存命中率。
除上述情况之外,如果系统或应用程序使用了双缓冲、三缓冲、垂直同步等机制,也会引入一定的延时。
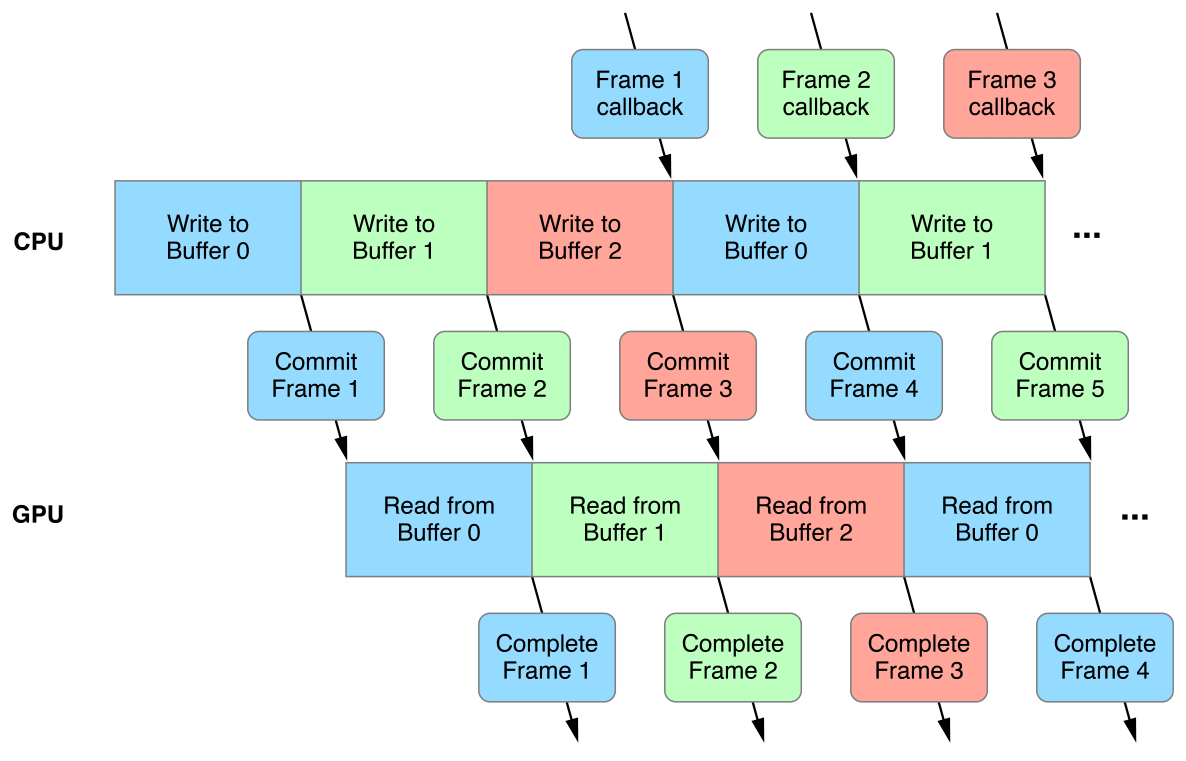
三缓冲执行机制示意图。
Android系统渲染模块使用了多层级封装和三缓冲机制,使得画面总是延迟3帧:
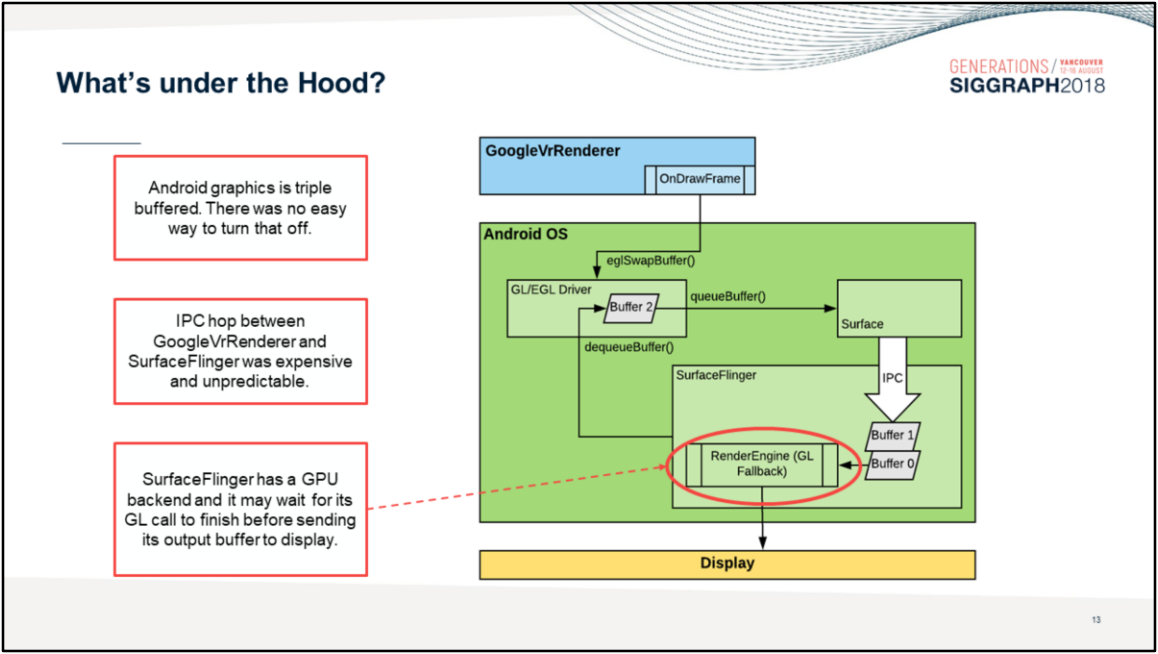
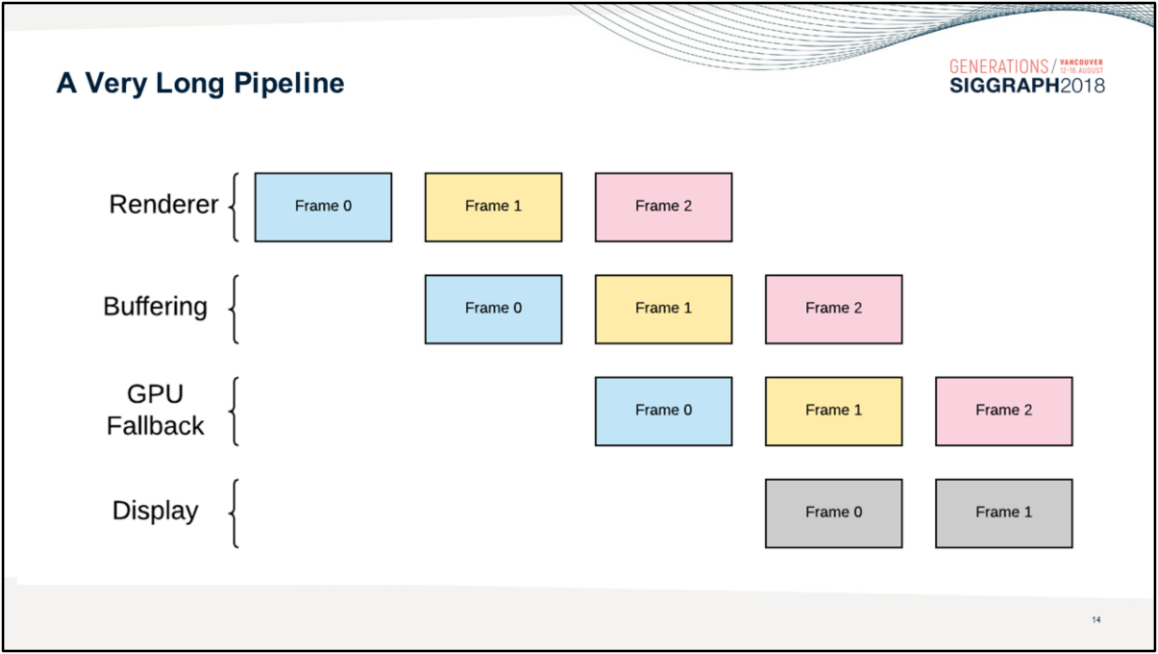
相反,善用Async Compute、Copy Engine、Graphic Pipeline等部位的并行机制,利用RDG的自动处理资源分配和依赖,利用子资源(subresource)和别名资源(aliasied resource)的特性,合并屏障等操作,可以减少Pass之间、Pass内部的等待和延时,提升并行效率。

Async Compute、Copy Engine、Graphic Pipeline的并行运行案例。

别名资源运行机制示意图,其中资源A和D分别在不同时间段占用了同一块内存区域。在使用RDG时,别名资源可以节省超过50%的已使用资源分配空间,即便它们会给渲染系统添加额外的资源管理复杂性。
总之,从CPU的App层的逻辑更新、渲染指令生成、图形API的调用和提交,横跨驱动层、系统层、GPU内部,到最终的显示器呈现,都可能存在各种各样的依赖、等待、卡顿和延时等问题。这就要求我们统揽全局,甄别整条渲染管线的瓶颈,对症下药,才能使我们的程序高效、流畅、即时地运行。
UE4官方文档针对延时给了一些建议和优化措施,详见Low Latency Frame Syncing。
- 未完待续
团队招员
博主所在的团队正在用UE4开发一种全新的沉浸式体验的产品,急需各路贤士加入,共谋宏图大业。目前急招以下职位:
- UE逻辑开发。
- UE引擎程序。
- UE图形渲染。
- TA(技术向、美术向)。
要求:
- 扎实的技术基础。
- 高度的技术热情。
- 良好的自驱力。
- 良好的沟通协作能力。
- 有UE使用经验或移动端开发经验更佳。
有意向或想了解更多的请添加博主微信:81079389(注明博客园求职),或者发简历到博主邮箱:81079389#qq.com(#换成@)。
静待各路英雄豪杰相会。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Mobile Rendering
- Qualcomm Adreno GPU
- PowerVR Developer Documentation
- Arm Mali GPU Best Practices Developer Guide
- Arm Mali GPU Graphics and Gaming Development
- Moving Mobile Graphics
- GDC Vault
- Siggraph Conference Content
- GameDev Best Practices
- Accelerating Mobile XR
- Frequently Asked Questions
- Google Developer Contributes Universal Bandwidth Compression To Freedreno Driver
- Using pipeline barriers efficiently
- Optimized pixel-projected reflections for planar reflectors
- UE4画面表现移动端较PC端差异及最小化差异的分享
- Deferred Shading in Unity URP
- 移动游戏性能优化通用技法
- 深入GPU硬件架构及运行机制
- Adaptive Performance in Call of Duty Mobile
- Jet Set Vulkan : Reflecting on the move to Vulkan
- Vulkan Best Practices - Memory limits with Vulkan on Mali GPUs
- A Year in a Fortnite
- The Challenges of Porting Traha to Vulkan
- L2M - Binding and Format Optimization
- Adreno Best Practices
- 移动设备GPU架构知识汇总
- Mali GPU Architectures
- Cyclic Redundancy Check
- Arm Guide for Unreal Engine
- Arm Virtual Reality
- Best Practices for VR on Unreal Engine
- Optimizing Assets for Mobile VR
- Arm Guide for Unreal Engine 4 Optimizing Mobile Gaming Graphics
- Adaptive Scalable Texture Compression
- Tile-Based Rendering
- Understanding Render Passes
- Lighting for Mobile Platforms
- Frame Pacing for Mobile Devices
- ARM Mali GPU. Midgard Architecture
- ARM’s Mali Midgard Architecture Explored
- [Unite Seoul 2019] Mali GPU Architecture and Mobile Studio
- Killing Pixels - A New Optimization for Shading on ARM Mali GPUs
- Qualcomm's Quad-Core Snapdragon S4 (APQ8064/Adreno 320) Performance Preview
- Low Resolution Z Buffer support on Turnip
- Render Graph与现代图形API
- Hidden Surface Removal Efficiency
- Unreal Engine 4: Mobile Graphics on ARM CPU and GPU Architecture
- Low Latency Frame Syncing
- Qualcomm Snapdragon Mobile Platform OpenCL General Programming and Optimization
- Qualcomm Announces Snapdragon 865 and 765(G): 5G For All in 2020, All The Details
- Introduction to PowerVR for Developers
- PowerVR Series5 Architecture Guide for Developers
- PowerVR Graphics - Latest Developments and Future Plans
- PowerVR virtualization: a critical feature for automotive GPUs
- PowerVR Performance Recommendations
- PowerVR Low Level GLSL Optimisation
- Mobile GPU approaches to power efficiency
- Processing Architecture for Power Efficiency and Performance
- opengl: glFlush() vs. glFinish()
- Cramming Software onto Mobile GPUs
- Vulkan on Mobile Done Right
- Triple Buffering
- Asynchronous Shaders
- Why Talking About Render Graphs
- NVIDIA Variable Rate Shading
- Introduction to compute shaders
- Introduction to GPU Architecture
- An Introduction to Modern GPU Architecture
- Understanding GPU caches
- Transitioning from OpenGL to Vulkan
- Next Generation OpenGL Becomes Vulkan: Additional Details Released
- Bringing Fortnite to Mobile with Vulkan and OpenGL ES
- Appropriate use of render pass attachments
- Preparing Android for XR
剖析虚幻渲染体系(12)- 移动端专题Part 2(GPU架构和机制)的更多相关文章
- 剖析虚幻渲染体系(12)- 移动端专题Part 3(渲染优化)
目录 12.6 移动端渲染优化 12.6.1 渲染管线优化 12.6.1.1 使用新特性 12.6.1.2 管线优化 12.6.1.3 带宽优化 12.6.2 资源优化 12.6.2.1 纹理优化 1 ...
- 剖析虚幻渲染体系(12)- 移动端专题Part 1(UE移动端渲染分析)
目录 12.1 本篇概述 12.1.1 移动设备的特点 12.2 UE移动端渲染特性 12.2.1 Feature Level 12.2.2 Deferred Shading 12.2.3 Groun ...
- 剖析虚幻渲染体系(15)- XR专题
目录 15.1 本篇概述 15.1.1 本篇内容 15.1.2 XR概念 15.1.2.1 VR 15.1.2.2 AR 15.1.2.3 MR 15.1.2.4 XR 15.1.3 XR综述 15. ...
- 剖析虚幻渲染体系(06)- UE5特辑Part 1(特性和Nanite)
目录 6.1 本篇概述 6.1.1 本篇内容 6.1.2 基础概念 6.2 UE5新特性 6.2.1 UE5编辑器 6.2.1.1 下载编辑器及资源 6.2.1.2 启动示例工程 6.2.1.3 编辑 ...
- 剖析虚幻渲染体系(10)- RHI
目录 10.1 本篇概述 10.2 RHI基础 10.2.1 FRenderResource 10.2.2 FRHIResource 10.2.3 FRHICommand 10.2.4 FRHICom ...
- 剖析虚幻渲染体系(13)- RHI补充篇:现代图形API之奥义与指南
目录 13.1 本篇概述 13.1.1 本篇内容 13.1.2 概念总览 13.1.3 现代图形API特点 13.2 设备上下文 13.2.1 启动流程 13.2.2 Device 13.2.3 Sw ...
- 剖析虚幻渲染体系(14)- 延展篇:现代渲染引擎演变史Part 1(萌芽期)
目录 14.1 本篇概述 14.1.1 游戏引擎简介 14.1.2 游戏引擎模块 14.1.3 游戏引擎列表 14.1.3.1 Unreal Engine 14.1.3.2 Unity 14.1.3. ...
- 剖析虚幻渲染体系(11)- RDG
目录 11.1 本篇概述 11.2 RDG基础 11.2.1 RDG基础类型 11.2.2 RDG资源 11.2.3 RDG Pass 11.2.4 FRDGBuilder 11.3 RDG机制 11 ...
- 剖析虚幻渲染体系(08)- Shader体系
目录 8.1 本篇概述 8.2 Shader基础 8.2.1 FShader 8.2.2 Shader Parameter 8.2.3 Uniform Buffer 8.2.4 Vertex Fact ...
随机推荐
- P5137-polynomial【倍增】
正题 题目链接:https://www.luogu.com.cn/problem/P5137 题目大意 \(T\)组数据给出\(n,a,b,p\)求 \[\left(\sum_{0=1}^na^ib^ ...
- Java8通过Function获取字段名(获取实体类的字段名称)
看似很鸡肋其实在某些特殊场景还是比较有用的.比如你将实体类转Map或者拿到一个Map结果的时候,你是怎么获取某个map的key和value.方法一:声明 String key1="name& ...
- 神器----IntelliJ IDEA基本配置
介绍 首先是百度百科对于 IDEA 的介绍 IDEA 全称 IntelliJ IDEA,是java编程语言开发的集成环境.IntelliJ在业界被公认为最好的java开发工具,尤其在智能代码助手.代码 ...
- golang实现一个简单的websocket聊天室
基本原理: 1.引入了 golang.org/x/net/websocket 包. 2.监听端口. 3.客户端连接时,发送结构体: {"type":"login" ...
- 从一个舒服的姿势插入 HttpClient 拦截器技能点
马甲哥继续写一点大前端,阅读耗时5 minute,行文耗时5 Days 今天我们来了解一下如何拦截axios请求/响应? 这次我们举一反三,用一个最舒适的姿势插入这个技能点. axios是一个基于 p ...
- 20 行代码:Serverless 架构下用 Python 轻松搞定图像分类和预测
作者 | 江昱 前言 图像分类是人工智能领域的一个热门话题.通俗解释就是,根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法. 它利用计算机对图像进行定量分析,把图像或图像中 ...
- 学校选址(ArcPy实现)
一.背景 合理的学校空间位置布局,有利于学生的上课与生活.学校的选址问题需要考虑地理位置.学生娱乐场所配套.与现有学校的距离间隔等因素,从总体上把握这些因素能够确定出适宜性比较好的学校选址区. 二.目 ...
- 运行WampServer提示计算机中丢失 msvcr110.dll
在第一次运行WampServer的时候,出现"无法启动此程序,因为计算机中丢失 MSVCR110.dll.尝试重新安装该程序以解决此问题. 在浏览器的地址栏里输入 http://ww ...
- 题解 Beautiful Pair
题目传送门 题目大意 给出一个 \(n\) 个点的序列 \(a_{1,2,...,n}\) ,问有多少对点对 \((i,j)\) 满足 \(a_i\times a_j\le a_k(i\le k\le ...
- C++ 与 Visual Studio 2019 和 WSL(二)
终端 A more integrated terminal experience | Visual Studio Blog (microsoft.com) Say hello to the new V ...