论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络
论文代码:https://github.com/aleXiehta/WaveCRN
引用格式:Hsieh T A, Wang H M, Lu X, et al. WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement[J]. IEEE Signal Processing Letters, 2020, 27: 2149-2153.
摘要
基于简单的设计流程,端到端(E2E)语音增强(SE)神经模型受到了广泛的关注。为了提高端到端模型的性能,建模时需要有效地考虑语音的局域性和序列性。然而,在目前大多数用于SE的端到端模型中,这些属性要么没有得到充分考虑,要么太复杂而无法实现。在这论文中,我们提出了一个有效的E2E模型,术语为WaveCRN。与基于卷积神经网络(CNN)或长短期记忆(LSTM)的模型相比,WaveCRN使用CNN模块和堆叠简单递归单元(SRU)模块来捕获语音位置特征,并对位置特征的时序特性进行建模。与传统的递归神经网络和LSTM不同,SRU在计算中可以高效并行化,模型参数更少。为了更有效地抑制带噪语音中的噪声成分,我们提出了一种新的受限(restricted)特征掩蔽方法,该方法对隐藏层中的特征映射进行增强;这与语音分离方法中常用的将估计比率掩模应用于有噪谱特征的方法不同。在语音去噪和压缩语音恢复任务上的实验结果证实,在SRU和受限特征映射的情况下,WaveCRN的性能与其他最先进的方法相当,显著降低了模型复杂度和推理时间。
1 引言
与语音相关的应用,如自动语音识别(ASR)、语音通信和辅助听力设备,在现代社会中发挥着重要作用。然而,当涉及噪声时,大多数应用都不鲁棒。因此,语音增强(SE)以提高原始语音信号的质量和清晰度为目标,在这些应用中得到了广泛的应用。近年来,深度学习算法被广泛应用于SE系统的构建。
一类SE系统对频域声学特征进行增强,一般称为基于谱图的SE方法。在这些方法中,语音信号的分析和重建分别使用短时傅里叶变换(STFT)和短时傅里叶反变换([9][13])。然后,采用深度学习模型,如全连接深度去噪自动编码器[3]、卷积神经网络(CNNs)[14]、递归神经网络(RNNs)和长短期记忆(LSTM)[15]、[16]作为变换函数,将噪声谱特征转换为纯净频谱特征。同时,通过结合不同类型的深度学习模型(如CNN和RNN),推导出了一些方法来更有效地捕获局部和序列相关性[17][20]。最近,基于堆叠样本循环单元(SRU)[21],[22]构建的SE系统显示出了与基于LSTM的SE系统相当的去噪性能,同时需要更少的训练计算成本。虽然上述方法已经提供了出色的性能,但由于缺乏准确的相位信息,增强后的语音信号无法达到其完美的性能。为了解决这一问题,一些SE方法采用复数理想比率掩蔽(cIRM)和复数频谱映射来增强失真语音。在[26]中,相位估计被描述为一个分类问题,并用于一个源分离任务。
另一类SE方法提出直接对原始波形[27][31]进行增强,一般称为基于波形映射的方法。在深度学习模型中,全卷积网络(FCNs)被广泛用于直接进行波形映射[28]、[32]、[34]。最初提出用于文本到语音任务的WaveNet模型也被用于基于波形映射的SE系统[35],[36]。与全连接架构相比,全卷积层更好地保留了局部信息,能够更准确地模拟语音波形的频率特性。最近,时间卷积神经网络(TCNN)[29]被提出,以准确建模时间特征和执行时域SE。除了用于优化的点对点损失(如$l_1$和$l_2$规范)外,一些基于波形映射的SE方法[37]、[38]利用对抗损失或知觉损失来捕获预测和它们的目标之间的高级区别。
对于上述基于波形映射的SE方法,有效表征序列和局部模式是最终SE性能的重要考虑因素。虽然CNN与RNN/LSTM的结合可能是可行的解决方案,但RNN/LSTM的计算成本和模型规模都很高,这可能会大大限制其适用性。在本研究中,我们提出了一种基于E2E waveform mapping的SE方法,使用CRN,称为WaveCRN1,它结合了CNN和SRU的优势,以提高效率。与基于频谱映射的CRN[17][20]相比,提出的WaveCRN通过高度并行的循环单元直接从未经处理的波形中估计特征掩模。两个任务用于测试所提出的WaveCRN方法:(1)语音去噪(2)压缩语音恢复。对于语音去噪,我们使用开源数据集[39]评估我们的方法,并获得较高的语音质量感知评价(PESQ)评分[40],这与目前最先进的方法相媲美,同时使用相对简单的架构和l1损失函数。对于压缩语音恢复,与使用声学特征的[41]、[42]不同,我们简单地将语音传递给符号函数进行压缩。该任务在TIMIT数据库[43]上评估。提出的WaveCRN模型恢复了极其压缩的语音,与短时客观清晰度(STOI)[44]相比,提高了75.51%(从0.49提高到0.86)。
2 方法
在本节中,我们将详细描述基于WaveCRN的SE系统。该体系结构是一个完全可微分的端到端神经网络,不需要预处理和人工特征。得益于CNN和SRU的优势,它联合建模局部和序列信息。WaveCRN的总体架构如图1所示。
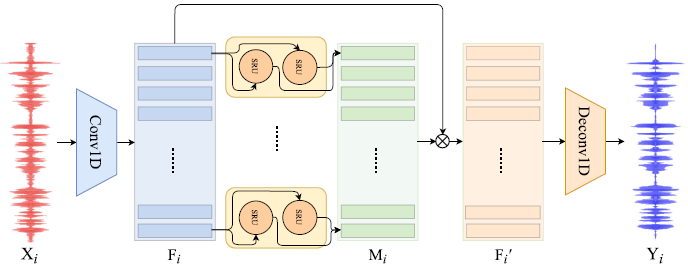
图1 提出的wavecrn模型的体系结构。
与频谱CRN不同,WaveCRN集成了一维CNN和双向SRU
A 1维卷积输入模块
如前一节所述,对于基于频谱映射的SE方法,语音波形首先通过STFT转换为频谱域。为了实现波形映射SE,WaveCRN使用1D CNN输入模块代替STFT处理。得益于神经网络的性质,CNN模块是完全可训练的。对于每一个batch,输入带噪语音$X(X\in R^{N*1*L})$是与一个二维张量$W(W\in R^{C*K})$卷积,以提取特征映射$F\in R^{N*C*T}$,其中batch size N、通道数C、内核大小K、time step T分别和音频长度L。值得注意的是,为了减少序列长度以提高计算效率,我们将卷积stride 设置为核大小的一半大小,从而使$F$的长度从$L$减少到$T=\frac{2L}{K}+1$。
B 时序编码
我们使用双向SRU(Bi-SRU)来捕获由输入模块在两个方向提取的特征图的时间相关性。对于每个batch,features map$F\in R^{N*C*T}$被传递给基于SRU的循环特征提取器。从两个方向提取的隐藏状态被连接起来形成编码特征。
C 受限特征mask
最优比率掩码(ORM)已广泛应用于SE和语音分离任务[45]。由于ORM是一个时频掩模,不能直接应用于基于波形映射的SE方法。在本研究中,我们采用受限特征掩模(RFM)对特征映射F进行掩模,所有元素的范围为-1 ~ 1
$$公式1:F'=M\circ F$$
其中M,是RFM,F'是通过将mask M和特征图F逐元素相乘估计出来的masked特征图。 需要注意的是ORM和RFM的主要区别在于前者应用于频谱特征 ,而后者用于变换后的 feature maps。
D 波形生成
如A所述,由于卷积过程中的步幅,序列长度从波形的$L$缩减到feature map的$T$。长度恢复对于生成与输入长度相同的输出波形至关重要。假设输入长度$L_{in}$、输出长度$L_{out}$、步幅$S$和填充$P$,则$L_{in}$和$L_{out}$的关系可表示为
$$公式2:L_{\text {out }}=\left(L_{\text {in }}-1\right) \times S-2 \times P+(K-1)+1$$
设$L_{in}=T$,$S=K/2$,$P=K/2$,则$L_{out}=L$即保证输出波形与输入波形具有相同的长度。
E 模型结构概述
如图1所示,我们的模型利用了CNN和SRU的优势。给定第$i$个带噪语音$X_i\in R^{1*L},i=0,...,N-1$,在一个batch中,一维卷积首先将$X_i$映射到特征映射$F_i$中进行局部特征提取。然后Bi-SRU计算一个RFM$M_i$,该$M_i$元素巧妙地将$F_i$相乘生成一个掩蔽特征映射$F'$。最后,转置的1D卷积层从掩蔽特征$F'_i$恢复增强的语音波形$X_i$。
在[21]中,已经证明SRU的性能与LSTM相当,但具有更好的并行性。LSTM中各门之间的依赖性导致训练和推理缓慢。相比之下,SRU中的所有门只依赖于当前时间的输入,并且通过在循环层之间添加highway 连接来捕获序列相关性。因此,SRU中的门是同时计算的。在正向传递时,SRU和LSTM的时间复杂度分别为$O(T·N·C)$和$O(T·N·C2)$。上述优点使得SRU将其与CNN相结合是合适的。一些研究[46],[47]将ResNet描述为其子网络中相对较浅路径的集合。由于SRU具有highway连接和随时间的重复,它可以被视为一个集成,用于对子序列中的依赖关系进行离散建模。
3 实验
A 实验步骤
1)、语音去噪:对于语音去噪任务,使用了开源数据集[39],它结合了语音库语料库[48]和需求语料库[49]。与以前的工作[25]、[33]、[35]-[38]类似,我们将语音数据下采样到16 kHz进行训练和测试。在语音库中,30名说话人中有28人用于训练,2名说话人用于测试。对于训练集,在4个信噪比水平(0、5、10和15dB)下,干净的语音被10种类型的噪声污染。对于测试组,在其他4个信噪比水平(2.5、7.5、12.5和17.5dB)下,干净的语音被5种看不见的噪声所污染。
2)、压缩(2位)语音恢复:对于压缩语音恢复任务,我们使用了Timit语料库[43],原始语音样本以16 kHz和16位格式记录。在这组实验中,每个样本都被压缩成2比特的格式(用−1、0或+1表示),节省了87.5%的比特,从而降低了数据传输和存储需求,我们相信这种压缩方案在现实世界的物联网场景中具有潜在的应用前景。注意,在去噪和恢复任务中使用了相同的模型架构。每个压缩样本的+1、0或−1值首先被映射到浮点表示,因此可以容易地应用波形域SE系统来恢复原始的未压缩语音。将原始语音表示为$\hat{y}$,压缩语音表示为$sgn(\hat{y})$,其中$g_\theta$表示SE过程。
$$公式3:\arg \min _{\theta}\left\|\hat{y}-g_{\theta}(\operatorname{sgn}(\hat{y}))\right\|_{1}$$
3、模型架构:在输入模块中,通道数设置为256,kernel size设置为0.006 s(96),stride size设置为0.003 s(48)。输入音频被填充,使其可被stride大小整除。将Bi-SRU hidden state的大小设置为通道的数量(有6个stacks)。接下来,所有hidden state被线性映射到半维,以形成一个mask,并巧妙地乘以特征映射。最后,在波形生成步骤中,利用转置卷积层将二维feature map映射为一维序列,该序列通过双曲正切(hyperbolic tangent)激活函数生成预测波形。$l1$范数作为训练WaveCRN的目标函数。为了更公平地比较模型架构,我们主要将WaveCRN与其他使用$l1$norm训练的SE系统进行比较。
B 实验结果
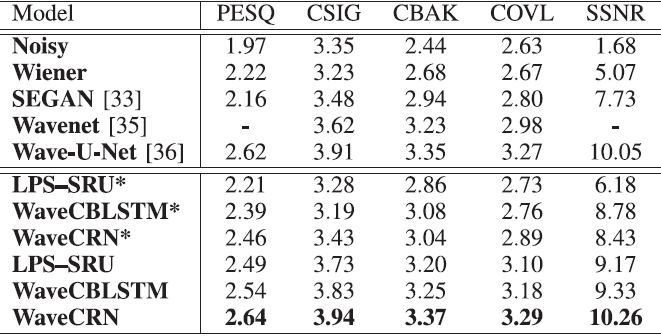
1) 语音去噪:对于语音去噪任务,我们采用了文献[50]中的五个评价指标:CSIG(信号失真)、CBAK(背景干扰)、COVL(综合质量)、PESQ(反映语音质量)和SSNR(分段信噪比)。表I列出了结果。与Wiener滤波、SEGAN、使用相同L1损耗的两个知名SE模型(即WaveNET和Wave-U-Net)、使用LPS特征作为输入的LPS-SRU以及结合CNN和BLSTM的Wave CBLSTM进行了比较。通过替换图中的一维卷积输入模块和转置的一维卷积输出模块,实现了LP-SRU。图1具有STFT和反向STFT模块。WaveCBLSTM是通过用LSTM代替图1中的SRU来实现的,CNN和LSTM相结合处理语音信号已经得到了广泛的研究[19],[20],[30]。在这项研究中,我们的目的是证明SRU在应用于基于波形的SE时,在去噪能力和计算效率方面优于LSTM。从表I可以清楚地看出,WaveCRN在所有感知和信号级评估指标方面都优于其他模型。
表1 语音去噪任务的结果。分数越高,表现越好
粗体值表示特定度量的最佳性能。用*标记的模型不使用RFM直接生成增强语音
接下来,我们研究了RFM的影响。如表I所示,LPS-SRU、WaveCBLSTM和WaveCRN优于不使用RFM的对应物(LPS-SRU*、WaveCBLSTM*和WaveCRN*)。值得注意的是,与使用波形作为输入的WaveCBLSTM和WaveCRN不同,LPS-SRU增强了频谱域中的音频。图2展示了有噪声的、干净的和增强的语音话语的幅度谱图。从图中可以画出两个观测值。首先,RFM显著消除了高频区域(绿色块)和静音部分(白色块)中的噪声分量。这一观察结果与表I中的结果一致:采用RFM的模型获得了更高的SSNR分数和语音质量。其次,如图2(E)所示,没有RFM,高频区域不能完全恢复。比较图2(E)和图2(G),在静默部分,WaveCBLSTM*比WaveCRN*具有更清晰的估计,但是高频区域的丢失会恶化音频质量,这可以在表I中找到。与WaveCRN*相比,WaveCBLSTM*具有更高的CBAK分数,但PESQ和SSNR分数更低。其次,表II给出了WaveCRN和WaveCBLSTM的执行时间和参数的比较,在相同的超参数设置(层数、隐藏状态维数、通道数等)下,WaveCRN的训练过程比WaveCBLSTM快15.45倍((38.1+59.86)/(2.07+4.27)),参数个数仅为51%。正向传递快18.41倍,也就是推理速度快18.41倍。
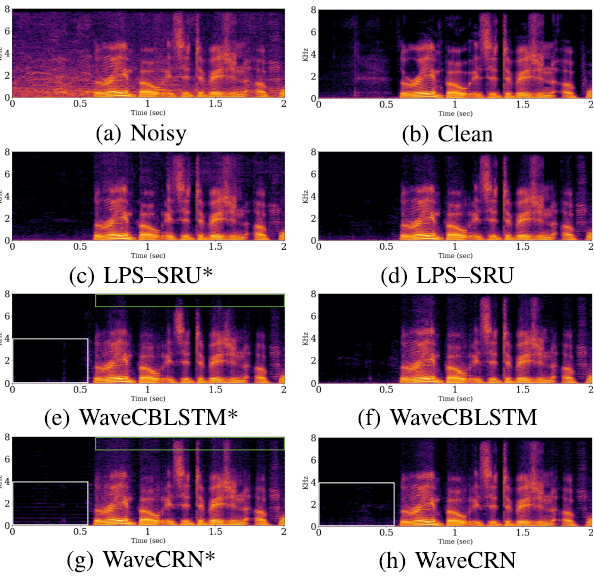
图2 LPS-SRU、LPS-SRU*、WaveCBLSTM、WaveCBLSTM*、WaveCRN和Wave-CRN*的噪声、干净和增强语音的幅度谱图,
其中标有*的模型不使用RFM直接生成增强语音。与其他方法相比,WaveCRN的改进用绿色(高频部分)和白色块(静音)高亮显示。
(A)Noisy。(B)clean。(C)LPS-SRU*。(D)LPS-SRU。(E)WaveCBLSTM*。(F)WaveCBLSTM。(G)WaveCRN*。(H)WaveCRN。
表2:比较了具有相同超参数的WaveCRN和WaveeCBLSTM的执行时间和参数个数。
这个实验是在一个环境设置中执行的,使用了48核CPU 2.20 GHZ和一个Titan xp gpu与12gb vram。
第一行和第二行表示在一批16个波形输入中1秒的正向和反向传播传递的执行时间,第三行表示参数的数量

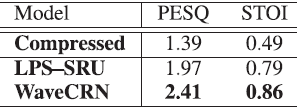
(2)压缩语音恢复:在压缩语音恢复任务中,分别使用WaveCRN和LPS-SRU将压缩语音转换为未压缩语音;LPS-SRU采用与WaveCRN相同的SRU结构,但输入为LPS,分别使用STFT和逆STFT进行语音分析和重构。根据PESQ值和STOI分值对性能进行评估。从表三可以看出,WaveCRN和LPS-SRU使PESQ评分从1.39分提高到2.41分和1.97分,STOI分从0.49分提高到0.86分和0.79分。这两种方法都取得了显著的改进,而WaveCRN的性能明显优于LPS-SRU。
图3 压缩语音恢复任务的结果
我们可以从图3(A)和3(B)中观察到,语音质量在2比特格式中显著降低,特别是在静音部分和高频区域。然而,由WaveCRN和LPS-SRU恢复的语音谱图呈现出更清晰的结构,如图3(C)和3(D)所示。另外,挡路白区实验表明,WaveCRN比LPS-SRU能更有效地恢复语音模式。图4显示了瞬时频率谱图。正如预期的那样,LPS-SRU使用压缩的相位谱图恢复波形;因此,WaveCRN通过直接使用波形作为输入而不会丢失相位信息,从而保留了相位频谱的更多细节。

图3所示。LPS SRU和WaveCRN生成的原始、压缩和恢复语音的幅度谱图。
(一)压缩。(b)Ground Truth。(c) LPS-SRU。(d) WaveCRN。
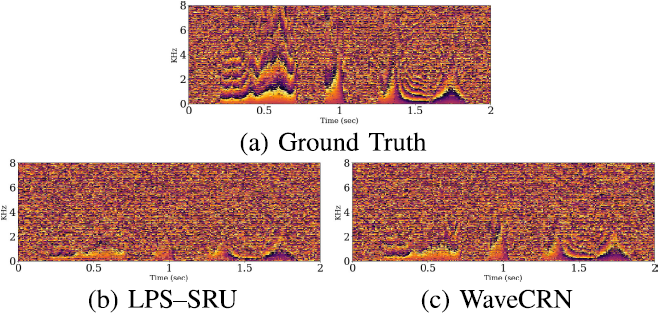
图4所示。用LPS SRU和WaveCRN分析未压缩和恢复语音的瞬时频谱图。
(一)Ground Truth。(b) LPS-SRU。(c) WaveCRN。
4 结论
本文提出了WaveCRN E2E SE模型。WAVE-CRN采用双向结构对提取的特征的顺序相关性进行建模。实验结果表明,WaveCRN在去噪能力和计算效率上均优于相关工作。这项研究的贡献有四个方面:(A)WaveCRN是第一个将SRU和CNN相结合来执行E2E SE的工作;(B)提出了一种新的RFM方法,将噪声特征直接转换为增强特征;(C)SRU模型相对简单,但性能与其他使用相同L1损失的最新SE模型相当;(D)设计了一种新的实际应用(压缩语音恢复),并对其性能进行了测试;WaveCRN在E2E SE上取得了令人满意的结果本研究将SE模型架构与传统的L1范数损失进行比较,未来的工作将探索在WaveCRN系统中采用替代的知觉损失和对抗性损失。
参考文献
[1] P. C. Loizou, Speech Enhancement: Theory and Practice, 2nd ed. Boca Raton, FL, USA: CRC Press, 2013.
[2] M. Kolbk, Z.-H. Tan, and J. Jensen, Speech intelligibility potential of general and specialized deep neural network based speech enhancement systems, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 25, no. 1, pp. 153 167, Jan. 2017.
[3] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, Speech enhancement based on deep denoising autoencoder, in Proc. Interspeech, 2013, pp. 436 440.
[4] B. Xia and C. Bao, Wiener filtering based speech enhancement with weighted denoising auto-encoder and noise classification, Speech Com- mun. , vol. 60, pp. 13 29, 2014.
[5] D. Wang and J. Chen, Supervised speech separation based on deep learning: An overview, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 26, no. 10, pp. 1702 1726, Oct. 2018.
[6] Z. Meng, J. Li, and Y. Gong, Adversarial feature-mapping for speech enhancement, in Proc. Interspeech, 2017, pp. 3259 3263.
[7] M. H. Soni, N. Shah, and H. A. Patil, Time-frequency masking-based speech enhancement using generative adversarial network, in Proc. ICASSP, 2018, pp. 5039 5043.
[8] L. Chai, J. Du, Q.-F. Liu, and C.-H. Lee, Using generalized Gaussian distributions to improve regression error modeling for deep learning-based speech enhancement, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 27, no. 12, pp. 1919 1931, Dec. 2019.
[9] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, A regression approach to speech enhancement based on deep neural networks, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 23, no. 1, pp. 7 19, Jan. 2015.
[10] F.XieandD. VanCompernolle, AfamilyofMLPbasednonlinearspectral estimators for noise reduction, in Proc. ICASSP, 1994, pp. 53 56.
[11] S. Wang, K. Li, Z. Huang, S. M. Siniscalchi, and C.-H. Lee, A transfer learning and progressive stacking approach to reducing deep model sizes with an application to speech enhancement, in Proc. ICASSP, 2017, pp. 5575 5579.
[12] D. Liu, P. Smaragdis, and M. Kim, Experiments on deep learning for speech denoising, in Proc. Interspeech, 2014, pp. 2685 2689.
[13] L. Sun, J. Du, L.-R. Dai, and C.-H. Lee, Multiple-target deep learning for lSTM-RNN based speech enhancement, in Proc. HSCMA, 2017, pp. 136 140.
[14] S.-W. Fu, Y. Tsao, and X. Lu, SNR-aware convolutional neural network modeling for speech enhancement, in Proc. Interspeech, 2016, pp. 3768 3772.
[15] F. Weninger et al., Speech enhancement with LSTM recurrent neural networksanditsapplicationtonoise-robustASR, inProc. LVA/ICA,2015, pp. 91 99.
[16] A. L. Maas, Q. V. Le, T. M. O Neil, O. Vinyals, P. Nguyen, and A. Y. Ng, Recurrent neural networks for noise reduction in robust ASR, in Proc. Interspeech, 2012, pp. 22 25.
[17] H. Zhao, S. Zarar, I. Tashev, and C.-H. Lee, Convolutional-recurrent neural networks for speech enhancement, in Proc. ICASSP, 2018, pp. 2401 2405.
[18] K. Tan and D. Wang, Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 28, pp. 380 390, 2020.
[19] K. Tan and D. Wang, A convolutional recurrent neural network for real- time speech enhancement, in Proc. Interspeech, 2018.
[20] K. Tan, X. Zhang, and D. Wang, Real-time speech enhancement using an efficient convolutional recurrent network for dual-microphone mobile phones in close-talk scenarios, in Proc. ICASSP, 2019, pp. 5751 5755.
[21] T. Lei, Y. Zhang, S. I. Wang, H. Dai, and Y. Artzi, Simple recur- rent units for highly parallelizable recurrence, in Proc. EMNLP, 2018, pp. 4470 4781.
[22] X. Cui, Z. Chen, and F. Yin, Speech enhancement based on simple recurrent unit network, Appl. Acoust. , vol. 157, 2020, Art. no. 107019.
[23] S.-W. Fu, T.-y. Hu, Y. Tsao, and X. Lu, Complex spectrogram enhance- ment by convolutional neural network with multi-metrics learning, in Proc. MLSP, 2017, pp. 1 6.
[24] D. S. Williamson and D. Wang, Time-frequency masking in the complex domain for speech dereverberation and denoising, IEEE/ACM Trans. Audio, Speech, Lang.Process. , vol. 25, no. 7, pp. 1492 1501, Jul. 2017.
[25] J. Yao and A. Al-Dahle, Coarse-to-fine optimization for speech enhance- ment, in Proc. Interspeech, 2019, pp. 2743 2747.
[26] N. Takahashi, P. Agrawal, N. Goswami, and Y. Mitsufuji, PhaseNet: Discretized phase modeling with deep neural networks for audio source separation, in Proc. Interspeech, 2018, pp. 2713 2717.
[27] S.-W. Fu, Y. Tsao, X. Lu, and H. Kawai, Raw waveform-based speech enhancement by fully convolutional networks, in Proc. APSIPA ASC, 2017, pp. 6 12.
[28] T. N. Sainath, R. J. Weiss, A. Senior, K. W. Wilson, and O. Vinyals, Learning the speech front-end with raw waveform CLDNNs, in Proc. Interspeech, 2015, pp. 1 5.
[29] A. Pandey and D. Wang, TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain, in Proc. Inter- speech, 2019, pp. 6975 6879.
[30] J. Li, H. Zhang, X. Zhang, and C. Li, Single channel speech enhancement using temporal convolutional recurrent neural networks, in Proc. APSIPA ASC, 2019, pp. 896 900.
[31] M. Kolbæk, Z.-H. Tran, S. H. Jensen, and J. Jensen, On loss functions for supervised monaural time-domain speech enhancement, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 28, pp. 825 838, 2020.
[32] S. Fu, T. Wang, Y. Tsao, X. Lu, and H. Kawai, End-to-end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 26, no. 9, pp. 1570 1584, Sep. 2018.
[33] S. Pascual, A. Bonafonte, and J. Serra, SEGAN: Speech enhancement generative adversarial network, in Proc. Interspeech, 2017, pp. 3642 3646.
[34] K. Qian, Y. Zhang, S. Chang, X. Yang, D. Florêncio, and M. Hasegawa- Johnson, Speech enhancement using Bayesian wavenet, in Proc. Inter- speech, 2017, pp. 2013 2017.
[35] D. Rethage, J. Pons, and X. Serra, A wavenet for speech denoising, in Proc. Interspeech, 2017, pp. 5069 5073.
[36] R. Giri, U. Isik, and A. Krishnaswamy, Attention wave-U-Net for speech enhancement, in Proc. WASPAA, 2019, pp. 4049 4053.
[37] S. Pascual, J. Serra, and A. Bonafonte, Time-domain speech enhance- ment using generative adversarial networks, Speech Commun. , vol. 114, pp. 10 21, 2019.
[38] F. G. Germain, Q. Chen, and V. Koltun, Speech denoising with deep feature losses, in Proc. Interspeech, 2019, pp. 2723 2727.
[39] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, Investi- gating RNN-based speech enhancement methods for noise-robust text-to- speech, in Proc. SSW, 2016, pp. 146 152.
[40] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ) a new method for speech quality assessment of telephone networks and codecs, in Proc. ICASSP, 2001, pp. 749 752.
[41] M. Cernak, A. Lazaridis, A. Asaei, and P. N. Garner, Composition of deep and spiking neural networks for very low bit rate speech cod- ing, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 24, no. 12, pp. 2301 2312, Dec. 2016.
[42] L. Deng, M. L. Seltzer, D. Yu, A. Acero, A. Rahman Mohamed, and G. E. Hinton, Binary coding of speech spectrograms using a deep auto- encoder, in Proc. Interspeech, 2010, pp. 1692 1695.
[43] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren, DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM. NIST speech disc 1-1.1, NASA STI/Recon Tech. Rep., vol. 93, p. 27043, 1993.
[44] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algo- rithm for intelligibility prediction of time frequency weighted noisy speech, IEEE/ACM Trans. Audio, Speech, Lang. Process. , vol. 19, no. 7, pp. 2125 2136, Sep. 2011.
[45] S. Liang, W. Liu, W. Jiang, and W. Xue, The optimal ratio time-frequency mask for speech separation in terms of the signal-to-noise ratio, JASA, vol. 134, no. 5, pp. EL452 EL458, 2013.
[46] A. Veit, M. J. Wilber, and S. Belongie, Residual networks behave like ensembles of relatively shallow networks, in Proc. NeurIPS, 2016, pp. 550 558.
[47] S. De and S. L. Smith, Batch normalization biases deep residual networks towards shallow paths, CoRR, vol. abs/2002.10444, 2020.
[48] C. Veaux, J. Yamagishi, and S. King, The voice bank corpus: Design, collection and data analysis of a large regional accent speech database, in Proc. O-COCOSDA/CASLRE, 2013, pp. 1 4.
[49] J. Thiemann, N. Ito, and E. Vincent, The diverse environments multi channel acoustic noise database: A database of multichannel environmen- tal noise recordings, J. Acoust. Soc. Amer. , pp. 3591 3591, 2013.
[50] Y. Hu and P. C. Loizou, Evaluation of objective quality measures for speech enhancement, IEEE Trans. Audio, Speech, Lang. Process. , vol. 16, no. 1, pp. 229 238, Jan. 2008.
论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement的更多相关文章
- 【论文翻译】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 论文链接:https://arxi ...
- 论文翻译:Fullsubnet: A Full-Band And Sub-Band Fusion Model For Real-Time Single-Channel Speech Enhancement
论文作者:Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li 翻译作者:凌逆战 论文地址:Fullsubnet:实时单通道语音增强的全频带和子频带 ...
- 论文翻译:2019_TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain
论文地址:TCNN:时域卷积神经网络用于实时语音增强 论文代码:https://github.com/LXP-Never/TCNN(非官方复现) 引用格式:Pandey A, Wang D L. TC ...
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 论文翻译:2020_Acoustic Echo Cancellation Based on Recurrent Neural Network
论文地址:https://ieeexplore.ieee.org/abstract/document/9306224 基于RNN的回声消除 摘要 本文提出了一种基于深度学习的语音分离技术的回声消除方法 ...
- 论文翻译:2021_A New Real-Time Noise Suppression Algorithm for Far-Field Speech Communication Based on Recurrent Neural Network
论文地址:一种新的基于循环神经网络的远场语音通信实时噪声抑制算法 引用格式:Chen B, Zhou Y, Ma Y, et al. A New Real-Time Noise Suppression ...
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
随机推荐
- OpenGL思维导图
- Perl 编程 基础用法
Perl 编程 标准头部写法 #!/usr/bin/perl -w # 标准的头部写法,-w意为显示警告 变量 $a=$b+10 # $a和$b都不需要定义,拿过来就用 Note: $flag=0 如 ...
- v72.01 鸿蒙内核源码分析(Shell解析) | 应用窥伺内核的窗口 | 百篇博客分析OpenHarmony源码
子曰:"苟正其身矣,于从政乎何有?不能正其身,如正人何?" <论语>:子路篇 百篇博客系列篇.本篇为: v72.xx 鸿蒙内核源码分析(Shell解析篇) | 应用窥视 ...
- FastAPI 学习之路(三十二)创建数据库
在大型的web开发中,我们肯定会用到数据库操作,那么FastAPI也支持数据库的开发,你可以用 PostgreSQL MySQL SQLite Oracle 等 本文用SQLite为例.我们看下在fa ...
- Less-(1~4) union select
Less-1: 核心语句: 无任何防护:回显查询结果或错误内容. 输入单引号闭合语句中的单引号,#注释后面的内容,即可注入.由于有查询结果回显,直接联合注入即可. 1'order by x #(有些环 ...
- 对比7种分布式事务方案,还是偏爱阿里开源的Seata,真香!(原理+实战)
前言 这是<Spring Cloud 进阶>专栏的第六篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得了? 阿里面 ...
- 面试题 08.12. N皇后
题目 设计一种算法,打印 N 皇后在 N × N 棋盘上的各种摆法,其中每个皇后都不同行.不同列,也不在对角线上.这里的"对角线"指的是所有的对角线,不只是平分整个棋盘的那两条对角 ...
- 极速上手 VUE 3 —— teleport传送门组件
一.teleport 介绍 teleport 传送门组件,提供一种简洁的方式,可以指定它里面的内容的父元素.通俗易懂地讲,就是 teleport 中的内容允许我们控制在任意的DOM中,使用简单. 使用 ...
- Java:锁笔记
Java:锁笔记 本笔记是根据bilibili上 尚硅谷 的课程 Java大厂面试题第二季 而做的笔记 1. Java 锁之公平锁和非公平锁 公平锁 是指多个线程按照申请锁的顺序来获取锁,类似于排队买 ...
- [对对子队]会议记录4.12(Scrum Meeting 3)
今天已完成的工作 朱骏豪 工作内容:找到了游戏的背景场景,用PS扣了按钮的图 相关issue:实现UI的美术需求 实现游戏场景中的必要模型 梁河览 工作内容:将关卡选择界面和欢迎界面导入项 ...