『学了就忘』Linux文件系统管理 — 57、Linux文件系统介绍
在了解Linux的文件系统管理之前,先简单了解一下硬盘的结构。
1、了解硬盘结构(了解即可)
(1)硬盘的逻辑结构
如下图所示:
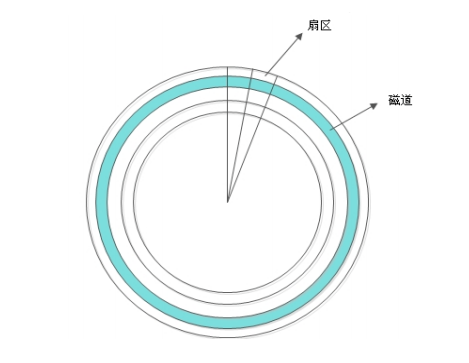
说明:
- 上图中一圈一圈的同心圆(蓝色部分),我们称之为磁道。数据就存放在磁道当中。
- 从磁盘的中心向外发散切割线,这切割先和磁道的重叠区域就是一个扇区。
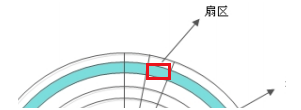
- 每个扇区的大小事固定的,为
512Byte。扇区也是磁盘的最小存贮单位。
接下来我们从侧面看,如下图所示:
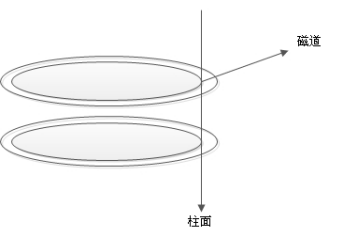
说明:
- 硬盘的大小是使用“磁头数×柱面数×扇区数×每个扇区的大小”这样的公式来计算的。
- 磁头数(
Heads)表示硬盘总共有几个磁头,也可以理解成为硬盘有几个盘面,然后乘以二(磁头在磁盘两面都有); - 柱面数(
Cylinders)表示硬盘每一面盘面有几条磁道(就是把磁盘横过来,磁盘是有厚度的,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。也可以说成磁道就是一个柱面,有多个磁道,就有多少个柱面数,磁盘的柱面数与一个盘面上的磁道数是相等的。) - 扇区数(
Sectors)表示每条磁道上有几个扇区;每个扇区的大小一般是512Byte。
硬盘示例图如下:
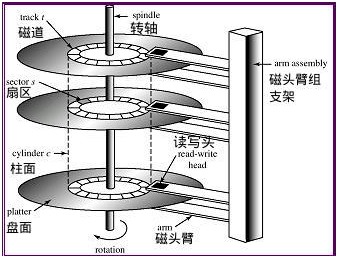
以上就是机械师硬盘,他的优点是,容量大,价格便宜。缺点,由于是物理结构的磁盘,需要转动磁盘来存储或者读取数据的,转速越快,存取效率越高。普通硬盘转速一般7200转每分钟,转速越高,硬盘发热量越大。(注意磁头是不搭在磁盘上的,是悬空的。)
(2)硬盘接口
硬盘接口的种类如下:
- IDE硬盘接口(
Integrated Drive Electronics,并口,即电子集成驱动器)也称作"ATA硬盘"
或"PATA硬盘”,是早期机械硬盘的主要接口,ATA133硬盘的理论速度可以达到133MB/s
(此速度为理论平均值),IDE硬盘接口。(基本淘汰) - SATA接口(
Serial ATA,串口)是速度更高的硬盘标准,具备了更高的传输速度,并具备了更强的纠错能力。目前已经是SATA三代,理论传输速度达到600MB/s(此速度为理论平均值)。 - SCSI接口(
Small Computer System Interface,小型计算机系统接口)广泛应用在服务器上,具有应用范围广、多任务、带宽大、CPU占用率低及支持热插拔等优点,理论传输速度达到320MB/s。(已淘汰)
2、Linux文件系统介绍
文件系统管理也就是分区管理。
(1)Linux文件系统的特性
super block(超级块):记录整个文件系统的信息,包括block与inode的总量,已经使用的inode和block的数量,未使用的inode和block的数量,block与inode的大小,文件系统的挂载时间,最近一次的写入时间,最近一次的磁盘检验时间等。date block(数据块,也称作block):用来实际保存数据的(相当于柜子的隔断),block的大小(1KB,2KB或4KB->默认)和数量在格式化后就已经决定,不能改变,除非重新格式化(制作柜子的时候,隔断大小就已经决定,不能更改,除非重新制作柜子)。
每个blcok只能保存一个文件的数据,要是文件数据小于一个block块,那么这个block的剩余空间不能被其他文件使用;要是文件数据大于一个block块,则占用多个block块。
Windows中磁盘碎片整理工具的原理就是把一个文件占用的多个block块尽量整理到一起,这样可以加快读写速度。inode(i节点,柜子门上的标签,128字节):用来记录文件的权限(r,w、x),文件的所有者和属组,文件的大小,文件的状态改变时间(ctime),文件的最近一次读取时间(atime),文件的最近一次修改时间(mtime),文件的数据真正保存的block编号。每个文件需要占用一个inode。
(2)Linux常见文件系统
ext:Linux中最早的文件系统,由于在性能和兼容性上具有很多缺陷,现在已经很少使用。ext2:是ext文件系统的升级版本,Red Hat Linux 7.2版本以前的系统默认都是ext2文件系统。于1993年发布,支持最大16TB的分区和最大2TB的文件(1TB=1024GB-1024× 1024KB)。ext3:ext2文件系统的升级版本,最大的区别就是带日志功能,以便在系统突然停止时,提高文件系统的可靠性。支持最大16TB的分区和最大2TB的文件。ext4:是ext3文件系统的升级版。ext4在性能、伸缩性和可靠性方面进行了大量改进。ext4的变化可以说是翻天覆地的,比如向下兼容ext3、最大1EB文件系统和16TB文件、无限数量子目录、Extents连续数据块概念、多块分配、延迟分配、持久预分配、快速FSCK、日志校验、无日志模式、在线碎片整理、inode增强、默认启用barrier等。它是CentOS6.x的默认文件系统。(说这么多,意思就是ext4文件系统比前三个强很多)xfs:XFS最早针对IRIX操作系统开发,是一个高性能的日志型文件系统,能够在断电以及操作系统崩溃的情况下,保证文件系统数据的一致性。它是一个64位的文件系统,后来进行开源并且移植到了Linux操作系统中,目前CentOS 7.x将XFS+LVM作为默认的文件系统。据官方所称,XFS对于大文件的读写性能较好。
(以上都是Linux系统中的文件系统,知道越新越好就可以了。 )swap:swap是Linux中用于交换分区的文件系统(类似于Windows中的虚拟内存),当内存不够用时,使用交换分区暂时替代内存。一般大小为内存的2倍,但是不要超过2GB,它是Linux的必需分区。NFS:NFS是网络文件系统(Network File System)的缩写,是用来实现不同主机之间文件共享的一种网络服务,本地主机可以通过挂载的方式使用远程共享的资源。iso9660:光盘的标准文件系统。Linux要想使用光盘,必须支持iso9660文件系统。fat:就是Windows下的fat16文件系统,在Linux中识别为fat。vfat:就是Windows下的fat32文件系统,在Linux中识别为vfat。支持最大32GB的分区和最大4GB的文件。NTFS:就是Windows下的NTFS文件系统,不过Linux默认是不能识别NTFS文件系统的,如果需要识别,则需要重新编译内核才能支持。它比fat32文件系统更加安全,速度更快支持最大2TB的分区和最大64GB的文件ufs:Sun公司的操作系统Solaris和SunOS所采用的文件系统。(用不着,了解一下即可)proc:Linux中基于内存的虚拟文件系统,用来管理内存存储目录/proc。(了解一下即可)sysfs:和proc一样,也是基于内存的虚拟文件系统,用来管理内存存储目录/sysfs。(了解一下即可)tmpfs:也是一种基于内存的虚拟文件系统,不过也可以使用swap交换分区。(了解一下即可)
3、整理一下对文件系统的认识
我们以前说一个分区,会分成两个部分,一小部分为上半部分,下面大部分为下半部分。
上半部分会分成一个一个i节点信息,理论上每个文件都会有自己唯一的i节点信息(如果遇到硬链接,两个文件的i节点就会一样)。
下半部分会分成一个一个block(数据块),在Linux系统下默认是4KB,用于存储数据。
如下图:
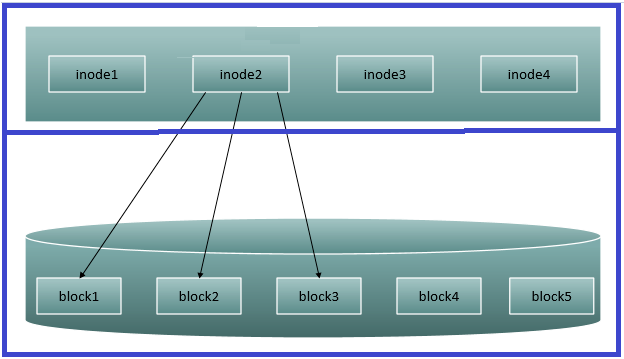
上边的图今天要稍微变一下。
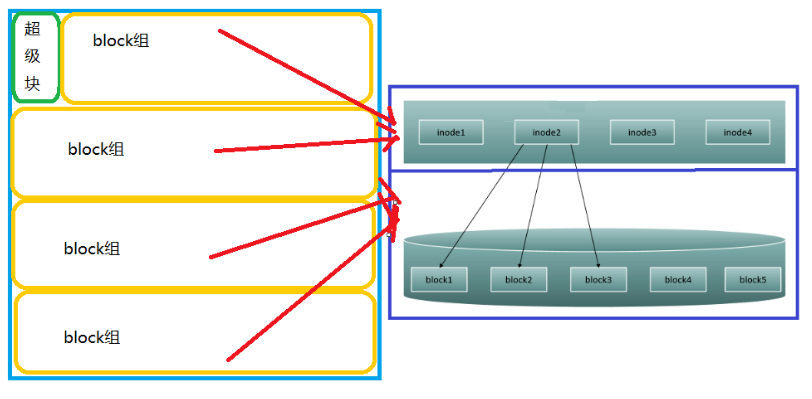
在我们的电脑上一般一个分区100GB,block块默认是4KB,所以100GB大小的分区,要有2500万+个block块。可以说是一个非常大的数字,这样会非常不好管理。
我们真正分区中系统文件的结构是如下:
首先一个分区,会在一个分区的开头,用一部分很小的空间,组成一个超级块。超级块的作用看上边,每个分区都会有一个超级块。
查看超级块信息,用下面命令。
[root@localhost ~]# dumpe2fs -h + 分区号(/dev/sda1)
然后该分区中的block块太多了,就在该分区中形成一些块组。在块组中,在进行上面形式的划分。
查看块组信息
[root@localhost ~]# dumpe2fs + 分区号(/dev/sda1)
Linux文件系统结构如下:
『学了就忘』Linux文件系统管理 — 57、Linux文件系统介绍的更多相关文章
- 『学了就忘』Linux基础命令 — 25、文件基本权限的管理
目录 1.文件和目录的默认权限 2.umask默认权限 (1)查看系统的umask权限 (2)用八进制数值显示umask权限 (3)umask权限的计算方法 (4)注意:umask默认权限的计算绝不是 ...
- 『学了就忘』Linux基础命令 — 23、文件基本权限的介绍和作用
目录 1.基本权限的介绍 (1)权限位的含义 (2)权限的优先级 2.权限的基本作用 (1)权限含义的解释 (2)目录权限说明 1.基本权限的介绍 (1)权限位的含义 前面讲解ls命令时,我们已经知道 ...
- 『学了就忘』Linux软件包管理 — 44、在RPM包中提取文件
目录 1.RPM包中文件的提取 2.在RPM包中提取文件的操作 (1)cpio命令介绍 (2)提取RPM包中文件 1.RPM包中文件的提取 为什么要做这个事呢? 在操作Linux系统的时候误删除一个文 ...
- 『学了就忘』Linux用户管理 — 50、用户管理相关文件详细说明
目录 1.用户信息文件 2./etc/shadow影子文件 3./etc/group 组信息文件 4.组密码文件 5.用户的家目录 6.用户邮箱目录 7.用户模板目录 总结: 提示:严格的用户权限划分 ...
- 『学了就忘』Linux权限管理 — 55、文件特殊权限
目录 1.文件特殊权限说明 2.设置SetUID 3.检测SetUID的脚本 4.设置SetGID (1)针对文件的作用 (2)针对目录的作用 5.Sticky BIT 6.设定文件特殊权限 7.文件 ...
- 『学了就忘』Linux基础 — 6、VMware虚拟机安装Linux系统(超详细)
目录 1.打开VMware虚拟机软件 2.选择Linux系统的ISO安装镜像 3.开启虚拟机安装系统 (1)进入Linux系统安装界面 (2)硬件检测 (3)检测光盘 (4)欢迎界面 (5)选择语言 ...
- 『学了就忘』Linux基础 — 7、补充:安装Linxu系统时设置硬盘挂载说明
目录 (1)新建一个/home分区 (2)再创建一个/boot分区. (3)创建一个swap分区 (4)最后剩余的空间全部分给根目录 (5)总结 上一篇在VMwar虚拟机中安装Linux操作系统中ht ...
- 『学了就忘』Linux基础 — 15、了解Linux系统的目录结构
目录 1.一级目录说明 (1)一级目录列表 (2)/bin/和/sbin/目录说明 (3)/boot/目录说明 (4)/lib/和/lib64/目录说明 (5)/lost+found/目录说明 (6) ...
- 『学了就忘』Linux基础 — 16、Linux系统与Windows系统的不同
目录 1.Linux严格区分大小写 2.Linux一切皆文件 3.Linux不靠扩展名区分文件类型 4.Linux中所有的存储设备都必须在挂载之后才能使用 5.Windows下的程序不能直接在Linu ...
随机推荐
- python socket 基本使用
socket通常也叫做"套接字",用于连接server client,是一个通信链的句柄,应用程序通常通过套接字向网络发出请求或应答网络请求. 就像python 处理file一样: ...
- RabbitMQ:从入门到搞定面试官
安装 使用docker安装,注意要安装tag后缀为management的镜像(包含web管理插件),我这里使用的是rabbitmq:3.8-management 1. 拉取镜像 shell docke ...
- 周末愉快--css画大熊猫
周末找了点轻松的话题,css画大熊猫. 先上效果图 欢迎竞猜大熊猫到底说了什么?? 再上源码 <!DOCTYPE html> <html lang="en"> ...
- Coursera Deep Learning笔记 结构化机器学习项目 (下)
参考:https://blog.csdn.net/red_stone1/article/details/78600255https://blog.csdn.net/red_stone1/article ...
- LeetCode:堆专题
堆专题 参考了力扣加加对与堆专题的讲解,刷了些 leetcode 题,在此做一些记录,不然没几天就忘光光了 力扣加加-堆专题(上) 力扣加加-堆专题(下) 总结 优先队列 // 1.java中有优先队 ...
- Java-基础-LinkedList
1. 简介 LinkedList 同时实现了List和Deque接口,也就是说它既可以看作是一个顺序容器,又可以看作是双向队列. 既然是双向列表,那么它的每个数据节点都一定有两个指针,分别指向它的前驱 ...
- 算法:Z字型(Zigzag)编排
问题:给定 n 行和 m 列的二维数组矩阵.如图所示,以 ZIG-ZAG 方式打印此矩阵. 从对称的角度来看,通过反复施加滑行反射可以从简单的图案如线段产生规则的之字形. 主要思想:算法从(0, 0) ...
- linux hostid与lmhostid
https://wangchujiang.com/linux-command/c/hostid.html hostid(host identifier) 显示当前主机的十六进制数字标识. 概要 hos ...
- Python Numpy matplotlib Histograms 直方图
import numpy as np import matplotlib.pyplot as plt mu,sigma = 2,0.5 v = np.random.normal(mu,sigma,10 ...
- cf 24 Game (观察+.. 想一想)
题意: 给一个数N,从1到N. 每次取两个数,三种操作:加.减.乘,运算完得一个数,把那俩数删了,把这个数加进去. 重复操作N-1次. 问是否可能得到24.若可以,输出每一步操作. 思路: 小于4,不 ...