面试HashMap你都扛不住,还想拿到offer?
当我们面试Java开发岗位时,面试官问的频率出现最多的问题,就是这个HashMap,不管是传统型公司还是互联公司,HashMap是必问的,所以作者爆肝整理了HashMap的23个问题以及答案,请查收!
1、你知道HashMap的数据结构吗?
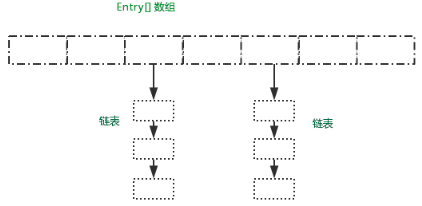
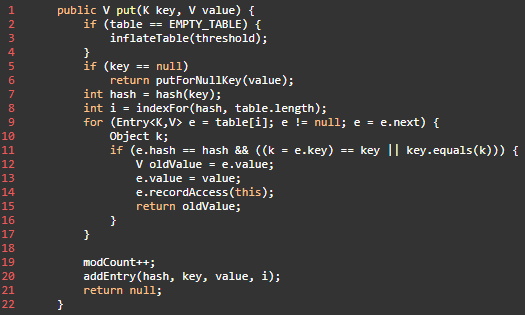
- 判断当前数组是否需要初始化。
- 如果 key 为空,则 put 一个空值进去。
- 根据 key 计算出 hashcode。
- 根据计算出的 hashcode 定位出所在桶。
- 如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。
- 如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置
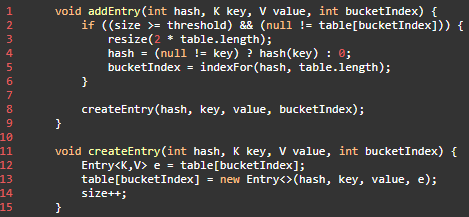
- 当调用 addEntry 写入 Entry 时需要判断是否需要扩容。
- 如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。
- 而在 createEntry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。
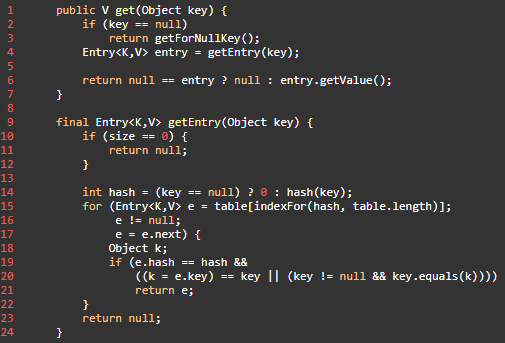
- 首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。
- 判断该位置是否为链表。
- 不是链表就根据 key、key 的 hashcode 是否相等来返回值。
- 为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。
- 啥都没取到就直接返回 null
- 当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树;
- 如果当前桶已经为红黑树,那就要按照红黑树的方式写入数据;

- 首先将 key hash 之后取得所定位的桶。
- 如果桶为空则直接返回 null 。
- 否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
- 如果第一个不匹配,则判断它的下一个是红黑树还是链表。
- 红黑树就按照树的查找方式返回值。
- 不然就按照链表的方式遍历匹配返回值。
- 由数组+链表的结构改为数组+链表+红黑树。
- 优化了高位运算的hash算法:h^(h>>>16)
- 扩容后,元素要么是在原位置,要么是在原位置再移动2次幂的位置,且链表顺序不变。
- 因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要;
- 当元素小于8个当时候,此时做查询操作,链表结构已经能保证查询性能;
- 当元素大于8个的时候,此时需要红黑树来加快查询速度,但是新增节点的效率变慢了;
- 如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的;
- 扩容 resize()时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表。
- 移除元素 remove()时,在removeTreeNode()方法会检查红黑树是否满足退化条件,与结点数无关。如果红黑树根root为空,或者root的左子树/右子树为空,root.left.left根的左子树的左子树为空,都会发生红黑树退化成链表。
- 多线程扩容,引起的死循环问题
- 多线程put的时候可能导致元素丢失
- put非null元素后get出来的却是null
- 因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
- 因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的,这些类已经很规范的覆写了hashCode()以及equals()方法。

输出值如下:

19、HashMap是线程安全的吗?如何实现线程安全?
- 通过Collections.synchronizedMap()来封装所有不安全的HashMap的方法,就连toString, hashCode都进行了封装,就是为每一个方法添加了synchronized关键字进行修饰。使用的是的synchronized方法,是一种悲观锁.在进入之前需要获得锁,确保独享当前对象,然后做相应的修改/读取。方式简单粗暴,但是效率低。
- 使用ConcurrentHashMap。只有在需要修改对象时,比较和之前的值是否被人修改了,如果被其他线程修改了,那么就会返回失败,是一种无锁的实现。基于CAS实现,类似于乐观锁机制。ConcurrentHashMap采用了"锁分段"策略,ConcurrentHashMap的主干是一个一个Segment组,在ConcurrentHashMap中,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的,对于同一个Segment的操作才需考虑线程同步。理论上就允许16个线程并发执行。
- 要统计整个ConcurrentHashMap的元素个数,可以将每个Segment的count相加,count是volatile变量,可以保证读到的是最新值,但count可能会在累加过程中发生改变,导致结果不正确。
- ConcurrentHashMap采用HashMap中的“快速失败”机制,即设置一个modCount变量,在put,remove,clean方法中都让modCount++,先尝试两次通过不对Segment加锁的方式统计Size,若发现前后的modCount不一致,则说明容器大小发生了变化,此时再通过锁住所有Segment的put,remove,clean方法计算count。
22、ConcurrentHashMap中put过程?
因为volatile不保证原子性,所以在put操作中需要对Segment加锁。
put操作分为两步:
- 是否需要扩容
- 在插入元素前先判断Segment里的HashEntry数组是否超过容量(cap*loadFactor),如果超过阈值,就进行扩容。值得一提的是,在HashMap中,是先插入元素后再检查是否达到容量,有可能造成扩容之后再也没有新元素插入,造成空间浪费。
- 举个例子,在ConcurrentHashMap中,现有元素正好等于容量,那么就先判断是否超过容量(没有超过),那么添加新元素(此时超出容量一个元素,但没有扩容)。而如果是HashMap,则先插入这个元素,发现超出容量,于是扩容,可再也没有新的元素添加进来了,于是造成了浪费。
- 定位元素位置
- 遍历HashEntry链表,找到对应元素位置并更新
23、HashMap和HashTable的区别?
- HashMap基于数组和链表实现。不考虑Hash冲突的情况下,仅需一次定位就能找到元素。比如在新增元素的时候,通过Hash函数将元素定位Hash表中某个位置,直接将数据存入到该地址上,当我们查找或者删除元素,可以直接通过Hash函数定位到该数据。但是没有什么事情都是完美的,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。HashMap采用了链地址法,也就是数组+链表的方式。把相同Hash值的数据放在了链表上。当HashMap中的链表出现越少,性能才会越好。当发生哈希冲突并且size大于阈值的时候,需要进行数组扩容,扩容时,需要新建一个长度为之前数组2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去,扩容后的新数组长度为之前的2倍,所以扩容相对来说是个耗资源的操作。HashMap继承自AbstractMap,HashMap允许key、value为空。HashMap默认容量是16,且负载因子是0.75。HashMap是线程不安全的,效率高。
- HashTable和HashMap的实现原理几乎一样,HashTable不允许key和value为null;HashTable是线程安全的。但是HashTable线程安全的策略实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
以上是整理的比较全面的HashMap面试题,大家记住答案的同时,最好还是理解其原理,往期精彩面试题解析回顾:
- JAVA面试题 String s = new String("xyz");产生了几个对象?
- Java面试题 从源码角度分析HashSet实现原理?
- JAVA面试题 请谈谈你对Sychronized关键字的理解?
- JAVA面试题 线程的生命周期包括哪几个阶段? - Java蚂蚁 - 博客园 (cnblogs.com)
- JAVA面试题 StringBuffer和StringBuilder的区别,从源码角度分析?
- JAVA面试题 手写ArrayList的实现,在笔试中过关斩将?
- JAVA面试题 浅析Java中的static关键字?
- JAVA面试题 启动线程是start()还是run()?为什么?
- Java面试题 equals()与"=="的区别?
面试HashMap你都扛不住,还想拿到offer?的更多相关文章
- Java面试& HashMap实现原理分析
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O( ...
- 你要的 React 面试知识点,都在这了
摘要: 问题很详细,插图很好看. 原文:你要的 React 面试知识点,都在这了 作者:前端小智 Fundebug经授权转载,版权归原作者所有. React是流行的javascript框架之一,在20 ...
- 经济学人精读笔记7:动乱当道,你还想买LV吗?
2020/2/24 经济学人精读笔记7:动乱当道,你还想买LV吗? 标签(空格分隔): 经济学人 Part 1 Luxury goods A tale of two handbags Purveyor ...
- [转载] JAVA面试题和项目面试核心要点精华总结(想进大公司必看)
JAVA面试题和项目面试核心要点精华总结(想进大公司必看) JAVA面试题和项目面试核心要点精华总结(想进大公司必看)
- iview 验证 trigger: 'blur,change', 同时加两个,省的每次还想input 还是 select
iview 验证 trigger: 'blur,change', 同时加两个,省的每次还想input 还是 select dataRuleValidate: { name: [{ required: ...
- 想进大厂,想收获高薪offer,资深猎头告诉你怎么做......
其实吧,面试官面试的时候主要就看三个方面:现在能力如何,未来潜力如何,人品如何. 第一个因素是最重要的,因为后面两个因素有太多的人为判断因素,无法量化.所谓的面试准备,"现在能力如何&quo ...
- 算法寒假实习面试经过之 滴滴(电话一面二面 offer)
一面:1h 介绍比赛项目. lr与xgb的区别? xgb 为什么不用归一化,onehot? xgb 与 gbdt的区别. 做这些比赛你们的优势在哪,既然全是相同的套路. RCNN的原理, CNN的原理 ...
- JAVA JAVA面试题和项目面试核心要点精华总结(想进大公司必看)
http://blog.csdn.net/ourpush/article/details/53706524 1.常问数据库查询.修改(SQL查询包含筛选查询.聚合查询和链接查询和优化问题,手写SQL语 ...
- docker扫盲,面试连这都不会就等着挂吧!
现在很多公司项目部署都是采用K8S docker容器方式,出门面试被问的概率极大,如果被面试官问docker相关知识点直接懵逼,那么基本就是被pass了,除非其他方面技术过硬.所以这种相对前沿的技术, ...
随机推荐
- Netty基础招式——ChannelHandler的最佳实践
本文是Netty系列第7篇 上一篇文章我们深入学习了Netty逻辑架构中的核心组件EventLoop和EventLoopGroup,掌握了Netty的线程模型,并且介绍了Netty4线程模型中的无锁串 ...
- Vue 脚手架学习
首先就是安装脚手架 npm install @vue/cil -g 全局安装 在这里我遇到一个问题:安装不了脚手架,报错显示: 通过苦逼的查找原因就是 以前使用的taobao镜像 导致的,删除镜像换成 ...
- 跟你说个笑话,硕士毕业两年,月薪10k,天天面向CV编程
"枯燥乏味的一天,又tm要开始了". 早上10:00,程序员毛毛带着路上买的早餐,打开24英寸的显示屏,去某论坛查一下昨天没有解决的bug. 9 个小时增删改查.搬砖写代码的一天又 ...
- 【剑指offer】65. 不用加减乘除做加法
剑指 Offer 65. 不用加减乘除做加法 知识点:数学:位运算 题目描述 写一个函数,求两个整数之和,要求在函数体内不得使用 "+"."-"."* ...
- Kong网关安装之Docker版(1)
前言: Kong 是天生的微服务网关.她的官方简介是:Kong 是一个云原生,高效,可扩展的分布式 API 网关. 自 2015 年在 github 开源后,广泛受到关注,目前已收获 1.9w+ 的 ...
- Build Web Server with Apache and Passenger
Follow the instructions at 2.6. Generic installation, upgrade and downgrade method: via tarball of P ...
- MySQL学习07(规范化数据库设计)
规范化数据库设计 当数据库比较复杂时我们需要设计数据库 糟糕的数据库设计 : 数据冗余,存储空间浪费 数据更新和插入的异常 程序性能差 良好的数据库设计 : 节省数据的存储空间 能够保证数据的完整性 ...
- 【Java】jeesite使用学习
初始配置环境及软件: 名称 版本 作用 Tomcat 7.0 微小型服务器,版本无所谓,装个Tomcat 9估计也没事 IntelliJ IDEA 2021.1.3 x64 2021.1.3 编译器, ...
- SpringBoot开发四-MyBatis入门
需求介绍-MyBatis入门 首先就是安装Mysql Server 和Mysql Workbench. SqlSessionFactory:用于创建SqlSession的工厂类 SqlSession: ...
- 【网络编程】TCPIP_3_地址族与数据序列
目录 前言 3. 地址族与数据序列 3.1 分配给套接字的 IP 地址与端口号 3.2 参数 IP 地址 3.2.1 IPV4 地址的结构体 3.2.2 地址族(Address Family) 3.2 ...