Spark Stage 的划分
Spark作业调度
对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation操作封装成作业并向集群提交运行。这个过程大致可以如下描述:
- 由DAGScheduler对RDD之间的依赖性进行分析,通过DAG来分析各个RDD之间的转换依赖关系
- 根据DAGScheduler分析得到的RDD依赖关系将Job划分成多个stage
- 每个stage会生成一个TaskSet并提交给TaskScheduler,调度权转交给TaskScheduler,由它来负责分发task到worker执行
接下来,理解 Spark 中RDD的依赖关系.
RDD依赖关系
Spark中RDD的粗粒度操作,每一次transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用,
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用(宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作)
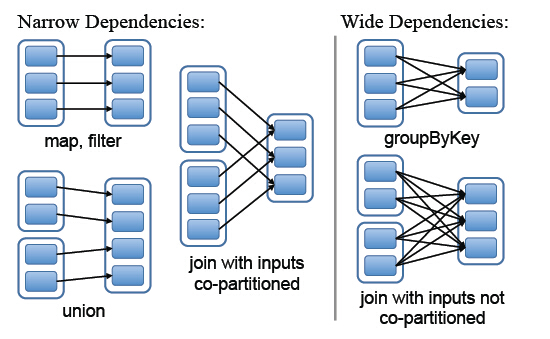
图中左边都是窄依赖关系,可以看出分区是1对1的。右边为宽依赖关系,有分区是1对多。(map,filter,union属于第一类窄依赖)
stage的划分
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。实际应用提交的Job中RDD依赖关系是十分复杂的,依据这些依赖关系来划分stage自然是十分困难的,Spark此时就利用了前文提到的依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系的一种叫法)就断开,遇到NarrowDependency就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定,RDD转换是基于分区的一种粗粒度计算,一个stage执行的结果就是这几个分区构成的RDD。
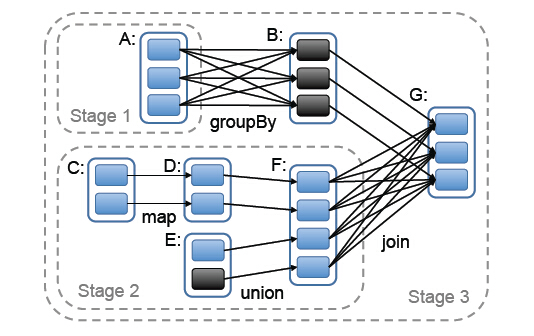
图中可以看出,在宽依赖关系处就会断开依赖链,划分stage,这里的stage1不需要计算,只需要计算stage2和stage3,就可以完成整个Job。
总结:遇到一个宽依赖就分一个stage
参考博客:https://blog.csdn.net/mahuacai/article/details/51919615
Spark Stage 的划分的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 用实例说明Spark stage划分原理
注意:此文的stage划分有错,stage的划分是以shuffle操作作为边界的,可以参考<spark大数据处理技术>第四章page rank例子! 参考:http://litaotao. ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- stage的划分
stage的划分是以shuffle操作作为边界的,遇到一个宽依赖就分一个stage 一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage.S ...
- 窄依赖与宽依赖&stage的划分依据
RDD根据对父RDD的依赖关系,可分为窄依赖与宽依赖2种. 主要的区分之处在于父RDD的分区被多少个子RDD分区所依赖,如果一个就为窄依赖,多个则为宽依赖.更好的定义应该是: 窄依赖的定义是子RDD的 ...
- Spark 宽窄依赖和stage的划分
窄依赖 父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的 ...
- Spark Stage切分 源码剖析——DAGScheduler
Spark中的任务管理是很重要的内容,可以说想要理解Spark的计算流程,就必须对它的任务的切分有一定的了解.不然你就看不懂Spark UI,看不懂Spark UI就无法去做优化...因此本篇就从源码 ...
- spark的知识的链接
IDEA 创建scala spark的Mvn项目:https://blog.csdn.net/u014646662/article/details/84618032 Spark详解03Job 物理执行 ...
随机推荐
- js实现日期格式化封装--八种
封装一个momentTime.js文件,包含8种格式. 需要传两个参数: 时间戳:stamp 格式化的类型:type, 日期补零的方法用到es6语法中的padStart(length,'字符'): 第 ...
- spark搭建
1.上传解压,配置环境变量 配置bin目录 2.修改配置文件 conf cp spark-env.sh.template spark-env.sh 增加配置 export SPARK_MASTER_I ...
- 动态sql & 抽取可重用sql
抽取可重用的sql片段 抽取:<sql id="xx"></sql> 使用:<include refid="xx">< ...
- vue配置请求拦截器和响应拦截器
首先确保我们已经设置的store.js进行值的存取,这时候我们需要配置请求和响应的拦截器设置 main.js import Vue from 'vue' import App from './App' ...
- RabbitMQ(六)消息幂等性处理
一.springboot整合rabbitmq 我们需要新建两个工程,一个作为生产者,另一个作为消费者.在pom.xml中添加amqp依赖: <dependency> <groupId ...
- 解决tomcat的404问题
遇到的问题 点击startup.bat启动tomcat启动成功,但在网页上输入local:8080却显示Access Error: 404 -- Not Found Cannot locate doc ...
- python实现模糊操作
目录: (一)模糊或平滑与滤波的介绍 (二)均值模糊 (1) 原理 (2)代码实现-----均值模糊函数blur() (三)中值模糊------mediaBlur函数 (四)高斯模糊------Gau ...
- [cf1137F]Matches Are Not a Child's Pla
显然compare操作可以通过两次when操作实现,以下仅考虑前两种操作 为了方便,将优先级最高的节点作为根,显然根最后才会被删除 接下来,不断找到剩下的节点中(包括根)优先级最高的节点,将其到其所在 ...
- [atARC061F]Card Game for Three
记录每一次操作的玩家为操作序列(去掉第一次),需要满足:$a$的个数为$n$且以$a$为结尾,$b$和$c$的个数分别不超过$m$和$k$ 其所对应的概率:每一个字符恰好确定一张卡牌,因此即$3^{n ...
- [atARC078F]Mole and Abandoned Mine
注意到最终图的样子可以看作一条从1到$n$的路径,以及删去这条路径上的边后,路径上的每一个点所对应的一个连通块 考虑dp,令$f_{S,i}$表示当前1到$n$路径上的最后一个点以及之前点(包括$i$ ...