在前端页面中使用Markdown并且优化a标签
近期在自己的项目中加入了对 Markdown 语法 的支持,主要用到的是markedjs这个项目。该项目托管在github上,地址为:https://github.com/markedjs/marked/
项目的安装
下载项目之后,在根目录下执行如下 npm 命令 进行安装
$ npm install
安装完成之后最终项目的目录结构如下
我们看一下根目录下的 package.json 文件,部分内容如下。 json有自己的语法格式,可以参考 Json 教程
"scripts": {
"test": "jasmine --config=jasmine.json",
"test:all": "npm test && npm run test:lint",
"test:unit": "npm test -- test/unit/**/*-spec.js",
"test:specs": "npm test -- test/specs/**/*-spec.js",
"test:lint": "eslint bin/marked .",
"test:redos": "node test/vuln-regex.js",
"test:update": "node test/update-specs.js",
"rules": "node test/rules.js",
"bench": "npm run rollup && node test/bench.js",
"lint": "eslint --fix bin/marked .",
"build:reset": "git checkout upstream/master lib/marked.js lib/marked.esm.js marked.min.js",
"build": "npm run rollup && npm run minify",
"build:docs": "node build-docs.js",
"rollup": "npm run rollup:umd && npm run rollup:esm",
"rollup:umd": "rollup -c rollup.config.js",
"rollup:esm": "rollup -c rollup.config.esm.js",
"minify": "uglifyjs lib/marked.js -cm --comments /Copyright/ -o marked.min.js",
"minifyMessage": "uglifyjs ext/onmpwmessage.js -cm --comments /Copyright/ -o ext/onmpwmessage.min.js",
"preversion": "npm run build && (git diff --quiet || git commit -am build)"
}
执行如下命令
$ npm run build
命令执行完成会生成marked.min.js文件
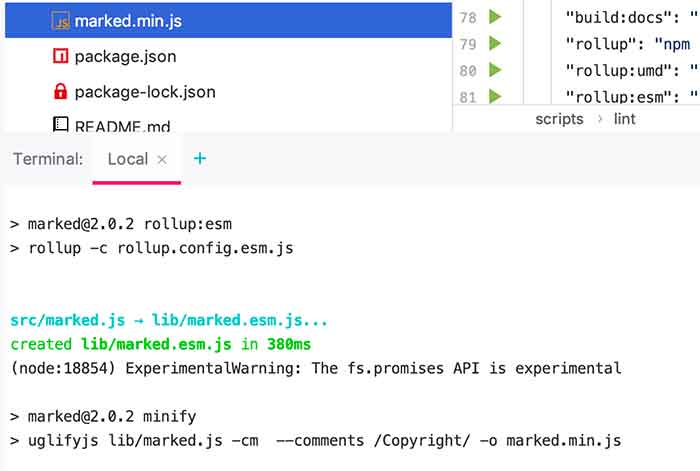
最后我们将 marked.min.js 文件拷贝到我们的项目中,然后就可以使用了
使用markedjs 解析编译Markdown内容
在页面中引入 marked.min.js 文件
<script type="text/javascript" src="/js/marked.min.js"></script>
接下来就是对内容的解析了,首先要初始化marked对象
marked.setOptions({
renderer: new marked.Renderer(),
gfm: true,
tables: true,
breaks: false,
pedantic: false,
sanitize: false,
smartLists: true,
smartypants: false,
highlight: function (code,lang) {
//使用 highlight 插件解析文档中代码部分
return hljs.highlightAuto(code,[lang]).value;
}
});
然后调用marked函数进行解析
let originText = "[迹忆客](https://www.jiyik.com)";
let newText = marked(originText);
console.log(newText);
实际情况中我们可以通过ajax从后台获取markdown的内容,然后通过marked解析成 html,将解析后的 html 内容放到页面中相应的地方即可。
说一下我的markdown的应用
本人的项目中不是在前端对Markdown进行转换,而是在编辑器中按照Markdown语法编辑好内容之后,通过markedjs将内容转换成html,存入到数据库中,在前台取出来的直接就是解析后的内容了,可以直接显示在页面上。
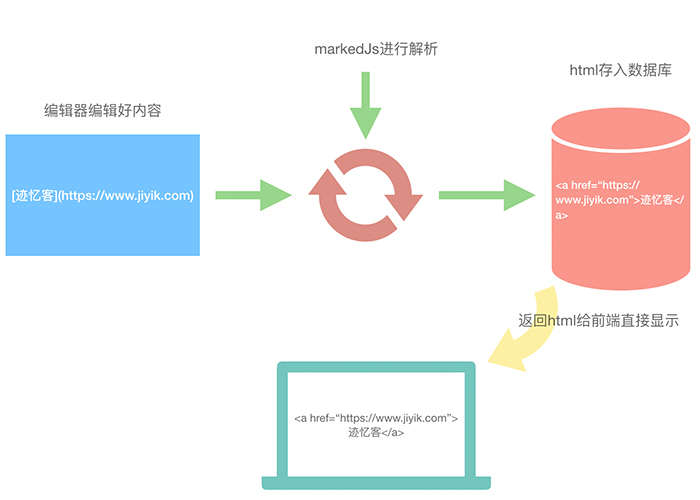
对markedJs的优化
下面到了本次重点内容了,markedJs相对来说比较成熟,个人感觉功能还是比较全面的。然而美中不足的是,可能受markdown默认语法的影响,对 a标签 的解析只有是当前页面打开,没有新窗口打开的语法。也就是说对于下面的语法
[迹忆客](https://www.jiyik.com "这里是title")
最终只能转换成
<a href="https://www.jiyik.com" title="这里是title">迹忆客</a>
如果我想要新窗口打开的a标签,是没有对应的语法可以使用的。总不能因为一个a标签就将markedJs抛弃不用吧,面对这种情况,即然项目是开源的,那就试着看一下自己能不能加上这一属性。
我总共用了三种方法来增加target这一属性
直接暴力添加
最开始我是这么考虑的,在项目中一般都是在文章内容里才会用到markdown的语法。一般情况下文章内容中的跳转都会使用新窗口打开。所以说,直接在解析后的a标签中加上属性target="_blank"。
按照这一思路,我就直接去看源码。此种方式有个最简单的方式就是全项目搜索<a。找到构造 a 标签的地方,在后面直接加上 target="_blank" 就可以了。
在项目中的 src/Renderer.js 文件中的140行左右
let out = '<a href="' + escape(href) + '"';
直接添加target属性
let out = '<a href="' + escape(href) + '" target="_blank"';
然后在根目录下执行命令
$ npm run build
将生成的 marked.min.js 应用到项目中。之后再新添加的a标签都带着 target="_blank" 属性。
虽然添加上了,但是仔细想想这种方式和没优化之前并没有什么区别,只是一个新窗口,一个不新窗口。没办法进行控制是最痛苦的。要是能通过某种方式对这个属性进行控制,那就完美了。
使用!控制属性是否添加
要想能控制target属性,就要在[]()中使用某种符号进行标记。img标签对应的markdown的语法为![]()。借鉴img标签的语法,我把叹号放到中括号里面[!]来实现对target属性的控制。
要实现的效果如下
[迹忆客](https://www.jiyik.com) // 解析后为 <a href="https://www.jiyik.com">迹忆客</a> [!迹忆客](https://www.jiyik.com) // 解析后为 <a href="https://www.jiyik.com" target="_blank">迹忆客</a>
要实现这种效果,就不像上面一样了,直接全项目搜索 <a 是没什么用的。这里我使用了WebStorm打开marked项目,然后利用上面的调试工具,追踪它的代码。
首先要在webstorm中配置markedJs,使其能够运行。首先新建 node.js 脚本运行
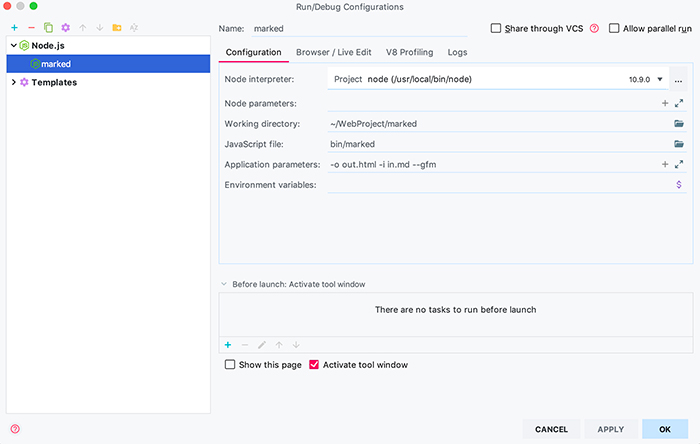
新建成功之后,可以在代码中打上断点,运用webstorm的调试功能来追踪其代码。
当然这里不能在项目的入口文件就打断点,这样在追踪的过程中是很痛苦的,因为如果代码层级很深的话,容易走着走着就迷路了。
先读源码,在认为和解析a标签相关的地方打上断点。在读了源码之后,我是在 src/Tokenizer.js文件中的 link() 方法里打上的断点(在 474 行)
经过追踪,最终跟到了src/Tokenizer.js中的outputLink()方法中,其实现如下:
function outputLink(cap, link, raw) {
const href = link.href;
const title = link.title ? escape(link.title) : null;
const text = cap[1].replace(/\\([\[\]])/g, '$1');
if (cap[0].charAt(0) !== '!') {
return {
type: 'link',
raw,
href,
title,
text,
};
} else {
return {
type: 'image',
raw,
href,
title,
text: escape(text)
};
}
}
代码中的 text 保存的就是 [迹忆客] 中的文本(迹忆客)。如果我们加上叹号,[!迹忆客],那text的值为“!迹忆客”。这样我们就可以对text的文本做一个判断,如果第一个字母是叹号!,则就要将target的值设置为"_blank"。否则的话target就为空。然后在返回的对象中加上target属性。修改后的代码如下
function outputLink(cap, link, raw) {
const href = link.href;
const title = link.title ? escape(link.title) : null;
const text = cap[1].replace(/\\([\[\]])/g, '$1');
if (cap[0].charAt(0) !== '!') {
let a_text = text;
let target = "";
if(a_text.charAt(0) === '!') {
target = "_blank";
a_text = a_text.substring(1); // 这里将文本中的!去掉
}
return {
type: 'link',
raw,
href,
title,
text:a_text,
target
};
} else {
return {
type: 'image',
raw,
href,
title,
text: escape(text)
};
}
}
然后继续追踪代码,来到了我们第一种方法中暴力添加的地方 link() 方法。这里我们不再使用暴力了,因为我们现在有选择了,需要给link方法增加一个参数 target。
link(href, title, text, target) {
href = cleanUrl(this.options.sanitize, this.options.baseUrl, href);
if (href === null) {
return text;
}
let out = '';
if(target !== "") {
out = '<a href="' + escape(href) + '" target="' + escape(target) + '"';
}else{
out = '<a href="' + escape(href) + '"';
}
if (title) {
out += ' title="' + title + '"';
}
out += '>' + text + '</a>';
return out;
}
然后我们继续找到调用link方法的地方—— src/Parser.js文件的第219行

在link方法调用的地方将 target参数传过去
case 'link': {
out += renderer.link(token.href, token.title, this.parseInline(token.tokens, renderer),token.target);
break;
}
到这里我们所有的代码就修改完成了,接下来就是编译项目,生成 marked.min.js 文件,在我的项目中使用了。
使用了一段时间,没有发现什么问题。但是总感觉这种方式不够彻底,当然不是说对于语法上不够彻底,而是对于代码上不够彻底。在匹配出text之后,还要对text的首字母进行判断,然后在截取字符串。效率上应该是有些不足(虽然实际情况没什么影响,但是毕竟要本着精益求精的态度不是吗,请允许我装一下)。还是应该继续优化代码,接下来就来到了终极的方法
究极大招,修改规则
即然不想从文本那里动手,那就要改变其匹配的规则。同样继续使用webstorm断点调试。可以发现对所有的标签匹配的规则如下
const inline = {
escape: /^\\([!"#$%&'()*+,\-./:;<=>?@\[\]\\^_`{|}~])/,
autolink: /^<(scheme:[^\s\x00-\x1f<>]*|email)>/,
url: noopTest,
tag: '^comment'
+ '|^</[a-zA-Z][\\w:-]*\\s*>' // self-closing tag
+ '|^<[a-zA-Z][\\w-]*(?:attribute)*?\\s*/?>' // open tag
+ '|^<\\?[\\s\\S]*?\\?>' // processing instruction, e.g. <?php ?>
+ '|^<![a-zA-Z]+\\s[\\s\\S]*?>' // declaration, e.g. <!DOCTYPE html>
+ '|^<!\\[CDATA\\[[\\s\\S]*?\\]\\]>', // CDATA section
link: /^!?\[(label)\]\(\s*(href)(?:\s+(title))?\s*\)/,
reflink: /^!?\[(label)\]\[(?!\s*\])((?:\\[\[\]]?|[^\[\]\\])+)\]/,
nolink: /^!?\[(?!\s*\])((?:\[[^\[\]]*\]|\\[\[\]]|[^\[\]])*)\](?:\[\])?/,
reflinkSearch: 'reflink|nolink(?!\\()',
emStrong: {
lDelim: /^(?:\*+(?:([punct_])|[^\s*]))|^_+(?:([punct*])|([^\s_]))/,
// (1) and (2) can only be a Right Delimiter. (3) and (4) can only be Left. (5) and (6) can be either Left or Right.
// () Skip other delimiter (1) #*** (2) a***#, a*** (3) #***a, ***a (4) ***# (5) #***# (6) a***a
rDelimAst: /\_\_[^_]*?\*[^_]*?\_\_|[punct_](\*+)(?=[\s]|$)|[^punct*_\s](\*+)(?=[punct_\s]|$)|[punct_\s](\*+)(?=[^punct*_\s])|[\s](\*+)(?=[punct_])|[punct_](\*+)(?=[punct_])|[^punct*_\s](\*+)(?=[^punct*_\s])/,
rDelimUnd: /\*\*[^*]*?\_[^*]*?\*\*|[punct*](\_+)(?=[\s]|$)|[^punct*_\s](\_+)(?=[punct*\s]|$)|[punct*\s](\_+)(?=[^punct*_\s])|[\s](\_+)(?=[punct*])|[punct*](\_+)(?=[punct*])/ // ^- Not allowed for _
},
code: /^(`+)([^`]|[^`][\s\S]*?[^`])\1(?!`)/,
br: /^( {2,}|\\)\n(?!\s*$)/,
del: noopTest,
text: /^(`+|[^`])(?:(?= {2,}\n)|[\s\S]*?(?:(?=[\\<!\[`*_]|\b_|$)|[^ ](?= {2,}\n)))/,
punctuation: /^([\spunctuation])/
};
这里我们只关心link规则
link: /^!?\[(label)\]\(\s*(href)(?:\s+(title))?\s*\)/
原来你一开始就没有把我们可爱的target考虑进去,target一定不是亲生的。
即然你不要,那我们就自己动手将其加进去吧,修改规则如下
link: /^!?\[(target)(label)\]\(\s*(href)(?:\s+(title))?\s*\)/,
这还不够,像里面的 target、label、href和title这都是一个标记,来说明此处应该是什么。用这种正则去匹配也匹配不出什么东西来啊。下面肯定还藏着有东西呢。于是继续寻找,最终发现下面的代码
inline._label = /(?:\[(?:\\.|[^\[\]\\])*\]|\\.|`[^`]*`|[^\[\]\\`])*?/;
inline._href = /<(?:\\.|[^\n<>\\])+>|[^\s\x00-\x1f]*/;
inline._title = /"(?:\\"?|[^"\\])*"|'(?:\\'?|[^'\\])*'|\((?:\\\)?|[^)\\])*\)/; inline.link = edit(inline.link)
.replace('label', inline._label)
.replace('href', inline._href)
.replace('title', inline._title)
.getRegex();
啊哈哈,这就对上了。这是为了防止一个这么长的正则不好阅读,所以才使用标记来进行说明,然后由程序自己来替换使用。还挺人性化的吗,这里给点个赞。
这就好办了,上面我们即然加上了target的标记,那这里我们也加个正则来匹配我们的叹号!
inline._target = /!?/; inline.link = edit(inline.link)
.replace('target',inline._target)
.replace('label', inline._label)
.replace('href', inline._href)
.replace('title', inline._title)
.getRegex();
因为我要捕获匹配的结果,所以在上面target标记外面加了小括号(target) 。 这里是属于正则表达式的知识点了。所以说正则表达式还是很重要的,如果不了解正则那我们也就没有大招了。到了第二种方式也就停止了。看到这是不是有种想学习正则表达式的冲动了。点击学习正则表达式。
接下来我们要对在第二种方式中修改的 outputlink() 方法再次进行修改
function outputLink(cap, link, raw) {
const href = link.href;
const title = link.title ? escape(link.title) : null;
const text = cap[2].replace(/\\([\[\]])/g, '$1');
const target = (cap[1].length == 1 && cap[1] === '!')?"_blank":"";
if (cap[0].charAt(0) !== '!') {
return {
type: 'link',
raw,
href,
title,
text,
target
};
} else {
return {
type: 'image',
raw,
href,
title,
text: escape(text)
};
}
}
看起来,是不是变简单了呢。不过只是修改这里还是不行的,因为我们前面在正则中多加了一个捕获组,所以对于之前的text、href和title它们的分组索引都要加 1 才对。
要在哪里修改呢,这里继续往下寻找,又找到了一个link方法,但是这个link方法和之前加参数的 link 方法不同。该link方法是 src/Tokenizer.js 文件中定义的。
link(src) {
const cap = this.rules.inline.link.exec(src);
if (cap) {
const trimmedUrl = cap[3].trim(); // 原先为 cap[2].trim()
if (!this.options.pedantic && /^</.test(trimmedUrl)) {
// commonmark requires matching angle brackets
if (!(/>$/.test(trimmedUrl))) {
return;
}
// ending angle bracket cannot be escaped
const rtrimSlash = rtrim(trimmedUrl.slice(0, -1), '\\');
if ((trimmedUrl.length - rtrimSlash.length) % 2 === 0) {
return;
}
} else {
// find closing parenthesis
// 原先为 const lastParenIndex = findClosingBracket(cap[2], '()')
const lastParenIndex = findClosingBracket(cap[3], '()');
if (lastParenIndex > -1) {
const start = cap[0].indexOf('!') === 0 ? 5 : 4;
const linkLen = start + cap[1].length + lastParenIndex;
// 原先为 cap[2] = cap[2].substring(0, lastParenIndex);
cap[3] = cap[3].substring(0, lastParenIndex);
cap[0] = cap[0].substring(0, linkLen).trim();
cap[4] = ''; // 原先为 cap[3] = '';
}
}
let href = cap[3]; // 原先为 let href = cap[2];
let title = '';
if (this.options.pedantic) {
// split pedantic href and title
const link = /^([^'"]*[^\s])\s+(['"])(.*)\2/.exec(href);
if (link) {
href = link[1];
title = link[3];
}
} else {
// 原先为 title = cap[3] ? cap[3].slice(1, -1) : '';
title = cap[4] ? cap[4].slice(1, -1) : '';
}
href = href.trim();
if (/^</.test(href)) {
if (this.options.pedantic && !(/>$/.test(trimmedUrl))) {
// pedantic allows starting angle bracket without ending angle bracket
href = href.slice(1);
} else {
href = href.slice(1, -1);
}
}
return outputLink(cap, {
href: href ? href.replace(this.rules.inline._escapes, '$1') : href,
title: title ? title.replace(this.rules.inline._escapes, '$1') : title
}, cap[0]);
}
}
第二种方式中修改的其他地方的代码就不要再继续动了,保持在第二种方式中的修改即可。
到此终极大招放完了。使用命令编译生成 marked.min.js 文件就行了。
在前端页面中使用Markdown并且优化a标签的更多相关文章
- 在前端页面中使用@font-face来显示web自定义字体【转】
本文转自W3CPLUS 的<CSS @font-face> @font-face是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中,随着@font-face模块的出现, ...
- 使用原生ajax访问后台数据并将其展现在前端页面中(小菜鸟自己整理玩的,大神勿喷)
首先你要有php的环境,关于php环境的搭建,php本地站点的搭建,此处不再重复请看这里:http://www.cnblogs.com/Gabriel-Wei/p/5950465.html我们把wam ...
- 页面中的CSS性能优化
大型网站中会有多个CSS文件,性能优化是不要的.主要有以下几个方法: 一:压缩样式表: 通过构建工具压缩CSS文件,能够减少文件的大小,从而得到更快的下载.解析和执行.对于使用预处理器例如 Sass, ...
- web前端页面中异步使用百度地图API
<div id="allmap"></div> //百度地图API功能 function loadJScript() { var script = docu ...
- 前端页面中:jsp和HTML的区别之处
JSP和HTML的区别 HTML页面是静态页面,也就是事先由用户写好放在服务器上,固定内容,不会变,由web服务器向客户端发送,平时上网看的网页都是大部分都是基于html语言的. JSP页面是有JSP ...
- 前端页面中如何在窗口缩放时让两个div始终在同一行显示
直接贴代码吧 先总结一下吧 有两种方法 一 最外层设置一个大div 给这个大div固定的宽度和高度 给里面两个小div 设置浮动 设置宽高 <!DOCTYPE html> &l ...
- 怎样获取页面中所有带href属性的标签集合
使用: document.links document.links instanceof HTMLCollection; 注意: 1. a 标签和 area 标签可以设置 href属性, 因此可以被获 ...
- 新技能GET!在前端表格中花式使用异步函数的奥义
背景 60年代时,操作系统中独立运行的单元通常是进程.但随着计算机技术的发展,人们发现在进程运行过程中,创建.撤销与切换都要花费较大的时空开销. 到了80年代为了解决这一问题,出现了更小的独立运行基本 ...
- Python Django CMDB项目实战之-2创建APP、建模(models.py)、数据库同步、高级URL、前端页面展示数据库中数据
基于之前的项目代码来编写 Python Django CMDB项目实战之-1如何开启一个Django-并设置base页index页文章页面 现在我们修改一个文章列表是从数据库中获取数据, 下面我们就需 ...
随机推荐
- PCB设计中新手和老手都适用的七个基本技巧和策略
本文将讨论新手和老手都适用的七个基本(而且重要的)技巧和策略.只要在设计过程中对这些技巧多加注意,就能减少设计回炉次数.设计时间和总体诊断难点. 技巧一:注重研究制造方法和代工厂化学处理过程 在这个无 ...
- Codeforces Round #747 (Div. 2)题解
谢天谢地,还好没掉分,还加了8分,(8分再小也是加啊)前期刚开始有点卡,不过在尽力的调整状态之后,还是顺利的将前面的水题过完了,剩下的E2和F题就过不去了,估计是能力问题,自己还是得认真补题啦. E2 ...
- uni-app(Vue)中(picker)用联动(关联)选择以至于完成某些功能
如下图所示,在项目中需求是通过首先选择学生的专业,选好之后在每个专业下面选择对应的学期,每个学期有对应的学费,因此就需要联动选择来实现这一功能. 以下仅展示此功能主要代码: <div class ...
- java性能优化常用工具jps、jstat、jinfo
jps:虚拟机进程状况工具 jps可以用来查看虚拟机进程,基本等同于ps -ef|grep java #查看jps的使用文档 [root@localhost script]# jps -help us ...
- ESXi 6.7 的https服务挂掉处理方法 503 Service Unavailable
首先进入EXSi开启SSH(ESXi的主机控制台,非web控制台,是安装esxi的控制台) 然后 /etc/init.d/hostd status 显示已停止, 使用 /etc/init.d/host ...
- httprunner3源码解读(2)models.py
源码目录结构 我们首先来看下models.py的代码结构 我们可以看到这个模块中定义了12个属性和22个模型类,我们依次来看 属性源码分析 import os from enum import Enu ...
- 消息队列手动确认Ack
以RabbitMQ为例,默认情况下 RabbitMQ 是自动ACK机制,就意味着 MQ 会在消息发送完毕后,自动帮我们去ACK,然后删除消息的信息.这样依赖就存在这样一个问题:如果消费者处理消息需要较 ...
- [JS]什么是闭包?
首先来思考一下下面的案例: function unclosure() { let count = 0 return count++ } for (let index = 0; index < 1 ...
- 【JAVA】编程(4)---摇色子
作业要求: 利用" Math.random ( ) "生成随机数的方法来模拟同时摇三个色子获得的点数:点数的多少不同,也会导致不同的输出结果:可适当对程序增添一些更有趣的功能: ...
- (十.7) JDBC(使用IDEA连接数据库)
写SQL语句: 调出mysqlconsole alt + 8 ok,完毕.