mysql数据查询语言DQL
DB(database)数据库:存储数据的'仓库',保存了一系列有组织的数据
DBMS(Database Management System)数据库管理系统:用于创建或管理DB
SQL(Structure Query Language):结构化查询语言,专门用来与数据库通信的语言
数据库的特点
1.将数据放入表中,表再放到库中
2.一个数据库中可以有多个表,每个表都有唯一的名字
3.表具有一些特性,这些特性定义了数据在表中如何存储,类似java中"类"的设计
4.表由列组成,称为字段。类似java中的属性
5.表中的数据按行存储,每一行类似于java中的"对象"
Mysql服务端的基本操作
查看Mysql版本号
cmd下:mysql --version (dos命令) / mysql -V
mysql语句: select version();
Mysql服务的启动与停止
方式一:计算机管理 - 服务与应用程序 - 服务 - 找到Mysql右击启动/停止
方式二:命令行cmd,管理员身份进入
停止: net stop mysql(服务名)
开启: net start mysql(我的服务名是mysql)
Mysql服务端的登录与退出
登录前必须保证服务是启动的
[]连接本机和端口为3366时可以省略
登录:mysql [-h 主机名] [-P 端口号] -u 用户名 -p(密码可以回车输入,也可以不加空格写在这后面)
退出:exit
Mysql的常用命令
每条命令的结尾加上分号
查看数据库:shwo databases;
进入数据库:use test;
查看当前库里的表:show tables;
查看其他库的表:show tables from 数据库名;
创建表:create table 表名(字段名 字段类型,字段名 字段类型));
查看表的结构:desc 表名
查看表里的数据:select * from 表名
shwo databases;
use sys;
show tables from mysql;#此时在test库里查看mysql库里的表
select database(); #查看当前的所在的库 sys
create table stuinfo(
-> id int,
-> name varchar(20));
desc stuinfo;
insert into stuinfo(id,name) values(1,'john');#插入数据
select * from stuinfo;
update stuinfo set name='' where id=1;#修改名字
delete from stuinfo where id=1;
插入已有的sql脚本
用户右键 - 执行SQL脚本
MySQL的语法规范
1.不区分大小写,但建议关键字大写,其他小写。
2.每条命令用分号结尾
3.每条命令根据需要,可以进行缩进或换行
4.注释 单行注释:# 或 --空格 多行注释/注释文字/
DQL数据查询语言(Data Query Language)
做笔记用的练习数据库的信息
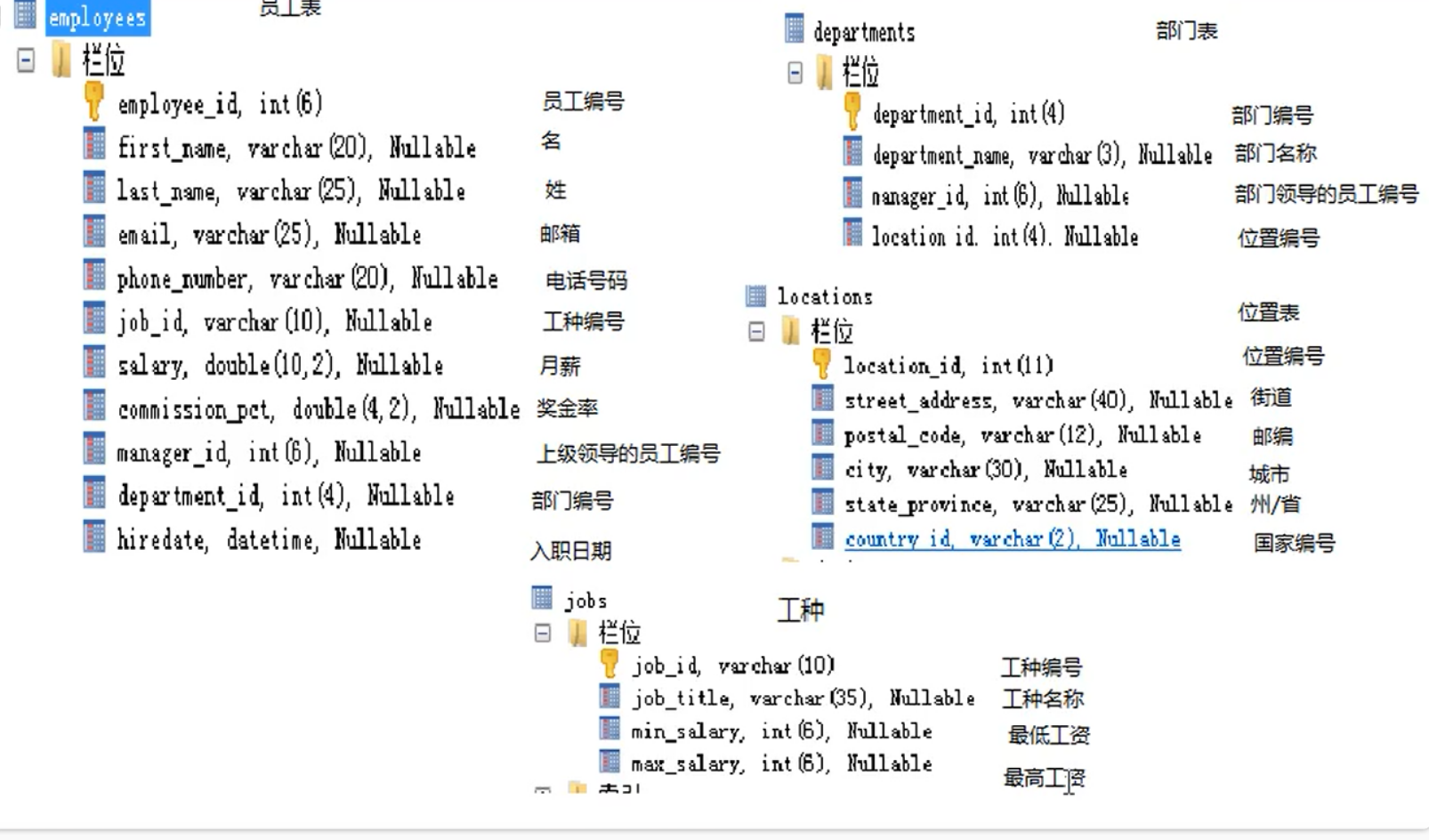
commission_pct可能为NULL
引号:
1.单引号包裹字符
2.当别名识别不出来的时,加上双引号
基础查询
语法:select 查询列表 from 表名;
查询列表:表中的字段、常量值、表达式、函数 -> 字段名默认值为查询列表
查询的结果是一个虚拟的表格
补充说明
1.``着重号,当字段被识别成关键字时可以使用
2.起别名的好处①便于理解②区分重名情况。
3.当别名识别不出来的时,加上双引号(特殊情况)
4.mysql中的+号只作运算符
如果其中一个为字符型,字符型->数值型,成功做加运算,失败则将字符串转换为0。
如果一方为null,则结果为null
# 基础查询
USE myemployees;
# 1.查询表中的单个字段
SELECT last_name FROM employees;
# 2.查询表中的多个字段
SELECT last_name,salary,email FROM employees;
# 3.查询表中的所有字段
# 方式一:使用*输出的顺序和原始表的顺序一样
SELECT * FROM employees;
# 方式二:可以自定义顺序
SELECT
`first_name`,
`last_name`,
`email`,
`phone_number`,
`manager_id`,
`salary`,
`job_id`,
`department_id`,
`hiredate`,
`commission_pct`
FROM
employees;
# 字段名默认值为查询列表,如100+5、VERSION()
# 4.查询常量值:单引号
SELECT 'join';
# 5.查询表达式:employees有多少行,就输出多少行
SELECT 100+5 from employees;
# 6.查询函数:值为返回值.执行函数查询返回值
SELECT VERSION();
# 字段名起别名
# 方式1 as
SELECT 100%98 AS 结果;
# 方式2: 使用空格
SELECT 100%98 结果;
# 特殊情况:当别名识别不出来的时,加上双引号
SELECT 100%98 AS "out put";
案例
1.去重:关键字DISTINCT
2.拼接字符串:函数concat(参数列表)
3.判断是否为null,设置默认值: 函数ifnull(表达式,为null之后的返回值)
4.判断是否为nul:isnull(一个参数),返回函数结果1真0假
# 查询员工表中涉及到的所有部门编号
SELECT DISTINCT department_id FROM employees;
# 查询员工名和姓连接成一个字段,并显示为姓名
SELECT CONCAT(last_name,first_name) AS 姓名 FROM employees;
SELECT CONCAT(last_name,",",first_name,",",IFNULL(commission_pct,0)) AS out_put FROM employees;
条件查询
语法:select 查询列表 from 表名 where 筛选条件;
说明:先定位到表,在筛选条件,最后执行查询语句。
分类
1.按条件表达式筛选(> < = !=/<> >= <=)
2.按逻辑表达式筛选(&&/and ||/or !/not)
3.模糊查询(like, between and, in, is null)
like
说明
1.一般和通配符搭配使用,
2.通配符:
%代表零个或多个字符
_任意单个字符
3.ESCAPE关键字 自定义转移符
4.可以判断数值型和字符型,都写在引号里
# 模糊查询
# 1.查询员工名中包含字符a(模糊条件)的员工信息
SELECT * FROM employees WHERE last_name LIKE '%a%';
# 2.查询员工名中第三个字符为e,第五个字符为a的员工名和工资
SELECT last_name,salary
FROM employees
WHERE last_name LIKE '__e_a%';
# 3.查询员工名中第二个字符为_的员工名
# 方法一:\转义字符
# 方法二:ESCAPE关键字 自定义转移符
SELECT last_name
FROM employees
# where last_name like '_\_%'、
WHERE last_name LIKE '_$_%' ESCAPE 'S';
between and
betwenn相当于>= and相当于<=
注意事项
1.包含临界值
2.顺序不能乱
# 查询员工编号在100到120之间的员工信息
SELECT * FROM employees WHERE employee_id BETWEEN 100 AND 120;
in()
in相当于等于
含义:判断某字段的值是否属于in列表中的某一项
特点:
1.in列表的值类型必须一致或兼容
2.不支持通配符
# 查询员工的工种编号 IT_PROG,AD_VP,AD_PRES中的一个员工名和工种编号
SELECT last_name,job_id
FROM employees
# where job_id = 'IT_PROG' or job_id ='AD_VP' or job_id ='AD_PRES';
WHERE job_id IN('IT_PROG' , 'AD_VP' , 'AD_PRES');
is null
| 类型 | 普通类型的数值 | null型 |
|---|---|---|
| 赋值 = != | √ | × |
| 关键字 is | × | √ |
| 安全等于 <=> | √ | √ |
# 模糊查询
# 查询没有奖金的员工名和奖金率
SELECT last_name ,commission_pct
FROM employees
# where commission_pct is NOT null ;
WHERE commission_pct IS NULL ;
# WHERE commission_pct<=> NULL;
习题
以下两种结果是一样的吗?
如果判断的字段有null值则不一样,commission_pct可以为null,所以结果不一样
SELECT * FROM employees;
SELECT * FROM employees WHERE commission_pct LIKE '%%' AND last_name LIKE '%%';
# 补充:以下情况是一样的
SELECT * FROM employees WHERE commission_pct LIKE '%%' OR last_name LIKE '%%';
排序查询
语法:select 查询列表 from 表 [where 筛选条件] order by 排序列表 [asc|desc]
说明:
1.asc代表升序,desc代表降序,默认是升序
2.order by 后可以跟表达式、别名、函数
3.支持多个字段排序,先按第一个排,第一个相同按第二个排
4.order by 子句一般放在查询语句最后。limit子句除外
5.执行顺序先from表再where再select查询最后order by
# 查询员工信息,要求工资从高到低排序
SELECT * FROM employees ORDER BY salary DESC;
# 查询员工信息,先按工资排序再按员工编号排序[按多个字段排序]
SELECT * FROM employees ORDER BY salary ASC,employee_id DESC;
常见函数
概念:将一组逻辑语句封装在方法体中,对外暴露方法名
调用: selsect 函数名() [from 表] 函数中的参数使用到了表中属性时需要添加
分类
- 单行函数 对于每一行数据进行计算后得到一行输出结果
- 字符函数
- 数学函数
- 日期函数
- 其他函数
- 流程控制函数
- 分组函数 做统计使用,有称为统计函数、聚合函数,一组数据输出一个结果
单行函数
字符函数
length(str):获取参数值的字节个数,如果是数字会自动添加''
concat(参数列表):拼接字符串
upper(str)/lower(str):将字符转换成大小写
substr/substring(参数列表):截取字符,mysql中索引从1开始
instr(str,substr):返回子串在str中第一次出现的起始索引,没有就返回0
trim('去除的字符' from '字符串'):去除前后的字符,默认去空格
lpad/rpad(str,总长度,填充字符): 根据总长度进行填充与截取。当str不足总长度用填充符号左/右填充,超了则截取
replace(str,from_str,to_str):把str中的所有from_str替换成to_str
# concat(参数列表)
SELECT CONCAT(last_name,'_',first_name) FROM employees;
# substr/substring(str,pos) 从pos位置(包含)开始截取str(光标左开始) 输出 冉ranan
SELECT SUBSTR('冉冉ranan',2) 结果;
# substr/substring(str,pos,length) 从1开始截取长度2 输出 ra
SELECT SUBSTR('ranan',1,2) 结果;
# instr(str,substr) 输出 2
SELECT INSTR('ranran','an');
# trim 规定去掉前后的a 输出 xxxaaxxx
SELECT TRIM('a' FROM 'aaaxxxxaaxxxaaaa');
# lpad:根据总个数进行填充与截取 输出 ***xxxr
SELECT LPAD('xxxr',7,'*');
# repalce 替换 输出 ccccxxxxrancc
SELECT REPLACE("ababxxxxranab",'ab','cc');
日期函数
now() 返回当前系统日期 + 时间
curdate() 返回当前系统日期
curtime() 返回当前的时间
year/month/monthname/day/hour(data/1998-1-1) 获取指定data的年份、月份...
str_to_date():将日期格式的字符串转换成指定格式的日期
date_format():将日期转换成字符串
相差天数 datediff(日期1,日期2),日期1-日期2
# 2019-09-13
SELECT STR_TO_DATE('9-13-1999','%m-%d-%y');
# %Y四位数年份 %y2位数年份 %m月份01 %c月份1 %d日 %H24小时 %h12小时 %i分钟 %s秒
# 2018年06月06日
SELECT date_format('2018/6/6','%Y年%m月%d日')
数学函数
round() 四舍五入
ceil(x) 向上取整,返回>=该参数的最小整数
floor(x) 向下取整,返回<=该参数的最大整数
truncate() 截断,小数点后保留几位
mod(a,b) 取余 a%b(a-a/b*b),被除数符号与结果符号相同
rand 获取随机数,返回0-1之间的小数
# round()负数先绝对值四舍五入再加负号
SELECT ROUND(1.33); # 默认往整数四舍五入,结果1
SELECT ROUND(1.33,2); # 小数点后保留几位 1.33
# ceil(x) 向上取整
SELECT CEIL(-1.001);; # 结果-1
SELECT CEIL(1.001); # 结果2
# truncate 截断
SELECT TRUNCATE(1.65,1) # 输出1.6
其他函数
version() 版本号
database() 当前库
user() 当前用户
password(str) 给str加密
md5(str) 返回该str的md5形式
流程控制函数
格式:if(表达式,成立执行,不成立执行)
case函数的使用一:swich case -> 适用于等值判断
格式:case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1 (;是语句时添加)
when 常量2 then 要显示的值2或语句2 (;是语句时添加)
else 默认情况
end
注意:
case做表达式时,then后是显示的值
case做语句时,then后是语句
case函数的使用二:类似于多重if -> 使用于不等式的判断
case
when 条件1 then 满足条件1要显示的值1或语句1(;是语句时添加)
when 条件2 then 满足条件2要显示的值2或语句2(;是语句时添加)
else 要显示的值n或语句n
end
/* 查询员工的工资
部门号 = 30,显示的工资为1.1
部门号 = 40,显示的工资为1.2
部门号 = 50,显示的工资为1.3
其他部门,为原工资
*/
SELECT salary * CASE department_id
WHEN 30 THEN 1.1
WHEN 40 THEN 1.2
WHEN 50 THEN 1.3
ELSE 1
END AS 工资
FROM employees;
SELECT salary 原始工资,department_id,
CASE department_id
WHEN 30 THEN 1.1 * salary
WHEN 40 THEN 1.2 * salary
WHEN 50 THEN 1.3 * salary
ELSE 1 * salary
END AS 工资
FROM employees;
/* 查询员工的工资情况
如果工资>20000,显示A级别
如果工资>15000,显示B级别
如果工资>10000,显示C级别
否则显示D级别
*/
SELECT salary ,CASE
WHEN salary>20000 THEN 'A'
WHEN salary>15000 THEN 'B'
WHEN salary>10000 THEN 'C'
ELSE 'D'
END AS 工资情况
FROM employees;
多行函数
说明:做统计使用,有称为统计函数、聚合函数,一组数据输出一个结果
sum 求和、avg 平均值、max 最大值、min 最小值、count 计算非null个数
注意:
1.参数支持类型 sum/avg 数值型 max/min/count 任何类型
2.以上分组函数都忽略null值
3.可以和distinct搭配使用实现去重
4.COUNT(*)常用于统计行数
5.和分组函数一同查询的字段要求是本表中group by后的字段 - 结果要求是规整的表格
# 去重之后再求和
SELECT SUM(DISTINCT salary) FROM employees;
# 保留2位,一般后面跟数字就是保留小数点后几位
SELECT AVG(salary,2) FROM employees;
# 统计非空行数
SELECT COUNT(*) FROM employees;
# 相当于多了列,一列全部是常数值,统计非空行数
SELECT COUNT(1/常数值) FROM employees;
SELECT DATEDIFF('2017-10-1','2017-9-29') # 2 (9.30 10.1)
分组查询
语法
SElECT 分组之后执行的函数,列(要求出现在group by的后面,分组条件,不需要显示就不写)
FROM table
[where condition]
[group by group_by_expression]
[order by 子句];
注意:
1.where一定放在from后面 -- 执行顺序先from再where再select查询构成基础查询,基础查询后面进行其他约束
2.查询列表特殊,要求是分组之后执行的函数和group by后面出现的字段(根据什么分组/每组条件)
有条件的分组
1.先筛选后分组
原始表中就能找到筛选的条件
2.先分组后筛选
原始表中找不到筛选的条件,分组后才能找到筛选的条件。筛选条件的关键词用having(理解为分组后是否有某个条件的行)
说明
1.分组之后执行的函数作为筛选条件,肯定是放在having后面
2.能先筛选的就先筛选
先筛选后分组
原始表中就能找到筛选的条件
# 案例1:查询每个工种的最高工资 分组条件每个工种
SELECT MAX(salary),job_id
FROM employees
GROUP BY job_id;
# 先筛选再分组 - 此时筛选的字段在from表里
/*
案例1.查询邮箱中包含a字符的,每个部门的平均工资
分组条件每个部门
*/
SELECT AVG(salary),department_id
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;
/*
案例2:查询有奖金的每个领导手下员工的最高工资 分组条件每个领导
*/
SELECT MAX(salary),manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
先分组后筛选
原始表中找不到筛选的条件,分组后才能找到筛选的条件。筛选条件的关键词用having(理解为分组后是否有某个条件的行)
# 先分组在筛选
/*
案例:查询哪个部门的员工个数>2
1.查询每个部门的员工个数
2.筛选>2的部门
*/
SELECT COUNT(*),department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>2;
/*
案例:查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
1.查询每个工种有奖金的员工的最高工资
2.最高工资>12000
*/
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING 最高工资>12000;
# 按表达式或者是函数分组
/*
案例:按员工姓名的长度分组,查询每组的员工个数,筛选员工个数>5的
*/
SELECT COUNT(*) 员工个数,LENGTH(last_name) 姓名长度
FROM employees
GROUP BY 姓名长度
HAVING 员工个数>5;
按多个字段分组
多个字段之间用逗号隔开并没有顺序要求
/*
案例:查询每个部门(不为null)每个工种的员工的平均工资,并按平均工资的高低显示
*/
SELECT AVG(salary) 平均工资,department_id,job_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id,job_id
ORDER BY 平均工资 DESC;
连接查询/多表查询
说明:
1.用于查询的字段来自于多个表
2.通常使用sql99标准
按功能分类
- 内连接
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接
- 右外连接
- 全外连接(mysql不支持)
- 交叉连接
sql92标准
等值连接
实现原理:用第一张的表的一行去匹配第二张表的每一行,匹配成功则留下来
说明:where后面添加连接条件
特点:
1.多表等值连接的结果为多表的交集部分
2.多表的顺序没有要求,一般为表起别名
注意:
1.先走from,起了别名后就不认识原表名了,所以就不能使用原表名去限定
2.有筛选条件就在where后面添加and
/*
案例1:查询员工名、工种号、工种名
*/
SELECT last_name,e.`job_id`,job_title # 这里的job_id有歧义,需要表来限定
FROM employees e,jobs j # 当多次使用表名限定时,可以给表起别名
WHERE e.`job_id` = j.`job_id`;
# 有筛选条件使用and
/*
案例2.查询有奖金的员工名,部门名
*/
SELECT last_name,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`
AND commission_pct IS NOT NULL;
# 添加分组
/*
案例1:查询每个城市的部门个数
*/
SELECT COUNT(*) 个数,city
FROM departments d,locations l
WHERE d.`location_id` = l.`location_id`
GROUP BY city;
# 添加排序
/*
案例:查询每个工种的工种名和员工的个数,并按员工的个数降序
*/
SELECT job_title,COUNT(*) AS 员工个数
FROM employees e,jobs j
WHERE e.`job_id` = j.`job_id`
GROUP BY job_title
ORDER BY 员工个数 DESC;
非等值连接
where条件之后不是通过等于连接的
自连接
自连接相当与等值连接,区别在于等值连接是多表连接,自连接是单表自己连接自己。
/*
案例1:查询员工名和上级的名称 同一张表需要寻找两遍
第一遍找员工的领导编号是是多少,第二遍找这个编号对应的人是谁
*/
SELECT
e.employee_id 员工编号,
e.last_name 员工名,
m.employee_id 领导编号,
m.last_name 领导名
FROM
employees e,employees m
WHERE m.employee_id =e.manager_id;
sql99标准
语法
select 查询列表
from 表1 别名
[连接类型] join 表2 别名
on 连接条件
[where 筛选条件]
连接类型
内连接:inner
外连接
左外 left [outer]
右外 right [outer]
全外 full [outer]
交叉连接 cross
等值连接
inner可以省略
# 等值连接
/*
案例.查询部门个数>3的城市名和部门个数
*/
SELECT city,COUNT(*) 部门个数
FROM departments d
INNER JOIN locations l
ON d.`location_id`= l.`location_id`
GROUP BY city
HAVING 部门个数>3;
非等值连接
# 查询员工的工资级别
SELECT salary,grade_level
FROM employees e
JOIN job_grades g
ON e.salary BETWEEN g.lowest_sal AND highest_sal'
自连接
/*
案例1:查询员工名和上级的名称 同一张表需要寻找两遍
第一遍找员工的领导编号是是多少,第二遍找这个编号对应的人是谁
*/
SELECT
e.employee_id 员工编号,
e.last_name 员工名,
m.employee_id 领导编号,
m.last_name 领导名
FROM
employees e
INNER JOIN
employees m
ON m.employee_id =e.manager_id;
外连接
应用场景:内连接连接的是交集部分;外连接用于查询一个表中有,另外一个表没有的记录。
说明
1.有主从表之分,主表会全部显示出来
2.左外连接 左边的是主表、右外连接 右边的是主表
3.全外不分主从表 = 内连接的结果 + 表1中2没有的 + 表2中有1没有的
/*
案例1.查询哪个部门没有员工
*/
SELECT department_name
FROM departments d
LEFT JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE employee_id IS NULL;
交叉连接
表1 4行 表2 11行 结果 44行
表1一行对应表2 11行 - 笛卡尔连接、
子查询
说明:出现在其他语句中的select语句,称为子查询或内查询,一般放在小括号里。
# select后面 相关子查询
# 仅支持标量子查询 结果集只有一行一列
# from 后面
# 表子查询 一般为多行多列
# where或having后面 ★
# 标量子查询(单行) √
# 列子查询(多行) 结果集只有一列多行 √
# 行子查询 较少 结果集有一行多列
# exists后面(相关子查询)
# 表子查询 一般为多行多列
where或having后面
标量子查询-单行子查询 列子查询-多行子查询
特点:
1.标量子查询,一般搭配单行操作符使用(> <...)
2.列子查询,一般单配多行操作符使用(in,any/some,all)
IN/NOT IN 等于列表中的任意一个
ANY/SOME 和子查询返回的某一个值比较
ALL 和子查询返回的所有值比较
3.子查询的执行先于主查询
# 标量子查询
/*
案例1:谁的工资比Abel高
*/
#①查询Abel的工资 ②查询员工的信息,满足salary>①
SELECT *
FROM employees
WHERE salary>( # 括号里返回的一行一列
SELECT salary
FROM employees
WHERE last_name='Abel'
);
/*
案例2:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
*/
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = ( # 括号里返回的一行一列
SELECT job_id
FROM employees
WHERE employee_id=141
) AND salary > ( # 括号里返回的一行一列
SELECT salary
FROM employees
WHERE employee_id=143
)
# 列子查询
/*
案例1.返回其他部门中比job_id为it_prog部门任一工资低的员工的员工号、姓名、job_id以及salary
*/
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id<>'iT_PROG'
AND salary < ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
# 行子查询(结果集一行多列或多行多列)
/*
查询员工编号最小并且工资最高的员工信息
*/
SELECT *
FROM employees
WHERE employee_id=(
SELECT MIN(employee_id)
FROM employees
)
AND salary = (
SELECT MAX(salary)
FROM employees
);
# 需要筛选条件都是相同的,可以用行查询代替
SELECT *
FROM employees
WHERE (employee_id,salary) = (
SELECT MIN(employee_id),MAX(salary)
FROM employees
)
select后面
不常用,仅仅支持标量子查询
/*
案例1:查询员工号=102的部门号
*/
SELECT(
SELECT department_name
FROM departments d
INNER JOIN employees e
ON d.department_id = e.department_id
WHERE e.employee_id=102
);
/*
案例2:查询每个部门的员工个数
*/
SELECT d.*,
(
SELECT COUNT(*)
FROM employees e
WHERE d.`department_id` = e.`department_id`
) 个数
FROM departments d; # d表中department_id的个数更多
from后面
一般from后面接着表,所以相当于将子查询的结果集充当表格使用。
要求该表必须其别名
/*
案例:查询每个部门的平均工资的工资等级
*/
#①查询每个部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#②连接①的结果和job_grades进行等级匹配
SELECT dep.*,g.grade_level
FROM( # 这个表一定要起别名,不然找不到
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) dep
INNER JOIN job_grades g
ON dep.ag BETWEEN lowest_sal ANG highest_sal;
exists后面(相关子查询)
语法:exists(完整的查询语句)
结果:1或者0
一般可以使用exists的都可以使用IN使用,所以使用频率不高
/*
案例:查询有员工的部门名
*/
# 先执行外查询,通过子查询过滤
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.`department_id` = e.`department_id`
);
# IN
SELECT department_name
FROM departments d
WHERE d.`department_id` IN(
SELECT department_id
FROM employees
)
分页查询
使用场景:当需要显示的数据,一页显示不全,需要分页提交sql请求
语法:
select 查询列表
from 表
limit [offset要显示条目的起始索引(从0开始)],size显示的条目个数
注意:
1.limit需要放在最后,执行的顺序也是最后执行
2.要显示的页数page,每页的条目数size limit size*(page-1),size
/*
案例1:查询前五条员工信息
*/
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5; # 从第一条开始可以省略
/*
案例2:有奖金的员工信息,并且工资较高的前10名显示出来
*/
SELECT * FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10;
执行顺序
中途每步都会生成虚拟表
1.from
2.join-on
3.where
4.group-by
5.having
6.select
7.order-by
8.limit
习题
/*
查询平均工资最高的job信息
*/
# ①查询平均最高工资
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC
LIMIT 1
# ②查询job信息
SELECT j.*
FROM jobs j
WHERE j.job_id = (
SELECT e.job_id
FROM employees e
GROUP BY e.job_id
ORDER BY AVG(salary) DESC
LIMIT 1
)
/*
查询平均工资高于公司平均工资的部门有哪些
*/
# 1.查询公司的平均工资
SELECT AVG(salary)
FROM employees
# 2.查询平均工资高于公司平均工资的部门id
SELECT AVG(salary) 部门平均工资,department_id
FROM employees
GROUP BY department_id
HAVING 部门平均工资>(
SELECT AVG(salary)
FROM employees
)
union联合查询
说明:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
....
使用场景:要查询的结果来自多个表,且多个表没有直接的连接关系,查询的信息顺序需要一样
注意:
union 会去重,需要全部显示使用union all
/*
查询部门编号>90或邮箱包含a的员工信息
*/
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id > 90;
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id > 90;
mysql数据查询语言DQL的更多相关文章
- MySQL数据库笔记三:数据查询语言(DQL)与事务控制语言(TCL)
五.数据查询语言(DQL) (重中之重) 完整语法格式: select 表达式1|字段,.... [from 表名 where 条件] [group by 列名] [having 条件] [order ...
- MySQL之数据查询语言(DQL)
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块: SELECT <字段> FROM <表名> WHERE <查询条件> - ...
- 数据查询语言DQL 与 内置函数(聚合函数)
数据查询语言DQL 从表中获取符合条件的数据 select select*from表的名字 查询表所有的数据.(select跟from必须一块用 成对出现的) * 表示所有字段,可以换成想要查询的 ...
- 学习资料 数据查询语言DQL
数据查询语言DQL介绍及其应用: 查询是SQL语言的核心,SQL语言只提供唯一一个用于数据库查询的语句,即SELECT语句.用于表达SQL查询的SELECT语句是功能最强也是最复杂的SQL语句,它提供 ...
- MySQL — 数据查询语言
目录 1.基础查询 2.条件查询 3.分组查询 4.排序查询 5.分页查询 6.多表查询 6.1.连接查询 6.1.1.内连接 6.1.2.外连接 6.1.3.自连接 6.1.4.联合查询 6.2.子 ...
- (七)MySQL数据操作DQL:单表查询1
(1)单表查询 1)环境准备 mysql> CREATE TABLE company.employee5( id int primary key AUTO_INCREMENT not null, ...
- (七)MySQL数据操作DQL:多表查询2
(1)准备环境 1)创建员工表 mysql> create table company.employee6( -> emp_id int auto_increment primary ke ...
- 30443数据查询语言DQL
5.4 SQL的数据查询功能 数据查询是数据库最常用的功能.在关系数据库中,查询操作是由SELECT语句来完成.其语法格式如下: SELECT column_expression FROM table ...
- Mysql基础3-数据操作语言DML-数据查询语言DQL
主要: 数据操作语言DML 数据查询语言DQL 数据操作语言DML DML: Data Mutipulation Language 插入数据(增) 一般插入数据形式 1)形式1: insert [in ...
随机推荐
- 替换空格 牛客网 剑指Offer
替换空格 牛客网 剑指Offer 题目描述 请实现一个函数,将一个字符串中的每个空格替换成"%20".例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20A ...
- binary-tree-maximum-path-sum leetcode C++
Given a binary tree, find the maximum path sum. The path may start and end at any node in the tree. ...
- JAVA笔记1__基本数据类型/输入输出/随机数/数组
/**八种基本数据类型 boolean byte short int long char float double */ public class test1{ public static void ...
- (二)lamp环境搭建之编译安装mysql
mysql 编译安装1,在网站上下载: wget http://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.15.tar.gz 2,安装cmake ...
- JavaScript 对象:String & Array 及其常见应用
String对象 split 功能:把字符串分割为字符串数组.官方文档已经描述的够清楚,不多赘述.主要说一下需要注意的情况以及应用 1.省略分割参数 var str="How are you ...
- Solon & Solon Cloud 1.5.62 发布,轻量级 Java 基础开发框架
Solon 已有120个生态扩展插件,此次更新主要为细节打磨,且对k8s和docker-compose更友好: 1.插件 solon.coud ,事件总线增加支持本地同主题多订阅模式(以支持同服务内, ...
- string类运用:特殊的翻译
特殊的翻译 小明的工作是对一串英语字符进行特殊的翻译:当出现连续且相同的小写字母时,须替换成该字母的大写形式,在大写字母的后面紧跟该小写字母此次连续出现的个数:与此同时,把连续的小写字母串的左侧和右侧 ...
- Python 操作 Redis 发布订阅
Python 操作 Redis 发布订阅 介绍 Redis可以通过多个客户机订阅相同的频道,一个服务机在相应频道进行发布,从而实现在客户机收听服务机发布相应信息,可以利用这个机制实现多个客户机之间的信 ...
- RabbitMQ 处理过慢,原来是一个 SQL 缓存框架导致的 GC 频繁触发
一:背景 1. 讲故事 上个月底,有位朋友微信找到我,说他的程序 多线程处理 RabbitMQ 时过慢,帮忙分析下什么原因,截图如下: 这问题抛出来,有点懵逼,没说CPU爆高,也没说内存泄漏,也没说程 ...
- Mastering-VSCode
中英文等宽 14寸1920x1080, Win10, 设置如下(前两个字体就够了), 字号14,16都可以. 需要下载UbuntuMono字体. 如果分表率低如14寸1366x768,可尝试 Inco ...