为什么使用 LSTM 训练速度远大于 SimpleRNN?
今天试验 TensorFlow 2.x , Keras 的 SimpleRNN 和 LSTM,发现同样的输入、同样的超参数设置、同样的参数规模,LSTM 的训练时长竟然远少于 SimpleRNN。
模型定义:
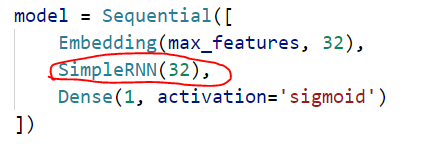
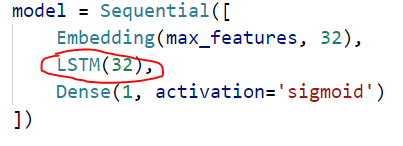
训练参数都这样传入:

我们知道,LSTM 是修正了的 SimpleRNN(我随意想出来的词,“修正”),或者说,是在 SimpleRNN 基础之上又添加了别的措施使模型能考虑到超长序列的标记之间的依赖。 缓解了梯度消失和梯度爆炸的问题。
所以,LSTM 比 SimpleRNN 是多了很多参数矩阵的,且每一步也多了一些计算。而训练过程既有前向,又有反向,不管哪个过程,理论上 LSTM都是比SimpleRNN要花更多时间的,那么为什么我在使用 TensorFlow with Keras 时会出现相反的情况呢?
训练情况(第一个 epoch):
SimpleRNN 的

LSTM的

原因,就在于:版本。
按住 Ctrl,点击两个类名 SimpleRNN 和 LSTM,进入定义的模块,会发现 from tensorflow.keras.layers import SimpleRNN 的 SimpleRNN定义所在的模块分别是这样的
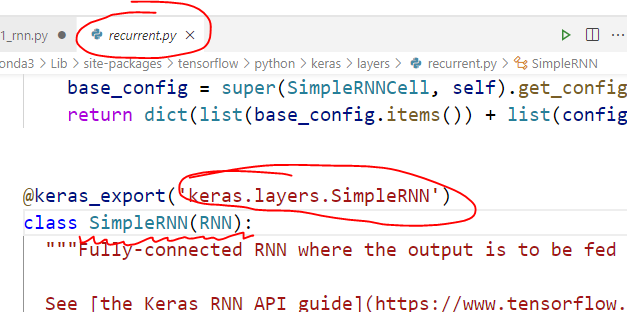
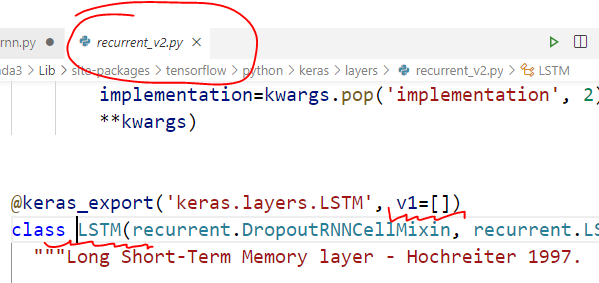
懂了,SimpleRNN 是 TensorFlow 1.xx 的东西,而这个 LSTM 是 TensorFlow 2.xx 的东西,肯定内部做了优化,反正二者一开始就不是一个起跑线上的东西。虽然我们写代码表面上都是from tensorflow.kears.layers 里 import 的,但是这种模块导入真的不能证明他们是放在同一个模块里定义的,因为导入是可以导来导去的,有的一个 import 就找到了它的定义,有的需要经过好几次 import 的传递,就像是个链,从我们的源文件一直到达最终定义的模块,这个 LSTM 隐藏的就很深(或者封装的很好(皮))。
要找到 这个 SimpleRNN 的 counterpart,就须使用 tensorflow.compat.v1.keras.layers.LSTM,找到它,发现
这就与上述 SimpleRNN 所在同一个模块了。
试验训练一下。

果然,比 SimpleRNN 慢得多,合理了。舒服了。
-------------------------------------------
我发现我真的好无聊,整天搞这些没用的。
抓主要矛盾,抓主要矛盾,主要矛盾!!!
下次一定 :)
为什么使用 LSTM 训练速度远大于 SimpleRNN?的更多相关文章
- 进程物理内存远大于Xmx的问题分析
问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值却达到了3.0G,随着进程的运行,R ...
- [转载]Java进程物理内存远大于Xmx的问题分析
进程物理内存远大于Xmx的问题分析 问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值 ...
- iGear 用了这个小魔法,模型训练速度提升 300%
一个高精度AI模型离不开大量的优质数据集,这些数据集往往由标注结果文件和海量的图片组成.在数据量比较大的情况下,模型训练周期也会相应加长.那么有什么加快训练速度的好方法呢? 壕气的老板第一时间想到的通 ...
- 实例演示 C# 中 Dictionary<Key, Value> 的检索速度远远大于 hobbyList.Where(c => c.UserId == user.Id)
前言 我们知道,有时候在一些项目中,为了性能,往往会一次性加载很多条记录来进行循环处理(备注:而非列表呈现).比如:从数据库中加载 10000 个用户,并且每个用户包含了 20 个“爱好”,在 Wi ...
- C++,1....n中随机等概率的输出m个不重复的数(假设n远大于m)。
#include <stdlib.h> #include <time.h> knuth(int n, int m) { srand((unsigned )); ; i < ...
- 高性能网络编程(一)----accept建立连接
编写服务器时,许多程序员习惯于使用高层次的组件.中间件(例如OO(面向对象)层层封装过的开源组件),相比于服务器的运行效率而言,他们更关注程序开发的效率,追求更快的完成项目功能点.希望应用代码完全不关 ...
- Linux Cache Mechanism Summary(undone)
目录 . 缓存机制简介 . 内核缓存机制 . 内存缓存机制 . 文件缓存机制 . 数据库缓存机制 1. 缓存机制简介 0x1: 什么是缓存cache 在计算机整个领域中,缓存(cache)这个词是一个 ...
- D. Powerful array 莫队算法或者说块状数组 其实都是有点优化的暴力
莫队算法就是优化的暴力算法.莫队算法是要把询问先按左端点属于的块排序,再按右端点排序.只是预先知道了所有的询问.可以合理的组织计算每个询问的顺序以此来降低复杂度. D. Powerful array ...
- 高性能网络编程1----accept建立连接
转 http://taohui.org.cn/tcpperf1.html 陶辉 taohui.org.cn 回到应用层,往往只需要调用类似于accept的API就可以建立TCP连接.建立连接的流程大 ...
随机推荐
- Azure Synapse Link for Dataverse
MyBuild - Scale, analyze and serve Microsoft Dynamics 365 application data with Azure 本周的微软Bulid大会上发 ...
- 最小生成树,Prim算法与Kruskal算法,408方向,思路与实现分析
最小生成树,Prim算法与Kruskal算法,408方向,思路与实现分析 最小生成树,老生常谈了,生活中也总会有各种各样的问题,在这里,我来带你一起分析一下这个算法的思路与实现的方式吧~~ 在考研中呢 ...
- Go语言流程控制02--选择结构之switch
package main import "fmt" /* @星座诊所2(switch) 根据用户输入的出生月份猜测其星座: ·白羊(4) 金牛(5) 双子(6) 巨蟹(7) 狮子( ...
- NVIDIA GPU上的直接线性求解器
NVIDIA GPU上的直接线性求解器 NVIDIA cuSOLVER库提供了密集且稀疏的直接线性求解器和本征求解器的集合,它们为计算机视觉,CFD,计算化学和线性优化应用程序提供了显着的加速.cuS ...
- 旷视MegEngine基本概念
旷视MegEngine基本概念 MegEngine 是基于计算图的深度神经网络学习框架. 本文简要介绍计算图及其相关基本概念,以及它们在 MegEngine 中的实现. 计算图(Computation ...
- 相机自动对焦AF原理
相机自动对焦AF原理 AF性能是判断相机好坏的重要指标,主要从准确度和速度两个方面来进行考察,本文将介绍自动对焦的几种方式. 一.凸透镜成像原理 二.三种对焦方法 有公式在手,只要给相机安个测距仪就好 ...
- 用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割 Accelerating Medical Image Segmentation with NVIDIA Tensor ...
- 女朋友看了也懂的Kafka(下篇)
前言: 在上篇中我们了解了Kafka是什么,为什么需要Kafka,以及Kafka的基本架构和各自的作用是什么,这篇文章中我们将从kafka内部每一个组成部分去看kafka 是如何保证数据的可靠性以及工 ...
- 尚硅谷Java——宋红康笔记【day1-day5】
day1 注释 1.java规范的三种注释方式: 单行注释 多行注释 文档注释(java特有) 2. 单行注释和多行注释的作用: ① 对所写的程序进行解释说明,增强可读性.方便自己,方便别人 ② 调试 ...
- 面试官:给我讲讲SpringBoot的依赖管理和自动配置?
1.前言 从Spring转到SpringBoot的xdm应该都有这个感受,以前整合Spring + MyBatis + SpringMVC我们需要写一大堆的配置文件,堪称配置文件地狱,我们还要在pom ...