MindSpore模型精度调优实战:常用的定位精度调试调优思路
摘要:在模型的开发过程中,精度达不到预期常常让人头疼。为了帮助用户解决模型调试调优的问题,我们为MindSpore量身定做了可视化调试调优组件:MindInsight。
本文分享自华为云社区《技术干货 | 模型优化精度、速度我全都要!MindSpore模型精度调优实战(二)》,原文作者:HWCloudAI 。
引言:
在模型的开发过程中,精度达不到预期常常让人头疼。为了帮助用户解决模型调试调优的问题,我们为MindSpore量身定做了可视化调试调优组件:MindInsight。我们还梳理了针对常见精度问题的调试调优指南,将以“MindSpore模型精度调优实战”系列文章的形式分享出来,希望能帮助用户轻松定位精度问题,快速优化模型精度。
回顾MindSpore模型精度调优实战系列点击跳转链接→技术干货 | 更快定位精度问题!MindSpore模型精度调优实战(一)。
本文是系列分享的第二篇,将给出常用的精度调试调优思路。本系列分享假设您的脚本已经能够运行并算出loss值。如果脚本还不能运行,请先参考相关报错提示进行修改。
遇到精度问题时,常用调试调优思路如下:
1. 检查代码和超参
2. 检查模型结构
3. 检查输入数据
4. 检查loss曲线
5. 检查精度是否达到预期
代码是精度问题的重要源头,检查代码重在对脚本和代码做检查,力争在源头发现问题(第2节);模型结构体现了MindSpore对代码的理解,检查模型结构重在检查MindSpore的理解和算法工程师的设计是否一致(第3节);有的问题要到动态的训练过程中才会发现,检查输入数据(第4节)和loss曲线(第5节)正是将代码和动态训练现象结合进行检查;检查精度是否达到预期则是对整体精度调优过程重新审视,并考虑调整超参、解释模型、优化算法等调优手段(第6节)。此外,熟悉模型和工具也是很重要的(第1节)。下面将分别介绍这些思路。
01精度调优准备
1.1 回顾算法设计,全面熟悉模型
精度调优前,要先对算法设计做回顾,确保算法设计明确。如果参考论文实现模型,则应回顾论文中的全部设计细节和超参选择情况;如果参考其它框架脚本实现模型,则应确保有一个唯一的、精度能够达标的标杆脚本;如果是新开发的算法,也应将重要的设计细节和超参选择明确出来。这些信息是后面检查脚本步骤的重要依据。
精度调优前,还要全面熟悉模型。只有熟悉了模型,才能准确理解MindInsight提供的信息,判断是否存在问题,查找问题源头。因此,花时间理解模型算法和结构、理解模型中算子的作用和参数的含义、理解模型所用优化器的特性等模型要素是很重要的。动手分析精度问题细节前,建议先带着问题加深对这些模型要素的了解。
前,要先对算法设计做回顾,确保算法设计明确。如果参考论文实现模型,则应回顾论文中的全部设计细节和超参选择情况;如果参考其它框架脚本实现模型,则应确保有一个唯一的、精度能够达标的标杆脚本;如果是新开发的算法,也应将重要的设计细节和超参选择明确出来。这些信息是后面检查脚本步骤的重要依据。
精度调优前,还要全面熟悉模型。只有熟悉了模型,才能准确理解MindInsight提供的信息,判断是否存在问题,查找问题源头。因此,花时间理解模型算法和结构、理解模型中算子的作用和参数的含义、理解模型所用优化器的特性等模型要素是很重要的。动手分析精度问题细节前,建议先带着问题加深对这些模型要素的了解。
1.2 熟悉工具
MindInsight功能丰富,建议用户简单阅读MindInsight教程(https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/visualization_tutorials.html),了解主要功能。定位精度问题时,建议使能summary训练信息收集功能,在脚本中加入SummaryCollector,并使用训练看板查看训练过程数据,如下图所示。Summary功能的使用指南请见 (https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/summary_record.html),训练可视功能的使用指南请见(https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/dashboard.html) 。
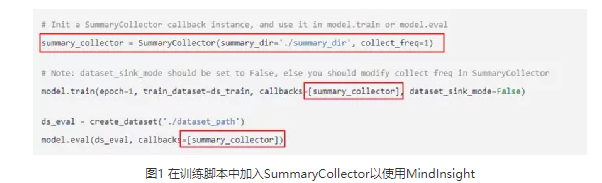
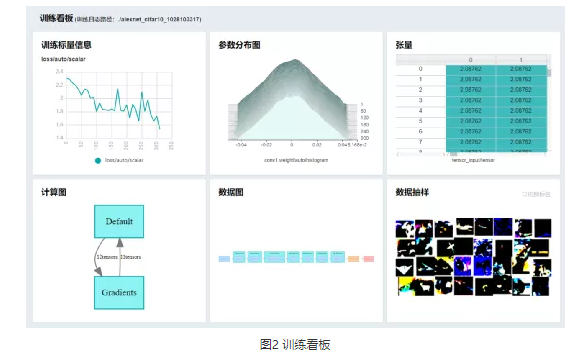
当您需要在线调试模型时,请参考此链接使能调试器功能:https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/debugger.html
02检查代码和超参
代码是精度问题的重要源头,超参问题、模型结构问题、数据问题、算法设计和实现问题会体现在脚本中,对脚本做检查是定位精度问题很有效率的手段。检查代码主要依赖代码走读,建议使用小黄鸭调试法:在代码走读的过程中,耐心地向没有经验的“小黄鸭”解释每一行代码的作用,从而激发灵感,发现代码问题。检查脚本时,要注意检查脚本实现(包括数据处理、模型结构、loss函数、优化器等实现)同设计是否一致,如果参考了其它脚本,要重点检查脚本实现同其它脚本是否一致,所有不一致的地方都应该有充分合理的理由,否则就应修改。
检查脚本时,也要关注超参的情况,超参问题主要体现为超参取值不合理,例如
1. 学习率设置不合理;
2. loss_scale参数不合理;
3. 权重初始化参数不合理等。
MindInsight可以辅助用户对超参做检查,大多数情况下,SummaryCollector会自动记录常见超参,您可以通过MindInsight的训练参数详情功能(如下图)和溯源分析功能查看超参。结合MindInsight模型溯源分析模块和脚本中的代码,可以确认超参的取值,识别明显不合理的超参。如果有标杆脚本,建议同标杆脚本一一比对超参取值,如果有默认参数值,则默认值也应一并比对,以避免不同框架的参数默认值不同导致精度下降或者训练错误。
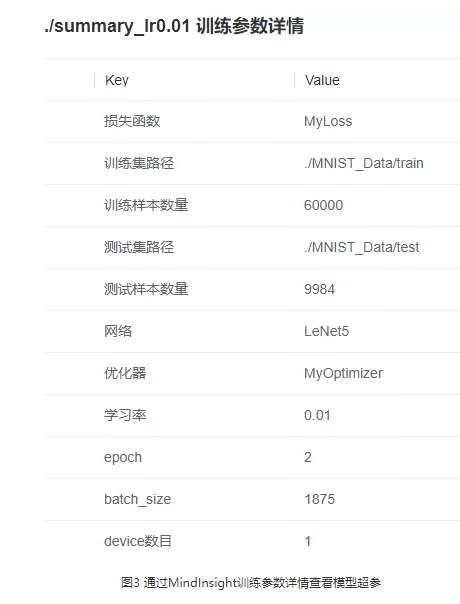
03检查模型结构
在模型结构方面,常见的问题有:
1. 算子使用错误(使用的算子不适用于目标场景,如应该使用浮点除,错误地使用了整数除);
2. 权重共享错误(共享了不应共享的权重);
3. 权重冻结错误(冻结了不应冻结的权重);
4. 节点连接错误(应该连接到计算图中的block未连接);
5. loss函数错误;
6. 优化器算法错误(如果自行实现了优化器)等。
建议通过检查模型代码的方式对模型结构进行检查。此外,MindInsight也可以辅助用户对模型结构进行检查。大多数情况下,SummaryCollector会自动记录计算图,通过MindInsight,用户可以方便地对计算图进行查看。模型脚本运行后,建议使用MindInsight计算图可视模块查看模型结构,加深对计算图的理解,确认模型结构符合预期。若有标杆脚本,还可以同标杆脚本对照查看计算图,检查当前脚本和标杆脚本的计算图是否存在重要的差异。
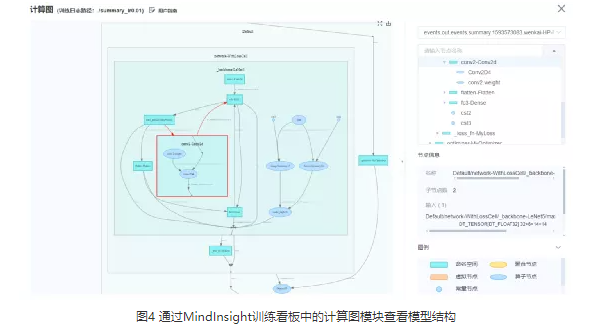
考虑到模型结构一般都很复杂,期望在这一步就能发现所有的模型结构问题是不现实的。只要通过可视化的模型结构加深对计算图的理解,发现明显的结构问题即可。后面的步骤中,发现了更明确的精度问题现象后,我们还会回到这一步重新检查确认。
注1:MindInsight支持查看SummaryCollector记录的计算图和MindSpore context的save_graphs参数导出的pb文件计算图。请参考我们教程中的“计算图可视化”部分了解更多信息(https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/dashboard.html)。
注2:脚本迁移工具可以将PyTorch、TensorFlow框架下编写的模型转换为MindSpore脚本,请访问教程(https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/migrate_3rd_scripts_mindconverter.html) 以了解更多信息。
04检查输入数据
通过检查输入模型的数据,可以结合脚本判断数据处理流水线和数据集是否存在问题。输入数据的常见问题有:
1. 数据缺失值过多;
2. 每个类别中的样本数目不均衡;
3. 数据中存在异常值;
4. 数据标签错误;
5. 训练样本不足;
6. 未对数据进行标准化,输入模型的数据不在正确的范围内;
7. finetune和pretrain的数据处理方式不同;
8. 训练阶段和推理阶段的数据处理方式不同;
9. 数据处理参数不正确等。
MindInsight可以辅助用户对输入数据、数据处理流水线进行检查。大多数情况下,SummaryCollector会自动记录输入模型的数据(数据处理后的数据)和数据处理流水线参数。输入模型的数据会展示在“数据抽样”模块,数据处理流水线参数会展示在“数据图”模块和“数据溯源”模块。通过MindInsight的数据抽样模块,可以检查输入模型的(数据处理流水线处理后的)数据。若数据明显不符合预期(例如数据被裁剪的范围过大,数据旋转的角度过大等),可以判断输入数据出现了一定的问题。通过MindInsight的数据图和数据溯源模块,可以检查数据处理流水线的数据处理过程和具体参数取值,从而发现不合理的数据处理方法。

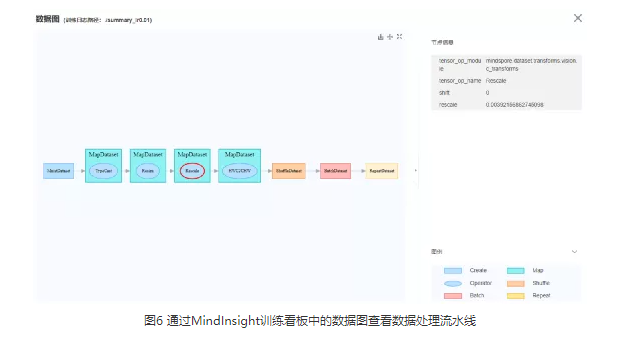
如果有标杆脚本,还可以同标杆脚本对照,检查数据处理流水线输出的数据是否和当前脚本的数据相同。例如,将数据处理流水线输出的数据保存为npy文件,然后使用numpy.allclose()方法对标杆脚本和当前脚本的数据进行对比。如果发现不同,则数据处理阶段可能存在精度问题。
若数据处理流水线未发现问题,可以手动检查数据集是否存在分类不均衡、标签匹配错误、缺失值过多、训练样本不足等问题。
05检查loss曲线
很多精度问题会在网络训练过程中发现,常见的问题或现象有:
1. 权重初始化不合理(例如初始值为0,初始值范围不合理等);
2. 权重中存在过大、过小值;
3. 权重变化过大;
4. 权重冻结不正确;
5. 权重共享不正确;
6. 激活值饱和或过弱(例如Sigmoid的输出接近1,Relu的输出全为0);
7. 梯度爆炸、消失;
8. 训练epoch不足;
9. 算子计算结果存在NAN、INF;
10. 算子计算过程溢出(计算过程中的溢出不一定都是有害的)等。
上述这些问题或现象,有的可以通过loss表现出来,有的则难以观察。MindInsight提供了针对性的功能,可以观察上述现象、自动检查问题,帮助您更快定位问题根因。例如:
- MindInsight的参数分布图模块可以展示模型权重随训练过程的变化趋势;
- MindInsight的张量可视模块可以展示张量的具体取值,对不同张量进行对比;
- MindInsight调试器内置了种类丰富,功能强大的检查能力,可以检查权重问题(例如权重不更新、权重更新过大、权重值过大/过小)、梯度问题(例如梯度消失、梯度爆炸)、激活值问题(例如激活值饱和或过弱)、张量全为0、NAN/INF、算子计算过程溢出等问题。
调试器使用教程:
https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/debugger.html
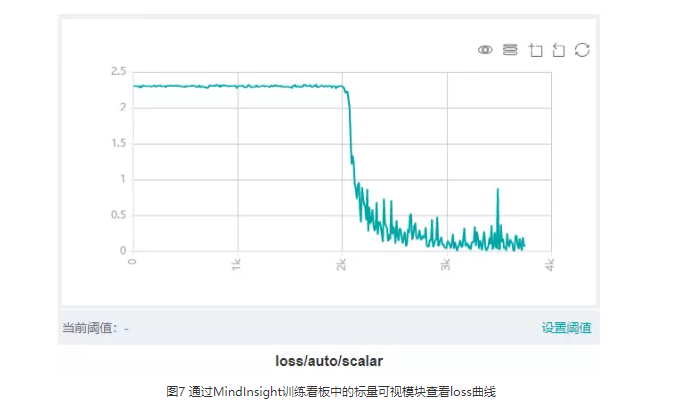
大多数情况下,SummaryCollector会自动记录模型的loss曲线,可以通过MindInsight的标量可视模块查看。loss曲线能够反映网络训练的动态趋势,通过观察loss曲线,可以得到模型是否收敛、是否过拟合等信息。
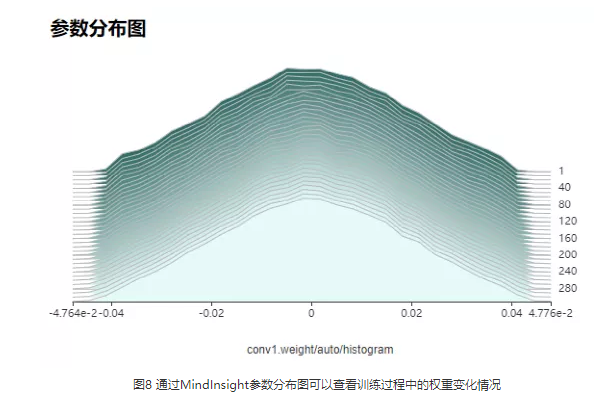
大多数情况下,SummaryCollector会自动记录模型参数变化情况(默认记录5个参数),可以通过MindInsight的参数分布图模块查看。如果想要记录更多参数的参数分布图,请参考SummaryCollector的histogram_regular参数(https://www.mindspore.cn/doc/api_python/zh-CN/master/mindspore/mindspore.train.html#mindspore.train.callback.SummaryCollector),或参考HistogramSummary算子(https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/summary_record.html#summarysummarycollector)。
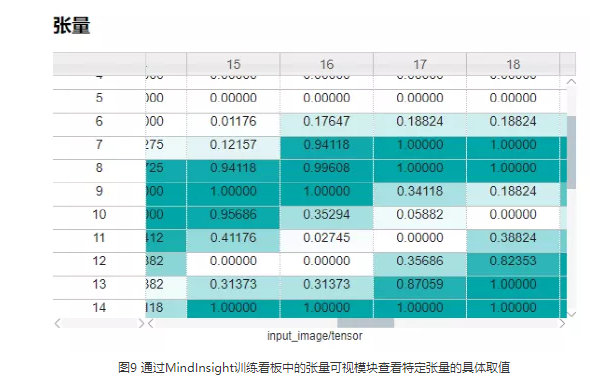
张量不会被自动记录,如果想要通过MindInsight查看张量的具体取值,请使用TensorSummary算子 (https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/summary_record.html#summarysummarycollector)。
下面结合loss曲线的常见现象介绍使用MindInsight进行精度问题定位的思路。
5.1 loss跑飞
loss跑飞是指loss中出现了NAN、+/-INF或者特别大的值。loss跑飞一般意味着算法设计或实现存在问题。定位思路如下:
1. 回顾脚本、模型结构和数据,
1)检查超参是否有不合理的特别大/特别小的取值,
2)检查模型结构是否实现正确,特别是检查loss函数是否实现正确,
3)检查输入数据中是否有缺失值、是否有特别大/特别小的取值。
2. 观察训练看板中的参数分布图,检查参数更新是否有明显的异常。若发现参数更新异常,可以结合调试器定位参数更新异常的原因。3. 使用调试器模块对训练现场进行检查。
1)若loss值出现NAN、+/-INF,可使用“检查张量溢出”条件添加全局监测点,定位首先出现NAN、+/-INF的算子节点,检查算子的输入数据是否会导致计算异常(例如除零)。若是算子输入数据的问题,则可以针对性地加入小数值epsilon避免计算异常。
2)若loss值出现特别大的值,可使用“检查过大张量”条件添加全局监测点,定位首先出现大值的算子节点,检查算子的输入数据是否会导致计算异常。若输入数据本身存在异常,则可以继续向上追踪产生该输入数据的算子,直到定位出具体原因。
3)若怀疑参数更新、梯度等方面存在异常,可使用“检查权重变化过大”、“检查梯度消失”、“检查梯度过大”等条件设置监测点,定位到异常的权重或梯度,然后结合张量检查视图,逐层向上对可疑的正向算子、反向算子、优化器算子等进行检查。
5.2 loss收敛慢
loss收敛慢是指loss震荡、收敛速度慢,经过很长时间才能达到预期值,或者最终也无法收敛到预期值。相较于loss跑飞,loss收敛慢的数值特征不明显,更难定位。定位思路如下:1. 回顾脚本、模型结构和数据,
1)检查超参是否有不合理的特别大/特别小的取值,特别是检查学习率是否设置过小或过大,学习率设置过小会导致收敛速度慢,学习率设置过大会导致loss震荡、不下降;
2)检查模型结构是否实现正确,特别是检查loss函数、优化器是否实现正确;
3)检查输入数据的范围是否正常,特别是输入数据的值是否过小
2. 观察训练看板中的参数分布图,检查参数更新是否有明显的异常。若发现参数更新异常,可以结合调试器定位参数更新异常的原因。3. 使用调试器模块对训练现场进程检查。
1)可使用“检查权重变化过小”、“检查未变化权重”条件对可训练(未固定)的权重进行监测,检查权重是否变化过小。若发现权重变化过小,可进一步检查学习率取值是否过小、优化器算法是否正确实现、梯度是否消失,并做针对性的修复。
2)可使用“检查梯度消失”条件对梯度进行监测,检查是否存在梯度消失的现象。若发现梯度消失,可进一步向上检查导致梯度消失的原因。例如,可以通过“检查激活值范围”条件检查是否出现了激活值饱和、Relu输出为0等问题。
5.3 其它loss现象
若训练集上loss为0,一般说明模型出现了过拟合,请尝试增大训练集大小。
06检查精度是否达到预期
MindInsight可以为用户记录每次训练的精度结果。在model.train和model.eval中使用同一个SummaryCollector实例时,会自动记录模型评估(metrics)信息。训练结束后,可以通过MindInsight的模型溯源模块检查训练结果精度是否达标。
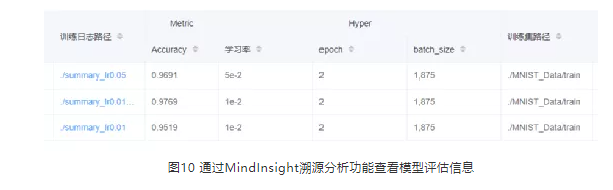
6.1 检查训练集上的精度
若训练集上模型的loss值、metric值未达到预期,可以参考以下思路进行定位和优化:
1. 回顾代码、模型结构、输入数据和loss曲线,
1)检查脚本,检查超参是否有不合理的值
2)检查模型结构是否实现正确
3)检查输入数据是否正确
4)检查loss曲线的收敛结果和收敛趋势是否存在异常
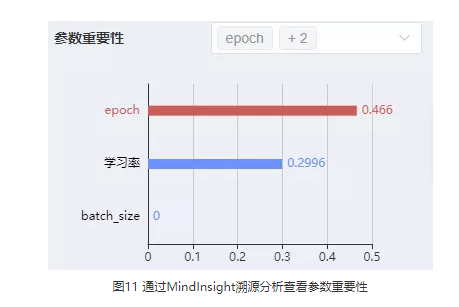
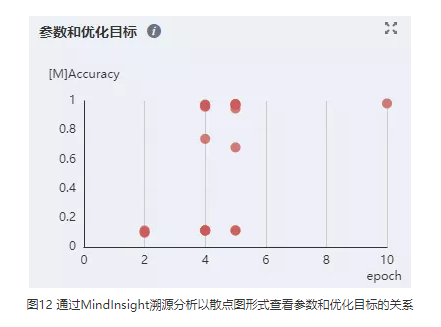
2. 尝试使用MindInsight溯源分析功能优化超参。溯源分析页面会对超参的重要性进行分析,用户应优先考虑调整重要性高的超参,从散点图中可以观察出超参和优化目标的关系,从而针对性地调整超参取值。
3. 尝试使用MindInsight调参器优化超参。请注意,调参器通过执行多次完整训练的方式进行超参搜索,消耗的时间为网络一次训练用时的若干倍,如果网络一次训练耗时较长,则超参搜索将需要很长的时间。调参器使用教程:https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/hyper_parameters_auto_tuning.html
4. 尝试使用MindInsight模型解释功能优化模型和数据集。模型解释功能可以通过显著图可视化展示对分类结果最重要的区域,还可以通过评分体系提示应该对哪类标签进行优化。
模型解释使用教程:https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/model_explaination.html
5. 尝试优化模型结构/算法。
6.2 检查验证集上的精度
若训练集精度和验证集精度都未达到预期,则应首先参考上一节检查训练集精度。若训练集精度已达到预期,但是验证集精度未达到预期,大概率是模型出现了过拟合,处理思路如下:
1. 检查验证集评估脚本的评估逻辑有无错误。特别是数据处理方式是否与训练集一致,推理算法有误错误,是否加载了正确的模型checkpoint。2. 增加数据量。包括增加样本量,进行数据增强和扰动等。3. 正则化。常见的技术如参数范数惩罚(例如向目标函数中添加一个正则项 ),参数共享(强迫模型的两个组件共享相同的参数值),提前中止训练等。4. 适当降低模型的规模。例如减少卷积层数等。
6.3 检查测试集上的精度
若验证集和测试集精度都未达到预期,则应首先参考上一节检查验证集精度。若验证集精度已达到预期,但是测试集精度未达到预期,考虑到测试集的数据是模型从未见过的新数据,原因一般是测试集的数据分布和训练集的数据分布不一致。处理思路如下:
1. 检查测试集评估脚本的评估逻辑有误错误。特别是数据处理方式是否与训练集一致,推理算法有误错误,是否加载了正确的模型checkpoint。
2. 检查测试集中的数据质量,例如数据的分布范围是否明显同训练集不同,数据是否存在大量的噪声、缺失值或异常值。
07小结
由于相同的现象存在多个可能原因,精度问题的定位非常依赖专家经验。希望上述定位方法和功能能够起到良好的引导的作用,帮助你不断积累成功经验,成为精度调优大师。
MindSpore模型精度调优实战:常用的定位精度调试调优思路的更多相关文章
- MindSpore模型精度调优实战:如何更快定位精度问题
摘要:为大家梳理了针对常见精度问题的调试调优指南,将以"MindSpore模型精度调优实战"系列文章的形式分享出来,帮助大家轻松定位精度问题,快速优化模型精度. 本文分享自华为云社 ...
- MindSpore模型精度调优实践
MindSpore模型精度调优实践 引论:在模型的开发过程中,精度达不到预期常常让人头疼.为了帮助用户解决模型调试调优的问题,为MindSpore量身定做了可视化调试调优组件:MindInsight. ...
- 高性能 Java 计算服务的性能调优实战
作者:vivo 互联网服务器团队- Chen Dongxing.Li Haoxuan.Chen Jinxia 随着业务的日渐复杂,性能优化俨然成为了每一位技术人的必修课.性能优化从何着手?如何从问题表 ...
- Java虚拟机性能监控与调优实战
From: https://c.m.163.com/news/a/D7B0C6Q40511PFUO.html?spss=newsapp&fromhistory=1 Java虚拟机性能监控与调 ...
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
- 类加载机制+JVM调优实战+代码优化
类加载机制 Java源代码经过编译器编译成字节码之后,最终都需要加载到虚拟机之后才能运行.虚拟机把描述类的数据从 Class 文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直 ...
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- JVM 性能调优实战之:使用阿里开源工具 TProfiler 在海量业务代码中精确定位性能代码
本文是<JVM 性能调优实战之:一次系统性能瓶颈的寻找过程> 的后续篇,该篇介绍了如何使用 JDK 自身提供的工具进行 JVM 调优将 TPS 由 2.5 提升到 20 (提升了 7 倍) ...
- JVM调优实战
JVM调优实战 文档修订记录 版本 日期 撰写人 审核人 批准人 变更摘要 & 修订位置 ...
随机推荐
- KMP算法中我对获取next数组的理解
之前在学KMP算法时一直理解不了获取next数组的函数是如何实现的,现在大概知道怎么一回事了,记录一下我对获取next数组的理解. KMP算法实现的原理就不再赘述了,先上KMP代码: 1 void g ...
- oracle实现通过logminer实现日志抓取分析
场景:现场库到前置库. 思考:使用触发器? 1.侵入性解决方案 2.需要时各种配置,不需要时又是各种配置 Change Data Capture:捕捉变化的数据,通过日志监测并捕获数据库的变动(包括数 ...
- python中使用excutemany执行update语句,批量更新
python中使用excutemany执行update语句,批量更新 # coding:utf8 import pymysql import logging connection = pymysql. ...
- Raft: 一点阅读笔记
前言 如果想要对Raft算法的了解更深入一点的话,仅仅做6.824的Lab和读<In Search of an Understandable Consensus Algorithm>这篇论 ...
- Python+Selenium - js操作
js操作:日期框 本部分涉及两个知识点:DOM树和js DOM树教程链接: https://www.w3school.com.cn/htmldom/index.asp js教程链接 https://w ...
- Linux基础服务——Bind DNS服务 Part2
Linux基础服务--Bind DNS服务 Part2 DNS反向解析与区域传送 实验环境延续Part1的实验环境. 反向区域配置 正向解析是域名到IP地址的映射,反向解析则是IP地址到域名的解析,在 ...
- VUE3后台管理系统【路由鉴权】
前言: 在"VUE3后台管理系统[模板构建]"文章中,详细的介绍了我使用vue3.0和vite2.0构建的后台管理系统,虽然只是简单的一个后台管理系统,其中涉及的技术基本都覆盖了, ...
- A100 GPU硬件架构
A100 GPU硬件架构 NVIDIA GA100 GPU由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成. GA100 GPU的完整实现包括以下单 ...
- cuSPARSELt开发NVIDIA Ampere结构化稀疏性
cuSPARSELt开发NVIDIA Ampere结构化稀疏性 深度神经网络在各种领域(例如计算机视觉,语音识别和自然语言处理)中均具有出色的性能.处理这些神经网络所需的计算能力正在迅速提高,因此有效 ...
- Android系统编程入门系列之应用环境及开发环境介绍
作为移动端操作系统,目前最新的Android 11.0已经发展的比较完善了,现在也到了系统的整理一番的时间,接下来的系列文章将以Android开发者为中心,争取用归纳总结的态度对初级入门者所应 ...