云原生的弹性 AI 训练系列之三:借助弹性伸缩的 Jupyter Notebook,大幅提高 GPU 利用率
Jupyter Notebooks 在 Kubernetes 上部署往往需要绑定一张 GPU,而大多数时候 GPU 并没有被使用,因此利用率低下。为了解决这一问题,我们开源了 elastic-jupyter-operator,将占用 GPU 的 Kernel 组件单独部署,在长期空闲的情况下自动回收,释放占用的 GPU。这篇文章主要介绍了这一开源项目的使用方式以及工作原理。
Jupyter Notebooks 是目前应用最为广泛的交互式开发环境,它很好地满足了数据科学、深度学习模型构建等场景的代码开发需求。不过 Jupyter Notebooks 在方便了算法工程师和数据科学家们日常开发工作的同时,也对基础架构提出了更多的挑战。

资源利用率的问题
最大的挑战来自于 GPU 资源利用率。在运行的过程中即使没有代码在运行,Notebook 也会长期占用着 GPU,造成 GPU 的空置等问题。在大规模部署 Jupyter 实例的场景下,一般会通过 Kubernetes 创建多个 Notebook 实例,分配给不同的算法工程师使用。而在这样的情况下,我们需要在对应的 Deployment 中事先申请 GPU,这样 GPU 会与对应的 Notebook 实例绑定,每个 Notebook 实例都会占用一张 GPU 显卡。
然而同一时间,并不是所有的算法工程师都在使用 GPU。在 Jupyter 中,编辑代码的过程是不需要使用计算资源的,只有在执行 Cell 中的代码片段时,才会使用 CPU 或 GPU 等硬件资源,执行并返回结果。由此可以预见,如果通过这样的部署方式会造成相当程度的资源浪费。

造成这一问题的原因主要是原生的 Jupyter Notebooks 没有很好地适配 Kubernetes。在介绍问题原因之前,先简单概述一下 Jupyter Notebook 的技术架构。如下图所示,Jupyter Notebook 主要由三部分组成,分别是用户和浏览器端,Notebook Server 和 Kernel。
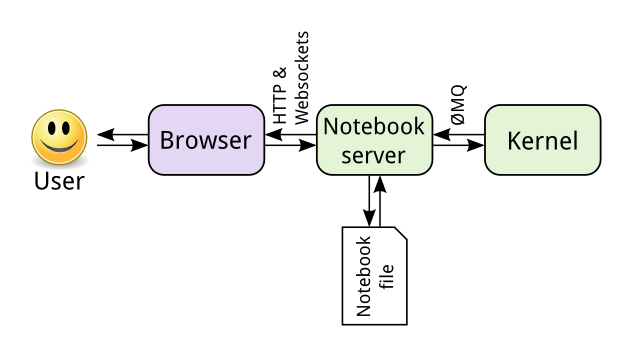
其中用户和浏览器端是 Jupyter 的前端,主要负责展示代码和执行结果等。Notebook Server 是它的后端服务器,来自浏览器的代码执行请求会被 Notebook Server 处理,分派给 Kernel 执行。Kernel 是真正负责执行代码,返回结果。
在传统的使用方式中,用户会通过 jupyter notebook $CODE_PATH 等命令,在本地运行 Jupyter Notebook Server,随后访问浏览器中的 Jupyter 交互式开发界面。当代码需要执行时,Notebook Server 会创建一个独立的 Kernel 进程,这一进程会使用 GPU 等运行。在 Kernel 长期空闲,没有代码需要执行时,这一进程会被终止,GPU 也就不再会被占用。
而当部署在 Kuberenetes 之上后,问题就产生了。Notebook Server 和 Kernel 运行在同一个 Pod 的同一个容器下,尽管只有执行代码时才需要运行的 Kernel 组件是需要 GPU 的,而长期运行的 Notebook Server 是不需要的,但是受限于 Kubernetes 的资源管理机制,还是需要给其提前申请 GPU 资源。
在 Notebook Server 的整个生命周期中,这一块 GPU 始终与 Pod 绑定。在 Kernel 进程空闲时虽然会被回收,但是已经分配给 Pod 的 GPU 卡却不能再交还给 Kubernetes 进行调度了。
解决方案
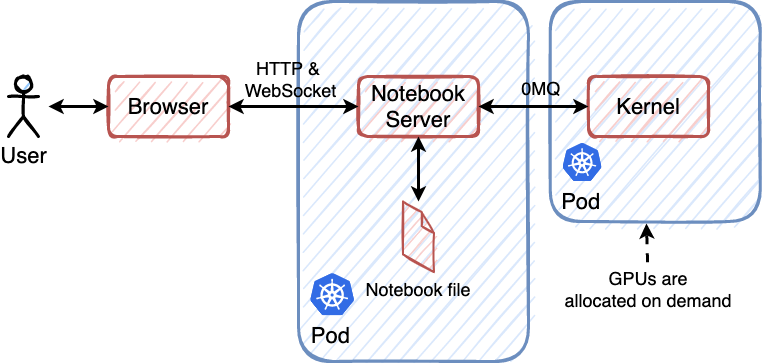
为了解决这一问题,我们开源了项目 elastic-jupyter-operator。思路非常朴素:问题源于 Notebook Server 和 Kernel 在同一个 Pod 中,导致我们无法分别为这两个组件申请计算资源。那只要将他们分开部署,让 Notebook Server 在单独的 Pod 中,Kernel 也在单独的 Pod 中,相互之间通过 ZeroMQ 通信即可。
通过这样的方式,Kernel 会在空闲时被释放。在需要时会再次被临时性地申请 GPU,运行起来。为了实现这一目的,我们在 Kubernetes 中实现了 5 个 CRD,同时为 Jupyter 引入了一个新的 KernelLauncher 实现。通过它们,用户可以在 GPU 空闲时将 Kernel 回收释放,在需要执行代码时再动态地申请 GPU 资源,创建 Kernel Pod 进行代码执行。
简单的例子
下面我们将通过一个例子介绍使用方式。首先我们需要创建 JupyterNotebook CR(CustomResource),这一个 CR 会创建出对应的 Notebook Server:
apiVersion: kubeflow.tkestack.io/v1alpha1
kind: JupyterNotebook
metadata:
name: jupyternotebook-elastic
spec:
gateway:
name: jupytergateway-elastic
namespace: default
auth:
mode: disable
其中指定了 gateway,这是另外一个 CR JupyterGateway。为了能够让 Jupyter 支持远程的 Kernel,需要这样一个网关进行请求的转发。我们同样需要创建这样一个 CR:
apiVersion: kubeflow.tkestack.io/v1alpha1
kind: JupyterGateway
metadata:
name: jupytergateway-elastic
spec:
cullIdleTimeout: 3600
image: ccr.ccs.tencentyun.com/kubeflow-oteam/enterprise-gateway:2.5.0
JupyterGateway CR 中的配置 cullIdleTimeout 指定了经过多久的空闲时间后,其管理的 Kernel Pod 会被系统回收释放。在例子中是 1 个小时。创建完这两个资源后,就可以体验到弹性伸缩的 Jupyter Notebook 了。如果在一个小时内一直没有使用的话,Kernel 会被回收。
$ kubectl apply -f ./examples/elastic/kubeflow.tkestack.io_v1alpha1_jupyternotebook.yaml
$ kubectl apply -f ./examples/elastic/kubeflow.tkestack.io_v1alpha1_jupytergateway.yaml
$ kubectl port-forward deploy/jupyternotebook-elastic 8888:8888
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jovyan-219cfd49-89ad-428c-8e0d-3e61e15d79a7 1/1 Running 0 170m
jupytergateway-elastic-868d8f465c-8mg44 1/1 Running 0 3h
jupyternotebook-elastic-787d94bb4b-xdwnc 1/1 Running 0 3h10m
除此之外,由于 Notebook 和 Kernel 解耦的设计,使得用户可以方便地修改 Kernel 的镜像与资源配额、向已经在运行的 Notebook 中添加新的 Kernel 等。
设计与实现
在介绍完使用方式后,我们简单介绍其设计与实现。

当用户在浏览器中选择执行代码时,首先请求会发送给在 Kubernetes 上运行的 Notebook Server。由于目前集群上没有正在运行的 Kernel,代码执行任务无法分配下去,所以 Notebook Server 会向 Gateway 发送一个创建 Kernel 的请求。Gateway 负责管理远端的 Kernel 的生命周期,它会在 Kubernetes 集群中创建对应的 JupyterKernel CR。随后会与集群中已经创建好的 Kernel 通过 ZeroMQ 进行交互,然后将代码执行的请求发送给 Kernel 进行执行,随后将结果发送给 Notebook Server 再将其返回给前端进行渲染和展示。
而 Gateway 会根据在 JupyterGateway CR 中定义的有关资源回收的参数,定时检查目前管理的 Kernel 中有没有满足要求,需要被回收的实例。当 Kernel 空闲时间达到了定义的阈值时,Gateway 会删除对应的 JupyterKernel CR,将其回收,释放 GPU。
总结
目前深度学习在开发与落地生产的过程中仍然存在着诸多的挑战。elastic-jupyter-operator 瞄准了在开发过程中的 GPU 利用率与开发效率的问题,提出了一种可行的方案,将占用 GPU 的 Kernel 组件单独部署,在长期空闲的情况下自动回收,释放占用的 GPU,通过这样的方式提高资源的利用率的同时,也给予了算法工程师用户更多的灵活度。
从算法工程师的角度来说,elastic-jupyter-operator 支持自定义的 Kernel,可以自行选择在 Kernel 的容器镜像中安装 Python 包或者系统依赖,不需要担心与团队内部的 Notebook 统一镜像的版本一致性问题,提高研发效率。
而从运维与资源管理的角度来说,elastic-jupyter-operator 遵循了云原生的设计理念,以 5 个 CRD 的方式对外提供服务,对于已经落地 Kuerbenetes 的团队来说具有较低的运维成本。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

云原生的弹性 AI 训练系列之三:借助弹性伸缩的 Jupyter Notebook,大幅提高 GPU 利用率的更多相关文章
- 云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
引言 随着模型规模和数据量的不断增大,分布式训练已经成为了工业界主流的 AI 模型训练方式.基于 Kubernetes 的 Kubeflow 项目,能够很好地承载分布式训练的工作负载,业已成为了云原生 ...
- 云原生的弹性 AI 训练系列之二:PyTorch 1.9.0 弹性分布式训练的设计与实现
背景 机器学习工作负载与传统的工作负载相比,一个比较显著的特点是对 GPU 的需求旺盛.在之前的文章中介绍过(https://mp.weixin.qq.com/s/Nasm-cXLtJObjLwLQH ...
- 打造云原生大型分布式监控系统系列文章-腾讯工程师roc
附上本系列文章链接 打造云原生大型分布式监控系统(一): 大规模场景下 Prometheus 的优化手段 打造云原生大型分布式监控系统(二): Thanos 架构详解 打造云原生大型分布式监控系统(二 ...
- Home Assistant系列--之树莓派安装Samba 和 Jupyter Notebook
1.什么是Samba? Samba是在Linux和UNIX系统上实现SMB协议的一个免费软件,由服务器及客户端程序构成.SMB(Server Messages Block,信息服务块)是一种在局域网上 ...
- 重大升级!灵雀云发布全栈云原生开放平台ACP 3.0
云原生技术的发展正在改变全球软件业的格局,随着云原生技术生态体系的日趋完善,灵雀云的云原生平台也进入了成熟阶段.近日,灵雀云发布重大产品升级,推出全栈云原生开放平台ACP 3.0.作为面向企业级用户的 ...
- [源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期
[源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期 目录 [源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Work ...
- AI云原生浅谈:好未来AI中台实践
AI时代的到来,给企业的底层IT资源的丰富与敏捷提出了更大的挑战,利用阿里云稳定.弹性的GPU云服务器,领先的GPU容器化共享和隔离技术,以及K8S集群管理平台,好未来通过云原生架构实现了对资源的灵活 ...
- 阿里云弹性容器实例产品 ECI ——云原生时代的基础设施
阿里云弹性容器实例产品 ECI ——云原生时代的基础设施 1. 什么是 ECI 弹性容器实例 ECI (Elastic Container Instance) 是阿里云在云原生时代为用户提供的基础计算 ...
- 技术分享 | 云原生多模型 NoSQL 概述
作者 朱建平,TEG/云架构平台部/块与表格存储中心副总监.08年加入腾讯后,承担过对象存储.键值存储,先后负责过KV存储-TSSD.对象存储-TFS等多个存储平台. NoSQL 技术和行业背景 No ...
随机推荐
- MMM双主-双从读写分离部署
原文转自:https://www.cnblogs.com/itzgr/p/10233932.html作者:木二 目录 一 前期规划 1.1 主机规划 1.2 虚拟IP规划 1.3 用户列表 1.4 整 ...
- 发布日志 - kratos v2.0.4 版本发布
V2.0.4 Release Release v2.0.4 · go-kratos/kratos (github.com) 新的功能 proto-gen-http 工具在生产代码时如果 POST/PU ...
- 1,Spark参数调优
Spark调优 目录 Spark调优 一.代码规范 1.1 避免创建重复RDD 1.2 尽量复用同一个RDD 1.3 多次使用的RDD要持久化 1.4 使用高性能算子 1.5 好习惯 二.参数调优 资 ...
- 二、grep文本搜索工具
grep命令作为Unix中用于文本搜索的神奇工具,能够接受正则表达式,生成各种格式的输出.除此外,它还有大量有趣的选项. # 搜索包含特定模式的文本行: [root@centos8 ~]#grep p ...
- C# 爬虫框架实现 流程_爬虫结构/原理
目录链接:C# 爬虫框架实现 概述 首先需要讲的是,爬虫的原理.其实在我看来,爬虫只是用来解决以下四个问题的工具: 提取哪些网页 提取网页上的哪些内容 存储到哪里(推荐数据库/开源类/Console) ...
- 【SpringCloud技术专题】「Eureka源码分析」从源码层面让你认识Eureka工作流程和运作机制(上)
前言介绍 了解到了SpringCloud,大家都应该知道注册中心,而对于我们从过去到现在,SpringCloud中用的最多的注册中心就是Eureka了,所以深入Eureka的原理和源码,接下来我们要进 ...
- python打包发布自己的pip项目
原文链接:https://blog.csdn.net/Liangjun_Feng/article/details/80037315 一.注册pypi账号 网址:https://pypi.org/ 直接 ...
- Python - 通过PyYaml库操作YAML文件
PyYaml简单介绍 Python的PyYAML模块是Python的YAML解析器和生成器 它有个版本分水岭,就是5.1 读取YAML5.1之前的读取方法 def read_yaml(self, pa ...
- MongoDB 常见问题 - 解决 brew services list 查看 MongoDB 服务 status 显示 error 的问题
问题背景 将 MongoDB 作为服务运行 brew services start mongodb-community@4.4 也显示运行成功了,但是查看服务列表的时候,发现 MongoDB 服务的还 ...
- 【第十一篇】- Git Gitee之Spring Cloud直播商城 b2b2c电子商务技术总结
Git Gitee 大家都知道国内访问 Github 速度比较慢,很影响我们的使用. 如果你希望体验到 Git 飞一般的速度,可以使用国内的 Git 托管服务--Gitee(gitee.com). G ...